
一、结 论写在前面
传统的推荐系统通过学习和强化过去的用户-物品交互形成强烈的反馈循环,这反过来限制了新用户兴趣的发现。
为了解决这一问题,论文引入了一种结合大型语言模型(LLMs)和经典推荐模型的混合层次框架,用于用户兴趣探索。该框架通过“兴趣集群”控制LLMs和经典推荐模型之间的接口,集群的粒度可以由算法设计者明确确定。该方法结合了LLMs在推理和泛化方面的优势,以及经典推荐模型的基础。它首先使用语言表示“兴趣集群”,并利用经过微调的LLM生成严格属于这些预定义集群的新兴趣描述。在低层次上,它通过限制经典推荐模型(在这种情况下是一个基于Transformer的序列推荐器)返回属于高层次生成的新集群的物品,将这些生成的兴趣具体化为物品级别的策略。
论文在一个服务于数十亿用户的工业级商业平台上展示了这种方法的有效性。实时实验表明,新兴趣的探索和用户对平台的整体享受度都有显著提升。未来的工作将重点关注考虑长期效应,以进一步改进使用LLMs进行推荐系统的分层规划。
二、论文 的简单介绍
2.1 论文的背景
推荐系统在帮助用户导航如今网络上庞大且不断增长的内容方面不可或缺。然而,这些系统往往受到强烈的反馈循环的影响,推荐与用户过去行为相似的物品。经典推荐系统根据用户的历史交互推断其下一个兴趣。虽然这对短期参与可能有效,但它限制了用户发现新兴趣,导致内容疲劳。最近的研究强调了用户兴趣探索的重要性,旨在引入超出用户历史偏好的多样化内容。然而,由于兴趣空间的广阔和用户对先前未见兴趣的亲和力的高度不确定性,有效地向用户引入新兴趣是具有挑战性的。
近期在大语言模型(LLMs)和其他基础模型方面的突破为革新推荐系统提供了机遇。这些模型中预训练的世界知识有可能通过引入多样化和偶然的推荐来打破推荐反馈循环,解决用户兴趣探索的挑战。尽管先前的工作已经展示了通过将推荐问题转化为自然语言处理任务来使用LLMs进行推荐的潜力,但在现实世界的工业推荐系统中部署这些方法仍然极其挑战,原因如下:
(1) 与领域特定的推荐模型不同,LLMs缺乏对工业规模在线平台上大规模且快速演变的物品库(例如,YouTube每分钟上传超过500小时的内容,Spotify每秒上传一首新曲目[18])的深入了解;
(2) 现成的LLMs不了解用户的协作信号,无法捕捉领域特定的用户行为;
(3) 为每个用户请求服务的LLMs的延迟和成本巨大,无法满足工业推荐平台预期的O(100ms)响应时间和生产查询每秒(QPS)要求。
为了克服上述挑战,论文引入了一种结合LLMs和经典推荐模型的混合层次规划范式(如图1所示),用于大规模推荐系统中的用户兴趣探索。
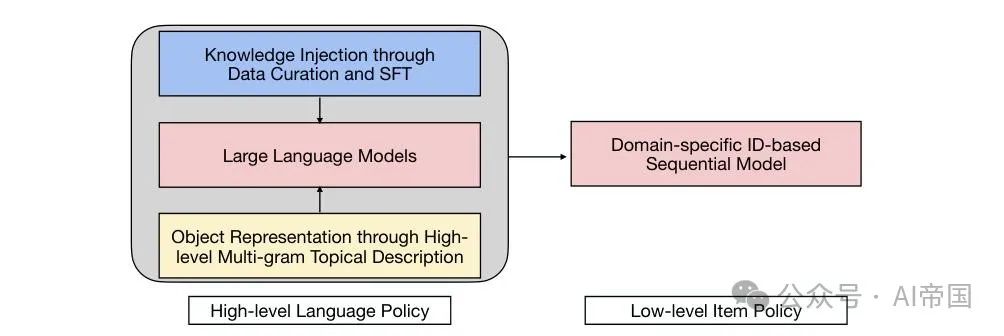
为了表示动态用户兴趣并将昂贵的LLM推理转移到离线阶段,使其可行地在线提供LLM生成的新的兴趣转换。
2.2 论文的方法
这里论文将介绍混合层次规划范式以及为实现受控生成和用户行为对齐而设计的LLM微调过程,以将LLMs应用于现实世界的大规模推荐系统中。

2.2.1 预备知识
在线平台上物品数量庞大且新物品不断涌入,使得在个体物品层面进行LLM规划变得不可行。因此,论文利用LLM在物品兴趣层面的规划能力来缩小规划空间。高效层次规划的前提是一组高质量的物品兴趣集群,其中每个集群内的物品在主题上是一致的。遵循与[6]相同的程序,论文根据物品的主题一致性将其分组为N个流量加权的等尺寸集群,这种方法已被证明能很好地扩展到论文问题的规模。
为了创建这些集群,论文首先根据物品的元数据(标题、标签等)和内容(帧和音频)将其表示为256维嵌入。然后,论文根据相似性在图中连接物品并将其聚类为流量平衡的集群。这个聚类过程重复多次以创建一个4级树结构,每个物品与不同的树级相关联。更高级别的集群代表更广泛的主题,而更低级别的集群代表更具体的主题。
2.2.2 混合层次规划
混合方法结合了LLM产生语言策略,生成高层级的新兴趣,以及经典推荐模型产生物品策略,将