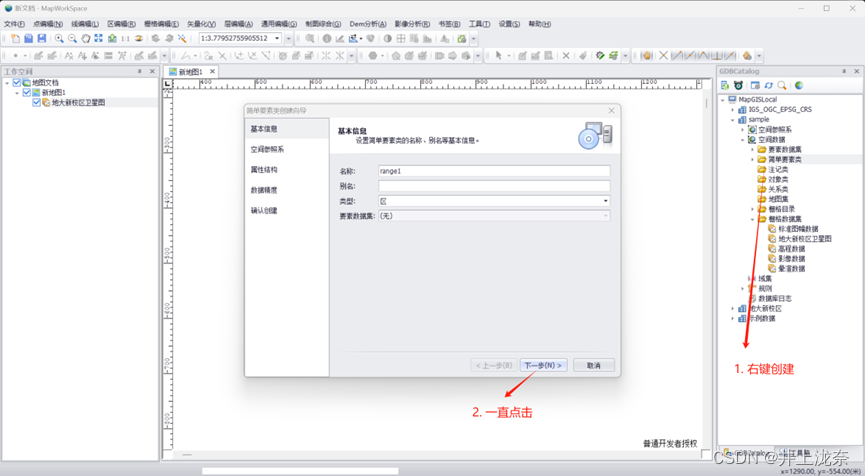
实验1
实验1主要是做实验环境的配置,包括MapGis的安装、开发者权限的申请、添加数据库数据等操作,根据指导操作后执行成功,界面如下。
实验2
实验2采用多线程并行技术,将地图利用多线程进行读取展示,原项目使用了两个线程,现将项目改为使用三个线程。主要就是计算怎么去划分三个矩形,原代码将地图区域划分为了左右两个部分,改为三个线程需要划分为左中右三个部分,因此计算的矩形坐标需要改变,具体代码如下:
// 左边矩形
rect1.XMin = map.Range.XMin;
rect1.XMax = map.Range.XMin + (map.Range.XMax - map.Range.XMin) / 3;
rect1.YMin = map.Range.YMin;
rect1.YMax = map.Range.YMax;
// 中间矩形
rect2.XMin = rect1.XMax;
rect2.XMax = map.Range.XMax - (map.Range.XMax - map.Range.XMin) / 3;
rect2.YMin = map.Range.YMin;
rect2.YMax = map.Range.YMax;
// 右边矩形
rect3.XMin = rect2.XMax;
rect3.XMax = map.Range.XMax;
rect3.YMin = map.Range.YMin;
rect3.YMax = map.Range.YMax;
然后调用三个线程去执行读取图片并显示的操作:
var threadOne = new Thread(() => ToPicture(map, rect1, "D:\\ThreadOne.png", pictureBox1));
var threadTwo = new Thread(() => ToPicture(map, rect2, "D:\\ThreadTwo.png", pictureBox2));
var threadThree = new Thread(() => ToPicture(map, rect3, "D:\\ThreadThree.png", pictureBox3));
threadOne.Start();
threadTwo.Start();
threadThree.Start();
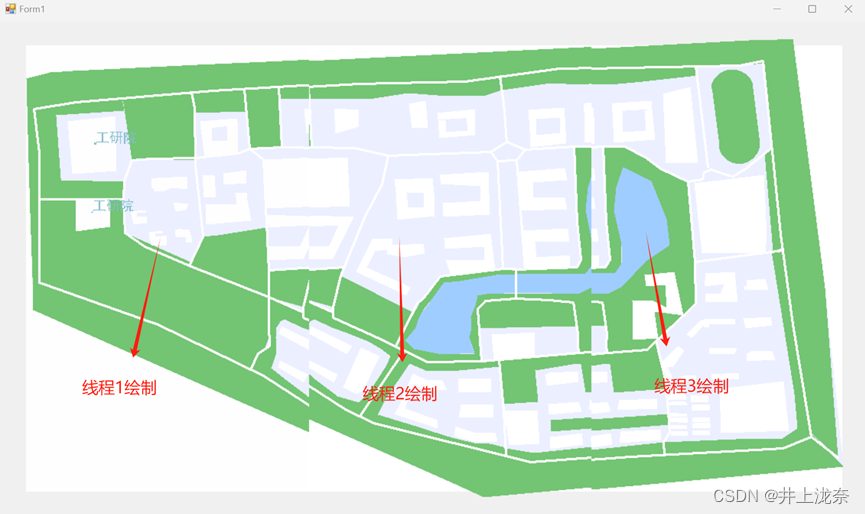
代码运行结果如下图:
实验3
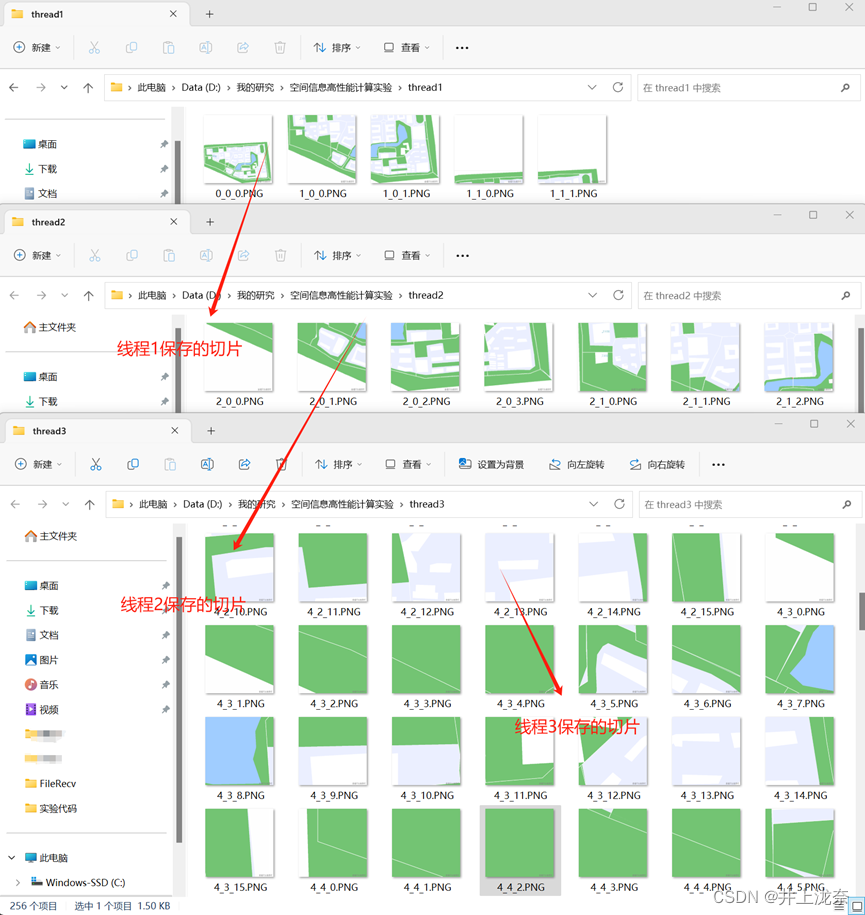
实验3实现了对空间信息的切片,代码执行后将切片保存到设定的路径下,原代码使用了两个线程进行并行化切片,将该代码改造为三个线程并行,新建一个线程去调用ToSlices函数即可,需要将参数中的start_level和end_level修改,保证三个线程对开始结束的层级都能包含,代码如下:
var threadOne = new Thread(() => ToSlices(map, 0, 1, "D:\\我的研究\\空间信息高性能计算实验\\thread1\\"));
threadOne.Name = "ThreadOne";
var threadTwo = new Thread(() => ToSlices(map, 2, 3, "D:\\我的研究\\空间信息高性能计算实验\\thread2\\"));
threadTwo.Name = "ThreadTwo";
var threadThree = new Thread(() => ToSlices(map, 4, 4, "D:\\我的研究\\空间信息高性能计算实验\\thread3\\"));
threadThree.Name = "ThreadThree";
threadOne.Start();
threadTwo.Start();
threadThree.Start();
实验4
实验4对矢量数据进行并行化查询,原代码利用两个线程对数据进行检索,修改代码使用三个线程并行化查询。首先需要添加一个ListView组件,并将组件属性中的View属性改为Details,确保属性值都和原组件一样,然后需要修改一些代码,首先创建一个新的线程并启动:
var threadThree = new Thread(() => GetSFCls(SFCls, listView3, 3));
threadThree.Name = "ThreadThree";
threadThree.Start();
然后修改GetSFCls函数中的一些内容,将task_count分为三份,同时对第二个线程修改并增加第三个线程的条件语句,代码如下:
double task_count = objCount / 3;
...
else if (pre_or_next == 2){...}
else
{
if (n > 2 * task_count)
{
ListViewItem items = null;
items = listView.Items.Add(id.ToString());
for (int i = 0; i < num; i++)
{
Fld = Flds.GetItem(i);
string name = Fld.FieldName;
object val = Rcd.get_FldVal(name);
ObjectVal(items, val);
}
}
}
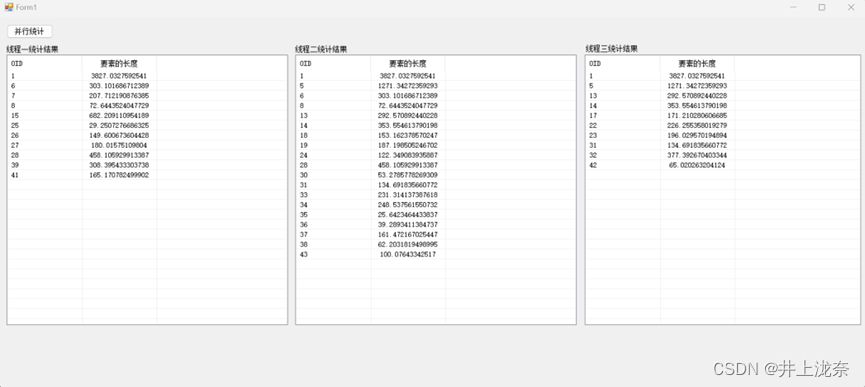
代码运行结果如下:

实验5
实验5有点类似于实验4,内容是对矢量数据的并行统计,原代码使用两个线程进行并行化统计,修改代码使用三个线程对数据进行并行化统计。首先类似实验4在设计中添加一个ListView组件,然后添加线程代码:
var threadThree = new Thread(() => statistics(SFCls, listView3, 3));
threadThree.Name = "ThreadThree";
threadOne.Start();
然后将二线程的两部分划分为三个部分,将矩形区域的范围修改:
if (L_or_R == 1)
{
// 处理数据集的左侧1/3部分
rect.XMax = resource_sfcls.Range.XMin + (resource_sfcls.Range.XMax - resource_sfcls.Range.XMin) / 3;
rect.YMax = resource_sfcls.Range.YMax;
rect.YMin = resource_sfcls.Range.YMin;
rect.XMin = resource_sfcls.Range.XMin;
mode = SpaQueryMode.Intersect;
}
else if (L_or_R == 2)
{
// 处理数据集的中间1/3部分
rect.XMin = resource_sfcls.Range.XMin + (resource_sfcls.Range.XMax - resource_sfcls.Range.XMin) / 3;
rect.XMax = resource_sfcls.Range.XMin + 2 * (resource_sfcls.Range.XMax - resource_sfcls.Range.XMin) / 3;
rect.YMax = resource_sfcls.Range.YMax;
rect.YMin = resource_sfcls.Range.YMin;
mode = SpaQueryMode.Intersect;
}
else
{
// 处理数据集的右侧1/3部分
rect.XMin = resource_sfcls.Range.XMin + 2 * (resource_sfcls.Range.XMax - resource_sfcls.Range.XMin) / 3;
rect.XMax = resource_sfcls.Range.XMax;
rect.YMax = resource_sfcls.Range.YMax;
rect.YMin = resource_sfcls.Range.YMin;
mode = SpaQueryMode.Intersect;
}
代码运行结果如下图所示:
实验6
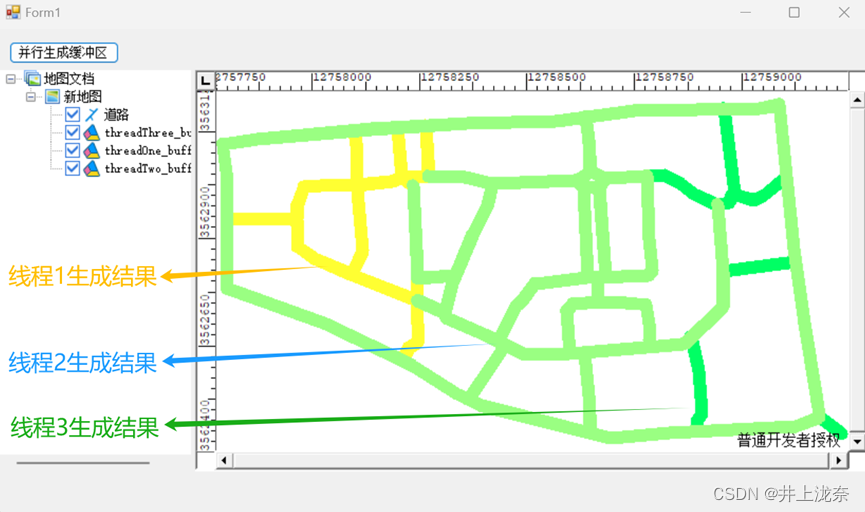
实验6实现并行数据缓冲,原代码使用了两个线程进行并行化缓冲,修改代码使用三线程进行并行数据缓冲。首先在按钮的点击事件函数button1_Click中添加新的线程:
var threadThree = new Thread(() => Buffer(sfcls, GDB, "threadThree_buffer", 3));
threadThree.Name = "ThreadThree";
threadOne.Start();
然后将生成缓冲函数中将地图划分为三部分:
if (L_or_R == 1)
{
// 左侧1/3区域
rect.XMax = resource_sfcls.Range.XMin + (resource_sfcls.Range.XMax - resource_sfcls.Range.XMin) / 3;
rect.YMax = resource_sfcls.Range.YMax;
rect.YMin = resource_sfcls.Range.YMin;
rect.XMin = resource_sfcls.Range.XMin;
mode = SpaQueryMode.Intersect;
_RegInfo = new RegInfo();
_RegInfo.FillClr = 168; //黄色
}
else if (L_or_R == 2)
{
// 中间1/3区域
rect.XMin = resource_sfcls.Range.XMin + (resource_sfcls.Range.XMax - resource_sfcls.Range.XMin) / 3;
rect.XMax = resource_sfcls.Range.XMin + 2 * (resource_sfcls.Range.XMax - resource_sfcls.Range.XMin) / 3;
rect.YMax = resource_sfcls.Range.YMax;
rect.YMin = resource_sfcls.Range.YMin;
mode = SpaQueryMode.Intersect;
_RegInfo = new RegInfo();
_RegInfo.FillClr = 292; //浅绿
}
else
{
// 右侧1/3区域
rect.XMin = resource_sfcls.Range.XMin + 2 * (resource_sfcls.Range.XMax - resource_sfcls.Range.XMin) / 3;
rect.XMax = resource_sfcls.Range.XMax;
rect.YMax = resource_sfcls.Range.YMax;
rect.YMin = resource_sfcls.Range.YMin;
mode = SpaQueryMode.Intersect;
_RegInfo = new RegInfo();
_RegInfo.FillClr = 376; //绿色
}
该项目需要注意的是,当生成一次缓冲后,改缓冲会添加到数据库中,如果再次执行会报错,因此需要修改名称或者在数据库中将添加的缓冲删除掉。
代码运行结果如下:
实验7
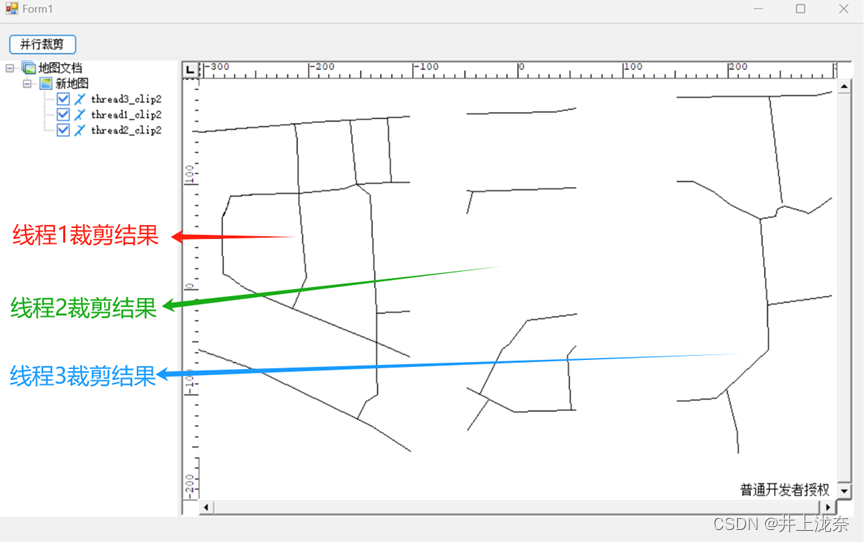
实验7实现了对道路矢量数据进行裁剪,原代码使用了两个线程并行化裁剪,将代码修改为三个线程并行化裁剪。首先添加新的裁剪矩形框:
SFeatureCls clip_sfcls3 = null;
clip_sfcls3 = new SFeatureCls(GDB);
clip_sfcls3.Open("矩形框3", 1);
然后创建第三个结果简单要素类:
SFeatureCls ResultSFeatureCls3 = new SFeatureCls(GDB);
id = ResultSFeatureCls3.Create("thread3_clip", cliped_sfcls.GeomType, 0, 0, null);
最后创建并启动第三个线程:
var threadThree = new Thread(() => Clip(cliped_sfcls, clip_sfcls3, ResultSFeatureCls3));
threadThree.Name = "ThreadThree";
threadThree.Start();
和实验6一样,执行一次成功后会在数据库中添加裁剪的矢量线,需要修改名称或者在数据库中删掉才能再次执行,代码运行结果如下:
实验8
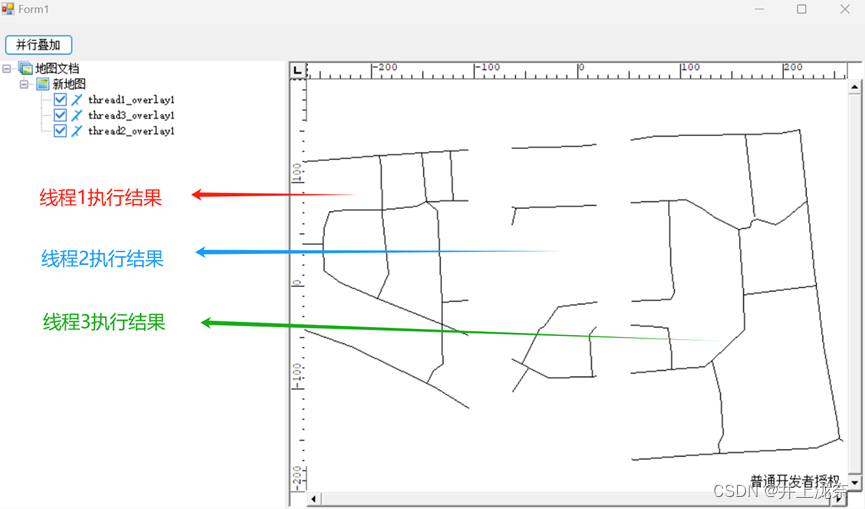
实验8实验的是矢量数据的叠加,原代码使用了两个线程对地图进行并行叠加,将其改造为三个线程的并行叠加,具体改造类似实验7,首先添加新的矩形框:
SFeatureCls overlay_sfcls3 = null;
overlay_sfcls3 = new SFeatureCls(GDB);
overlay_sfcls3.Open("矩形框3", 1);
然后创建第三个结果简单要素类:
SFeatureCls ResultSFeatureCls3 = new SFeatureCls(GDB);
id = ResultSFeatureCls3.Create("thread3_overlay1", sfcls.GeomType, 0, 0, null);
最后创建第三个线程并启动:
var threadThree = new Thread(() => Overlay(sfcls, overlay_sfcls3, ResultSFeatureCls3));
threadThree.Name = "ThreadThree";
threadThree.Start();
同样的,也需要删掉数据库数据或者该名称才能再次运行,代码运行结果如下:
实验9
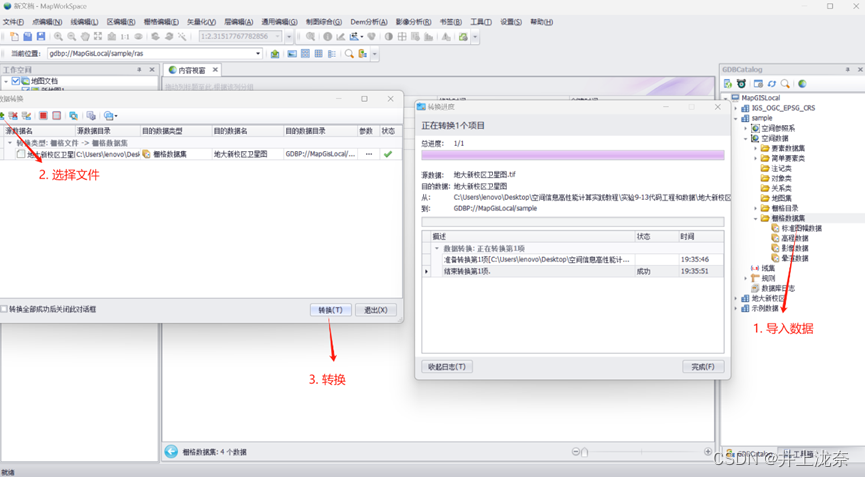
本实验对栅格数据进行并行查询,该实验会使用窗口化进程调用另外两个exe文件,达到并行的效果,首先需要在数据库中导入空间数据。
然后修改三个项目中的文件地址信息,运行窗体程序项目得到如下结果:
现将其改造为3个线程查询。首先需要新建一个新的项目,作为第三个进程的查询程序,其中代码和pro1和pro2类似,需要修改输出文件位置和查询的范围,之前的项目是将查询分为两部分,分别查询行号为290和行号为1448的数据,线程后可将其分为三份(理论上需要这么修改代码,但实际上只有两个行号290和1448,此项目实际上应该划分列号,但是划分列号也不太好分为三个线程,只能按顺序三等分了):
int i =( height / 3) * 2 + 1; i < height_max; i++
然后在窗体程序中,添加调用第三个进程的代码:
Process p3 = new Process();
p3.StartInfo.FileName = "xxx//pro3.exe";
p3.StartInfo.UseShellExecute = false;
p3.StartInfo.RedirectStandardInput = true;
p3.StartInfo.RedirectStandardOutput = true;
p3.StartInfo.RedirectStandardError = true;
p3.StartInfo.CreateNoWindow = true;
p3.Start();
p3.WaitForExit();
p3.Close();
然后添加第三个线程调用刚刚创建的第三个进程:
Process p3 = new Process();
p3.StartInfo.FileName = "xxx\\pro3.exe";
p3.StartInfo.UseShellExecute = false;
p3.StartInfo.RedirectStandardInput = true;
p3.StartInfo.RedirectStandardOutput = true;
p3.StartInfo.RedirectStandardError = true;
p3.StartInfo.CreateNoWindow = true;
p3.Start();
p3.WaitForExit();
p3.Close();
最后在窗体设计中添加一个DataGridView,然后创建第三个数据表格,并将数据添加到DataGridView组件显示:
DataTable dt3 = new DataTable();
dt3.Columns.Add("行号", typeof(int));
dt3.Columns.Add("列号", typeof(int));
dt3.Columns.Add("像元值", typeof(double));
string[] rows2 = File.ReadAllLines(@"xxx\\2-3.txt");
foreach (string row2 in rows2)
{
dt.Rows.Add(row2.Split(','));
dt3.Rows.Add(row2.Split(','));
}
dataGridView4.DataSource = dt3;
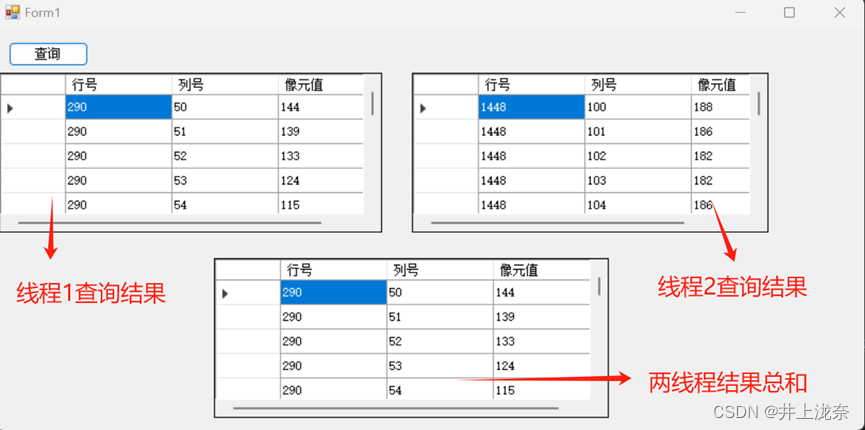
代码运行结果如下:
实验10
实验10是栅格数据的并行计算,原代码使用了两个线程调用两个进程进行并行化,整体上和实验9较为类似,这里不再详述,也是添加进程,在窗体程序中添加DataGridView组件并使用该组件对数据进行可视化:
//添加进程3 p2(p、p1、p2的顺序)
Process p2 = new Process();
p2.StartInfo.FileName = "xxx\\pro3.exe";
p2.StartInfo.UseShellExecute = false;
p2.StartInfo.RedirectStandardInput = true;
p2.StartInfo.RedirectStandardOutput = true;
p2.StartInfo.RedirectStandardError = true;
p2.StartInfo.CreateNoWindow = true;
p2.Start();
p2.WaitForExit();
p2.Close();
// 数据可视化
DataTable dt3 = new DataTable();
dt3.Columns.Add("行号", typeof(int));
dt3.Columns.Add("列号", typeof(int));
dt3.Columns.Add("计算前像元值", typeof(double));
dt3.Columns.Add("计算后像元值", typeof(double));
string[] rows2 = File.ReadAllLines(@"xxx\\3.txt");
foreach (string row2 in rows2)
{
dt3.Rows.Add(row2.Split(','));
dt2.Rows.Add(row2.Split(','));
}
dataGridView4.DataSource = dt3;
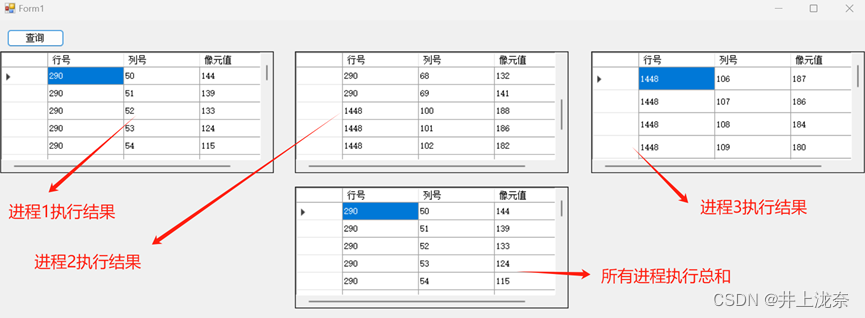
代码运行结果如下:
实验11
实验11是实现的是对栅格数据的并行化裁剪,首先需要在数据库中创建裁剪区,具体过程如图所示:
设置好数据库后,新建一个项目作为进程3,内容基本类似进程1和进程2的代码,修改其中数据源和输出地址即可:
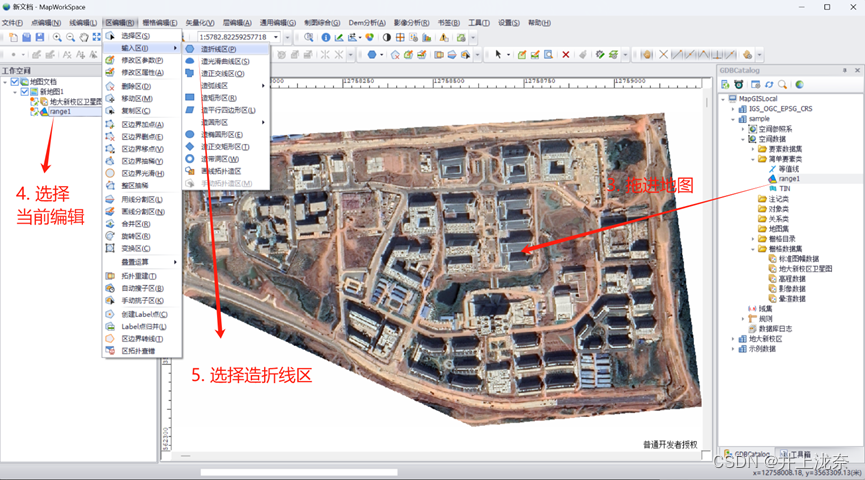
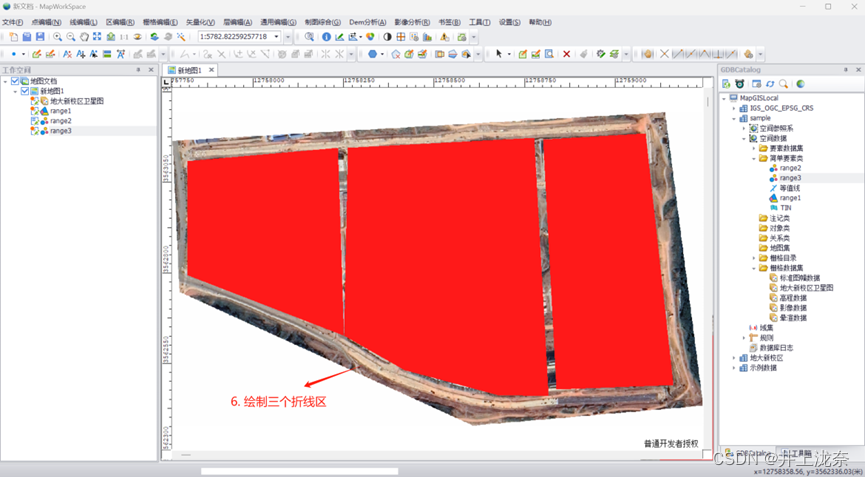
bool flg = VectorCls.Open("range3", 0);//打开简单要素类
string url = " xxx\\3.tif";
然后需要在设计中添加第三个PictureBox作为图片的可视化窗口,并且需要将属性中的SizeMode设置为StretchImage,否则缩放比例会失调。最后在窗体程序中添加一个线程去调用进程3,并将其展示到添加的图片组件中:
Process p2 = new Process();
p2.StartInfo.FileName = "xxx\\pro3.exe";
p2.StartInfo.UseShellExecute = false;
p2.StartInfo.RedirectStandardInput = true;
p2.StartInfo.RedirectStandardOutput = true;
p2.StartInfo.RedirectStandardError = true;
p2.StartInfo.CreateNoWindow = true;
p2.Start();
p2.WaitForExit();
p2.Close();
string url3 = "xxx\\3.tif"; //进程3裁剪的结果
this.pictureBox3.Load(url3);
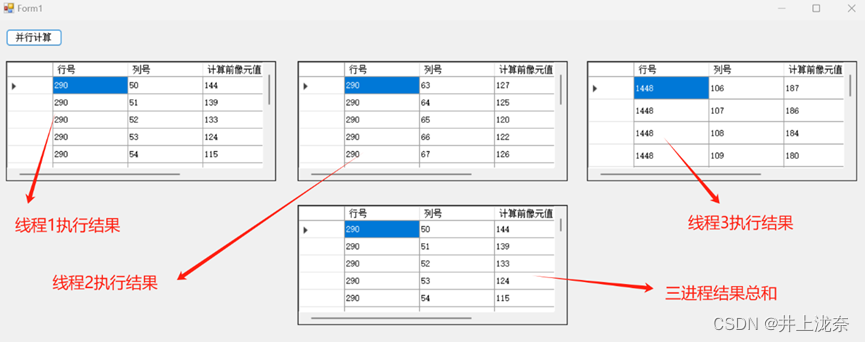
最后代码运行结果如图:

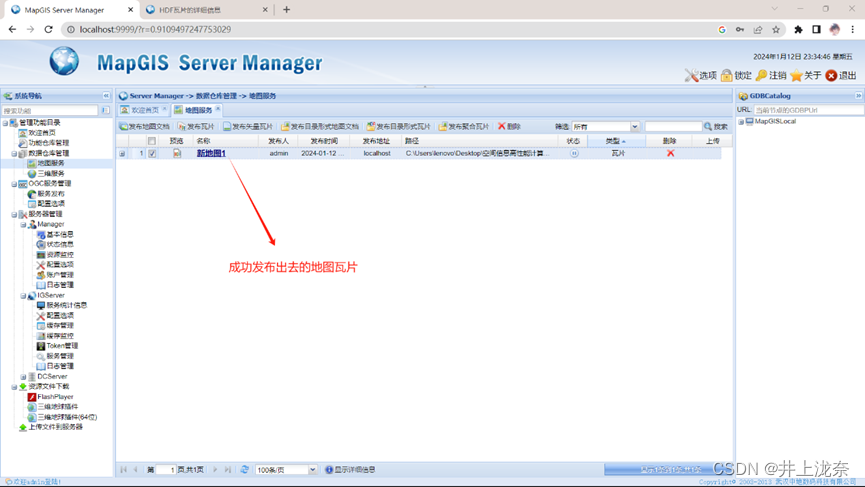
实验12
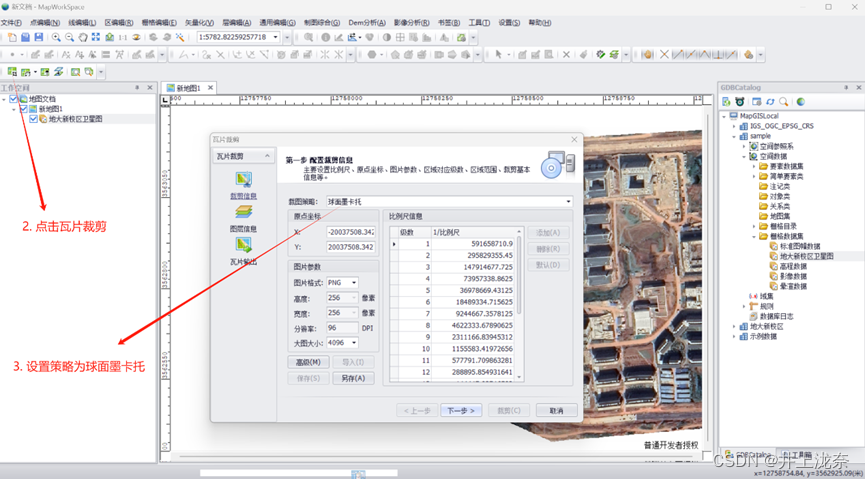
实验12完成了对网络地图的并行下载,原代码使用了两个线程想在网络地图,将其改造成三个线程,因为要使用三个进程下载,就需要地图层级有三个,因此发布瓦片时不能像书中一样,需要设置三个层级,而不是两个,具体步骤如下。
首先将地图导入,然后右键空白位置选择瓦片工具条,打开工具条。
然后点击刚才打开的工具条,选择瓦片裁剪功能,在弹窗中将截图策略设置为球面墨卡托。
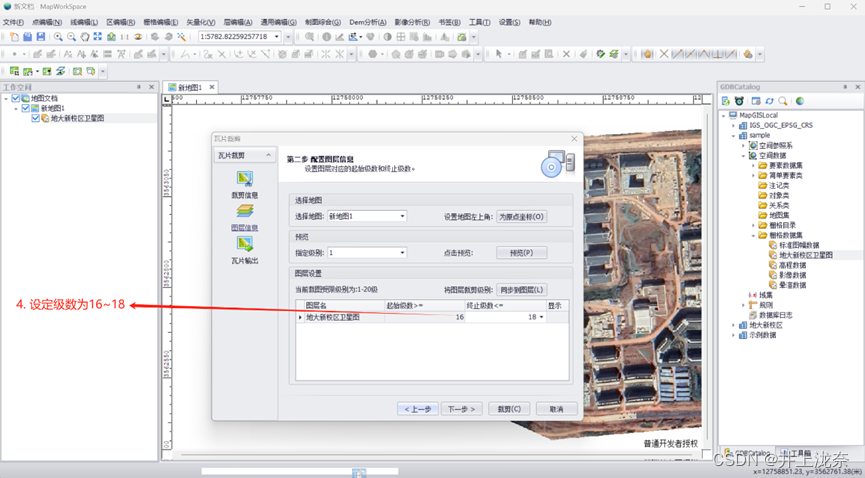
随后在下一步中将级数设置为16~18(此处和指导书不一样,因为要三个线程,所以要设置三个层级)。
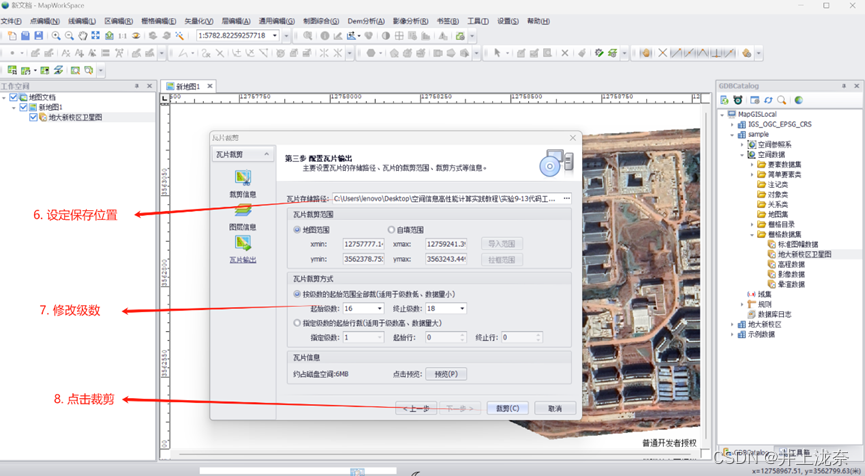
点击下一步后在弹窗中设置瓦片保存路径,并将级数设置为和上个步骤一样,最后点击裁剪即可。
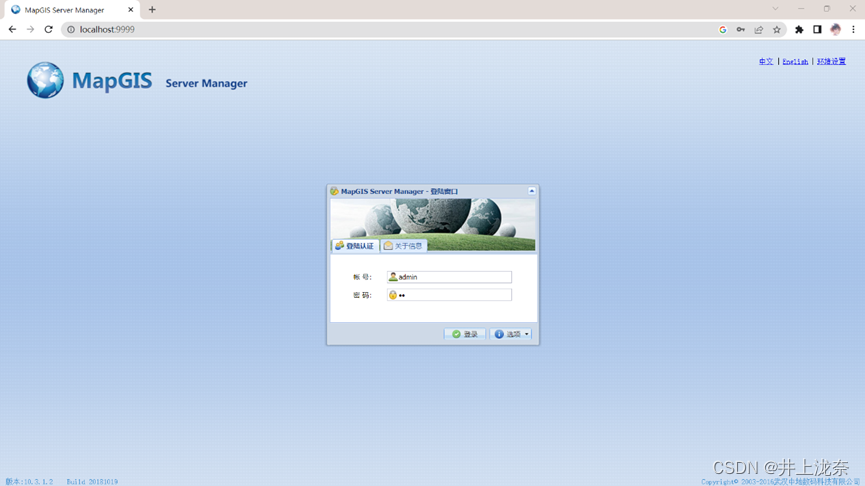
保存好裁剪文件后,浏览器中打开本机9999端口进入MapGis Manager的登陆界面,输入账密进行登陆。
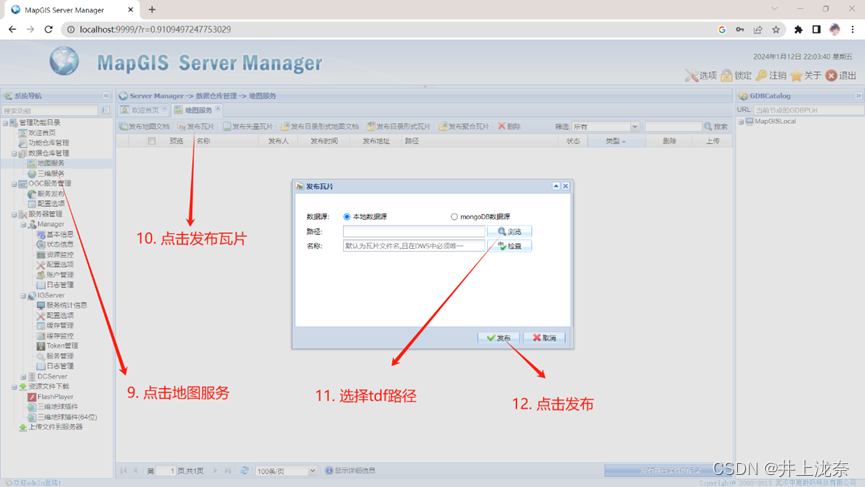
登陆成功后,在地图服务中,点击发布瓦片,然后在弹窗中选择上一步保存下来的TDF文件的路径,点击发布即可。
发布成功后,创建一个新的项目作为第三个下载进程,代码和进程1和进程2的代码较为类似,将计算宽度的代码修改,一些变量名也可以改为18后缀表示第18个层级,并且将输出路径修改为合适的路径:

WebClient client = new WebClient();
double width18 = (x2 - x1) / Math.Pow(2, 17);
double L18min = Math.Floor((xmin - x1) / width18);
double H18min= Math.Floor((y2 - ymax) / width18);
double L18max = Math.Floor((xmax - x1) / width18);
double H18max = Math.Floor((y2 - ymin) / width18);
Console.WriteLine("18级" + "," + H18min + "," +
H18max + "," + L18min + "," + L18max);
for (int i = Convert.ToInt32(H18min); i < Convert.ToInt32(H18max)+1;i++ )
{
for (int j = Convert.ToInt32(L18min); j < Convert.ToInt32(L18max)+1; j++)
{ string filename=18+"-"+num+"."+"png";
num=num+1;
string dir = "xxx\\result\\" + filename;
string url = "http://localhost:6163/igs/rest/mrms/tile/新地图1/"
+ (16-1)+"/"+i+"/"+j;
client.DownloadFile(url, dir);
}
}
然后对调用的三个进程的项目添加第三个进程并启动:
Process p2 = new Process();
p2.StartInfo.FileName = "xxx\\pro2.exe"
p2.StartInfo.UseShellExecute = false;
p2.StartInfo.RedirectStandardInput = true;
p2.StartInfo.RedirectStandardOutput = true;
p2.StartInfo.RedirectStandardError = true;
p2.StartInfo.CreateNoWindow = true;
p2.Start();
然后添加进程执行结束的代码:
p2.WaitForExit(); // 等待程序执行完退出进程
int code2 = p2.ExitCode; // 进程退出码,正确退出返回0
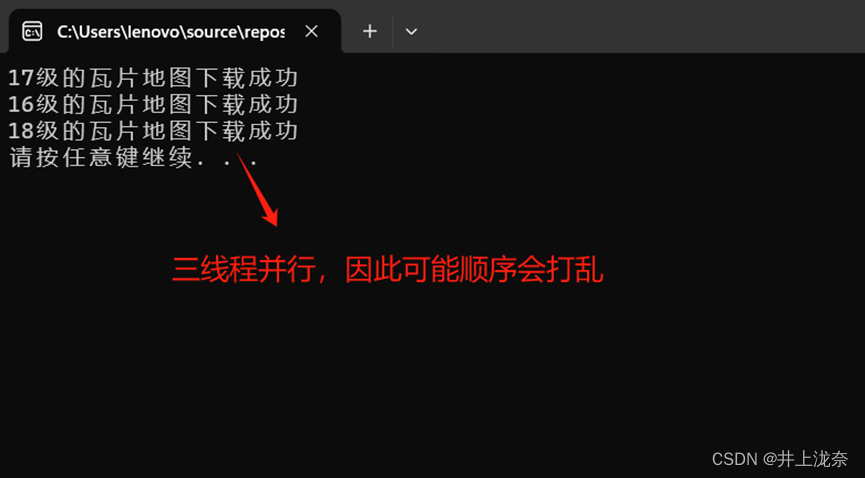
if (code2 == 0)
{
Console.WriteLine("18级的瓦片地图下载成功");
}
p2.Close(); // 进程退出码,正确退出返回0
代码运行结果如下:
下载情况如下:
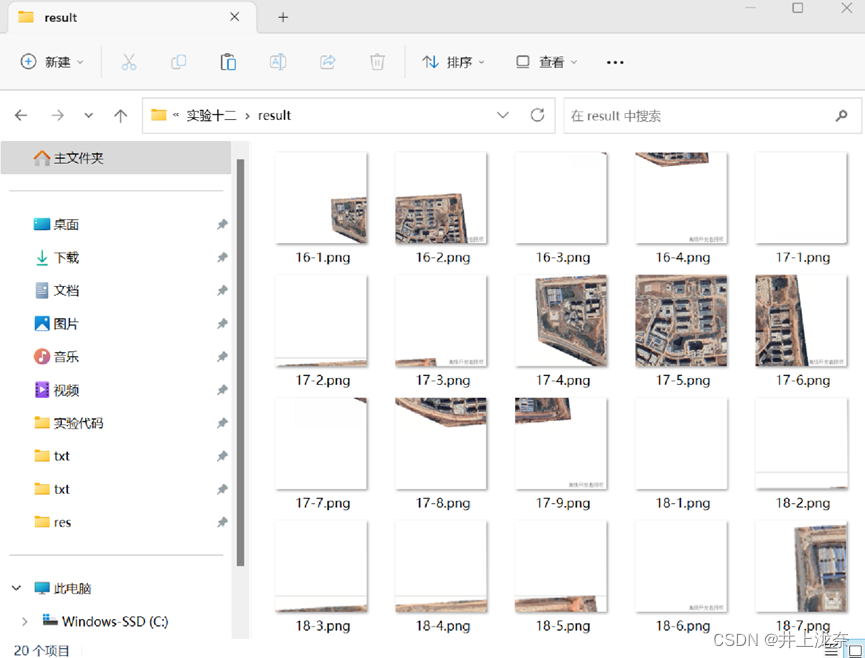
实验13
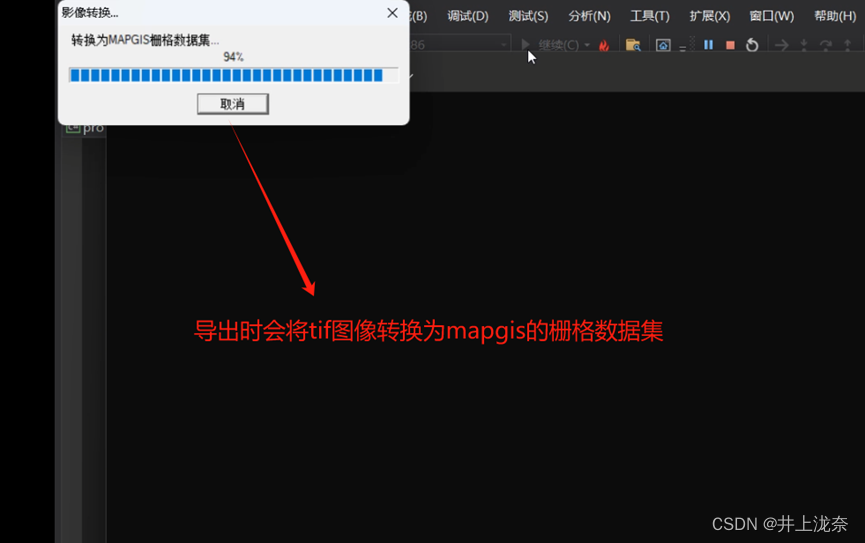
实验13实现了对空间数据的并行导入导出,原代码使用了两个线程实现,将其改造为三个线程。原代码使用了连个线程,因此在result文件夹中只有两个tif图像,为了使用三个线程需要有三个tif图像,可以将实验11中裁剪的三张tif图像复制一个过来命名为13-3.tif作为第三个线程导入导出的图像。
然后创建一个新的项目作为第三个进程,代码和第一个第二个进程的项目代码类似,稍微修改部分文件路径的代码即可,然后在调用线程的项目中添加第三个线程调用进程3的代码并启动线程:
Process p2 = new Process();
p2.StartInfo.FileName = "xxx\\pro3.exe";
p2.StartInfo.UseShellExecute = false;
p2.StartInfo.RedirectStandardInput = true;
p2.StartInfo.RedirectStandardOutput = true;
p2.StartInfo.RedirectStandardError = true;
p2.StartInfo.CreateNoWindow = true;
p2.Start();
随后添加第三个线程执行结束的代码:
p2.WaitForExit(); // 等待程序执行完退出进程
int code2 = p2.ExitCode;
if (code == 0)
{
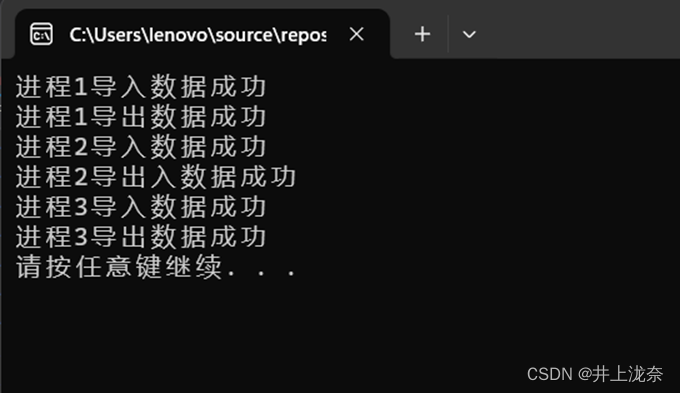
Console.WriteLine("进程3导入数据成功");
Console.WriteLine("进程3导出数据成功");
}
p2.Close();
代码执行结果如下:
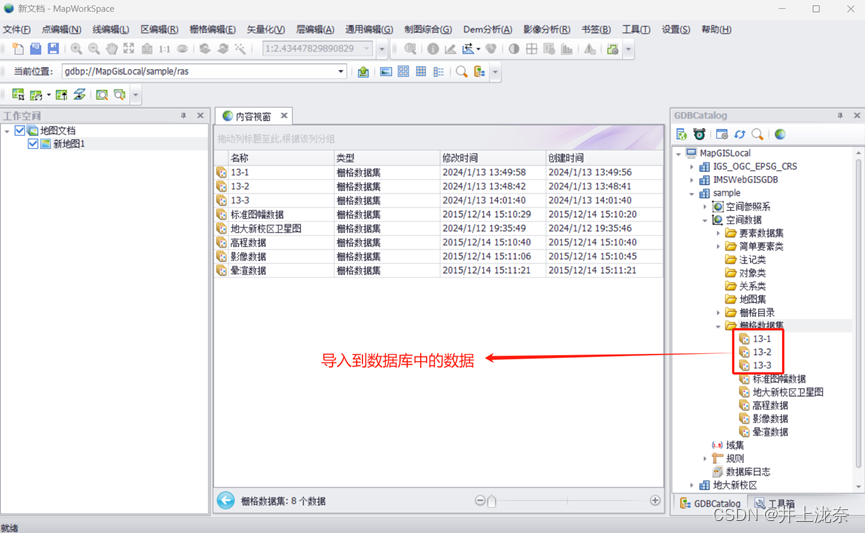
在数据库中能够查看到刚刚导入的数据:
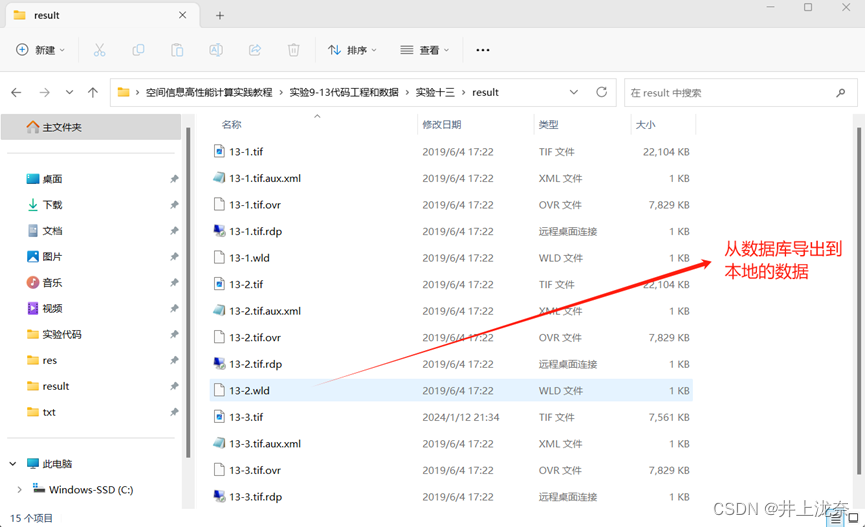
最后能在本地查看到数据库导出到本地的数据:
附录:问题汇总
问题1
简要介绍第一代、第二代、第三代具有代表性的微处理器及其特点。
1971年,英特尔公司推出了世界上第一款微处理器4004,这是第一个可用于微型计算机的四位微处理器,它包含2300个晶体管。随后英特尔又推出了8008,1974年,8008发展成8080,成为第二代微处理器。8080作为代替电子逻辑电路的器件被用于各种应用电路和设备中,如果没有微处理器,这些应用就无法实现。
由于微处理器可用来完成很多以前需要用较大设备完成的计算任务,价格又便宜,于是各半导体公司开始竞相生产微处理器芯片。Zilog公司生产了8080的增强型Z80,摩托罗拉公司生产了6800,英特尔公司于1976年又生产了增强型8085。这些芯片基本没有改变8080的基本特点,都属于第二代微处理器。它们均采用NMOS工艺,集成度约9000只晶体管,平均指令执行时间为1uS~2uS,采用汇编语言、BASIC、Fortran编程,使用单用户操作系统。
1978年英特尔公司生产的8086是第一个16位的微处理器。很快Zilog公司和摩托罗拉公司也宣布计划生产Z8000和68000。这就是第三代微处理器的起点。
8086微处理器最高主频速度为8MHz,具有16位数据通道,内存寻址能力为1MB。同时英特尔还生产出与之相配合的数学协处理器i8087,这两种芯片使用相互兼容的指令集,但i8087指令集中增加了一些专门用于对数、指数和三角函数等数学计算的指令。人们将这些指令集统一称之为x86指令集。
问题2
画出第三代微处理器的架构图,描述每个组成部分之间的联系。
其中包含有如下部件:
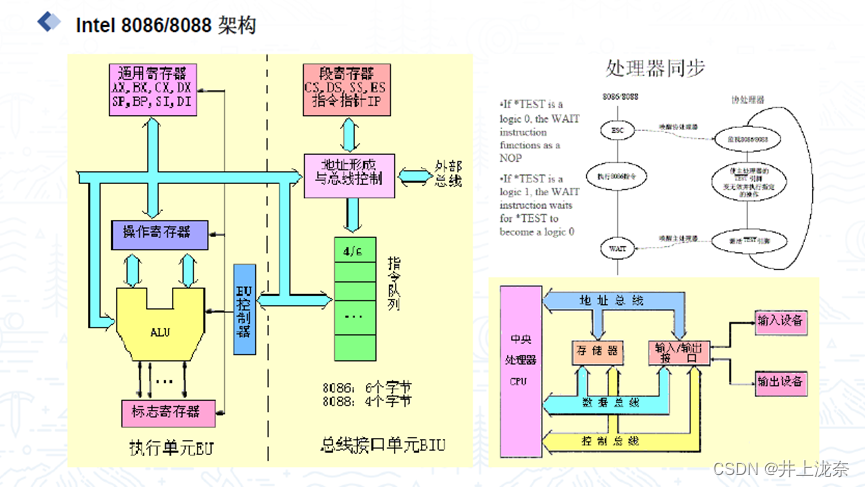
- 运算器 : 负责执行所有的算术运算和逻辑运算,是处理器的核心部分之一,对于执行指令集非常重要。
- 寄存器: 小容量但非常快速的内存位置,用于临时存储指令、数据和地址。为通用寄存器、指针和索引寄存器、段寄存器这几种类型:
- IP (指令指针): 存储下一条要执行的指令的地址。
- 标志寄存器: 存储了状态标志,比如零标志(ZF), 进位标志(CF)等,这些标志用于指示上一条指令的结果或影响接下来的指令执行。
- 控制单元 (CU): 负责解析指令,生成用于控制数据流向和处理器行为的信号,控制其他部件按照指令执行任务。
- 指令预取队列: 通过预先读取指令到队列中,可以在执行当前指令的同时,预取下一些指令。
- 总线接口单元: 负责与外部的数据总线、地址总线和控制总线的接口,管理数据、地址和控制信息的流入流出。
- 时钟发生器: 生成同步信号来协调各个组件的操作。
- 数据/地址缓冲器: 用于暂时存储从内存或I/O传输的数据,以及待处理的地址信息。
问题3
8088微处理器传送和接收数据为什么使用8位而不使用16位?
1979年,英特尔公司又开发出了8088。8086和8088在芯片内部均采用16位数据传输,所以都称为16位微处理器,但8086每周期能传送或接收16位数据,而8088每周期只采用8位。因为最初的大部分设备和芯片是8位的,而8088的外部8位数据传送、接收能与这些设备相兼容。
问题4
简要介绍什么是超线程技术。
2002年,英特尔推出新款Intel Pentium 4处理器内含创新的超线程技术(HT,Hyper-Threading)。
超线程技术:就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。
采用超线程即可在同一时间里,应用程序可以使用芯片的不同部分。虽然单线程芯片每秒钟能够处理成千上万条指令,但是在任一时刻只能够对一条指令进行操作。而超线程技术可以使芯片同时进行多线程处理,使芯片性能得到提升。
问题5
简要介绍286,386,486,586处理器的特点。
1982年,英特尔公司在8086的基础上,研制出了80286微处理器,该微处理器的最大主频为20MHz,内部、外部数据传输均为16位,使用24位内存储器的寻址,内存寻址能力为16MB。80286在以下四个方面比它的前辈有显著的改进:支持更大的内存;能够模拟内存空间;能同时运行多个任务;提高了处理速度。最早PC机的速度是4MHz,第一台基于80286的AT机运行速度为6MHz至8MHz,一些制造商还自行提高速度,使80286达到了20MHz,这意味着性能上有了重大的进步。
1985年10月17日,英特尔划时代的产品80386 DX正式发布,其内部包含27.5万个晶体管,时钟频率为12.5MHz,后逐步提高到20MHz、25MHz、33MHz、40MHz。80386DX的内部和外部数据总线是32位,地址总线也是32位,可以寻址到4GB内存,并可以管理64TB的虚拟存储空间。它的运算模式除了具有实模式和保护模式以外,还增加了一种“虚拟86”的工作方式,可以通过同时模拟多个8086微处理器来提供多任务能力。虽然当时80386没有完善和强大的浮点运算单元,但配上80387协处理器, 80386就可以顺利完成许多需要大量浮点运算的任务,从而顺利进入了主流的商用电脑市场。另外, 80386还有其他丰富的外围配件支持,如82258(DMA控制器)、8259A(中断控制器)、8272(磁盘控制器)、82385(Cache控制器)、82062(硬盘控制器)等。针对内存的速度瓶颈,英特尔为80386设计了高速缓存(Cache),采取预读内存的方法来缓解这个速度瓶颈,从此以后,Cache就和CPU成为了如影随形的东西。
1989年,英特尔推出80486芯片。这款芯片首次实破了100万个晶体管的界限,集成了120万个晶体管,使用1微米的制造工艺。80486的时钟频率从25MHz逐步提高到33MHz、 40MHz、50MHz。80486是将80386和数学协微处理器80387以及一个8KB的高速缓存集成在一个芯片内。80486中集成的80487的数字运算速度是以前80387的两倍,内部缓存缩短了微处理器与慢速DRAM的等待时间。并且,在80x86系列中首次采用了RISC(精简指令集)技术,可以在一个时钟周期内执行一条指令。它还采用了突发总线方式,大大提高了与内存的数据交换速度。由于这些改进,80486的性能比带有80387数学协微处理器的80386 DX性能提高了4倍。
1993年,新一代586 CPU问世。为了摆脱486时代微处理器名称混乱的困扰,英特尔公司把自己的新一代产品命名为Pentium(奔腾)以区别AMD和Cyrix的产品。Pentium最初级的CPU是Pentium 60和Pentium 66,分别工作在与系统总线频率相同的60MHz和66MHz两种频率下,没有倍频设置。早期的奔腾75MHz~120MHz使用0.5微米的制造工艺,后期120MHz频率以上的奔腾则改用0.35微米工艺。奔腾的性能相当平均,整数运算和浮点运算都不错。
问题6
lntel第一款64位处理器是什么型号?有什么特点?
2001年英特尔发布了Itanium(安腾)处理器。Itanium处理器是英特尔第一款64位元的产品。这是为顶级、企业级服务器及工作站设计的,在Itanium处理器中体现了一种全新的设计思想,完全是基于平行并发计算而设计(EPIC)。对于最苛求性能的企业或者需要高性能运算功能支持的应用(包括电子交易安全处理、超大型数据库、电脑辅助机械引擎、尖端科学运算等)而言,Itanium处理器基本是PC处理器中唯一的选择。
Itatium 基于一种全新的64bit处理器架构——IA-64架构,这种架构不同于以前的IA-32架构,即X86架构,也不同于Intel的EM-64T架构,即X64架构。这是一种真正的64bit架构,不同于X64架构,它不与以前的32bit架构的应用程序兼容。
问题7
并行计算机按运行机制分可分为哪几类?按系统结构分可分为哪几类?简述什么是集群计算机。
1966年由Flynn提出的分类法,称为Flynn分类法。--从计算机的运行机制进行分类 :单指令流单数据流(Single Instruction stream Single Data stream, SISD);单指令流多数据流(Single Instruction stream Multiple Data stream, SIMD);多指令流单数据流(Multiple Instruction stream Single Data stream, MISD);多指令流多数据流(Multiple Instruction stream Multiple Data stream, MIMD)。
从系统结构的角度来分类,一般有以下几种:分布式存储器的SIMD处理机;向量超级计算机(共享式存储器SIMD);对称多处理器(SMP);并行向量处理机(PVP);集群计算机。
集群计算机是随着微处理器和网络技术的进步而逐渐发展起来的,它主要用来解决大型计算问题。集群计算机是一种并行或分布式处理系统,由很多连接在一起的独立计算机组成,像一个单独集成的计算机资源一样协同工作。计算机节点可以是一个单处理器或多处理器的系统,拥有内存、 IO设备和操作系统。一个集群一般是指连接在一起的两个或多个计算机(节点)。节点可以是在一起的,也可以是物理上分散而通过网络连结在一起的。一个连接在一起的计算机集群对于用户和应用程序来说像一个单一的系统,这样的系统可以提供一种价格合理的且可获得所需性能和快速而可靠的服务的解决方案,而在以往只能通过更昂贵的专用共享内存系统来达到。
并行计算机与超级计算机技术,为多核计算机的出现奠定了基础,而集成电路技术是多核芯片得以实现的物理条件。
问题8
阐述SIMD和MIMD之间的区别?
SISD就是普通的顺序处理的串行机。SIMD和MIMD是典型的并行计算机。
在一台SIMD计算机中,有一个控制部件(又称为控制单元,control unit)和许多处理单元(processing unit)。大量的处理单元通常构成阵列,因此SIMD计算机有时也称为阵列处理机。所有的处理单元在控制部件的统一控制下工作。控制部件向所有的处理单元广播同一条指令,所有的处理单元同时执行这条指令,但是每个处理单元操作的数据不同。控制部件可以有选择地屏蔽掉一些处理单元,被屏蔽掉的处理单元不执行控制部件广播的指令。
在MIMD计算机中没有统一的控制部件。在MIMD中,各处理器可以独立地执行不同的指令。实际上,在SIMD机中,各处理单元执行的是同一个程序,而在MIMD机上,各处理器可以独立执行不同的程序。在MIMD中,每个处理器都有控制部件,各处理器通过互连网络进行通信。
MIMD结构比SIMD结构更加灵活。SIMD计算机通常要求实际问题包含大量的对不同数据的相同运算(例如向量运算和矩阵运算)才能发挥其优势。MIMD可以适应更多的并行算法,因此可以更加充分地开掘实际问题的并行性。SIMD所使用的CPU通常是专门设计的,而MIMD可以使用通用CPU。
问题9
什么是摩尔定律?阐述摩尔定律会失效的原因。
英特尔公司的创始人之一戈登•摩尔(Gordon Moore)于1965年在总结存储器芯片的增长规律时,发现“微芯片上集成的晶体管数目每12个月翻一番”,称为摩尔定律。后来的发展很好地验证了这一说法,后来表述为“集成电路的集成度每18个月翻一番”,或者说“三年翻两番”,这表明半导体技术是按一个较高的指数规律发展的。从第一款微处理器4004至今,微处理器使用的晶体管数量的增长情况基本上符合摩尔定律,每2~3年集成度提高两倍,器件特征尺寸按比例缩小,工艺技术更新一代。
问题10
计算频率1GHz的CPU与2GHz的CPU之间的功耗比。
功耗比
=
c
f
1
3
c
f
2
3
=
(
f
1
f
2
)
3
=
8
\text{功耗比 }=\frac{cf_1^3}{cf_2^3}=(\frac{f_1}{f_2})^3=8
功耗比 =cf23cf13=(f2f1)3=8
问题11
频率为1.5GHz的双核CPU相当于频率为多少的单核CPU的功耗,给出推导过程。
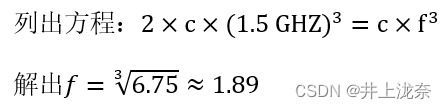
问题12
多核处理器的雏形是哪一个型号?简述其特点。
80486则将80386和80387以及一个8KB的高速缓存集成在一个芯片内。从一定意义上,80486可以称为多核处理器的原始雏形。
1989年,英特尔推出80486芯片。这款芯片首次实破了100万个晶体管的界限,集成了120万个晶体管,使用1微米的制造工艺。80486的时钟频率从25MHz逐步提高到33MHz、 40MHz、50MHz。80486是将80386和数学协微处理器80387以及一个8KB的高速缓存集成在一个芯片内。80486中集成的80487的数字运算速度是以前80387的两倍,内部缓存缩短了微处理器与慢速DRAM的等待时间。并且,在80x86系列中首次采用了RISC(精简指令集)技术,可以在一个时钟周期内执行一条指令。它还采用了突发总线方式,大大提高了与内存的数据交换速度。由于这些改进,80486的性能比带有80387数学协微处理器的80386 DX性能提高了4倍。
问题13
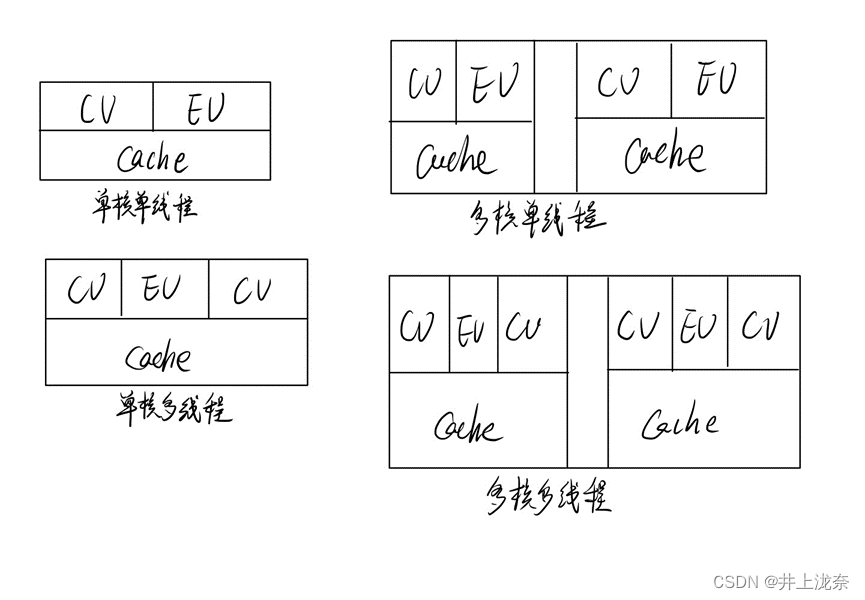
处理器根据核心结构的不同可分为哪几类?分别画出每种类型的结构示意图。
如图所示:
问题14
分别解释什么是指令级并行和线程级并行。
- 指令级并行
当指令之间不存在相关时,它们在流水线中是可以重叠起来并行执行的。这种指令序列中存在的潜在并行性称为指令级并行。在机器指令级并行,通过指令级并行,处理器可以调整流水线指令重执行顺序,并将它们分解成微指令,能够处理某些在编译阶段无法知道的相关关系(如涉及内存引用时),并简化编译设计。能够允许一个流水线机器上编译的指令,在另一个流水线上也能有效运行。指令级并行能使处理器速度迅速提高。 - 线程级并行
线程级并行将处理器内部的并行由指令级上升到线程级,旨在通过线程级的并行来增加指令吞吐量,提高处理器的资源利用率。当某一个线程由于等待内存访问结构而空闲时,可以立刻导入其他的就绪线程来运行。处理器流水线就能够始终处于忙碌的状态,系统的处理能力提高了,吞吐量也相应提升。服务器可以通过每个单独的线程为某个客户服务(web服务器,数据库服务器)。