大家好,人脸表情识别是计算机视觉领域中的一个重要研究方向,它涉及到对人类情感状态的理解和分析。随着深度学习技术的发展,基于深度学习的人脸表情识别系统因其高精度和强大的特征学习能力而受到广泛关注。本文旨在探讨基于深度学习的人脸表情识别系统的设计与实现,从数据处理、模型训练等多个方面进行全面分析。
项目地址:基于深度学习的人脸表情识别系统设计与实现
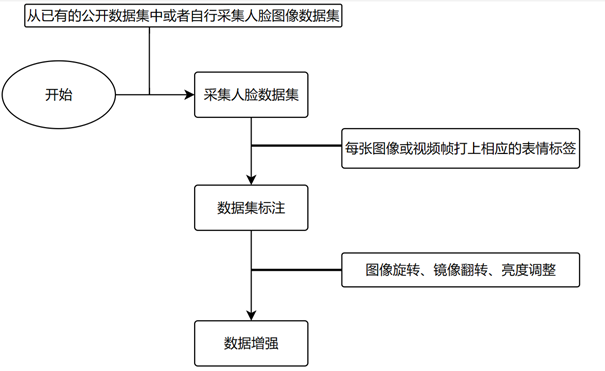
1.数据使用与处理
可以使用已有的公开数据集进行人脸表情识别模型的训练,比如FER2013、CK+、JAFFE等数据,这些数据集通常包含了大量的人脸图像,每张图像都标注了相应的表情类别,上传一部分照片,给照片打上相应的标签。
标注工作可以通过人工标注或者半自动标注工具来完成,对于已有的数据集或者采集到的数据,可以使用数据增强技术来增加样本的多样性和数量。数据增强技术包括图像旋转、镜像翻转、亮度调整。
2.识别模型构建
在人脸表情识别系统中,ResNet模型通过残差连接保证了信息和梯度的有效流动,CNN模型通过卷积和池化操作提取图像特征,而Xception模型则通过深度可分离卷积提升模型的性能和效率。这些模型的结合使用,可以提高人脸表情识别的准确性和实时性。
2.1 Resnet模型
Resnet(Residual Network)模型是一种深度残差网络结构,通过使用残差块(Residual Block)解决了深度神经网络训练过程中的梯度消失和梯度爆炸问题。它在人脸表情识别等领域取得了很好的效果。ResNet由多个残差块组成,每个残差块包含多个卷积层和恒等映射,通过跨层连接将输入和输出相加,保证了网络的信息传递和梯度流动。
x = Conv2D(32, (3, 3), strides=(2, 2), use_bias=False)(img_input)
x = BatchNormalization(name='block1_conv1_bn')(x)
x = Activation('relu', name='block1_conv1_act')(x)
x = Conv2D(64, (3, 3), use_bias=False)(x)
x = BatchNormalization(name='block1_conv2_bn')(x)
x = Activation('relu', name='block1_conv2_act')(x)
residual = Conv2D(128, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
2.2 CNN模型
CNN(Convolutional Neural Network)模型是一种经典的卷积神经网络结构,由卷积层、池化层和全连接层组成,通过卷积操作和池化操作提取图像的特征,并通过全连接层进行分类。CNN由于结构简单、易于理解和实现,在人脸表情识别等任务中也取得不错的效果。
def simple_CNN(input_shape, num_classes):
model = Sequential()
model.add(Convolution2D(filters=16, kernel_size=(7, 7), padding='same',
name='image_array', input_shape=input_shape))
model.add(BatchNormalization())
model.add(Convolution2D(filters=16, kernel_size=(7, 7), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(2, 2), padding='same'))
model.add(Dropout(.5))
model.add(Convolution2D(filters=32, kernel_size=(5, 5), padding='same'))
model.add(BatchNormalization())
model.add(Convolution2D(filters=32, kernel_size=(5, 5), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(2, 2), padding='same'))
model.add(Dropout(.5))
model.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Convolution2D(filters=64, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(2, 2), padding='same'))
model.add(Dropout(.5))
model.add(Convolution2D(filters=128, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Convolution2D(filters=128, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(AveragePooling2D(pool_size=(2, 2), padding='same'))
model.add(Dropout(.5))
model.add(Convolution2D(filters=256, kernel_size=(3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Convolution2D(filters=num_classes, kernel_size=(3, 3), padding='same'))
model.add(GlobalAveragePooling2D())
model.add(Activation('softmax',name='predictions'))
return model2.3 Xeception模型
Xception是一种极端深度卷积神经网络结构,是Google提出的一种基于Inception架构改进的模型。Xception采用了深度可分离卷积(Depthwise Separable Convolution)替代传统的卷积操作,大大减少了模型参数和计算量,并提升了模型的性能。Xception在人脸表情识别等领域也有很好的应用。
def big_XCEPTION(input_shape, num_classes):
img_input = Input(input_shape)
x = Conv2D(32, (3, 3), strides=(2, 2), use_bias=False)(img_input)
x = BatchNormalization(name='block1_conv1_bn')(x)
x = Activation('relu', name='block1_conv1_act')(x)
x = Conv2D(64, (3, 3), use_bias=False)(x)
x = BatchNormalization(name='block1_conv2_bn')(x)
x = Activation('relu', name='block1_conv2_act')(x)
residual = Conv2D(128, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(128, (3, 3), padding='same', use_bias=False)(x)
x = BatchNormalization(name='block2_sepconv1_bn')(x)
x = Activation('relu', name='block2_sepconv2_act')(x)
x = SeparableConv2D(128, (3, 3), padding='same', use_bias=False)(x)
x = BatchNormalization(name='block2_sepconv2_bn')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = layers.add([x, residual])
residual = Conv2D(256, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = Activation('relu', name='block3_sepconv1_act')(x)
x = SeparableConv2D(256, (3, 3), padding='same', use_bias=False)(x)
x = BatchNormalization(name='block3_sepconv1_bn')(x)
x = Activation('relu', name='block3_sepconv2_act')(x)
x = SeparableConv2D(256, (3, 3), padding='same', use_bias=False)(x)
x = BatchNormalization(name='block3_sepconv2_bn')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = layers.add([x, residual])
x = Conv2D(num_classes, (3, 3),
#kernel_regularizer=regularization,
padding='same')(x)
x = GlobalAveragePooling2D()(x)
output = Activation('softmax',name='predictions')(x)
model = Model(img_input, output)
return model3.分类结果输出模块
分类结果输出模块应该在用户界面上以清晰、直观的方式展示分类结果,可以采用图形化展示的方式,如在界面上显示识别出的表情图标或动态效果,以直观地反映分类结果。同时,也可以通过文本形式显示分类结果,包括类别名称、置信度等信息,以便用户查看。
for (i, (emotion, prob)) in enumerate(zip(self.EMOTIONS, preds)):
# 用于显示各类别概率
text = "{}: {:.2f}%".format(emotion, prob * 100)
# 绘制表情类和对应概率的条形图
w = int(prob * 300) + 7
cv2.rectangle(canvas, (7, (i * 35) + 5), (w, (i * 35) + 35), (224, 200, 130), -1)
cv2.putText(canvas, text, (10, (i * 35) + 23), cv2.FONT_HERSHEY_DUPLEX, 0.6, (0, 0, 0), 1)为了增强用户体验,分类结果输出模块可以提供一些交互功能,如点击图标或结果文本可以查看详细的分类信息、切换不同的分类结果展示方式等。用户可以通过这些交互功能更方便地了解分类结果,进行进一步的操作或分析。分类结果输出模块应该能够实时更新显示最新的分类结果。当系统进行分类预测时,输出模块应该及时更新界面上的显示内容,以确保用户能够即时获取到最新的分类信息。
在设计分类结果输出模块时,需要考虑到可能出现的异常情况,如模型无法对输入数据进行分类或分类结果不确定等。系统应该具备相应的异常处理机制,能够给出友好的提示信息并处理异常情况,以保证系统的稳定性和可靠性。为了方便系统管理和故障排查,分类结果输出模块可以设计成具有日志记录功能。系统可以记录每次分类结果的相关信息,包括时间、输入数据、输出结果等,以便日后查看和分析。
4.模型训练与使用
对构建的模型进行训练,优化器采用adam,定义回调函数 Callbacks 用于训练过程,并且定义模型权重位置、命名等信息。划分训练、测试集,并引入图片产生器,在批量中对数据进行增强,扩充数据集大小。
# 载入数据集
faces, emotions = load_fer2013()
faces = preprocess_input(faces)
num_samples, num_classes = emotions.shape
# 划分训练、测试集
xtrain, xtest, ytrain, ytest = train_test_split(faces, emotions, test_size=0.2, shuffle=True)
# 图片产生器,在批量中对数据进行增强,扩充数据集大小
data_generator = ImageDataGenerator(
featurewise_center=False,
featurewise_std_normalization=False,
rotation_range=10,
width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=.1,
horizontal_flip=True)运行项目前,需要下载相关的库和python环境,比如:Keras、pyqt5、Scikit-learn、tensorflow、imutils、opencv-python等。运行main.py文件,成功后会有一个登录界面,要登陆账号和密码才能进入人脸表情识别主界面。
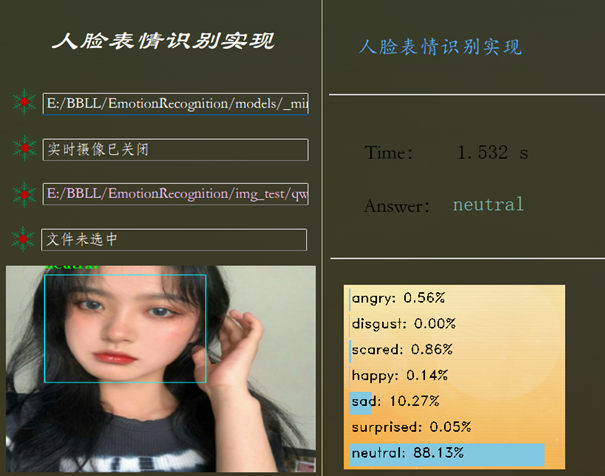
通过数据预处理、模型选择、训练优化、分类结果输出等多个操作,实现基于深度学习的人脸表情识别系统,为准确快速地识别和分析人类面部表情提供了保障。