1
引言
每一个使用 kotlin 的同学,或多或少都会使用 Lazy , 其中文翻译名为 延迟初始化 。
作用也相对直接,如果我们有某个对象或字段,我们可能只想使用时再初始化,此时就可以先声明,等到使用时再去初始化,并且这个初始化过程默认也是线程安全(不特定使用NONE)。这样的好处就是性能优势,我们不必应用或者页面加载时就初始化一切,相比过往的 var xx = null ,这种方式一定程度上也更加便捷。
2
目录
-
Lazy 使用方式
-
Lazy 内部源码设计解析
-
Lazy 使用场景推荐
-
如何简化日常开发
3
常见用法
在最开始之前,我们先看看最简单的用法:
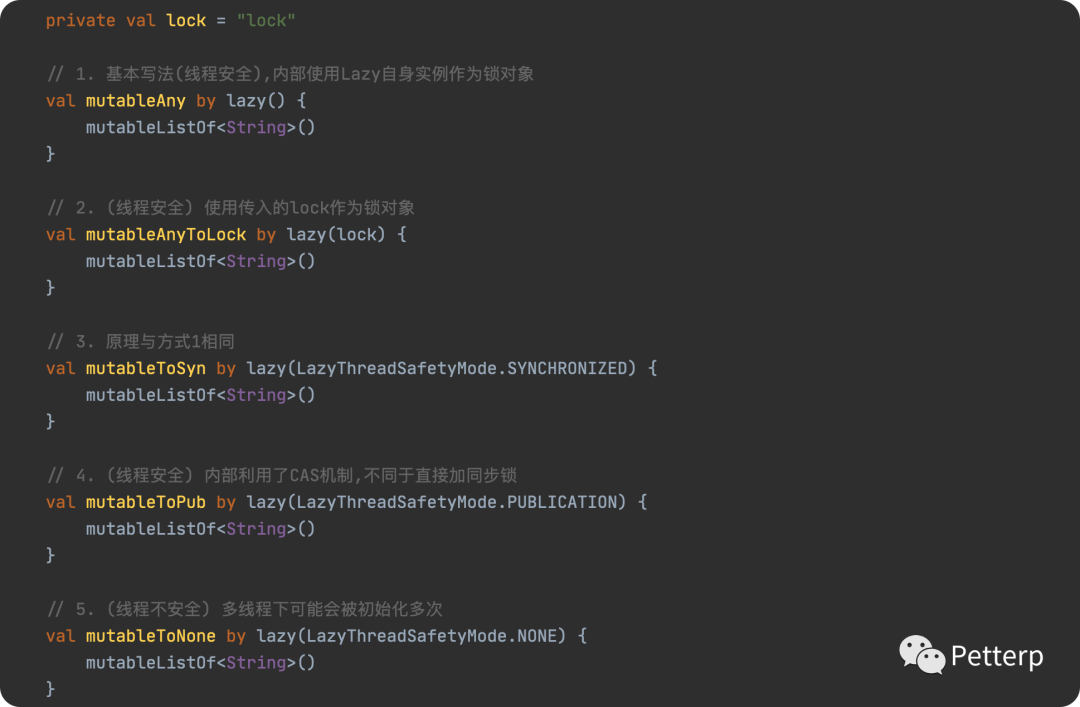
我们在上面演示了5种使用方式。日常我们可能见过或者用的最多就是方式1或者方式3, 但相对而言我个人用的比较多的是方式4和5,主要是其相比其他更适合常见的场景,这个在后文会提到为什么,先不做过多赘述。
仔细观察我的注释,虽然一共有5种使用方式,但其实主要就三种,为什么呢?如下图具体源码所示:
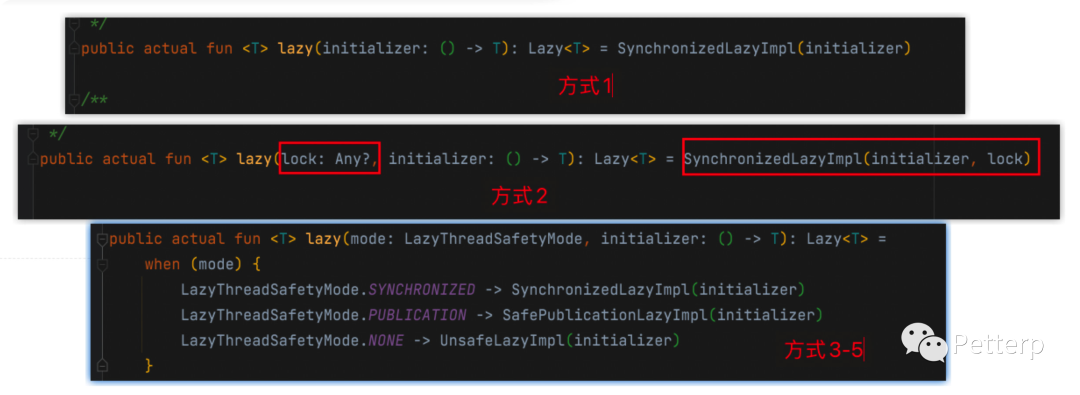
所以我们源码解析的话主要去看后者 LazyThreadSafetyMode 相关对应的这三个类即可。
-
SynchronizedLazyImpl
-
SafePublicationLazyImpl
-
UnsafeLazyImpl
最终的实现原理上也即 对象锁 ,CAS , 默认实现 三种方式,我们接下来顺着源码一起来看看吧。
4
源码解析
我们先看看其最常见的Lazy接口:
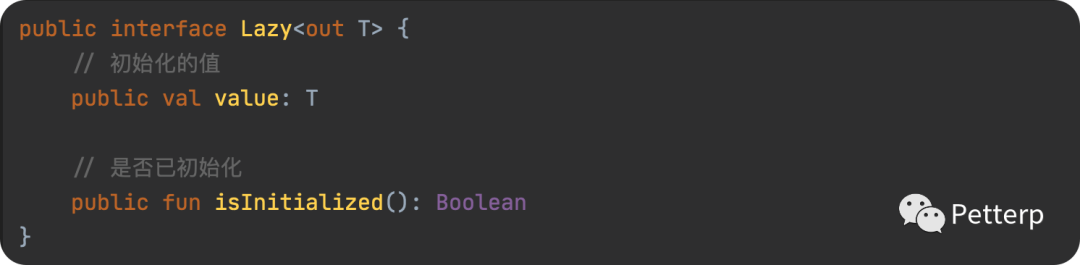
Lazy有三个具体实现,也就是我们上面提到的, 所以我们分别去看他们三个对应的源码 - >
SYNCHRONIZED
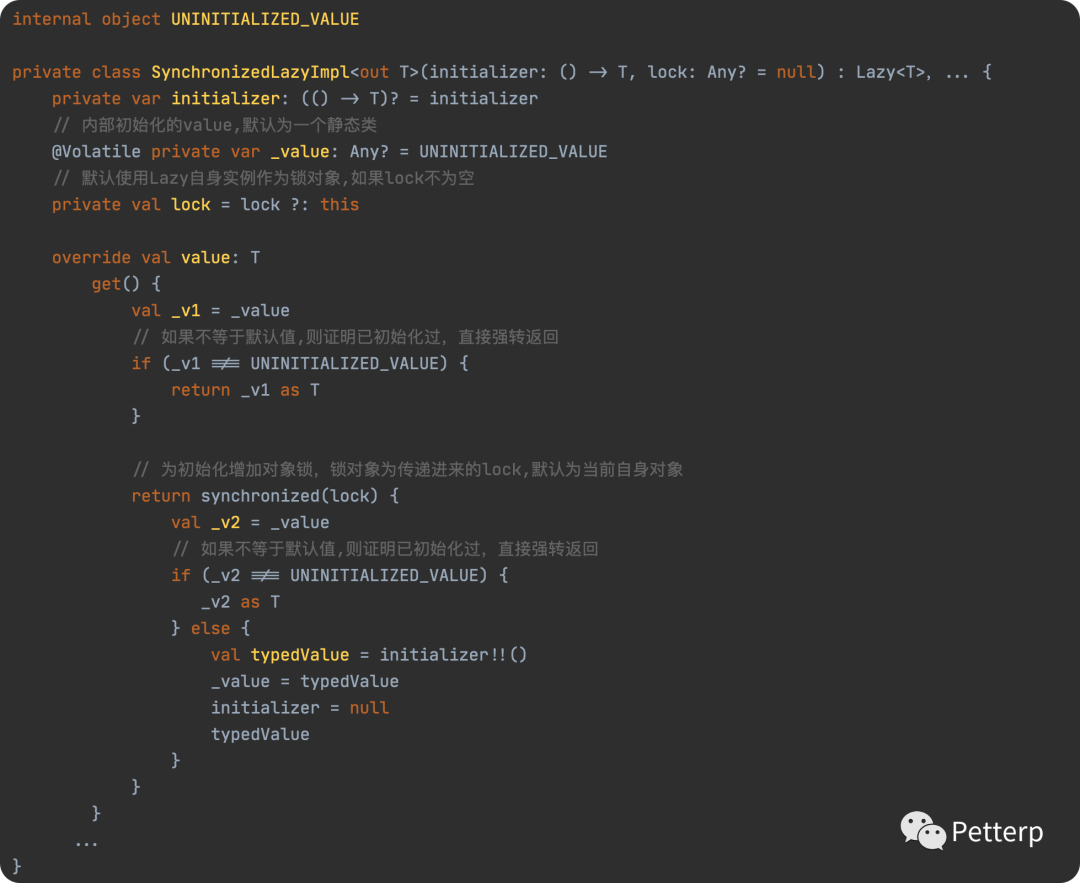
即 SynchronizedLazyImpl ,具体如下:
用一个例子来详细说说过程,比如如下代码:

当我们调用 mutableToSyn 时,我们其实调用的是 Lazy.value ,而 此时 Lazy 的实现类为 SynchronizedLazyImpl ,所以我们实际上是调用到了上述 value 实现。
然后 get() 方法里会先进入一个对象锁区域,锁的对象正是我们传入的 lock (没传入的话使用Lazy自身对象)。因为这里加了锁,所以就算此时有多个线程同时调用 get() 方法,也不存在线程安全问题。然后 get() 里面会判断当前是否已经初始化,是就返回,否则就调用我们自己传入的回调函数去初始化。
PUBLICATION
即 SafePublicationLazyImpl ,相对 SynchronizedLazyImpl ,细节方面会有一些需要注意的,具体如下:
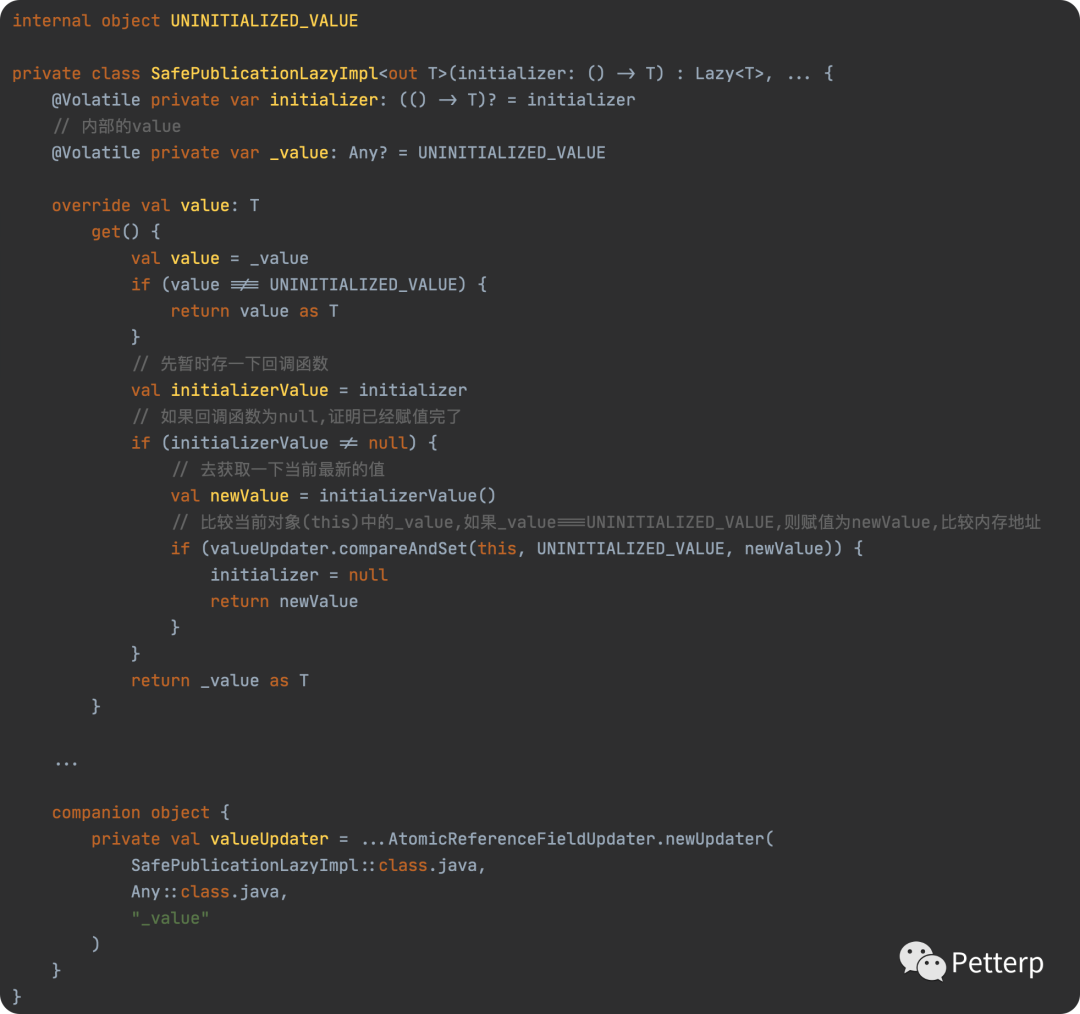
用一个例子来详细说说过程,比如如下代码:

当我们调用 mutableToPub 时,我们其实调用的是 Lazy.value ,而 此时 Lazy的实现类为 SafePublicationLazyImpl ,所以我们实际上是调用到了上述 value 实现。
get() 里面会先判断 _value 是否已经不是默认值,如果不是,则直接返回,证明已经被初始化了;否则就判断初始化函数是否为 null ,如果为null,证明已经被人初始化过了,则直接返回 _value, 否则先去调用一下函数,获得初始化的值 newValue ,然后使用 valueUpdater.compareAndSet 以 CAS 的方式去更新 _value 的值,如果当前 _value 与预期的 UNINITIALIZED_VALUE 相等,则设置 _value 为新的 newValue,然后将初始化函数置 null。
疑问解析
-
为什么 initializer 与 _value 要增加 Volatile 修饰?
-
为什么要使用 AtomicReferenceFieldUpdater.compareAndSet 去更新 ?
我相信不少同学会存在这样的疑问(如果没有那为自己鼓鼓掌)。如果我们看 SynchronizedLazyImpl 内部,会发现 Volatile 也修饰了 _value ,那为什么呢?
所以下面就上面的这两个问题,我们开始将时间线拨回当年学习java锁的时候 - >:
我们知道,每个线程都拥有自己的工作内存,以便提高效率。而线程内部的操作过程也主要是以工作内存为主,在工作内存中的更改会在后续才会刷新到主存,而这个刷新时机是 不定 的,也就是说在多线程情况下,很可能A线程的更改,B线程那边此时无法及时得知。
比如现在存在 线程A 与 线程B :
线程A此时要读取变量sum,其首先去主存中获取该变量,然后存到自己的工作内存里作为一个副本,以后线程A的所有读取都会直接读取自己工作内存里的。如果此时线程A要修改变量sum,同样也是先对工作内存中的副本做更改,然后再刷新到主存里,但至于什么时候写入主存中,无法保证。而线程B 此时去读取这个变量,可能获取的 还是原来的值 ,这就导致了如果线程B也有自增逻辑,那么就会导致不一致。这也是我们常说的 可见性 问题。
那为了解决这个问题,我们经常会采用如下两种解决方式,即 synchronized 或者 volatile 。
synchronized 可以保证同一时刻只有一个线程获取锁,在释放锁时会将当前变量的修改主动刷新到主存,所以避免了上述问题。但相对,这样的方式就需要就需要阻塞其他线程。所以在某些场景下我们也可以用另一种方式,比如读多写少的场景时,因为如果每次读取都是经过加锁,可能对我们性能会有所影响,而 volatile 在这种场景就可以避免这个问题。
当我们在多线程情况下修改 volatile 修饰的变量时,其会第一时间刷新到主存中,并且对于所有线程都是可见,当其他线程操作时,对于 volatile 修饰的,每次操作都需要先去主存中去取一下最新的,然后再进行操作,这就避免了阻塞线程所导致的性能问题。但需要注意的是,volatile 并不保证 原子性 ,其可以保证可见性及抑制指令 重排序(默认情况下编译器会对我们的代码进行优化,将某些步骤进行调整,多线程情况可能会影响我们最终效果,抑制重排序即禁止编译器的优化)。
什么是原子性?
原子性就是指该操作是不可再分的。不论是多核还是单核,具有原子性的量,同一时刻只能有一个线程来对它进行操作。简而言之,在整个操作过程中不会被线程调度器中断的操作,都可认为是原子性。比如 a = 1,即直接赋值的这种行为,其不依赖其他步骤。
而像这种 a++ 的就不属于,因为其步骤如下:
需要先取出a的值
然后再进行+1
然后再写入
上述三个步骤步步相连,如果此时两个线程同时操作,A线程在执行步骤1后,而B线程此时刚好完成了整个步骤,此时A的值就相当于旧值,那么接下来的自增与赋值就已经与我们原有的逻辑不一致。
所以如果我们去看上述的判断逻辑:

如果不使用 compareAndSet ,那这里我们大概率会写出这样的代码:
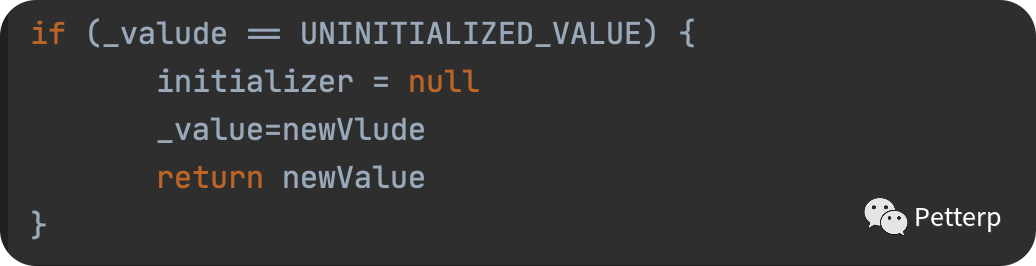
先比较 _value 是不是默认值 UNINITIALIZED_VALUE
是就设置为新值 newValue
但上述过程显然不是一个原子操作,即我们没法保证在执行完 判断逻辑 时, 赋值时会不会被打断,很可能已经有其他线程赋值了,此时就存在了与预期不一致的情况。
所以这里使用 AtomicReferenceFieldUpdater.compareAndSet ,而 AtomicReferenceFieldUpdater 是 jdk 为我们提供的以原子操作去更新指定对象字段方式。其中 compareAndSet 方法的主要逻辑如下:
主要是利用了CAS机制。我们去查找当前对象,也就是内存中 _value 的预估值是否为 UNINITIALIZED_VALUE 默认值,如果操作时,发现 这个要实际操作的值真的是 UNINITIALIZED_VALUE ,也就是当前资源并没有其他线程占用 ,那么我们就将其更新为 newValue 。否则如果发现这个值已经不是 UNINITIALIZED_VALUE , 则 放弃此次操作 。
小彩蛋:为什么这里要使用 AtomicReferenceFieldUpdater ,而不是 AtomicReference?
具体见此:
AR源码里面,本质也有一个private volatile V value; 存在,这两者的差异点主要在于AR本身是要指向一个对象的,也就是要比ARFU多创建一个对象,而这个对象的头(Header)占12个字节,它的成员(Fields)占4个字节,也就比ARFU要多出来16个字节,这是对于32位的是这种情况,如果是64位的话,你启用了-XX:+UseComparessedOops 指针压缩的话,那么Header还是占用12个字节,Fields也还是占用4个字节,但如果没有启用指针压缩的话,那么Header是占16个字节,Fields占用8个字节,总共占用24个字节,那么就说明每创建一个AR都会多出来这么多的内存,那么对GC的压力就有很大的影响了。
NONE
即 UnsafeLazyImpl ,具体如下:
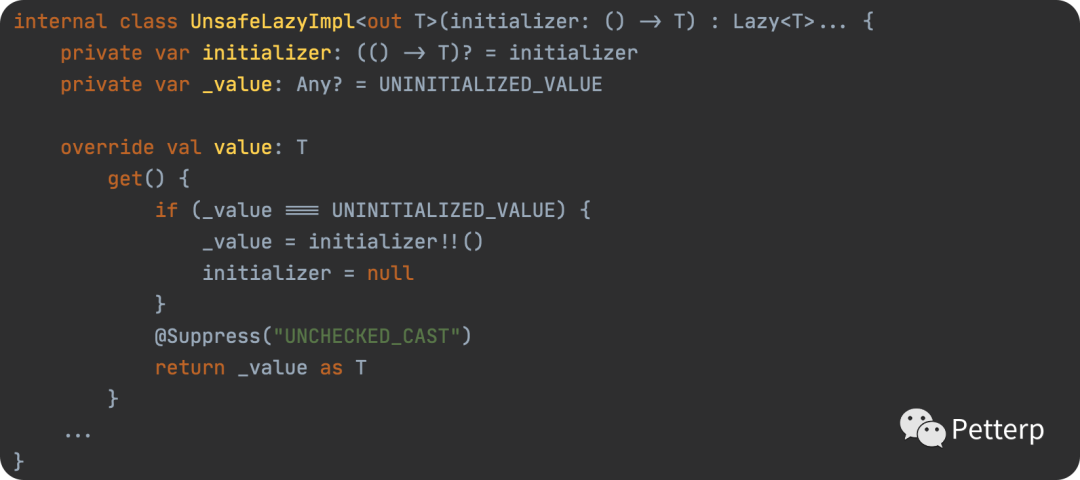
UnsafeLazyImpl
具体也没什么说的,首先判断 value 是否等于默认值,如果是,则调用初始化逻辑,否则返回。
因为没有做任何线程安全的处理,所以必须其调用位置必须是线程安全,否则多线程下调用很可能会造成多次初始化导致逻辑问题。
5
使用建议
分析完上面几种,其实我们不难发现,上述三种都有其各自的不同场景。
-
SYNCHRONIZED
线程安全 比如有某个变量,可能会被多个线程同时调用,而且你不接受初始化函数可能会调用多次,所以可以使用此方法,但需要注意的是,因为get时其内部使用了对象锁,所以在多线程情况下 第一次 调用时,很可能会阻塞我们的其他线程,比如子线程和主线程同时调用,此时子线程先调用到,那主线程此时就会被阻塞,虽然这个时机其实一般而言很短(主要取决于内部逻辑),但也仍需要注意。
-
PUBLICATION
线程安全 但是相比前者,你可以接受 你的初始化函数可能被调用多次 ,但并不影响你最终的使用,因为只有第一个初始化结果的才会被返回,并不影响你的逻辑,所以一般情况下,如果不在意上述问题,我们可以尽量采用这种方式去编写线程安全代码。以避免调用get加锁导致初始化性能损耗。
-
NONE
非线程安全 使用此方式,需要注意在线程安全的情况下调用,否则多线程下很可能造成多个初始化变量,导致不同的线程初始时调用的对象甚至不一致,造成逻辑问题。但其实对于 Android 开发而言,这种反而是比较常见的用途,与我们打交道的往往都是主线程,比如我们可以用在Activity 或者 Fragment 中去 lazy 一些字段等。
6
扩展使用
Fragment-Bundle
对于一个项目而言,都有标准的key传递,所以可以根据标准化的传递方式。
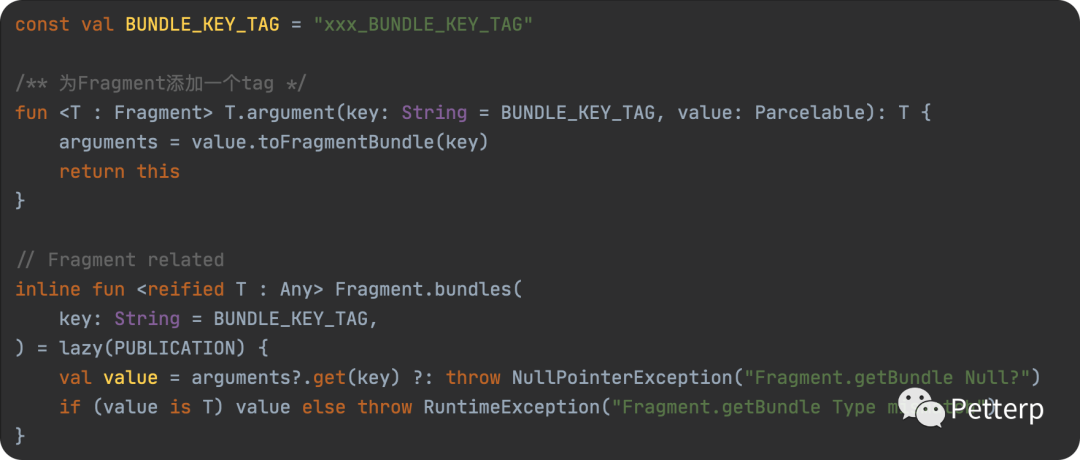
fragment-bundle-simple
使用时:
private val searchKey by bundles<SearchUserKey>()
Rv-Adapter
我们项目中常见会去使用 BaseQuickAdapter ,那如何利用 lazy 优化呢,一个简单思路如下:


综合,我们不难发现,通过扩展函数或者定义顶级函数,然后只需要返回 lazy{} ,即可以为我们的通用业务代码或者组件写出较为优雅的代码,示例如下,具体玩出怎样的花样,就看大家各自的兴趣了。
参考
Kotlin Lazy — What are they? How to use them?
https://medium.com/@kiitvishal89/kotlin-lazy-know-them-inside-out-94ab4de1676d
为什么volatile不能保证原子性而Atomic可以?
https://www.cnblogs.com/Mainz/p/3556430.html
volatile为什么不能保证原子性?
https://www.zhihu.com/question/329746124
AtomicReference和AtomicReferenceFieldUpdater有何异同?
https://apkok.github.io/2021/04/26/%E9%9D%A2%E8%AF%95%E9%A2%98%E5%8D%81%EF%BC%9AAtomicReference%E5%92%8CAtomicReferenceFieldUpdater%E6%9C%89%E4%BD%95%E5%BC%82%E5%90%8C%EF%BC%9F/