前言
这几天看了关于几篇关于大文件上传的文章,都用到了从零实现了大文件上传中的切片上传、断点续传、秒传、暂停等功能,其实既是面试题,也是在实际业务中会用到的功能,今天我就从0开始写一篇关于大文件上传的详细总结,也是借鉴了以下两篇文章的精髓做出的总结。字节跳动面试官:请你实现一个大文件上传和断点续传 、 全网最全面的"大文件上传"
背景
在实际业务中,甲方爸爸突然说:我要上传一个10G的学习资源👲
你:???💀☠👻💩😅
一般情况下,前端上传文件就是new FormData,然后把文件 append 进去,然后post发送给后端就完事了,但是文件越大,上传的文件也就越长,如果在上传过程中,突然被网管拔了网线,又或者电脑突然中木马了,又或者请求超时,等待过久等等情况,十分影响甲方大哥的体验。
所以这时候就要用到大文件上传了,确保能让用户在上传的时候想停就停(暂停功能),就算断网了也能继续接着上传(断点上传),如果是之前上传过这个文件了(服务器还存着),就不需要做二次上传了(秒传)
技术要求
- Web Worker (多线程)
- Vue2 + vue-cli5(基础版功能)
- Vue3 + Vite(完整版功能)
- Node + express (后端简单实现)
根据难易程度我写了两个版本的大文件上传功能,vue2是基础版,只有切片上传功能,不做其他复杂功能处理,而vue3会进行全部功能的实现。这样方便理解的同时,可以根据实际业务需求去封装成组件,满足不同场景的需求,同时我会对涉及到的技术知识点进行进一步的讲解,包括 Web Worker 跟 Node.js。
Web Worker
关于 Web Worker 如果想要了解更多可以先参考阮一峰大佬的 Web Worker 使用教程,以及一些具体用例 一文彻底了解Web Worker。
我们都知道,如果让浏览器中JS有大量计算时,会造成 UI 阻塞,出现界面卡顿、掉帧等情况,严重时还会出现页面卡死等情况(其实很容易触发,例如让你计算十万条数据)。
这时候该怎么办呢?该 Web Worker 登场了,在HTML5的新规范中,实现了 Web Worker 来引入 js 的 “多线程” 技术, 可以让我们在页面主运行的 js 线程中,加载运行另外单独的一个或者多个 js 线程。
总结就是: Web Worker专门处理复杂计算的,从此让前端拥有后端的计算能力
所以 Web Worker 对大文件上传来说有什么用呢?假如我们把 10G 的文件要进行切割成每块1MB的小文件,那岂不是会生成10万个切片,所以这时候就需要用到 Web Worker 了。
具体用法在代码中我会解释,又或者可以参考上面两篇文章(注意 webpack4 跟 webpack5 使用方法不一样,具体要看官方文档使用说明,下面我只针对 vue-cli5 跟 vite 去使用)
前端部分(基础版)
在实现代码之前,先把流程捋一下:首先前端拿到超大文件,需要把文件进行切割分成固定大小的切片,再通过http请求把所有的切片传给后端,后端拿到切片后,处理每一个切片并返回是否处理成功给前端,等把所有的切片都上传完后,后端再把所有的切片合并成一个完整的文件,代表大文件上传完成!
好,那http请求就得用到 axios ,当然你也可以使用原生 XMLHttpRequest 去做请求,以下就直接使用 axios去实现了。
考虑到要把文件切片,那怎么知道每一个文件的唯一标识呢?我们可以用到 speak-md5 去计算文件的hash值。这样如果就算文件同名那它的唯一标识也会不同,又或者文件内容更改后得到的hash值也会不同。
上传进度条
因为是多个切片多个接口请求,那我们怎么判断我们的上传进度呢?有些同学可能会说,onUploadPrigress可以实现接口请求进度,可以通过(e.loaded / e.total) * 100)去计算。但是! onUploadPrigress返回的进度只是文件切片从前端上传到服务器这一过程的进度而已,并不代表上传到服务器就绝对上传成功了!
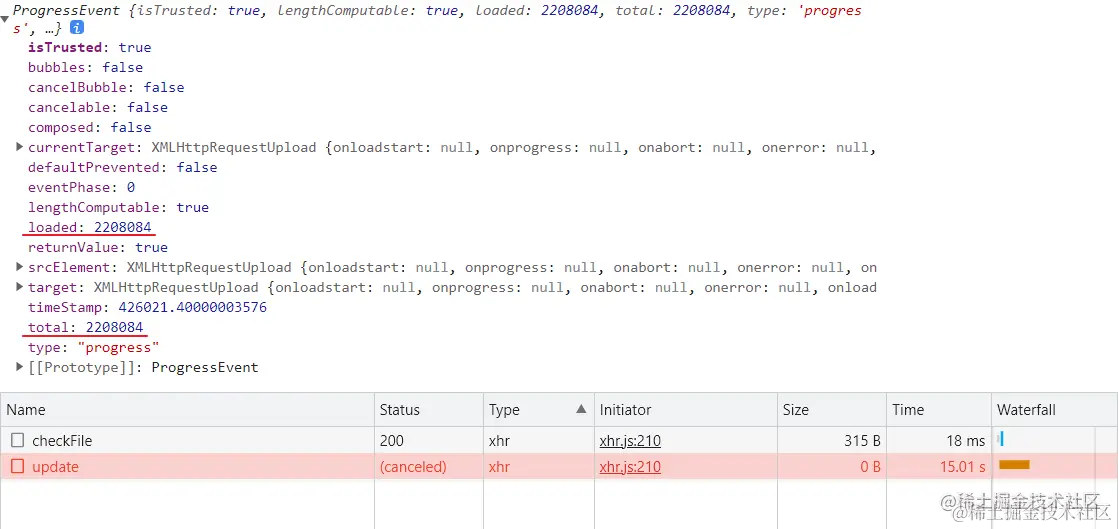
可以看到后端报错造成上传失败,这样计算的进度条也是100%,所以文件完全上传到了服务器 !== 上传成功
但是能不能让后端得到切片并处理完后再返回值通知前端该切片已经上传成功了呢?这样就可以通过 (上传成功的切片数 / 该文件的总切片数) * 100 去计算单个文件的上传进度条
也可以通过 最新进度 = 旧进度 + 100 / 总切片数 去计算。
vue2前端代码实现
切片核心是利用 Blob.prototype.slice 方法,和数组的 slice 方法相似,文件的 slice 方法可以返回原文件的某个切片,同时利用 Web Worker 结合 spark-md5 去计算文件hash值。
因为要用到 spark-md5 ,但是Worker内部需要用 importScripts() 去加载其他脚本,所以需要自行下载spark-md5源码单独作为js文件方便在Worker内部引入。(在github源代码中也有)
在Worker内部引入脚本方式
其实 worker 在内部不仅仅可以使用importScripts()引入脚本,也可以使用ES6的引入方式
将 Worker 脚本作为静态资源:
在public中分别新建 hash-worker.js 跟 spark-md5.min.js 文件,至于为什么要放在在public中,worker需要与主线程的脚本文件同源的网络资源,它是相对于你vue项目中的index.html位置去引入的。
在.vue文件中
const worker = new Worker('./hash-worker.js')
在hash-worker.js中,因为spark-md5跟worker是同目录下,就不需要使用相对路径引入了。
importScripts('spark-md5.min.js')
使用ES6方式引入
在 src 下新建文件夹 worker 再分别新建 hash-worker.js 跟 spark-md5.min.js 文件
其实我们查看 webpack5 (vue-cli5内置webpack5)官方文档就可以看到推荐使用引入方式代替了 worker-loader
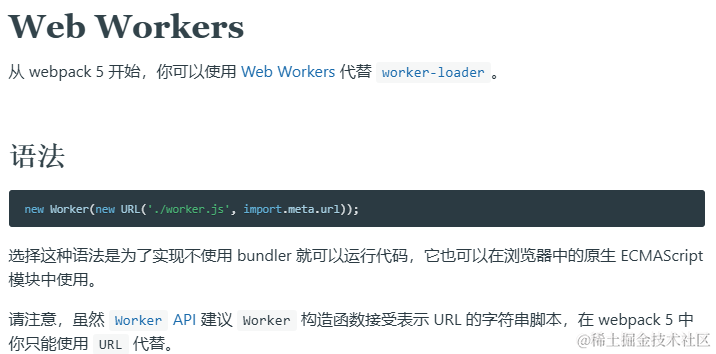
但是在使用importScripts()引入脚本时就不能像第一种用法那样了,不然就会
// .vue文件
const worker = new Worker(
new URL('@/worker/hash-worker.js', import.meta.url)
)
// hash-worker.js
// 第一种写法
importScripts('spark-md5.min.js')
// 第二种写法
importScripts('./spark-md5.min.js')
// 第三种:把spark-md5.min.js放在 public 文件夹下使用以上两种写法
// 第四种:把spark-md5.min.js放在 public 文件夹下
importScripts('/public/spark-md5.min.js')
以上四种写法都会导致发生同一种错误如下,可以看到在worker同源策略下时浏览器读不到spark-md5.min.js文件,但是如果这两个文件都放在public下,再使用import.meta.url是正常读取到的。但这不是我们想要的

在阮一峰教程中可以看到以下评论说明,经验证确实可以成功!

// .vue文件
const worker = new Worker(
new URL('@/worker/hash-worker.js', import.meta.url),
{
type: 'module',
}
)
// hash-worker.js
import SparkMD5 from './spark-md5.min.js'
所以后续的代码都会使用第二种引入方法,如遇到问题可直接使用第一种。
为了UI美观,项目中使用了element-ui组件库,可自行选择
代码实战
考虑到代码可能过长,就不一一解释所有代码,但会在代码中进行注解,重点部分会单独拿出来说明
<template>
<div>
<div class="upload-drag" @click="handleClick">
<input
type="file"
ref="fileInput"
@change="hanldeUploadFile"
accept=""
multiple="false"
style="display: none" />
<div>
<i class="el-icon-upload" style="font-size: 50px; color: #c0c4cc"></i>
</div>
</div>
<div
style="display: flex; margin-top: 10px"
v-for="item in uploadFileList"
:key="item.fileHash">
<div style="width: 300px">
<el-progress
type="line"
:text-inside="true"
:stroke-width="26"
:percentage="item.percentage"></el-progress>
<div>
<div style="margin-left: 4px">
<div
v-if="item.state === 0"
style="height: 24px; width: 100%"></div>
<p v-else-if="item.state === 1">正在解析中...</p>
<p v-else-if="item.state === 2">正在上传中...</p>
<p v-else-if="item.state === 3">上传完成</p>
<p v-else-if="item.state === 4">上传失败</p>
</div>
</div>
</div>
<!-- 在处理文件中时不能取消 -->
<el-button
v-if="![0, 1].includes(item.state)"
style="margin-left: 10px; height: 40px"
type="danger"
@click="cancelUpload(item)"
>取消</el-button
>
</div>
</div>
</template>
<style>
.upload-drag {
width: 150px;
height: 80px;
display: flex;
justify-content: center;
align-items: center;
background: #fff;
border: 1px dashed #d8d8d8;
border-radius: 4px;
cursor: pointer;
overflow: hidden;
transition: border-color 0.2s ease;
}
.upload-drag:hover {
border: 1px dashed #4595eb;
}
</style>
首先我们要定义几个变量,考虑到用户需要多选上传,就直接定义上传列表为数组,以及请求最大并发数
data() {
return {
// 1kb = 1024b 1kb * 1024 = 1M
// 切片大小 1 * 1024 * 1024 刚好1M
chunkSize: 1 * 1024 * 1024,
// 上传文件列表:
uploadFileList: [],
// 请求最大并发数
maxRequest:6
}
},
在点击触发文件上传事件后
methods: {
handleClick() {
// 点击触发选取文件
this.$refs.fileInput.dispatchEvent(new MouseEvent('click'))
},
async hanldeUploadFile() {
const fileEle = this.$refs.fileInput
// 如果没有文件内容
if (!fileEle || !fileEle.files || fileEle.files.length === 0) {
return false
}
const files = fileEle.files
// 多文件
Array.from(files).forEach(async (item, i) => {
const file = item
// 单个上传文件
let inTaskArrItem = {
id: new Date() + i, // 因为forEach是同步,所以需要用指定id作为唯一标识
state: 0, // 0不做任何处理,1是计算hash中,2是正在上传中,3是上传完成,4是上传失败,5是上传取消
fileHash: '',
fileName: file.name,
fileSize: file.size,
allChunkList: [], // 所有请求的数据
whileRequests: [], // 正在请求中的请求个数,目前是要永远都保存请求个数为6
finishNumber: 0, //请求完成的个数
errNumber: 0, // 报错的个数,默认是0个,超多3个就是直接上传中断
percentage: 0, // 单个文件上传进度条
}
this.uploadFileList.push(inTaskArrItem)
// 开始处理解析文件
inTaskArrItem.state = 1
if (file.size === 0) {
// 文件大小为0直接取消该文件上传
this.uploadFileList.splice(i, 1)
// 继续执行for循环
}
// 计算文件hash
const { fileHash, fileChunkList } = await this.useWorker(file)
console.log(fileHash, '文件hash计算完成')
// 解析完成开始上传文件
let baseName = ''
// 查找'.'在fileName中最后出现的位置
const lastIndex = file.name.lastIndexOf('.')
// 如果'.'不存在,则返回整个文件名
if (lastIndex === -1) {
baseName = file.name
}
// 否则,返回从fileName开始到'.'前一个字符的子串作为文件名(不包含'.')
baseName = file.name.slice(0, lastIndex)
// 这里要注意!可能同一个文件,是复制出来的,出现文件名不同但是内容相同,导致获取到的hash值也是相同的
// 所以文件hash要特殊处理
inTaskArrItem.fileHash = `${fileHash}${baseName}`
inTaskArrItem.state = 2
// 初始化需要上传所有切片列表
inTaskArrItem.allChunkList = fileChunkList.map((item, index) => {
return {
// 总文件hash
fileHash: `${fileHash}${baseName}`,
// 总文件size
fileSize: file.size,
// 总文件name
fileName: file.name,
index: index,
// 切片文件本身
chunkFile: item.chunkFile,
// 单个切片hash,以 - 连接
chunkHash: `${fileHash}-${index}`,
// 切片文件大小
chunkSize: this.chunkSize,
// 切片个数
chunkNumber: fileChunkList.length,
// 切片是否已经完成
finish: false,
}
})
// 逐步对单个文件进行切片上传
this.uploadSignleFile(inTaskArrItem)
})
console.log(this.uploadFileList, 'uploadFileList')
},
// 生成文件 hash(web-worker)
useWorker(file) {
return new Promise((resolve) => {
const worker = new Worker(
new URL('@/worker/hash-worker.js', import.meta.url),
{
type: 'module',
}
)
worker.postMessage({ file, chunkSize: this.chunkSize })
worker.onmessage = (e) => {
const { fileHash, fileChunkList } = e.data
if (fileHash) {
resolve({
fileHash,
fileChunkList,
})
}
}
})
},
},
我们要注意的是,计算文件hash是需要时间的,所以我们的文件上传状态也需要改变,从而对每个文件对象定义了state属性,关于allChunkList是用于记录所有需要上传的切片数据(指还未上传的),whileRequests是正在http请求中的个数,finishNumber是记录后端处理完的切片个数,也是方便计算文件上传进度的;errNumber是记录在所有的上传切片列表中,切片上传失败的个数(后面会详细讲)。
如果有细心的同学可以发现,这里用的是
forEach循环,一开始的想法是用for循环 + await,但是发现会出现一个现象:就是只能等一个文件解析完才能进行解析下一个,但是我想要的是,在多文件上传中,直接全部一起解析,哪个文件解析完就开始调上传接口即可,所以这里改用成了forEach。
接下来的重点是对Worker的代码详细说明:
import SparkMD5 from './spark-md5.min.js'
// 创建文件切片
function createFileChunk(file, chunkSize) {
return new Promise((resolve, reject) => {
let fileChunkList = []
let cur = 0
while (cur < file.size) {
// Blob 接口的 slice() 方法创建并返回一个新的 Blob 对象,该对象包含调用它的 blob 的子集中的数据。
fileChunkList.push({ chunkFile: file.slice(cur, cur + chunkSize) })
cur += chunkSize
}
// 返回全部文件切片
resolve(fileChunkList)
})
}
// 加载并计算文件切片的MD5
async function calculateChunksHash(fileChunkList) {
// 初始化脚本
const spark = new SparkMD5.ArrayBuffer()
// 计算切片进度(拓展功能,可自行添加)
let percentage = 0
// 计算切片次数
let count = 0
// 递归函数,用于处理文件切片
async function loadNext(index) {
if (index >= fileChunkList.length) {
// 所有切片都已处理完毕
return spark.end() // 返回最终的MD5值
}
return new Promise((resolve, reject) => {
const reader = new FileReader()
reader.readAsArrayBuffer(fileChunkList[index].chunkFile)
reader.onload = (e) => {
count++
spark.append(e.target.result)
// 更新进度并处理下一个切片
percentage += 100 / fileChunkList.length
self.postMessage({ percentage }) // 发送进度到主线程
resolve(loadNext(index + 1)) // 递归调用,处理下一个切片
}
reader.onerror = (err) => {
reject(err) // 如果读取错误,则拒绝Promise
}
})
}
try {
// 开始计算切片
const fileHash = await loadNext(0) // 等待所有切片处理完毕
self.postMessage({ percentage: 100, fileHash, fileChunkList }) // 发送最终结果到主线程
self.close() // 关闭Worker
} catch (err) {
self.postMessage({ name: 'error', data: err }) // 发送错误到主线程
self.close() // 关闭Worker
}
}
// 监听消息
self.addEventListener(
'message',
async (e) => {
try {
const { file, chunkSize } = e.data
const fileChunkList = await createFileChunk(file, chunkSize) // 创建文件切片
await calculateChunksHash(fileChunkList) // 等待计算完成
} catch (err) {
// 这里实际上不会捕获到calculateChunksHash中的错误,因为错误已经在Worker内部处理了
// 但如果未来有其他的异步操作,这里可以捕获到它们
console.error('worker监听发生错误:', err)
}
},
false
)
// 主线程可以监听 Worker 是否发生错误。如果发生错误,Worker 会触发主线程的error事件。
self.addEventListener('error', function (event) {
console.log('Worker触发主线程的error事件:', event)
self.close() // 关闭Worker
})
如果你已经看过阮一峰大佬的教程,相信对worker的怎么监听消息、发送消息、关闭Worker已经有了初步的了解,但是这样也已经够用了,在worker中我们可以拿到file信息以及需要切片的大小chunkSize,这时候就需要对每个文件进行切片,我们利用Blob.slice进行切割相同等分,并返回全部切片fileChunkList
在拿到fileChunkList我们需要用到spark-md5以增量方式对文件进行哈希处理(在spark-md5文档有说明),最终可以拿到整个文件的hash值,并发送消息回给调用worker的主线程。但是在处理文件hash值赋值的时候要注意,不同文件名但内容相同的文件哈希值是一样的,因为spark-md5是根据文件内容去获取文件哈希,从而导致可能出现同一个哈希值,所以我们在上面处理文件的时候就要特殊处理!
inTaskArrItem.fileHash = `${fileHash}${baseName}`
下面两个压缩包处理后的hash值是一样的

在调用接口上传文件之前我们先对axios进行简单的二次封装,以及封装接口信息
// src/utils/request.js
import axios from 'axios'
// 设置请求头
const myBaseURL = 'http://localhost:3000'
// 创建axios实例
const service = axios.create({
baseURL: myBaseURL, // 请求头
timeout: 6 * 1000, // 请求超时时间
})
// 响应拦截
service.interceptors.response.use(
(response) => {
return response.data
},
(error) => {
return Promise.reject(error)
}
)
export default service
// src/api/index.js
import service from '@/utils/request'
/**
* [uploadFile] - 上传切片参数
* @param fileHash 文件hash,String
* @param fileSize 文件大小,Number
* @param fileName 文件名称,String
* @param index 多文件上传中的所在index,number
* @param chunkFile 切片文件本身,File || Blob || void
* @param chunkHash 切片文件hash,String
* @param chunkSize 分片大小,Number
* @param chunkNumber 切片总数量,Number
* @param finish 是否上传完成,可选参数,Boolean
* @returns 返回值描述(如果有的话)
*/
// 上传单个切片
export function uploadFile(data) {
// 封装 axios 请求或 HTTP 客户端请求
return service({
url: '/upload',
method: 'post',
data,
})
}
/**
* [mergeChunk] - 合并切片
* @param chunkSize 分片大小,Number
* @param fileName 文件名称,String
* @param fileSize 文件大小,Number
*/
// 合并所有切片
export function mergeChunk(data) {
return service({
url: '/merge',
method: 'post',
data,
})
}
浏览器同域名同一时间请求的最大并发数
在处理完上面的代码后,我们就可以开始上传了,但是上传切片之前要普及一个知识点,在Chrome浏览器中同域名同一时间请求的最大并发数为6个,一开始是打算使用for循环或者Promise.all()并发请求几百个接口,感觉这样效率高一些,后来发现文件小没事,大了请求直接不响应了,例如15个切片15个请求浏览器会感觉有点卡顿, 几百上千个切片请求瞬间浏览器卡死或者接口超时自动取消!
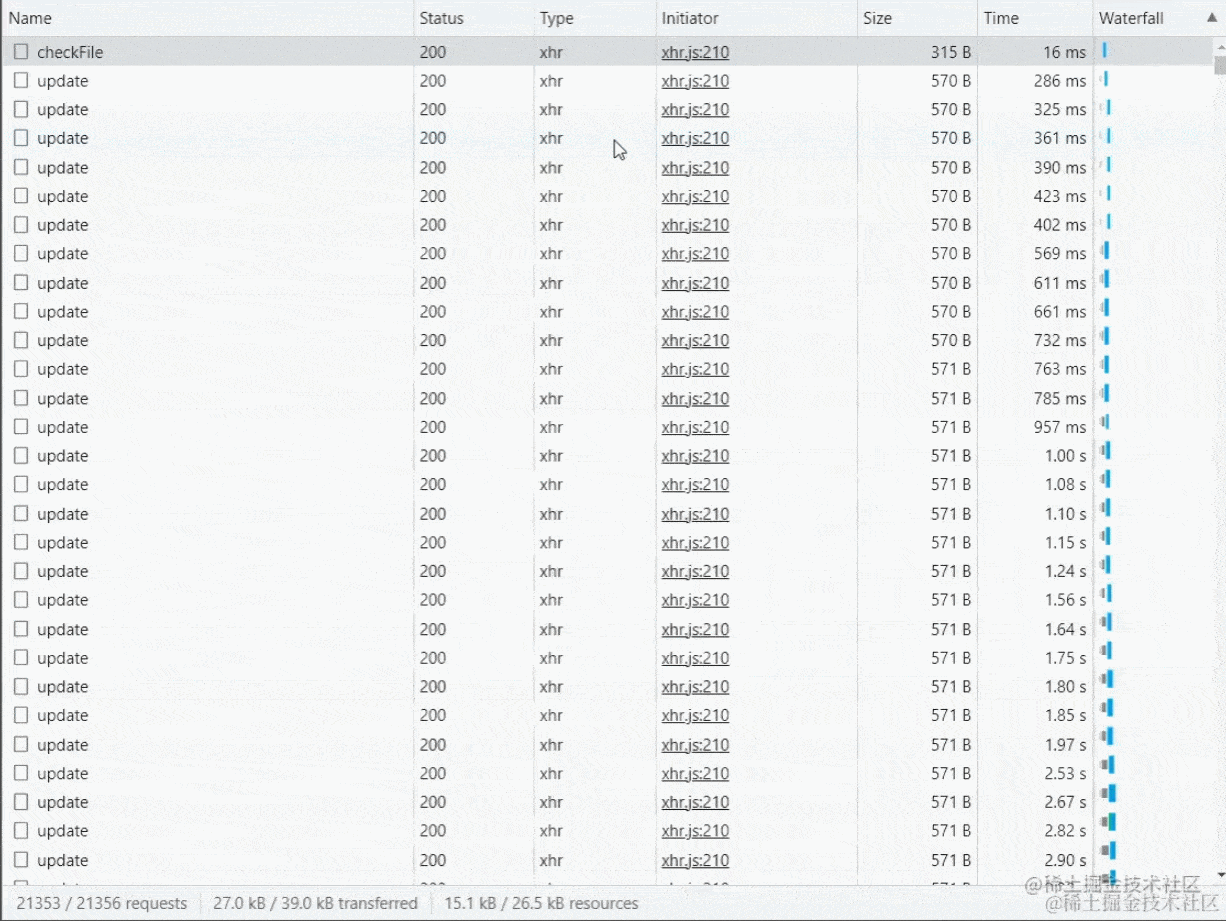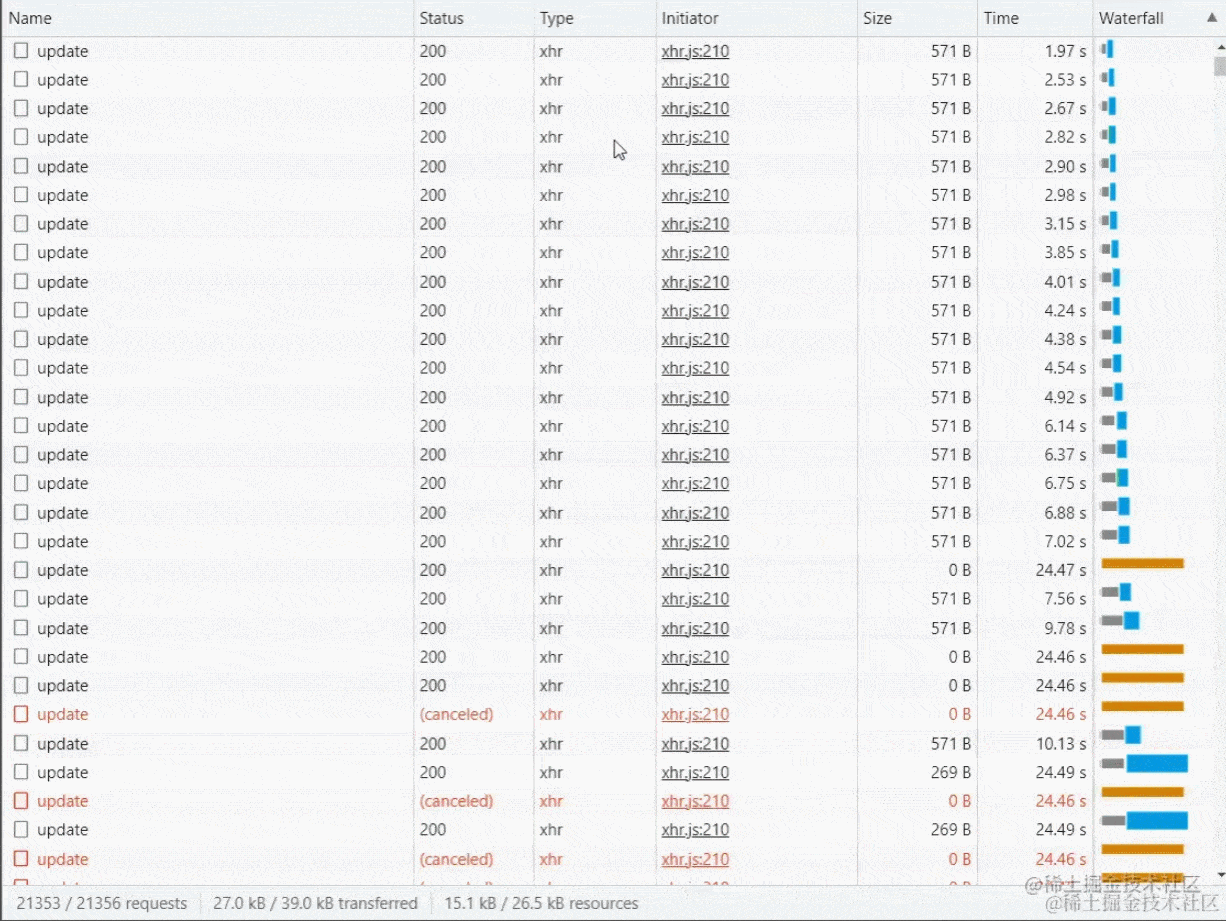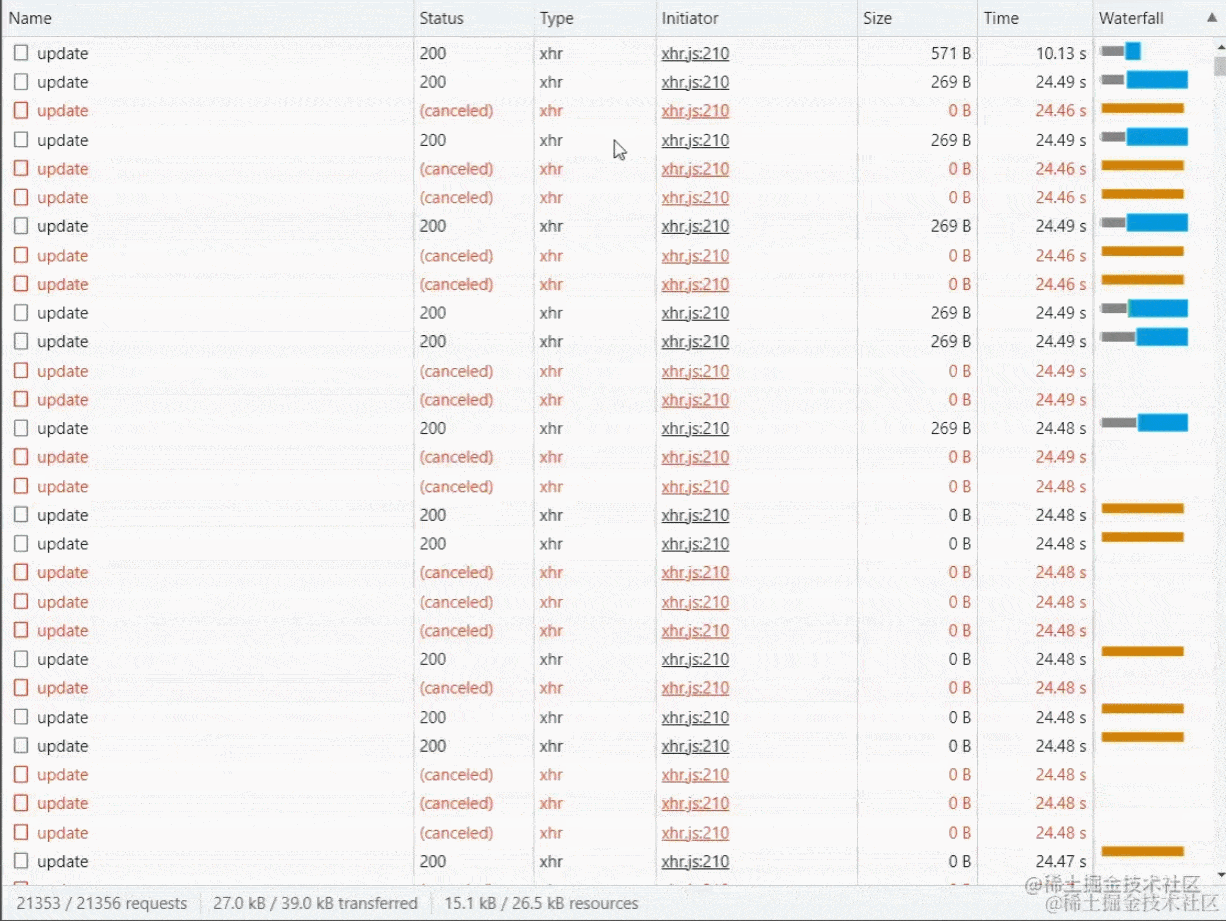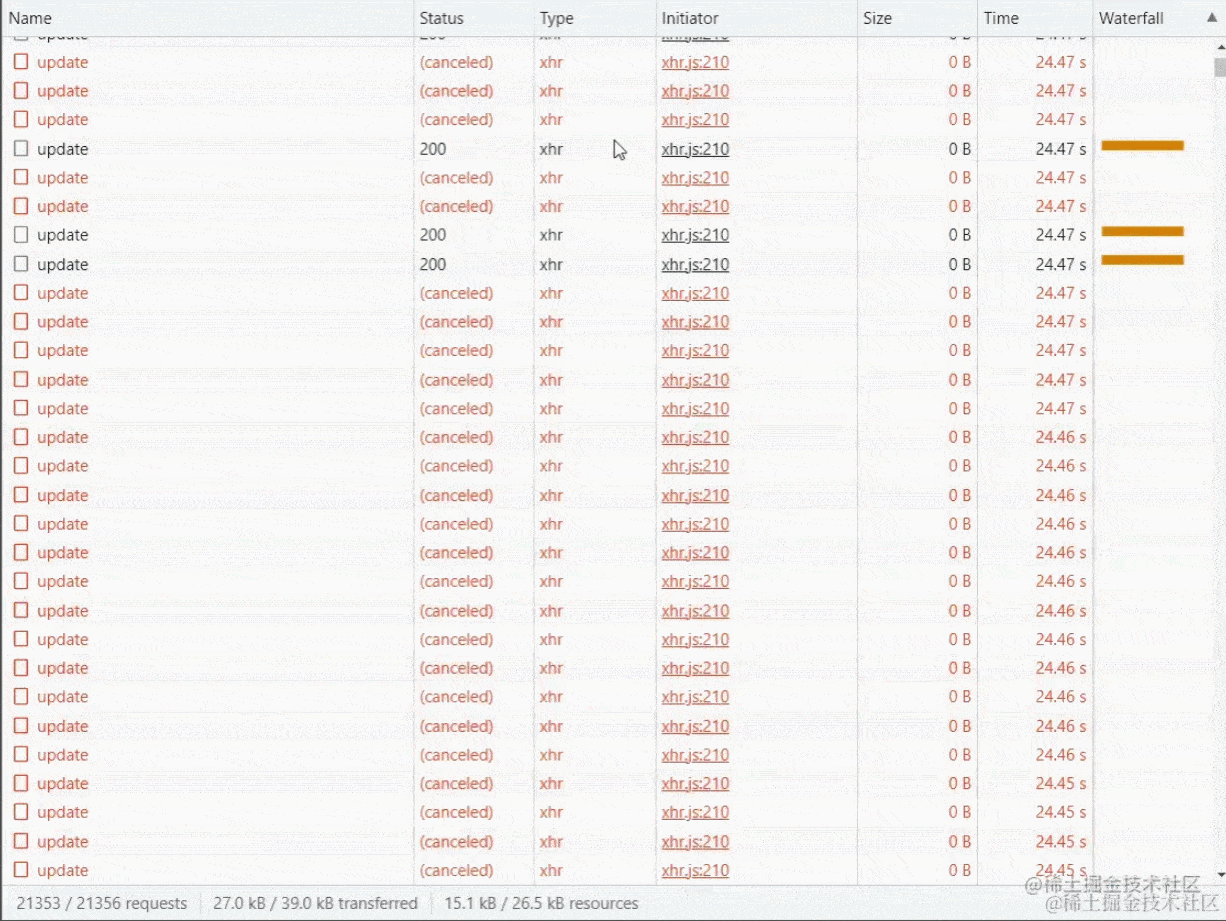
所以我们刚才定义的maxRequest就派上用场了,同时要注意的是要使用for循环搭配await去使用(forEach是没有异步效果以及中断的)
// 单个文件上传
uploadSignleFile(taskArrItem) {
// 如果没有需要上传的切片 / 正在上传的切片还没传完,就不做处理
if (
taskArrItem.allChunkList.length === 0 ||
taskArrItem.whileRequests.length > 0
) {
return false
}
// 找到文件处于处理中/上传中的 文件列表(是文件而不是切片)
const isTaskArrIng = this.uploadFileList.filter(
(itemB) => itemB.state === 1 || itemB.state === 2
)
// 实时动态获取并发请求数,每次调请求前都获取一次最大并发数
// 浏览器同域名同一时间请求的最大并发数限制为6
// 例如如果有3个文件同时上传/处理中,则每个文件切片接口最多调 6 / 3 == 2个相同的接口
this.maxRequest = Math.ceil(6 / isTaskArrIng.length)
// 从数组的末尾开始提取 maxRequest 个元素。
let whileRequest = taskArrItem.allChunkList.slice(-this.maxRequest)
// 设置正在请求中的个数
taskArrItem.whileRequests.push(...whileRequest)
// 如果总请求数大于并发数
if (taskArrItem.allChunkList.length > this.maxRequest) {
// 则去掉即将要请求的列表
taskArrItem.allChunkList.splice(-this.maxRequest)
} else {
// 否则总请求数置空,说明已经把没请求的全部放进请求列表了,不需要做过多请求
taskArrItem.allChunkList = []
}
// 单个分片请求
const uploadChunk = async (needObj) => {
const fd = new FormData()
const {
fileHash,
fileSize,
fileName,
index,
chunkFile,
chunkHash,
chunkSize,
chunkNumber,
} = needObj
fd.append('fileHash', fileHash)
fd.append('fileSize', String(fileSize))
fd.append('fileName', fileName)
fd.append('index', String(index))
fd.append('chunkFile', chunkFile)
fd.append('chunkHash', chunkHash)
fd.append('chunkSize', String(chunkSize))
fd.append('chunkNumber', String(chunkNumber))
const res = await uploadFile(fd).catch(() => {})
// 先判断是不是取消状态,就什么都不要再做了,及时停止
if (taskArrItem.state === 5) {
return false
}
// 请求异常,或者请求成功服务端返回报错都按单片上传失败逻辑处理,.then.catch的.catch是只能捕捉请求异常的
if (!res || res.code === -1) {
// 切片上传失败+1
taskArrItem.errNumber++
// 超过3次之后直接上传中断
if (taskArrItem.errNumber > 3) {
console.log('切片上传失败超过三次了')
// 标识文件上传失败
taskArrItem.state = 4
} else {
console.log('切片上传失败还没超过3次')
uploadChunk(needObj) // 失败了一片,继续当前分片请求
}
} else if (res.code === 0) {
// 单个文件上传失败次数大于0则要减少一个
taskArrItem.errNumber > 0 ? taskArrItem.errNumber-- : 0
// 单个文件切片上传成功数+1
taskArrItem.finishNumber++
// 单个切片上传完成
needObj.finish = true
// 单个文件上传成功后就要更新文件进度条
this.signleFileProgress(needObj, taskArrItem) // 更新进度条
// 上传成功了就删掉请求中数组中的那一片请求
taskArrItem.whileRequests = taskArrItem.whileRequests.filter(
(item) => item.chunkFile !== needObj.chunkFile
)
// 如果单个文件最终成功数等于切片个数
if (taskArrItem.finishNumber === chunkNumber) {
// 全部上传完切片后就开始合并切片
await this.handleMerge(taskArrItem)
} else {
// 如果还没完全上传完,则继续上传
this.uploadSignleFile(taskArrItem)
}
}
}
// 开始上传单个切片
for (const item of whileRequest) {
uploadChunk(item)
}
},
代码解析:在上传前要判断如果还未上传列表为空 || 部分正在上传的切片请求还在请求,则不做处理(或等待正在上传的切片上传完)。
同时要动态设置最大并发数,例如如果有3个文件同时上传/处理中,则每个文件切片接口最多调 6 / 3 == 2个相同的接口。
设置正在上传的请求列表,并把在未上传切片列表中的相对应数据删除,如果把没请求的全部放进请求列表了,则要把未上传切片列表置空。
开始循环调上传接口,但是如果中途取消了某个文件上传,取消状态则不要做任何处理,及时停止
假设在某个切片在上传过程中,突然被网管拔了网线又或者请求超时等,可能会导致某个上传失败/丢失。那怎么办?我们可以选择继续上传该切片,如果连续三次失败则判定该文件上传失败。
所以我们就得以后端是否处理成功并返回为标准,防止出现切片丢失等问题,并把该切片标识为上传完成,文件切片上传成功数+1,并动态设置文件上传进度条。
那我们可以根据 文件切片上传成功数 === 文件总切片数 判断文件是否已经把所有切片上传完成,然后调接口通知后端,让后端去合并所有的切片并通知前端是否合并完成,这就代表了该文件完全上传成功!
// 调取合并接口处理所有切片
async handleMerge(taskArrItem) {
const { fileName, fileHash } = taskArrItem
const res = await mergeChunk({
chunkSize: this.chunkSize,
fileName,
fileHash,
}).catch(() => {})
// 如果合并成功则标识该文件已经上传完成
if (res && res.code === 0) {
// 设置文件上传状态
this.finishTask(taskArrItem)
console.log('文件合并成功!')
} else {
// 否则上传文件失败
taskArrItem.state = 4
console.log('文件合并失败!')
}
// 最后赋值文件切片上传完成个数为0
taskArrItem.finishNumber = 0
},
// 更新单个文件进度条
signleFileProgress(needObj, taskArrItem) {
taskArrItem.percentage = Number(
((taskArrItem.finishNumber / needObj.chunkNumber) * 100).toFixed(2)
)
},
// 设置单个文件上传已完成
finishTask(item) {
item.state = 3
item.percentage = 100
},
cancelUpload(item) {
item.state = 5
// 取消上传后删除该文件
this.uploadFileList = this.uploadFileList.filter(
(itemB) => itemB.fileHash !== item.fileHash
)
},
以上代码就可以实现前端的大文件切片上传功能了!
Node后端(基础版)
到了对于node不太熟悉的同学比较苦恼的地方了(例如我),但通过艰苦的学习后,需要用到的插件有:express(node框架,在这里主要用于简单的http请求)、fs-extra(代替node内置fs,主要用于处理文件的写入、读取、删除等)、multiparty(用于处理前端传过来的formData参数等)、nodemon(用于自动重启Node服务器及响应代码更改,不然你改一次代码就得重新启动一次)
代码实战
前置工作
新建一个node-server文件夹,里面再分别以及一个v2-file-upload.js跟package.json,以及一个target文件夹(用于保存文件),
package.json
{
"name": "node-server",
"version": "1.0.0",
"description": "处理前端大文件上传",
"main": "index.js",
"scripts": {
"dev:v2": "nodemon v2-file-upload.js",
},
"author": "",
"license": "ISC",
"dependencies": {
"express": "^4.19.2",
"fs-extra": "^11.2.0",
"multiparty": "^4.2.3"
},
"devDependencies": {
"nodemon": "^3.1.3"
}
}
v2-file-upload.js
// v2-file-upload.js
const express = require('express')
const app = express()
const port = 3000
const path = require('path')
const fse = require('fs-extra')
const multiparty = require('multiparty')
app.use((req, res, next) => {
// 请求头允许跨域
res.setHeader('Access-Control-Allow-Origin', '*')
res.setHeader('Access-Control-Allow-Headers', '*')
next()
})
app.options('*', (req, res) => {
res.sendStatus(200)
})
app.listen(port, () => console.log('v2基础大文件上传:监听3000端口'))
app.get('/content', async (req, res) => {
res.send({
code: 0,
msg: '你成功访问了3000端口',
})
})
做完以上工作后,直接在你的端口运行 npm install ,再运行 npm run dev:v2 就可以成功启动Node服务啦!
在
v2-file-upload.js中,主要用express启动一个http服务,并设置了允许跨域,以及设置了对于任何路径上的 HTTP OPTIONS 请求,服务器都会发送一个带有 200 状态码的响应。
成功运行:
访问测试
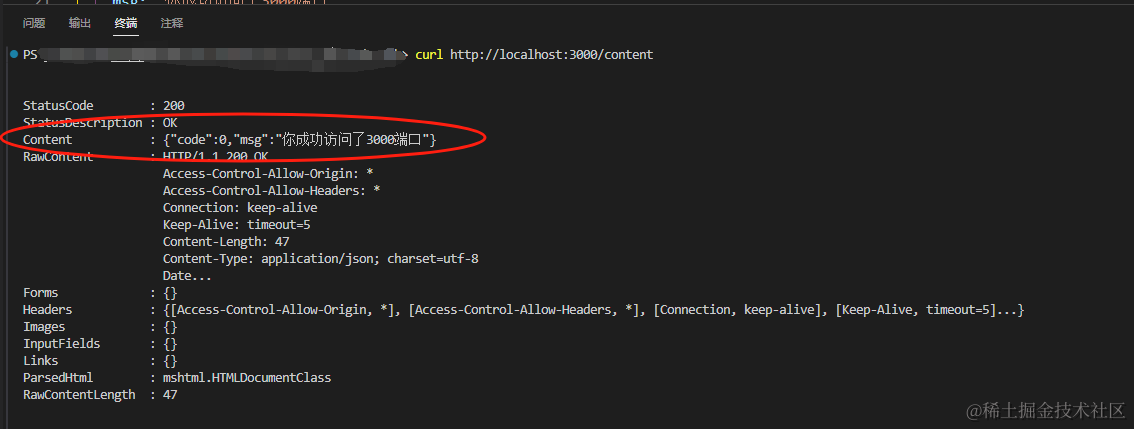
在中断输入:curl http://localhost:3000/content,可以看到以下内容,证明访问成功!
关于跨域访问,可自行在项目中测试即可。
在基础版中只有两个后端接口,/upload 跟 /merge 分别就是上传跟合并接口
/upload 接口
// v2-file-upload.js
// 大文件存储目录
const UPLOAD_DIR = path.resolve(__dirname, 'target')
// 创建临时文件夹用于临时存储 所有的文件切片
const getChunkDir = (fileHash) => {
// 添加 chunkCache 前缀与文件名做区分
// target/chunkCache_fileHash值
return path.resolve(UPLOAD_DIR, `chunkCache_${fileHash}`)
}
// 处理切片上传
app.post('/upload', async (req, res) => {
try {
// 处理文件表单
const form = new multiparty.Form()
form.parse(req, async (err, fields, files) => {
if (err) {
res.send({ code: -1, msg: '单片上传失败', data: err })
return false
}
// fields是body参数
// 文件hash ,切片hash ,文件名
const { fileHash, chunkHash, fileName } = fields
// files是传过来的文件所在的真实路径以及内容
const { chunkFile } = files
// 创建一个临时文件目录用于 临时存储所有文件切片
const chunkCache = getChunkDir(fileHash)
// 检查 chunkDir临时文件目录 是否存在,如果不存在则创建它。
if (!fse.existsSync(chunkCache)) {
await fse.mkdirs(chunkCache)
}
// 将上传的文件切片移动到指定的存储文件目录
// fse.move 方法默认不会覆盖已经存在的文件。
// 将 overwrite: true 设置为 true,这样当目标文件已经存在时,将会被覆盖。
// 把上传的文件移动到 /target/chunkCache_ + chunkHash
await fse.move(chunkFile[0].path, `${chunkCache}/${chunkHash}`, {
overwrite: true,
})
res.send({
code: 0,
msg: '单片上传完成',
data: { fileHash, chunkHash, fileName },
})
})
} catch (errB) {
res.send({ code: -1, msg: '单片上传失败', data: errB })
}
})
我们已经定义了target目录,利用path.resolve解析成可识别的绝对路径,以及我们还要动态新建一个用于缓存文件的所有切片的目录(通过代码)
在上面代码中,我们用 multiparty 去处理文件数据,要注意fields是传过来的参数、 files 是传过来时的文件真实路径及内容,创建一个临时缓存目录,并把真实路径的文件移动到临时缓存目录中,移动完成后再返回上传结果。
/merge 接口
// v2-file-upload.js
// 处理请求参数
// 处理请求参数
const resolvePost = (req) => {
// 所有接收到的数据块拼接成一个字符串,然后解析为 JSON 对象。
return new Promise((resolve) => {
let body = [] // 使用数组而不是字符串来避免大字符串的内存问题
// 监听请求对象 req 的 data 事件。每当有数据块传输过来时,处理程序就会被调用。
req.on('data', (data) => {
// 假设数据是 Buffer,将其追加到数组中
body.push(data)
})
// 监听请求对象 req 的 end 事件。当所有数据块接收完毕时
req.on('end', () => {
// 使用 Buffer.concat 将所有数据块合并为一个 Buffer
const buffer = Buffer.concat(body)
// 将 Buffer 转换为字符串(假设是 UTF-8 编码)
const stringData = buffer.toString('utf8')
try {
// 尝试解析 JSON 字符串
const parsedData = JSON.parse(stringData)
// 如果解析成功,则 resolve
resolve(parsedData)
} catch (error) {
// 如果解析失败,则 reject
reject(new Error('参数解析失败'))
}
// 可以添加一个 'error' 事件监听器来处理任何可能出现的错误
req.on('error', (error) => {
reject(error)
})
})
})
}
// 把文件切片写成总的一个文件流
const pipeStream = (path, writeStream) => {
return new Promise((resolve) => {
// 创建可读流
const readStream = fse.createReadStream(path).on('error', (err) => {
// 如果在读取过程中发生错误,拒绝 Promise
reject(err)
})
// 在一个指定位置写入文件流
readStream.pipe(writeStream).on('finish', () => {
// 写入完成后,删除原切片文件
fse.unlinkSync(path)
resolve()
})
})
}
// 合并切片
const mergeFileChunk = async (chunkSize, fileHash, filePath) => {
try {
// target/chunkCache_fileHash值
const chunkCache = getChunkDir(fileHash)
// 读取 临时所有切片目录 chunkCache 下的所有文件和子目录,并返回这些文件和子目录的名称。
const chunkPaths = await fse.readdir(chunkCache)
// 根据切片下标进行排序
// 否则直接读取目录的获得的顺序会错乱
chunkPaths.sort((a, b) => a.split('-')[1] - b.split('-')[1])
let promiseList = []
for (let index = 0; index < chunkPaths.length; index++) {
// target/chunkCache_hash值/文件切片位置
let chunkPath = path.resolve(chunkCache, chunkPaths[index])
// 根据 index * chunkSize 在指定位置创建可写流
let writeStream = fse.createWriteStream(filePath, {
start: index * chunkSize,
})
promiseList.push(pipeStream(chunkPath, writeStream))
}
// 使用 Promise.all 等待所有 Promise 完成
// (相当于等待所有的切片已写入完成且删除了所有的切片文件)
Promise.all(promiseList)
.then(() => {
console.log('所有文件切片已成功处理并删除')
// 在这里执行所有切片处理完成后的操作
// 递归删除缓存切片目录及其内容 (注意,如果删除不存在的内容会报错)
if (fse.pathExistsSync(chunkCache)) {
fse.remove(chunkCache)
console.log(`chunkCache缓存目录删除成功`)
} else {
console.log(`${chunkCache} 不存在,不能删除`)
}
})
.catch((err) => {
console.error('文件处理过程中发生错误:', err)
// 在这里处理错误,可能需要清理资源等
})
} catch (err) {
console.log(err, '合并切片函数失败')
}
}
// 提取文件后缀名
const extractExt = (fileName) => {
// 查找'.'在fileName中最后出现的位置
const lastIndex = fileName.lastIndexOf('.')
// 如果'.'不存在,则返回空字符串
if (lastIndex === -1) {
return ''
}
// 否则,返回从'.'后一个字符到fileName末尾的子串作为文件后缀(不包含'.')
return fileName.slice(lastIndex + 1)
}
// 合并接口
app.post('/merge', async (req, res) => {
// 在上传完所有切片后就要调合并切片
try {
// 处理所有参数
const data = await resolvePost(req)
// 切片大小 文件名 文件hash
const { chunkSize, fileName, fileHash } = data
// 提取文件后缀名
const ext = extractExt(fileName)
// 整个文件路径 /target/文件hash.文件后缀
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${ext}`)
// 开始合并切片
await mergeFileChunk(chunkSize, fileHash, filePath)
res.send({
code: 0,
msg: '文件合并成功',
})
} catch (err) {
res.send({
code: -1,
data: err,
msg: '文件合并失败!',
})
}
})
在上面代码中,当前端调用 /merge 接口时,先把所有的传参通过resolvePost函数解析为 JSON 对象,然后提取文件后缀(注意可能出现文件没有后缀的情况),再我们确定好最终的文件路径,也就是/target/文件hash.文件后缀
开始合并切片:通过fse.readdir读取临时目录下的所有文件和子目录,这个方法会返回这些文件和子目录的名称形成一个数组,我们要对这个数组根据切片下标进行排序,这样能保证我们最终的目录顺序是正确的。再通过pipeStream方法,创建可读流并写入,再写入完成后就删除该切片。最终利用Promise.all等待所有的切片已写入完成且删除了所有的切片文件,最后再通过fse.remove递归删除缓存切片目录及其内容,就通知前端合并完该切片! 至此整个文件就上传成功啦!
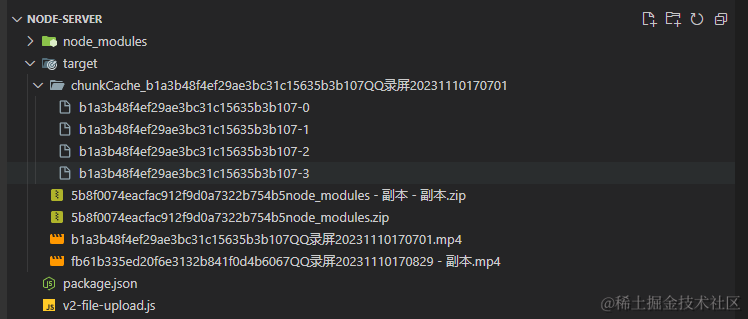
上传测试:可以看到最终上传的文件会存在target目录下,而chunkCache_开头的临时文件夹是用于存储切片(在合并完后会被删除)
到这里你已经完全掌握了基础版的大文件上传功能!
附上最终的UI效果:
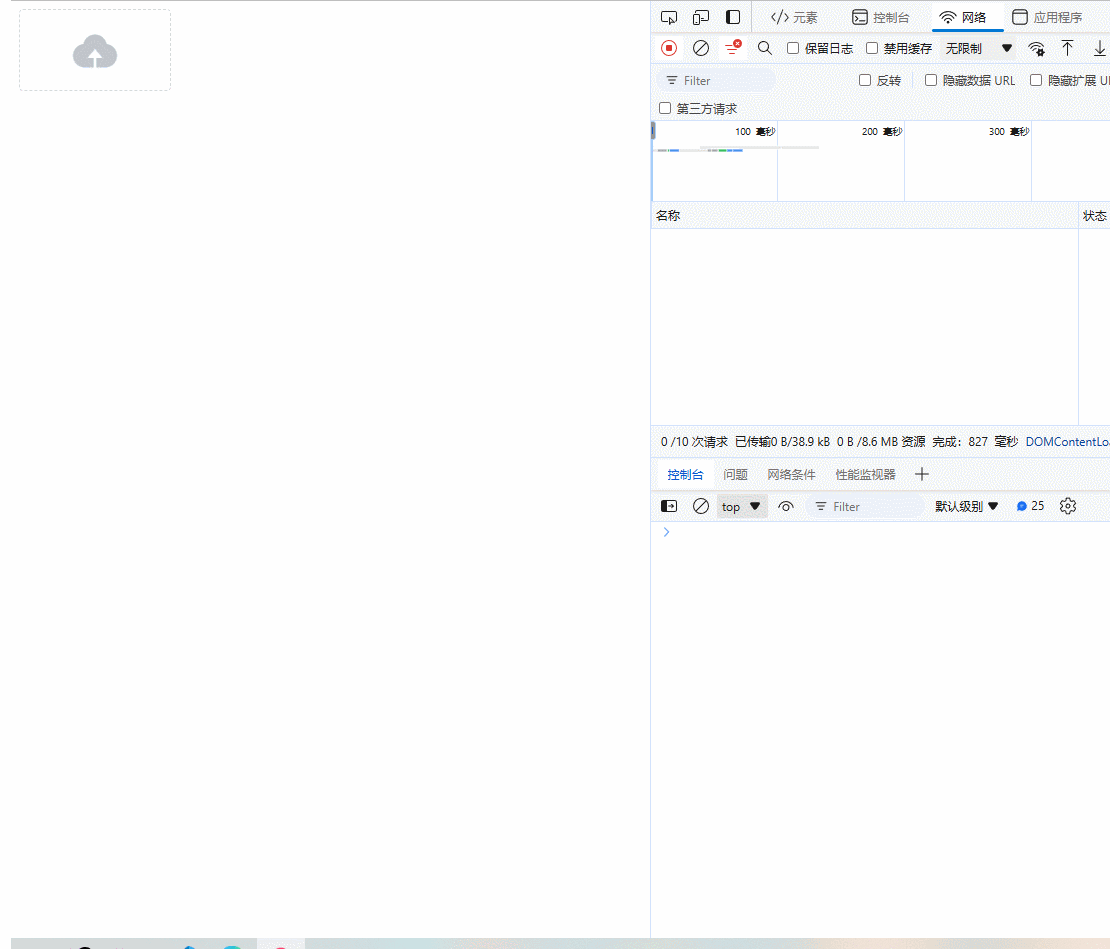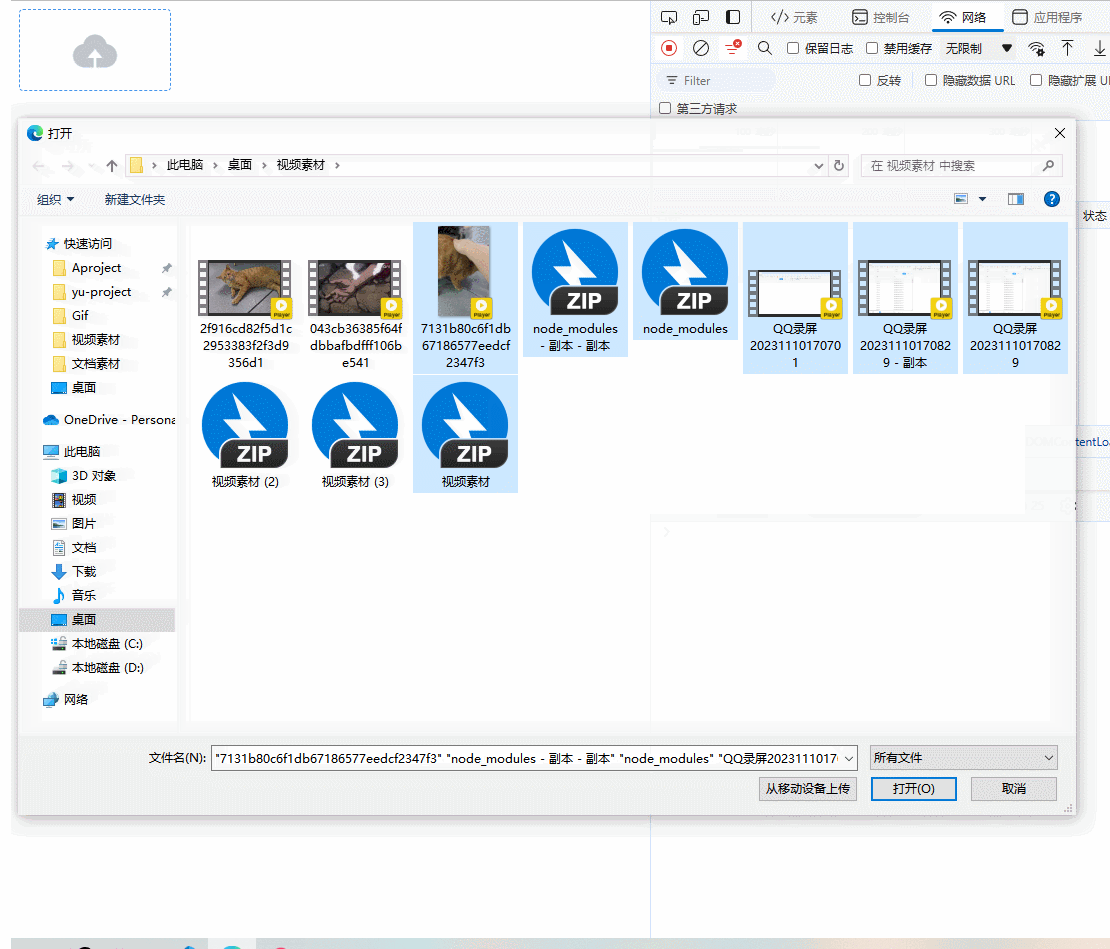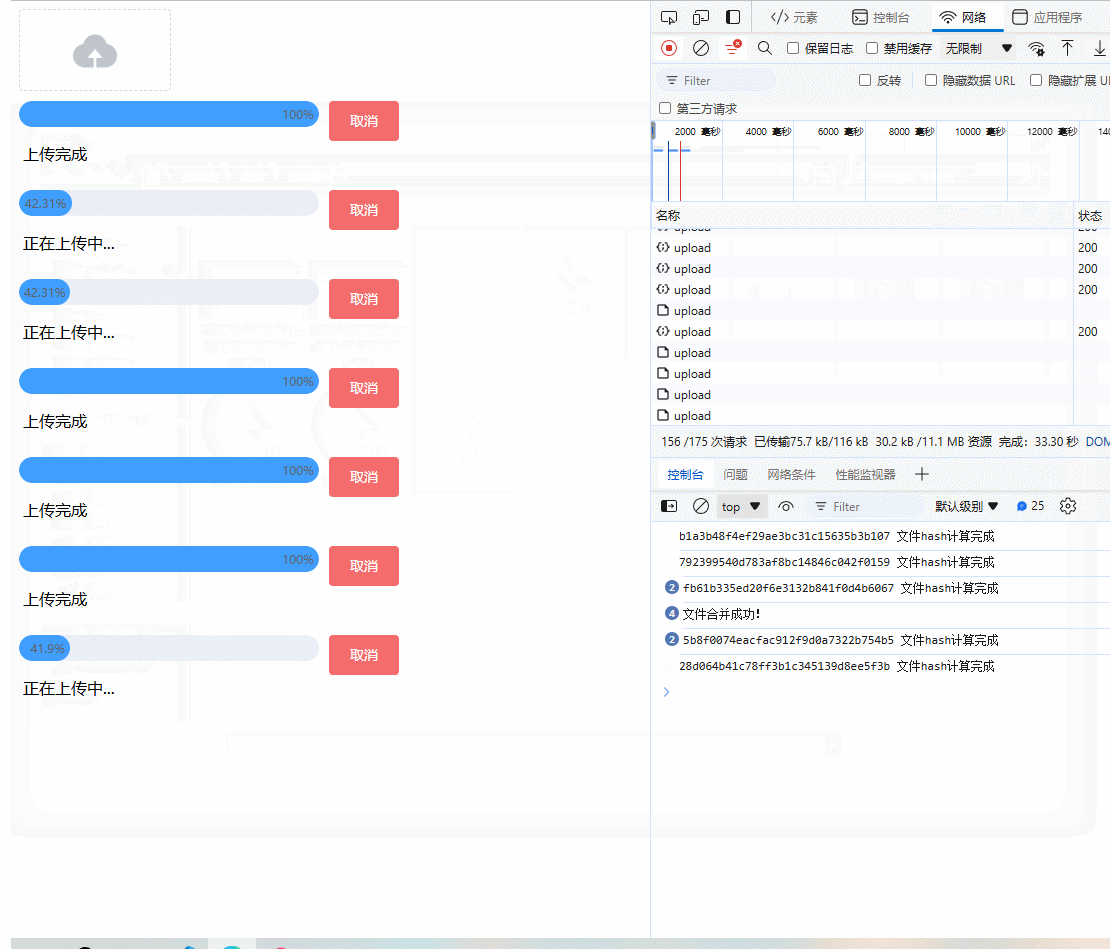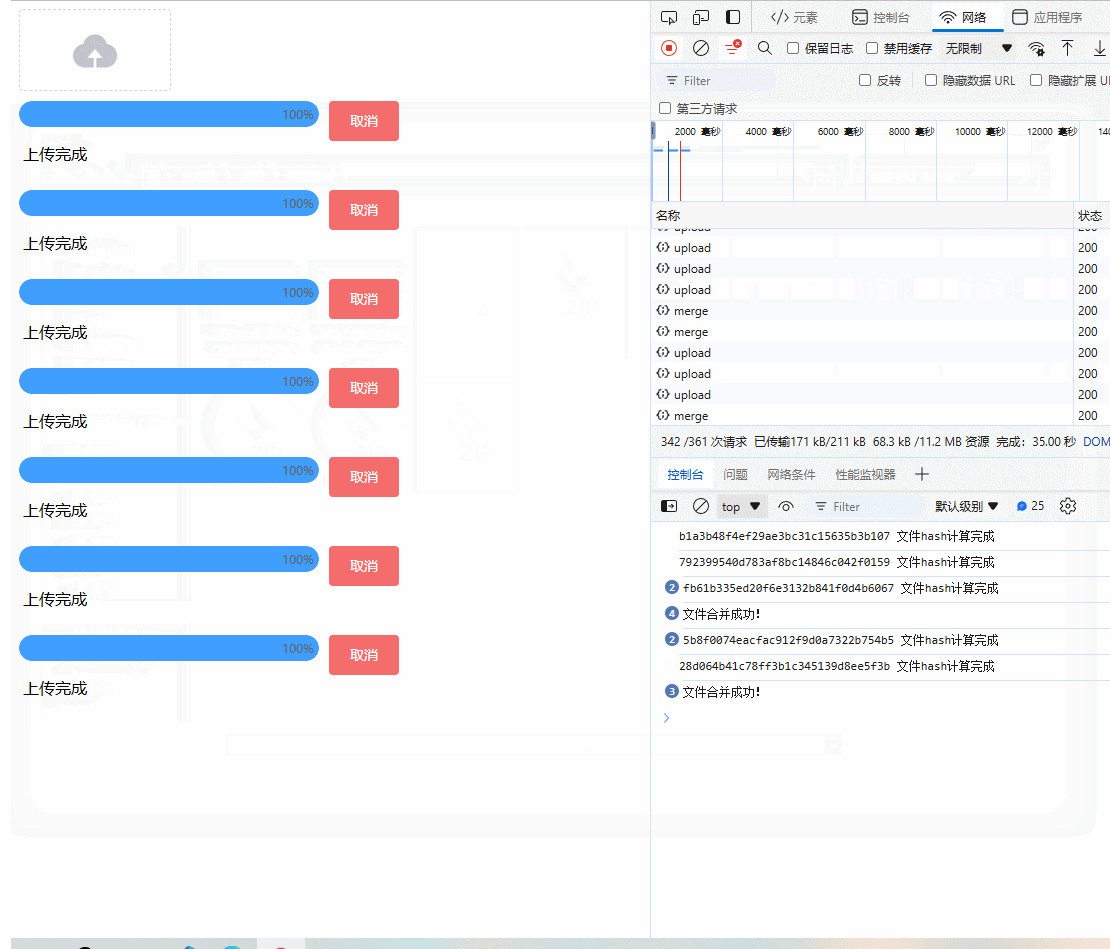
前端部分(Vue3 + vite完整版)
关于完整版包括了:切片上传 + 断点上传 + 秒传 + 暂停上传 + 恢复上传等功能,关于切片上传这里就不做过多的解释了(已在基础版讲解比较详细),至于为什么用Vue3只是觉得目前Vue3普及度很高,代码写法并无过多的复杂度(这里不使用hooks写法,需要的可自行封装),那就直接开始吧!
秒传
关于秒传原理其实就是:在上传文件之前先询问这个文件服务器端是否已存在,若已存在,则不需要上传了,直接让前端显示“已上传成功!”,这就是秒传(是不是很简单!)
所以我们只要在调上传接口之前调用一次检查文件是否存在接口即可!(代码会在断点上传一起放出)
断点上传
所谓断点上传(又名恢复上传)就是某个文件已经把部分切片上传到后端且保存,但是在上传过程中出现了一些不可预知问题:例如网络中断、超时、不小心刷新了页面等等,会导致上传中断,但是我们又不想再一次把所有切片又上传一次,只要把未上传的切片上传给后端即可。
那我们在上传文件之前就要调接口询问后端:我到底上传了哪些切片给你?赶紧给我返回过来,我要过滤掉这些已经传过的,留下没传过的。
所以这里如果后端把上面的秒传检查文件接口合起来,让我们在上传之前调一次不就知道了?
代码实现:
// 输入框change事件
const hanldeUploadFile = async (e) => {
const fileEle = e.target
// 如果没有文件内容
if (!fileEle || !fileEle.files || fileEle.files.length === 0) {
return false
}
const files = fileEle.files
// 多文件
Array.from(files).forEach(async (item, i) => {
const file = item
// 单个上传文件
// 这里要注意vue2跟vue3不同,
// 如果在循环 + await中,如果把一个普通对象push进一个响应式数组
// 直接修改原对象可能不会触发vue的DOM视图更新(但最终值会改变)
// 所以这里用了reactive做响应式代理
let inTaskArrItem = reactive({
id: new Date() + i, // 因为forEach是同步,所以需要用指定id作为唯一标识
state: 0, // 0是什么都不做,1文件处理中,2是上传中,3是暂停,4是上传完成,5上传中断,6是上传失败
fileHash: '',
fileName: file.name,
fileSize: file.size,
allChunkList: [], // 所有请求的数据
whileRequests: [], // 正在请求中的请求个数,目前是要永远都保存请求个数为6
finishNumber: 0, //请求完成的个数
errNumber: 0, // 报错的个数,默认是0个,超多3个就是直接上传中断
percentage: 0, // 单个文件上传进度条
cancel: null, // 用于取消切片上传接口
})
uploadFileList.value.push(inTaskArrItem)
// 如果不使用reactive,就得使用以下两种方式
// inTaskArrItem = uploadFileList.value[i]
// uploadFileList.value[i].state = 1
// 开始处理解析文件
inTaskArrItem.state = 1
if (file.size === 0) {
// 文件大小为0直接上传失败
inTaskArrItem.state = 6
// 上传中断
pauseUpload(inTaskArrItem, false)
}
console.log('文件开始解析')
// 计算文件hash
const { fileHash, fileChunkList } = await useWorker(file)
console.log(fileHash, '文件hash计算完成')
// 解析完成开始上传文件
let baseName = ''
// 查找'.'在fileName中最后出现的位置
const lastIndex = file.name.lastIndexOf('.')
// 如果'.'不存在,则返回整个文件名
if (lastIndex === -1) {
baseName = file.name
}
// 否则,返回从fileName开始到'.'前一个字符的子串作为文件名(不包含'.')
baseName = file.name.slice(0, lastIndex)
// 这里要注意!可能同一个文件,是复制出来的,出现文件名不同但是内容相同,导致获取到的hash值也是相同的
// 所以文件hash要特殊处理
inTaskArrItem.fileHash = `${fileHash}${baseName}`
inTaskArrItem.state = 2
console.log(uploadFileList.value, 'uploadFileList.value')
// 上传之前要检查服务器是否存在该文件
try {
const res = await checkFile({
fileHash: `${fileHash}${baseName}`,
fileName: file.name,
})
if (res.code === 0) {
const { shouldUpload, uploadedList } = res.data
if (!shouldUpload) {
finishTask(inTaskArrItem)
console.log('文件已存在,实现秒传')
return false
}
inTaskArrItem.allChunkList = fileChunkList.map((item, index) => {
return {
// 总文件hash
fileHash: `${fileHash}${baseName}`,
// 总文件size
fileSize: file.size,
// 总文件name
fileName: file.name,
index: index,
// 切片文件本身
chunkFile: item.chunkFile,
// 单个切片hash,以 - 连接
chunkHash: `${fileHash}-${index}`,
// 切片文件大小
chunkSize: chunkSize,
// 切片个数
chunkNumber: fileChunkList.length,
// 切片是否已经完成
finish: false,
}
})
// 如果已存在部分文件切片,则要过滤调已经上传的切片
if (uploadedList.length > 0) {
// 过滤掉已经上传过的切片
inTaskArrItem.allChunkList = inTaskArrItem.allChunkList.filter(
(item) => !uploadedList.includes(item.chunkHash)
)
// 如果存在需要上传的,但是又为空,可能是因为还没合并,
if (!inTaskArrItem.allChunkList.length) {
// 所以需要调用合并接口
await handleMerge(inTaskArrItem)
return false
} else {
// 同时要注意处理切片数量
inTaskArrItem.allChunkList = inTaskArrItem.allChunkList.map(
(item) => {
return {
...item,
chunkNumber: inTaskArrItem.allChunkList.length,
}
}
)
}
}
// 逐步对单个文件进行切片上传
uploadSignleFile(inTaskArrItem)
}
} catch (err) {}
})
}
!这里要注意的是
inTaskArrItem用了reactive做响应式代理push到uploadFileList,这是因为在forEach循环 + await中,如果在await后面直接修改inTaskArrItem某个属性,Vue3并不能实时更新DOM视图,就会导致uploadFileList在视图中不会变化,就算是用for + await也是类似(最后一个inTaskArrItem不会触发DOM更新),所以这里必须要么使用reactive,要么直接uploadFileList.value[i].state = 2修改, 又或者使用赋值重新引用响应式inTaskArrItem = uploadFileList.value[i]等其中一种方法去修改。
在上面代码中,我们通过checkFile接口去获取该文件是否需要再次上传,以及拿到已上传切片列表,如果不需要二次上传,则直接让其显示上传完成并设置上传状态,如果是已上传部分切片,则需要过滤掉已经上传过的切片,同时要注意,可能存在已经上传完所有切片但未合并的情况,这时候就得调一次合并接口即可。同时要注意处理切片数量,因为这在判断是否已经上传完全部切片的时候用到。
关于上面的循环异步导致响应式视图更新问题,可能会抽空测试总结并做一个分享
暂停上传
说到暂停上传,其实就是把还在请求中的接口直接中断。这时候我们就可以用到axios的AbortController方法去取消接口请求,(原生XMLHttpRequest 使用 abort 方法)

所以我们的上传接口要重新封装一下:
// src/api/index.js
// ...其他代码
// 上传单个切片
export function uploadFile(data, onCancel) {
const controller = new AbortController()
const signal = controller.signal // 获取 signal 对象
// 封装 axios 请求或 HTTP 客户端请求
const request = service({
url: '/upload',
method: 'post',
data,
signal, // 将 signal 传递给服务函数
})
// 如果提供了 onCancel 回调,则传递取消函数
if (typeof onCancel === 'function') {
// 如果是一个函数,则直接调用传一个取消方法给 这个方法
// 所以只要传进来是方法,就会直接传一个参数并直接触发这个函数
// 那传过来的这个方法就会接收到一个参数(就是取消函数() => controller.abort())
// 在调用uploadFile就可以拿到这个参数
onCancel(() => controller.abort()) // 调用 onCancel 时传入取消函数
}
return request
}
// App.vue
// 单个分片请求
const uploadChunk = async (needObj) => {
const fd = new FormData()
const {
fileHash,
fileSize,
fileName,
index,
chunkFile,
chunkHash,
chunkSize,
chunkNumber,
} = needObj
fd.append('fileHash', fileHash)
fd.append('fileSize', String(fileSize))
fd.append('fileName', fileName)
fd.append('index', String(index))
fd.append('chunkFile', chunkFile)
fd.append('chunkHash', chunkHash)
fd.append('chunkSize', String(chunkSize))
fd.append('chunkNumber', String(chunkNumber))
const res = await uploadFile(fd, (onCancelFunc) => {
// 在调用接口的同时,相当于同时调用了传入的这个函数,又能同时拿到返回的取消方法去赋值
needObj.cancel = onCancelFunc
}).catch(() => {})
// 先判断是不是处于暂停还是取消状态
// 你的状态都已经变成暂停或者中断了,就什么都不要再做了,及时停止
if (taskArrItem.state === 3 || taskArrItem.state === 5) {
return false
}
// 请求异常,或者请求成功服务端返回报错都按单片上传失败逻辑处理
if (!res || res.code === -1) {
taskArrItem.errNumber++
// 超过3次之后直接上传中断
if (taskArrItem.errNumber > 3) {
console.log('切片上传失败超过三次了')
pauseUpload(taskArrItem, false) // 上传中断
} else {
console.log('切片上传失败还没超过3次')
uploadChunk(needObj) // 失败了一片,继续当前分片请求
}
} else if (res.code === 0) {
// 单个文件上传失败次数大于0则要减少一个
taskArrItem.errNumber > 0 ? taskArrItem.errNumber-- : 0
// 单个文件切片上传成功数+1
taskArrItem.finishNumber++
// 单个切片上传完成
needObj.finish = true
signleFileProgress(needObj, taskArrItem) // 更新进度条
// 上传成功了就删掉请求中数组中的那一片请求
taskArrItem.whileRequests = taskArrItem.whileRequests.filter(
(item) => item.chunkFile !== needObj.chunkFile
)
// 如果单个文件最终成功数等于切片个数
if (taskArrItem.finishNumber === chunkNumber) {
// 全部上传完切片后就开始合并切片
handleMerge(taskArrItem)
} else {
// 如果还没完全上传完,则继续上传
uploadSignleFile(taskArrItem)
}
}
}
在这段代码中
// 在调用接口的同时,相当于同时调用了传入的这个函数,又能同时拿到返回的取消方法去赋值
const res = await uploadFile(fd, (onCancelFunc) => {
needObj.cancel = onCancelFunc
}).catch(() => {})
解析:这里我们在调uploadFile接口的同时,把一个
箭头函数A传递作为第二个形参传递给了uploadFile,而在封装的uploadFile内部,获取到的第二个形参也就是onCancel判断如果为function,则立即执行onCancel这个函数A,在执行的同时把箭头函数() => controller.abort()作为传参传给函数A,这样在函数A就可以拿到() => controller.abort()并赋值给当前切片的cancel字段。这样就可以在主动取消的时候,调用当前切片内部属性
cancel(),相当于调用该切片接口的controller.abort()进行取消请求
上面的解释可能需要多操作几遍测试去理解
这样我们就可以定义一个暂停事件:
// 暂停上传(是暂停剩下未上传的)
const pauseUpload = (taskArrItem, elsePause = true) => {
// elsePause为true就是主动暂停,为false就是请求中断
// 4是成功 6是失败 如果不是成功或者失败状态,
if (![4, 6].includes(taskArrItem.state)) {
// 3是暂停,5是中断
if (elsePause) {
taskArrItem.state = 3
} else {
taskArrItem.state = 5
}
}
taskArrItem.errNumber = 0
// 取消还在请求中的所有接口
if (taskArrItem.whileRequests.length > 0) {
for (const itemB of taskArrItem.whileRequests) {
itemB.cancel ? itemB.cancel() : ''
}
}
}
在暂停事件中,先判断该文件的上传成功失败状态,如果都不属于这两者,则需要判断是否为主动暂停还是被动中断(某切片连续上传失败3次),同时调用
controller.abort()取消还在请求中的所有接口。
恢复上传
既然我们都有了暂停上传了,就得有恢复上传吧,其实原理也很简单:只要把刚才暂停的正在上传中所有切片(whileRequests)放到待上传切片列表中(allChunkList),再去调用单个文件上传方法(uploadSignleFile)就可以啦。
// 继续上传
const resumeUpload = (taskArrItem) => {
// 2为上传中
taskArrItem.state = 2
// 把刚才暂停的正在上传中所有切片放到待上传切片列表中
taskArrItem.allChunkList.push(...taskArrItem.whileRequests)
taskArrItem.whileRequests = []
uploadSignleFile(taskArrItem)
}
看到这里,关于完整版的关键要点跟原理已经基本展示出来了,不把全部代码展示是因为跟基础版有重复之处,且过长以及剩余部分并不难,只要弄懂这几个功能需要的原理即可。
全部源码(Vue2 + Vue3 + Node)我会放在文章末尾~
Node后端(完整版)
其实完整版就是多了一个检查文件接口,这里也不难,只要根据前端传过来的文件hash值去找到是否有这个文件,以及检查是否存在该文件的切片缓存目录(如果有则返回该目录下的所有切片哈希)
// v3-file-upload.js
// 返回已上传的所有切片名
const createUploadedList = async (fileHash) => {
// 如果存在这个目录则返回这个目录下的所有切片
// fse.readdir返回一个数组,其中包含指定目录中的文件名。
return fse.existsSync(getChunkDir(fileHash))
? await fse.readdir(getChunkDir(fileHash))
: []
}
// 验证是否存在已上传切片
app.post('/verify', async (req, res) => {
try {
const data = await resolvePost(req)
const { fileHash, fileName } = data
// 文件名后缀
const ext = extractExt(fileName)
// 最终文件路径
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${ext}`)
// 如果已经存在文件则标识文件已存在,不需要再上传
if (fse.existsSync(filePath)) {
res.send({
code: 0,
data: {
shouldUpload: false,
uploadedList: [],
},
msg: '已存在该文件',
})
} else {
// 否则则返回文件已经存在切片给前端
// 告诉前端这些切片不需要再上传
res.send({
code: 0,
data: {
shouldUpload: true,
uploadedList: await createUploadedList(fileHash),
},
msg: '需要上传文件/部分切片',
})
}
} catch (err) {
res.send({ code: -1, msg: '上传失败', data: err })
}
})
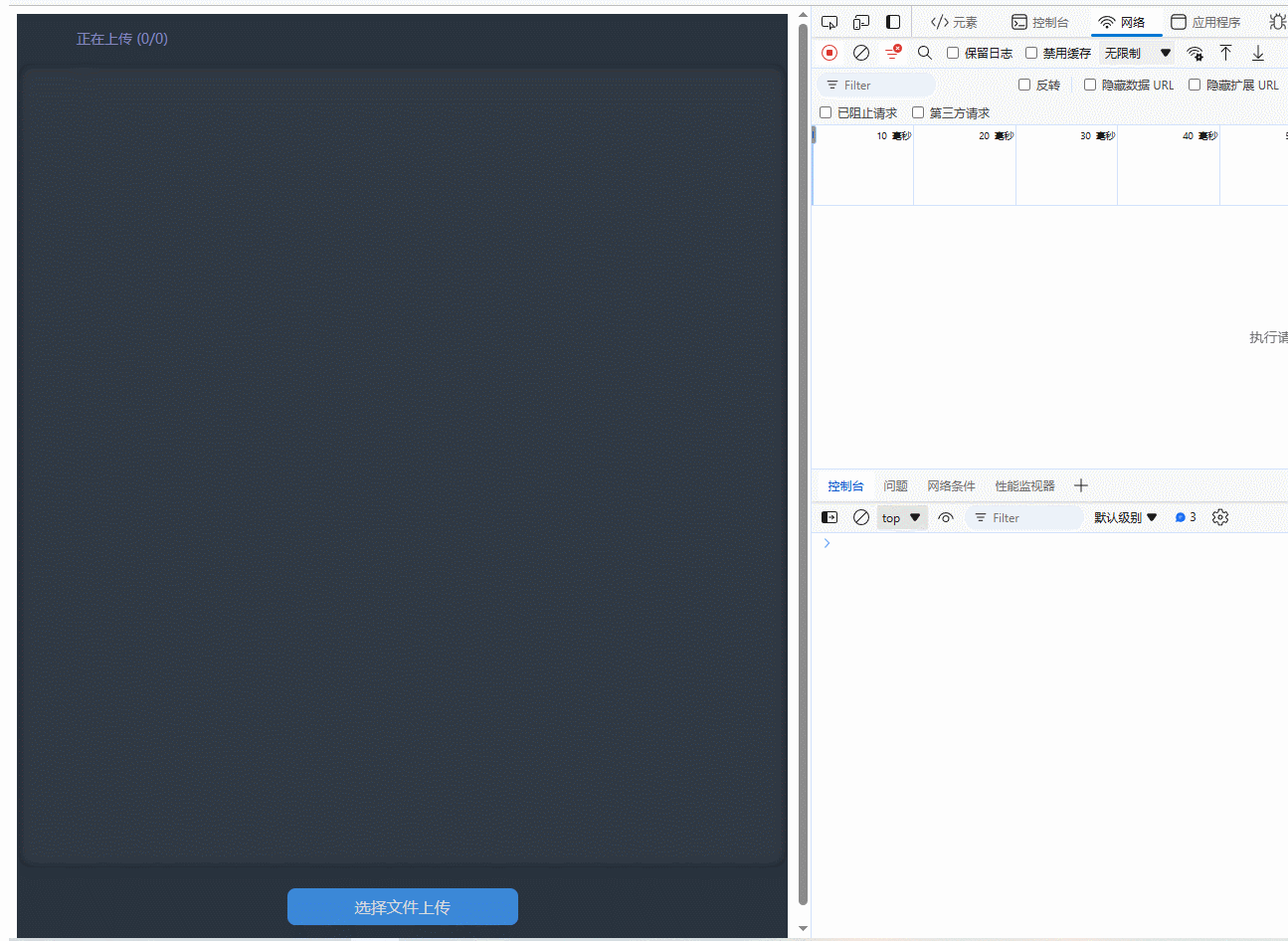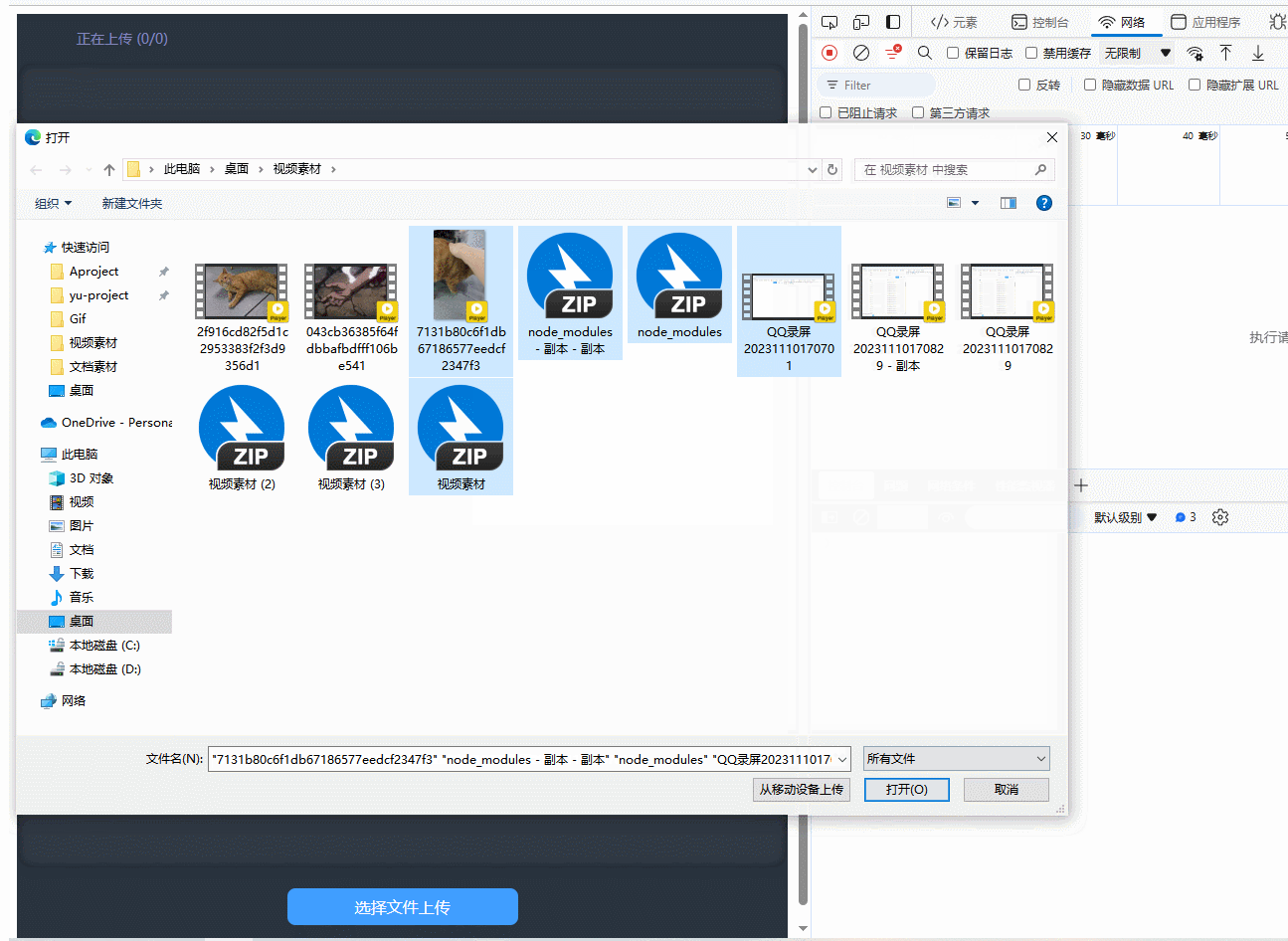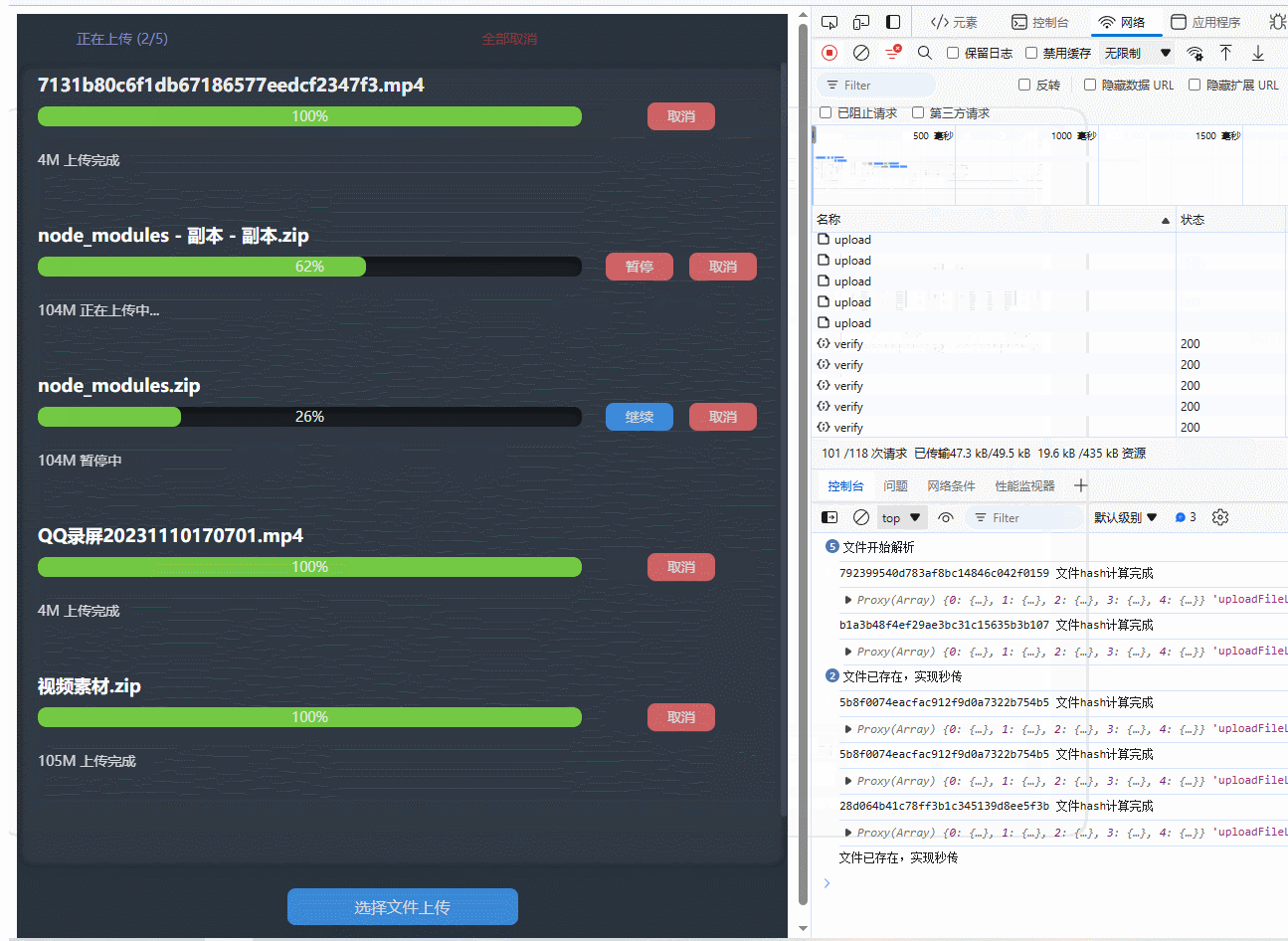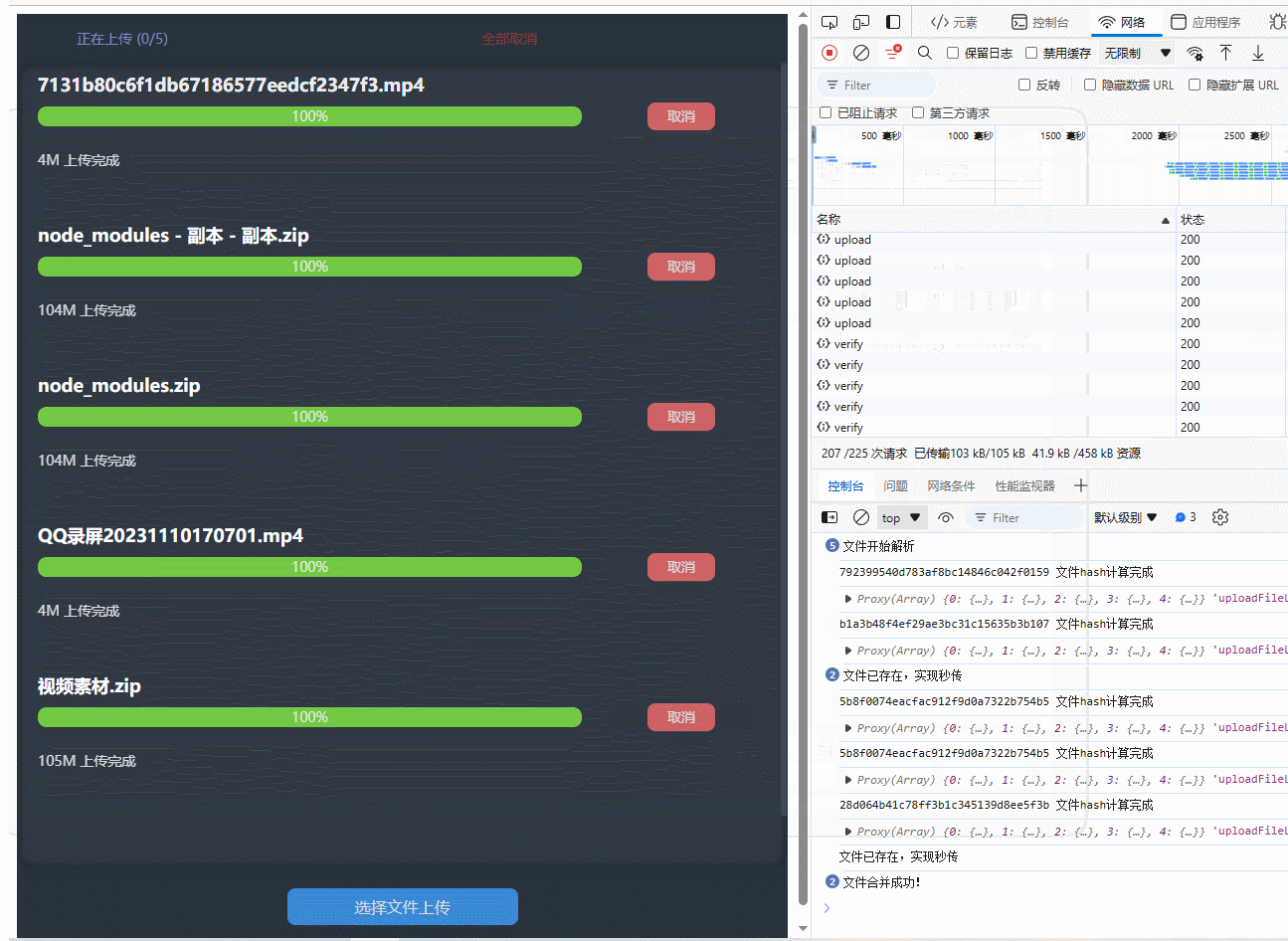
附上完整版UI效果图(完整版没有用到组件库,可根据实际情况使用)
总结
经过学习各大佬的文章再经过每一步都经过不断测试完善,对于代码以及原理算是讲的比较清晰明了,若有不足之处可随时评论。
不足之处
- 用户刷新页面/打开页面后,没有实现当前页面自动恢复文件列表的上传(该功能因为是存储文件信息,需要用到浏览器的本地缓存
indexDB功能,但该功能还是不够完美,所以没去实现,可自行了解indexDB)
可优化部分
- 对于文件哈希值的计算,对于大文件就算使用增量读取,但仍很耗时,可以对文件进行
抽样hash读取,但注意要保证准确度。 - 对前端文件合并处理,不一定要调接口,可以把这部分放到后端去处理,可以节省前端工作量
源代码
若觉得对你有所帮助,希望可以多多 Star⭐ 支持一下~
github:v2v3-large-file-upload
gitee:v2v3-large-file-upload