爬取的目的
通过爬取基金持仓信息,我们可以了解基金的资金流向,说白了,就是知道大型基金公司都买了什么股票,买了多少。也可以跟踪一些知名的基金,看看他们都买了什么股票,从而跟买或者不买,估值便宜的股票,又有很多基金入场,很可能这家公司大家都非常看好,未来业绩很可能增长,可能是一次比较好的投资机会;而有些股票,估值已经很高了,里边还有很多的基金公司,这就需要注意了,很可能基本面发生一点点恶化,或者达不到预期,基金公司可能就会大幅的抛售,导致股价大跌。
效果
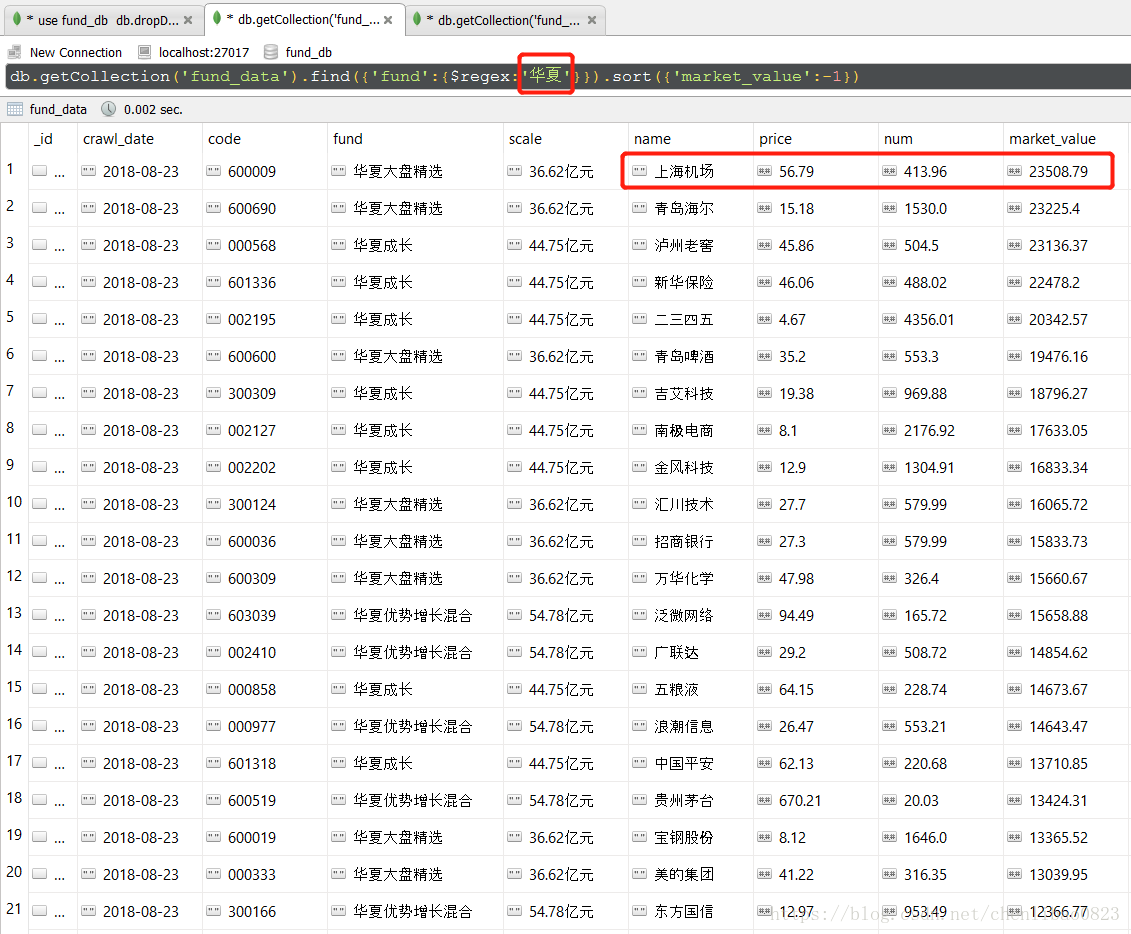
直接上图,看看最终的效果,我们直接搜索“华夏”,同时按照市值大小排序,就可以获得华夏基金中,市值最大的一只股票是上海机场,市值2.35亿,此处的市值是8月23日的市值,并不是买入的成本,华夏基金可能比较看好上海机场,一只股票花了2亿多。如果你感兴趣,就可以自己去研究下这只股票。(由于代码还在爬取中,所以数据并不全,仅供学习作用)
排第二的是青岛海尔,买了2.3亿,当然,我们也可以看看华夏基金公司一共买了多少的青岛海尔。如第二幅图,我们发现华夏大盘和华夏优势两只基金都买了青岛海尔,看来青岛海尔这只大白马,还是很受华夏看好的。

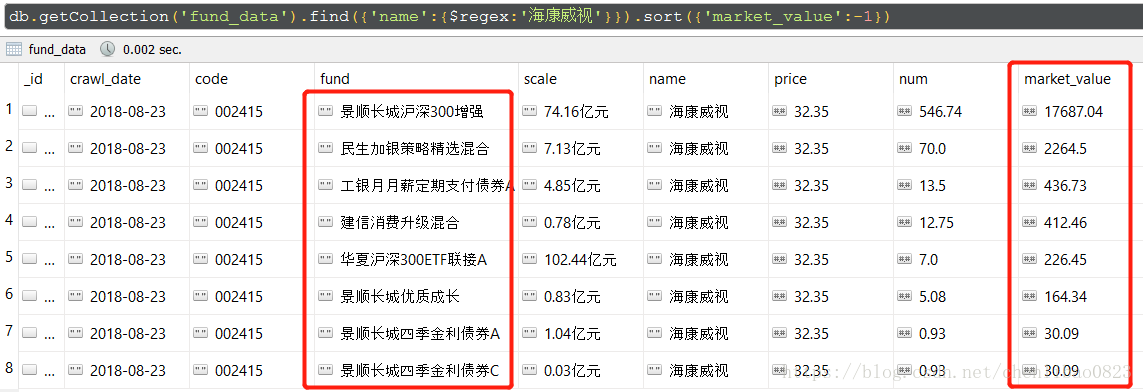
如果我们想看看,买入海康威视的基金公司有哪些,买入的多否,可以如下查询数据库,有8只公募基金买入海康
数据的运用还有很多,你也可以导出数据库,制作成图表的形式,具体看个人的需要。回归爬虫的主题。
项目思路
- 确定URL
- 确定爬取字段
书写爬虫
这是我们最终爬取的URL,如下
这是我们需要爬取的信息:
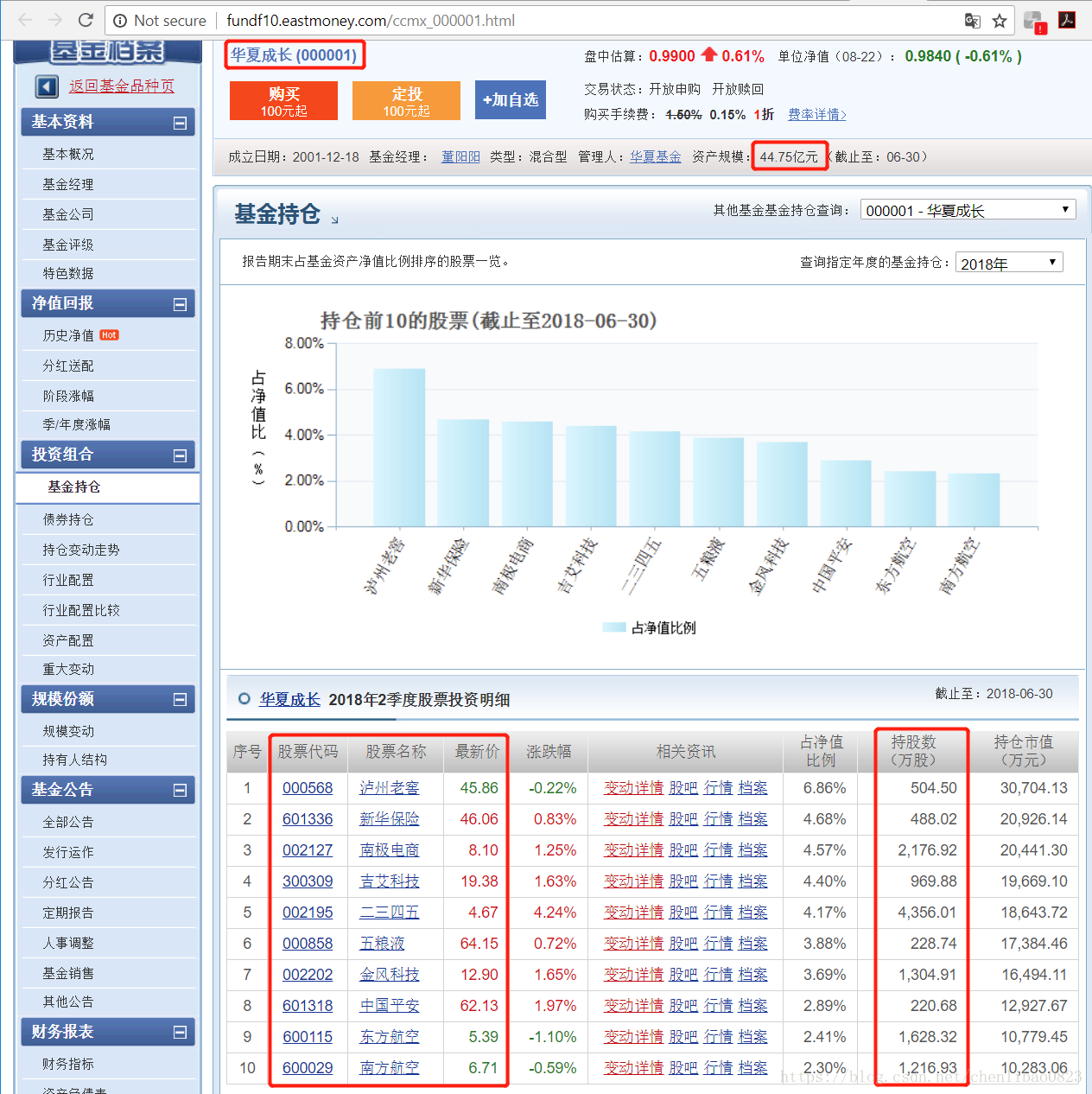
我们发现url中的000001为基金代码,所以我们找到了所有基金的代码,就可以获得所有基金信息的url。
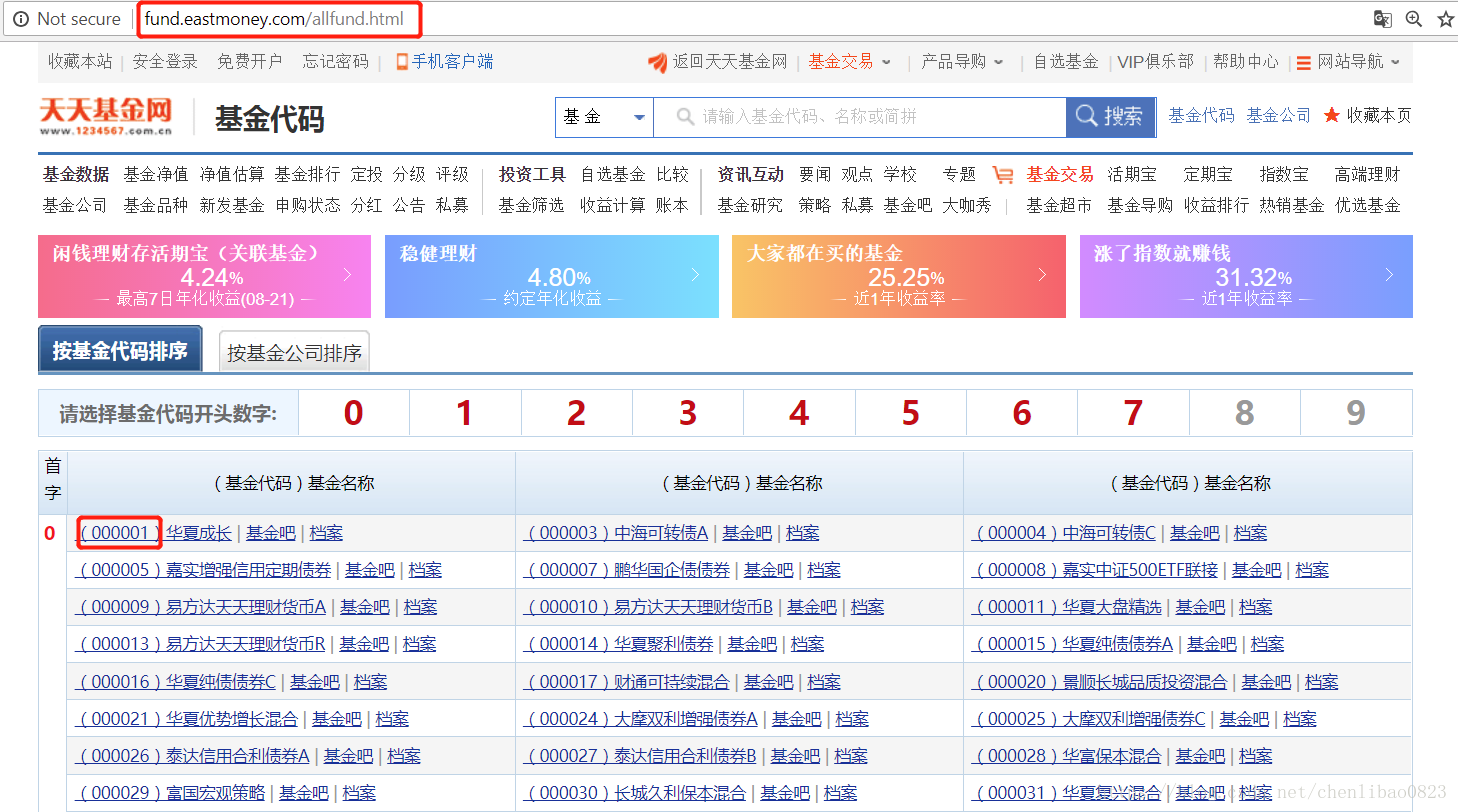
第一步我们就需要获得基金代码,我是从这个地址中,爬取了所有的基金代码,并构建了所有基金的url :
all_fund = http://fund.eastmoney.com/allfund.html
获取url的代码
这里我将爬取的基金代码导出到了文件fund_code.txt中,同时构建url,导出到 fund_url.txt。
这里需要注意,一个是编码的问题,我直接对html进行爬取数据,出现了编码问题,所以加了'gbk’,从而避免中文乱码的问题。
另外,此处爬取信息,我采用的etree.HTML进行解析,然后用xpath进行抓取,刚开始我是用BeautifulSoup的,但是由于到了标签a的时候,由于有多个标签a,定义具体的a位置比较麻烦,所以我采用了xpath,其能够对第几个标签进行选择,此处是用 “… / a[1] / text()”
# coding:utf-8
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
def get_code(url):
html = requests.get(url, headers=headers)
html.encoding = 'gbk'
document = etree.HTML(html.text)
info = document.xpath('// *[ @ id = "code_content"] / div / ul / li / div / a[1] /text()')
i = 0
for fund in info:
str = fund.split(')')[0]
code = str.split('(')[1]
with open('fund_code.txt', 'a+') as f:
f.write(code + '\n')
with open('fund_url.txt', 'a+') as u:
fund_url = 'http://fundf10.eastmoney.com/ccmx_%s.html' % code
u.write(fund_url + '\n')
i = i + 1
print('i:', i)
if __name__ == "__main__":
url = 'http://fund.eastmoney.com/allfund.html'
get_code(url)获得的数据是这样的:
正式爬取
我们爬取的字段:
爬取时间
股票代码
基金名称
基金规模
股票名称
实时价格
持股数量
股票市值
基金URL
这里边要注意,爬取时间,是直接获取的系统时间,实时价格,是你爬取时的价格,股票市值是由价格与持股数量计算出来的,而非网站爬取的,网站的显示市值,是按照季度末那一天的价格,对应的市值,我们采用的是实时市值。
代码如下
# coding:utf-8
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import random
from pymongo import MongoClient
import datetime
client = MongoClient('localhost', 27017)
fund_db = client['fund_db']
fund_data = fund_db['fund_data']
fund_no_data = fund_db['fund_no_data']
def get_info(url):
print(url)
opt = webdriver.ChromeOptions()
opt.set_headless()
driver = webdriver.Chrome(options=opt)
driver.maximize_window()
driver.get(url)
driver.implicitly_wait(5)
day = datetime.date.today()
today = '%s' % day
with open('jijin1.html', 'w', encoding='utf-8') as f:
f.write(driver.page_source)
time.sleep(1)
file = open('jijin1.html', 'r', encoding='utf-8')
soup = BeautifulSoup(file, 'lxml')
try:
fund = soup.select('#bodydiv > div > div > div.basic-new > div.bs_jz > div.col-left > h4 > a')[0].get_text()
scale = soup.select('#bodydiv > div > div.r_cont > div.basic-new > div.bs_gl > p > label > span')[2].get_text().strip().split()[0]
table = soup.select('#cctable > div > div > table')
trs = table[0].select('tbody > tr')
for tr in trs:
code = tr.select('td > a')[0].get_text()
name = tr.select('td > a')[1].get_text()
price = tr.select('td > span')[0].get_text()
try:
round(float(price), 2)
except ValueError:
price = 0
num = tr.select('td.tor')[3].get_text()
market = float(num.replace(',', '')) * float(price)
data = {
'crawl_date': today,
'code': code,
'fund': fund.split(' (')[0],
'scale': scale,
'name': name,
'price': round(float(price), 2),
'num': round(float(num.replace(',', '')), 2),
'market_value': round(market, 2),
'fund_url': url
}
fund_data.insert(data)
except IndexError:
info = {
'url': url
}
fund_no_data.insert(info)
if __name__ == "__main__":
with open('fund_url.txt', 'r') as f:
i = 0
for url in f.readlines():
get_info(url)
time.sleep(random.randint(0, 2))
i = i + 1
print('run times:', i)我采用了模拟浏览器的方式进行爬取,用了谷歌浏览器,并将其设置为无头模式(set_headless),用了BeautifulSoup来匹配文档。
一个注意点是,由于有些基金不是股票型的,根本就没买股票,所以爬取就会报IndexError,我这里用try…except的方式,如果报错,就将对应的URL写入数据库中的fund_no_data集合中。有数据的就写入fund_data集合中去。我这里采用的是MongoDB来存储数据。
可以看到我还加了不少的时间模块,主要是爬取的时候,也需要歇一歇,就怕速度太快,容易出现问题,或者被封号。里边我添加的crawl_date对应的数据,因为数据库无法直接识别,所以我用 today = ‘%s’ % day 格式化的模式,变成了字符串,这样就可以传入到了数据库了。
剩余的时间,就等着它爬完吧,写这篇文章的时候,已经跑了几个小时了,just hold on….
补充下,爬取之前,需要先将MongoDB打开。这里边比较难的地方,主要就是匹配定位,这个需要自己多去尝试,尝试的时候打印出来,看看结果,然后相应修改。我就是这么干的~
先写这么多。。。