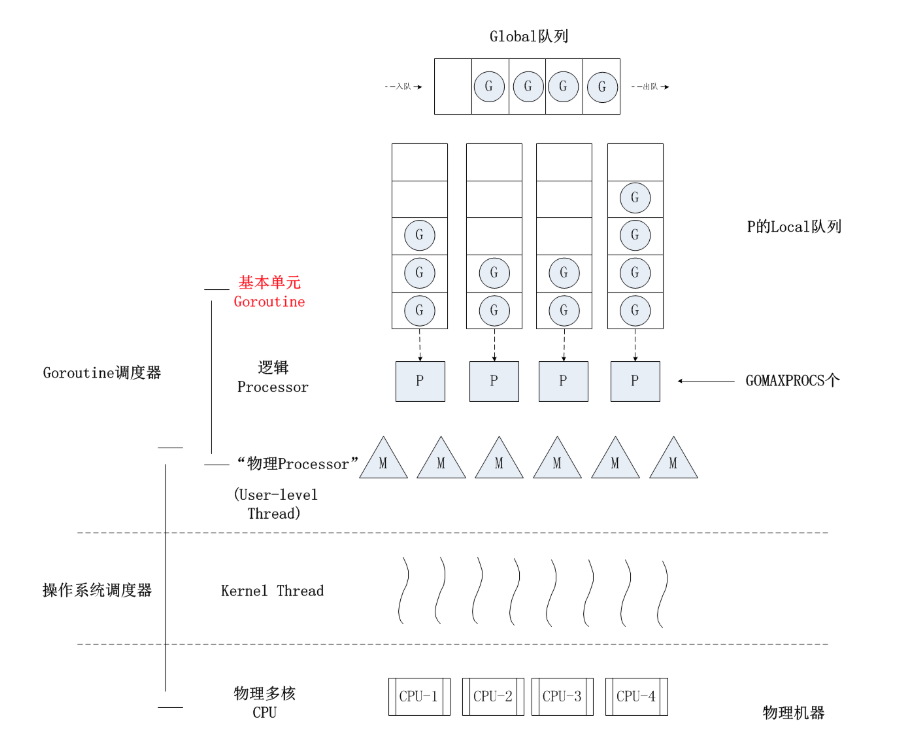
G M P
structG
goroutine的栈采取了动态扩容方式, 初始时仅为2KB,随着任务执行按需增长,最大可达1GB(64位机器最大是1G,32位机器最大是256M),且完全由golang自己的调度器 Go Scheduler 来调度。G并不直接绑定OS线程运行,而是由Goroutine Scheduler中的 P - Logical Processor (逻辑处理器)来作为两者的『中介』 G: 表示Goroutine,每个Goroutine对应一个G结构体,G存储Goroutine的运行堆栈、状态以及任务函数,可重用。G并非执行体,每个G需要绑定到P才能被调度执行。
structP
P: Processor,表示逻辑处理器, 对G来说,P相当于CPU核,G只有绑定到P(在P的local runq中)才能被调度。对M来说,P提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等,P的数量决定了系统内最大可并行的G的数量(前提:物理CPU核数 >= P的数量),P的数量由用户设置的GOMAXPROCS决定,但是不论GOMAXPROCS设置为多大,P的数量最大为256。
structM
M: Machine,OS线程抽象,代表着真正执行计算的资源,在绑定有效的P后,进入schedule循环;而schedule循环的机制大致是从Global队列、P的Local队列以及wait队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到M,如此反复。M并不保留G状态,这是G可以跨M调度的基础,M的数量是不定的,由Go Runtime调整,为了防止创建过多OS线程导致系统调度不过来,目前默认最大限制为10000个。
sysmon
sysmon每20us~10ms启动一次,按照《Go语言学习笔记》中的总结,sysmon主要完成如下工作:
- 释放闲置超过5分钟的span物理内存;
- 如果超过2分钟没有垃圾回收,强制执行;
- 将长时间未处理的netpoll结果添加到任务队列;
- 向长时间运行的G任务发出抢占调度;
- 收回因syscall长时间阻塞的P;
goroutine调度
Go runtime会在下面的goroutine被阻塞的情况下运行另外一个goroutine
- network input:网络IO阻塞(异步IO不会阻塞,只会阻塞同步IO)
- channel operations:channel阻塞
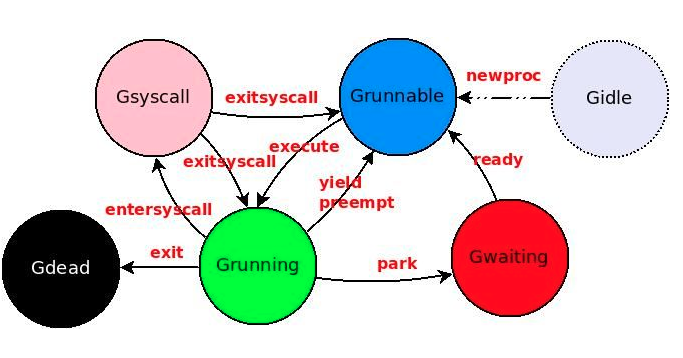
用户态阻塞/唤醒:这两个阻塞G的状态由_Gruning变为_Gwaitting。M会跳过该G尝试获取并执行下一个G,如果此时没有runnable的G供M运行,那么M将解绑P,并进入sleep状态
- blocking syscall (for example opening a file):系统调用阻塞
- primitives in the sync package:sync包里的原语操作
系统调用阻塞:当G被阻塞在某个系统调用上时,此时G会阻塞在_Gsyscall状态,M也处于 block on syscall 状态,此时的M可被抢占调度:执行该G的M会与P解绑,而P则尝试与其它idle的M绑定,继续执行其它G。如果没有其它idle的M,但P的Local队列中仍然有G需要执行,则创建一个新的M;当系统调用完成后,G会重新尝试获取一个idle的P进入它的Local队列恢复执行,如果没有idle的P,G会被标记为runnable加入到Global队列
- 抢占调度
这个抢占式调度的原理则是在每个函数或方法的入口,加上一段额外的代码,让runtime有机会检查是否需要执行抢占调度。这种解决方案只能说局部解决了“饿死”问题,对于没有函数调用,纯算法循环计算的G,scheduler依然无法抢占。由sysmon完成。
调试
https://golang.org/pkg/runtime/
$ go build test.go $ GODEBUG schedtrace=1000 ./test SCHED 0ms: gomaxprocs=4 idleprocs=4 threads=6 spinningthreads=0 idlethreads=4 runqueue=0 [0 0 0 0]
gomaxprocs: P的数量; idleprocs: 处于idle状态的P的数量;通过gomaxprocs和idleprocs的差值,我们就可知道执行go代码的P的数量; threads: os threads的数量,包含scheduler使用的m数量,加上runtime自用的类似sysmon这样的thread的数量; spinningthreads: 处于自旋状态的os thread数量; idlethread: 处于idle状态的os thread的数量; runqueue=1: go scheduler全局队列中G的数量; [3 4 0 10]: 分别为4个P的local queue中的G的数量。
如果需要查看PMG的详情可以用schedtrace=1000,scheddetail=1
goroutine的状态变迁
内存分配
mspan
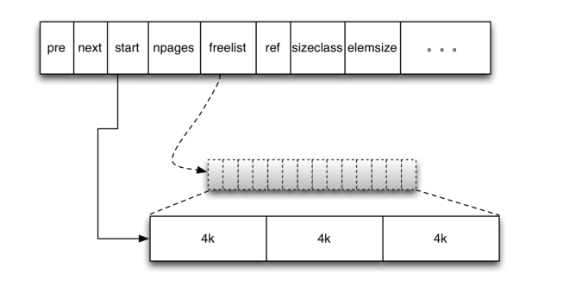
分配内存的最小单元,以链表形式存在有67种大小的mspan,8B,16B,32B...32KB(共66种,使用1~66表示),超过32KB的用0表示的大对象。
struct MSpan
{
MSpan *next; // in a span linked list
MSpan *prev; // in a span linked list
PageID start; // starting page number
uintptr npages; // number of pages in span
MLink *freelist; // list of free objects
uint32 ref; // number of allocated objects in this span
int32 sizeclass; // size class
uintptr elemsize; // computed from sizeclass or from npages
uint32 state; // MSpanInUse etc
int64 unusedsince; // First time spotted by GC in MSpanFree state
uintptr npreleased; // number of pages released to the OS
byte *limit; // end of data in span
MTypes types; // types of allocated objects in this span
};
- 每个page 大小8K(上图应该是8K)
- start表示起始page
- npages表示总的page数
- sizeclass表示元素大小类型,如:3表示32byte,其中0表示大对象
mcache
每个 Gorontine 的运行都是绑定到一个 P 上面,mcache 是每个 P 的 cache。本地内存,线程独享
type mcache struct {
// 小对象分配器,小于 16 byte 的小对象都会通过 tiny 来分配。
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr // number of tiny allocs not counted in other stats
// The rest is not accessed on every malloc.
alloc [_NumSizeClasses]*mspan // spans to allocate from
}
- alloc: 67种类型的mspan的指针,_NumSizeClasses=67。按是否需要标记又分为两种,如果对象包含了指针, 分配对象时会使用scan的span,如果对象不包含指针, 分配对象时会使用noscan的span
mcentrel
全局cache,mcache 不够用的时候向 mcentral 申请
type mcentral struct {
lock mutex
sizeclass int32
nonempty mSpanList // list of spans with a free object, ie a nonempty free list
empty mSpanList // list of spans with no free objects (or cached in an mcache)
}
- sizeclass:有67个mcenteral实例,对应申请不同类型的mspan
- nonempty:当前 mcentral 中可用的 mspan list
- empty:已经被使用的的mspan list
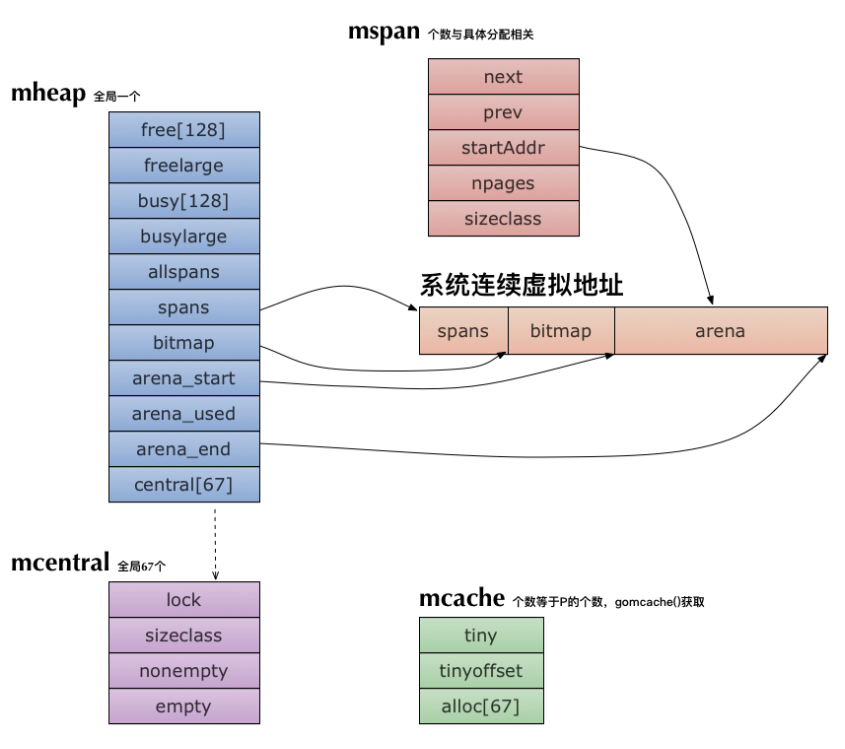
mheap
当 mcentral 也不够用的时候,通过 mheap 向操作系统申请
type mheap struct {
lock mutex
allspans []*mspan // all spans out there
// This is backed by a reserved region of the address space so
// it can grow without moving. The memory up to len(spans) is
// mapped. cap(spans) indicates the total reserved memory.
spans []*mspan
// central free lists for small size classes.
// the padding makes sure that the MCentrals are
// spaced CacheLineSize bytes apart, so that each MCentral.lock
// gets its own cache line.
central [_NumSizeClasses]struct {
mcentral mcentral
pad [sys.CacheLineSize]byte
}
arena_start uintptr
arena_used uintptr // always mHeap_Map{Bits,Spans} before updating
arena_end uintptr
}
- allspans:所有的 spans 都是通过 mheap申请,所有申请过的 mspan 都会记录在 allspans
- central [_NumSizeClasses]:mcentral实例,全局67个
- arean:是mheap的核心,启动时分配的虚拟连续内存地址,包括:spans(512M) bitmap(16G) arean(512G)。通常64位的系统最大堆内存是512G

- bitmap:标识对应的内存地址是否被使用,2位标识一个内存地址,一个标识shoud scan,一个标识is pointer。bitmap大小怎么算出来的?每个地址8byte,共512G/8个地址,bitmap中的每个byte能标识4个地址,因此大小为:512G/8/4=16G
- spans []mspan: 记录 arena 区域页号(page number)和 mspan 的映射关系。一页8K,每个 指针8byte,512GB/8KB8B=512MB
内存回收
标记清除
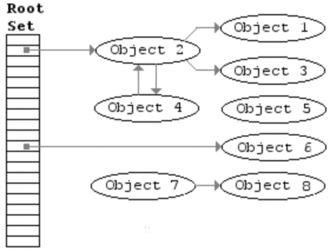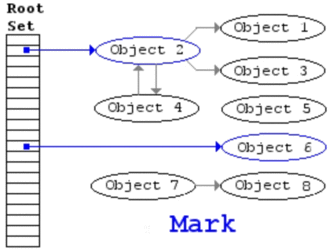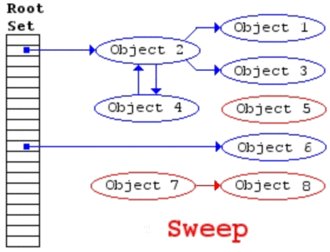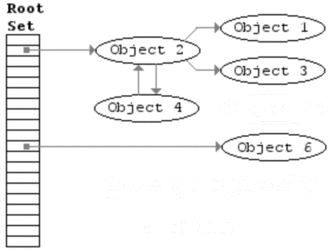
三色标记法
三色标记法是改进的标记清除
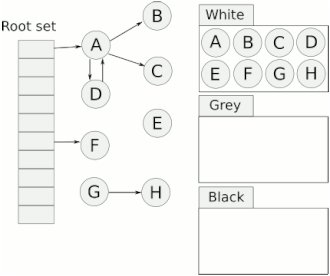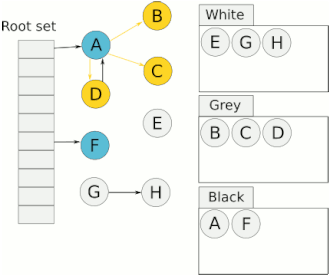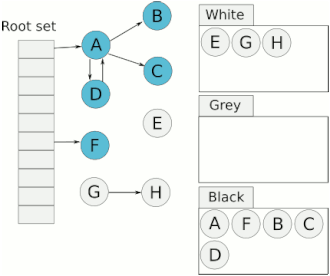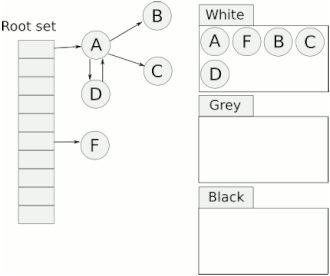
1.8以前两次stw

1.8以后一次stw

参考资料
https://studygolang.com/articles/11030 https://hk.saowen.com/a/0cd39976e6a0ef25d517a0a1fbeb6f9501c0183c6099d5305e9e990bb3eca3f9 https://segmentfault.com/a/1190000015464889 go 工具 https://software.intel.com/en-us/blogs/2014/05/10/debugging-performance-issues-in-go-programs 垃圾回收 https://blog.csdn.net/u010412301/article/details/79810963