关键要点
- 向量检索在AI中用于信息检索、推荐系统和图像搜索,研究表明其通过高维空间中的向量表示数据来提升搜索相关性。
- 它依赖于嵌入技术(如Word2Vec、BERT)和近邻算法(如kNN、ANN),证据倾向于其在处理大规模数据时效率高。
- 实际案例包括Google Images的视觉搜索和Spotify的音乐推荐,显示其在多模态搜索中的广泛应用。
什么是向量检索
向量检索是一种在AI中用于信息检索的技术,通过将数据(如文本、图像)表示为高维空间中的向量,并根据查询向量与这些向量的相似性来排名和检索相关项。与传统的关键词搜索不同,向量检索能捕捉数据的语义含义,提供更相关的搜索结果。
应用场景
向量检索广泛应用于:
- 信息检索:例如,找到与查询语义相似的文档。
- 推荐系统:如根据用户偏好推荐相似产品。
- 图像和视频搜索:通过视觉相似性查找相关内容。
技术原理
向量检索的核心是嵌入,通过机器学习模型(如Word2Vec、BERT)将数据映射为向量。相似性通常通过余弦相似度或欧几里得距离来衡量。高效搜索依赖于近邻算法,如精确的k-Nearest Neighbors (kNN) 或近似的Approximate Nearest Neighbor (ANN)。
优缺点
- 优点:能理解语义,提供多模态搜索,结合ANN算法处理大数据效率高。
- 缺点:设置和维护复杂,嵌入质量直接影响性能,且更新嵌入资源密集。
向量检索在AI中的应用与技术解析
引言
向量检索(Vector Search)是一种在人工智能(AI)领域中用于信息检索和相似性搜索的技术。它通过将数据(如文本、图像、音频)表示为高维空间中的向量,并利用这些向量的相似性来排名和检索相关项。与传统的关键词搜索相比,向量检索能够捕捉数据的语义含义,从而提供更相关、更自然的搜索结果。本报告将详细探讨向量检索的基本原理、常用算法、应用场景、优缺点,并附带代码示例和实际案例,帮助读者更好地理解和应用该技术。
基本原理
向量嵌入
向量嵌入是将数据映射为高维空间中的数值表示的过程,旨在捕捉数据的语义或特征。例如:
- 文本数据:可以使用Word2Vec、GloVe或基于变换器的模型如BERT生成词或句子的嵌入。这些模型通过在大型语料库上训练,学习到语义相似的词或句子在向量空间中更接近。
- 图像数据:通过卷积神经网络(CNNs)生成图像嵌入,捕捉视觉特征。
- 音频数据:类似地,可以通过深度学习模型生成音频的嵌入。
嵌入的生成依赖于机器学习模型,这些模型通常在数百万样本上训练,以确保嵌入能反映数据的上下文和含义。
相似性度量
向量检索的核心是测量两个向量之间的相似性。常用的度量包括:
-
余弦相似度:计算两个向量夹角的余弦值,特别适合高维数据,公式为:
-
欧几里得距离:测量两个点在欧几里得空间中的直线距离,公式为:
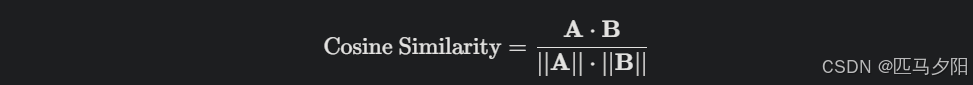
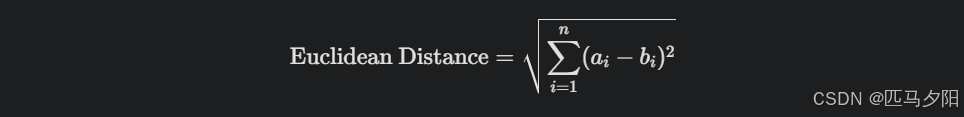
其他度量如曼哈顿距离(L1范数)也常用于特定场景。
这些度量帮助确定查询向量与数据向量之间的“近邻”,从而实现高效检索。
常用算法与技术
精确方法
- k-Nearest Neighbors (kNN):这是最基本的精确方法,通过计算查询向量与所有数据向量的距离,找到最近的k个邻居。虽然准确性高,但对于大规模数据集,计算复杂度高,通常为O(N·d),其中N是数据点数,d是维度。
近似方法
为了提高效率,近似方法被广泛采用:
- Approximate Nearest Neighbor (ANN):通过牺牲一定准确性,采用近似算法来加速搜索,适合高维空间中的大规模数据。
- ScaNN (Scalable Nearest Neighbors):由Google开发,是一种高效的向量相似性搜索算法,特别适用于语义搜索,结合量化技术和树结构优化。
- HNSW (Hierarchical Navigable Small Worlds):基于图的算法,通过构建层次化的导航小世界网络,高效处理大型数据集。
常用库
- Faiss:Facebook开发的库,支持高效的相似性搜索和聚类,特别适合密集向量。
- Annoy:Spotify开发的库,使用树结构进行近似最近邻搜索。
- ScaNN:Google的库,优化了大规模向量搜索性能。
这些库通过索引技术和预计算,显著降低了搜索时间,尤其在处理百万级或亿级数据时表现优异。
应用场景
向量检索在多个领域有广泛应用:
- 信息检索:通过语义相似性找到相关文档,而不仅仅依赖关键词匹配。例如,Slack的搜索功能使用向量检索找到上下文相关的消息。
- 推荐系统:如Spotify的音乐推荐,根据用户听歌历史推荐相似歌曲,或Amazon根据购买行为推荐产品。
- 图像和视频搜索:Google Images使用向量检索实现视觉相似性搜索,基于图像嵌入找到相似的图片。
- 语音和音频搜索:通过音频嵌入,找到相似的语音片段或识别说话者。
- 异常检测:通过识别向量空间中远离任何聚类的点,检测异常数据点。
这些场景展示了向量检索在多模态数据处理中的灵活性。
实际案例
以下是几个实际案例,展示向量检索的实际应用:
- Google Images:通过视觉嵌入实现基于图像的相似性搜索,用户可以上传图片找到相似的视觉内容 (Vector Search | Vertex AI | Google Cloud).
- Spotify的音乐推荐:使用音频和用户偏好的向量嵌入,推荐与用户听歌习惯相似的音乐 (What is vector search? | IBM).
- Slack的搜索:通过文本嵌入实现语义搜索,找到与查询意图相关的消息 (Vector Search Explained | Weaviate).
- Amazon的产品推荐:可能使用向量相似性推荐与用户浏览或购买历史相关的产品 (Advanced AI Vector Search for Business Data Insights).
这些案例表明,向量检索在提升用户体验和业务效率方面具有显著价值。
优缺点
优点
- 语义理解:向量检索能捕捉数据的语义含义,提供比关键词搜索更相关的结果。
- 多模态搜索:支持文本、图像、音频等多种数据类型,适合跨模态应用。
- 效率:结合ANN算法,能高效处理大规模数据集,满足实时搜索需求。
缺点
- 复杂性:设置和维护向量检索系统需要机器学习和数据科学的专业知识。
- 嵌入质量:搜索性能高度依赖嵌入的质量,差的嵌入可能导致不准确的结果。
- 维护成本:随着新数据增加,需要定期更新嵌入,资源消耗较大。
- 可解释性:基于高维向量的相似性搜索结果可能难以解释,影响用户信任。
代码示例
以下提供两个Python代码示例,展示向量检索的实现。
简单示例:使用NumPy实现暴力搜索
import numpy as np
# 生成随机数据,100个5维向量
data = np.random.rand(100, 5)
# 查询向量
query = np.random.rand(1, 5)
# 计算欧几里得距离
distances = np.sqrt(np.sum((data - query) ** 2, axis=1))
# 找到最近邻的索引
nearest_index = np.argmin(distances)
print("最近邻索引:", nearest_index)
高级示例:使用Sentence Transformers和FAISS实现句子相似性搜索
首先安装必要的库:
pip install sentence-transformers faiss-cpu
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
# 加载预训练的句子变换模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 样本句子
sentences = [
"这是一个测试句子。",
"另一个用于测试的句子。",
"这似乎与第一个相似。",
"完全不同的句子。"
]
# 生成嵌入
embeddings = model.encode(sentences)
# 创建FAISS索引,假设嵌入大小为384
index = faiss.IndexFlatL2(384)
index.add(np.array(embeddings).astype('float32'))
# 查询句子
query_sentence = "这是一个测试句子。"
# 生成查询嵌入
query_embedding = model.encode([query_sentence])
# 搜索最近的2个邻居
k = 2
distances, indices = index.search(np.array(query_embedding).astype('float32'), k)
# 打印结果
print("最近邻句子:", [sentences[i] for i in indices[0]])
这些示例展示了从简单暴力搜索到使用高级库的逐步实现,适合不同规模和复杂度的应用。
应用场景实例
以下提供两个具体实例,帮助理解向量检索的应用:
实例1:电子商务产品搜索
一个电子商务平台可以使用向量检索,根据客户浏览历史或购买行为提供更相关的产品推荐。通过将产品描述和客户偏好嵌入向量空间,平台可以找到语义相似的商品,提升用户体验并增加销售额。例如,搜索“运动鞋”可能推荐与用户之前购买的跑步鞋相似的休闲鞋。
实例2:法律服务中的文档检索
在法律服务中,向量检索可用于根据语义内容检索相关案例法或法律文档。例如,律师可以输入当前案件的描述,系统通过向量相似性找到相似的先例或相关判例,节省时间并提高研究准确性。
历史与发展
向量检索的历史可以追溯到20世纪50年代的计算语言学,试图将词表示为向量。1960年代的研究关注语义差异的测量,1980年代自然语言处理(NLP)转向机器学习模型。1980年代末,潜语义分析(LSA/LSI)被开发用于创建向量并执行信息检索。2013年,Word2Vec的引入使用神经网络生成词嵌入,进一步推动了向量检索的发展 (What is vector search? - Algolia Blog | Algolia).
结论
向量检索作为AI中的关键技术,通过嵌入和相似性搜索提供了强大的信息检索能力。其在信息检索、推荐系统和多模态搜索中的应用展示了其潜力,但也面临复杂性和维护成本的挑战。通过理解其原理和实践,组织可以更好地利用数据,提升决策效率。