文章目录
1、数组的优劣
优势:是一种简单的线性序列,可以快速地访问数组元素,效率高。如果从效率和类型检查地角度讲,数组是最好的。
劣势:不灵活,容量需要事先定义好,不能随着需求地变化而扩容。
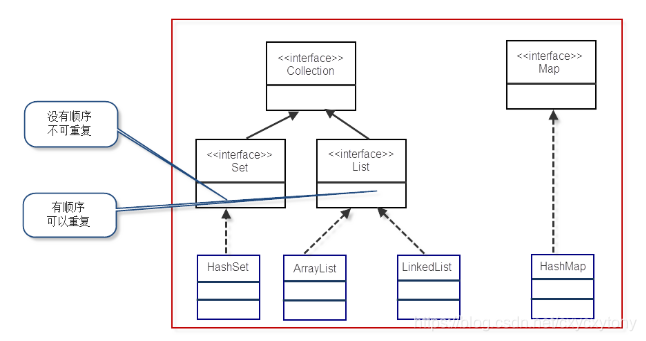
数组并不能满足我们对于“管理和组织数据的需求”,所以问哦们许哟啊一种更强大、更灵活、容量随时可扩的容器来装载我们的对象,这就是我们今天要学习的容器,也叫集合(Collection)。以下是容器的接口层次图:
2、泛型
泛型是JDK1.5以后增加的,它可以帮助我们建立类型安全的集合。在使用的泛型的集合中,遍历时不必进行强制类型转换。JDK提供了支持泛型的编译器,讲运行时的类型检查提前到了编译时执行,提高了代码可读性和安全型。
泛型的本质就是“数据类型的参数化”。我们可以把“泛型”理解为数据类型的一个占位符(形式参数),即告诉编译器,在调用反泛型时必须传入实际参数。
3、Collection接口
Clooection表示一组对象,它是集中、收集的意思。Collection接口的两个子接口时List、Set接口。
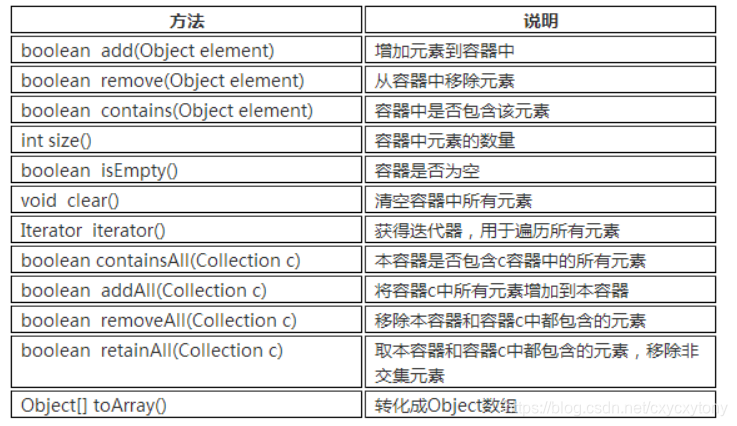
Collection接口中定义的方法:
由于 List、Set是Collection的子接口,意味着所有List、Set的实现类都有上面的方法。
4、List接口
List是有序、可重复的容器。
有序: List中每个元素都有索引标记。可以根据元素的索引标记(在Lis中的位置)访问元素,从而精确控制这些元素。
可重复: List允许加入重复的元素。更确切地讲,List通常允许满足e1.equals(e2)地元素重复加入容器。
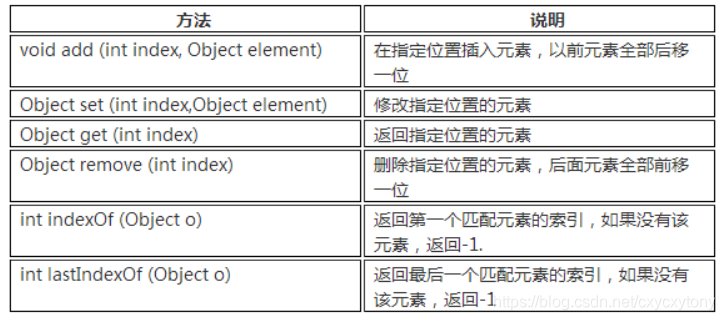
除了Collection接口中地方法,List多了一些更顺序(索引)有关地方法,参见下表:
List接口常用地实现类有3个:ArrayList、LinkedList和Vector。
4.1、ArrayList特点和底层实现
ArrayList底层是用 数组 实现的存储。
特点: 查询效率高,增删效率低,线程不安全。
我们都知道,数组长度是有限的,而ArrayList是可以存放任意数量的对象,长度不受限制,那么它是怎么实现的呢?本质上就是通过定义新的更大的数组,将旧数组中的内容拷贝到新数组,来时先扩容。
4.2、LinkedListt特点和底层实现
LinkedList底层用 双向链表 实现的存储。
特点: 查询效率低,增删效率高,线程不安全。
双向链表也叫双链表,是链表的一种,它的每个数据节点中都有两个指针,反别指向前一个节点和后一个节点。
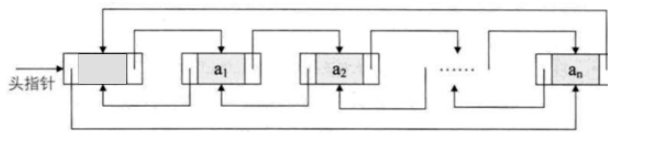
每个节点都应该有3部分内容:
class Node {
Node previous; //前一个节点
Object element; //本节点保存的数据
Node next; //后一个节点
}
4.3、Vector向量
Vector底层使用 数组 实现的List,相关的方法都加了同步检查,因此“线程安全,效率低”。
4.4、如何选用ArrayList、LinkedList、Vector
1、需要线程安全时,用Vector
2、不存在线程安全问题时,并且查找较多用ArraryList(一般使用它)
3、不存在线程安全问题时,增加或删除原始较多用LinkedList。
5、Map接口
Map是用来存储 “键(key)-值(value)对” 的。Map类中存储的“键值对”通过键来标识,所以“键对象”不能重复。
Map接口的实现类有HashMap、TreeMap、HashTable、Properties等。
Map接口中的常用方法:
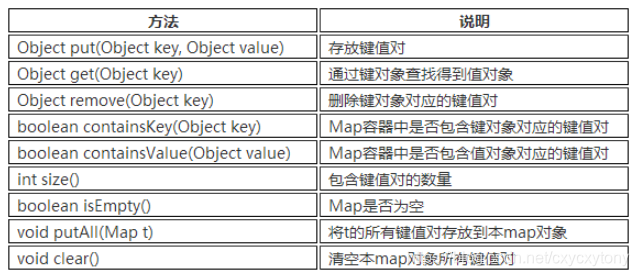
5.1、HashMap特点和底层实现
HashMap采用哈希算法实现,时Map接口最常用的实现类。由于底层采用了哈希表存储数据,要求键不能重复,如果发生重复,新的键值会替换旧的键值,HashMap在查找、删除、修改方面有非常高的效率。
HashMap底层实现采用了哈希表,这是一种非常重要的数据结构。
数据结构中由数组和链表来实现对数据的存储,他们各有特点。
(1)数组:占用空间连续。寻址容易,查询速度快。但是,增加和删除效率非常低。
(2)链表:占用空间不连续。寻址困难,查询速度慢。但是,增加和删除效率非常高。
那么,我们能不能结合数组和链表的优点(即查询快,增删效率也高)呢?答案就是“哈希表”。哈希表的本质就是“数组+链表”。
5.1.1、底层结构
从HashMap的底层源码中我们可以知道,HashMap的核心数据结构是一个个的节点,节点继承于Map.Entry,Entry的意思为条目。(其实这里的Node本质上也是一个Entry)
哈希表的基本结构就是“数组+链表”。我们打开HashMap源码,发现:
其中Node<K,V>[] table就是HashMap的核心数据结构,我们也称之为"位桶数字组",我们再继续看看Node是什么
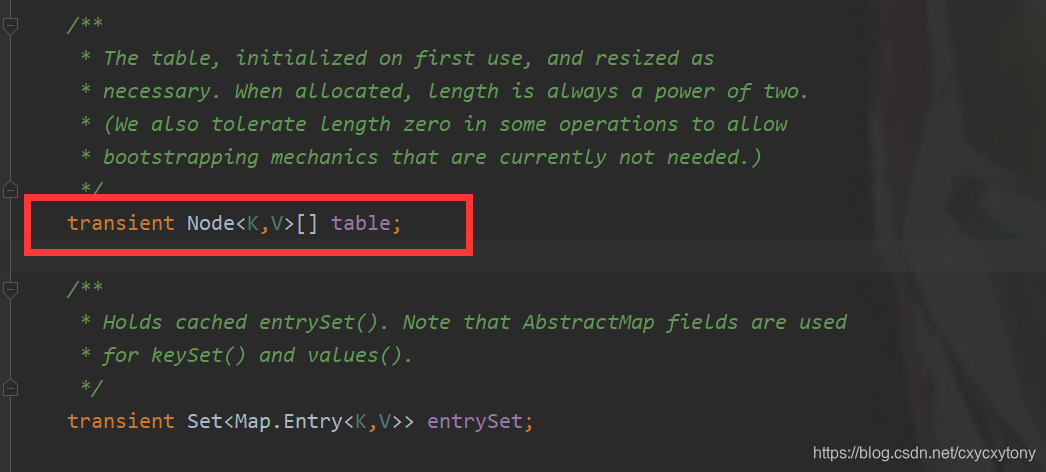
一个Node对象存储了:
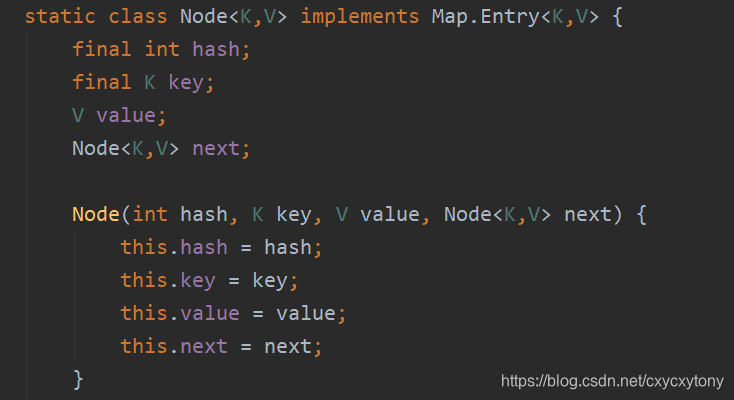
- key:键值对 ,value:键值对
- next:下一个节点
- hash:键对象的hash值
显然每一个Node对象就是一个单项链表结构,我们使用图形表示一个Node对象的典型示意:
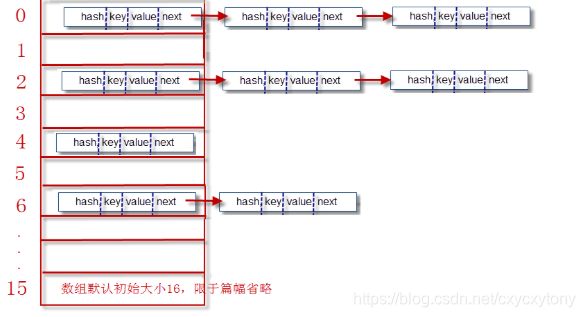
然后,我们画出Node<K,V>[] 的结构:

5.1.2、存储数据过程put(key, value)
明白了HashMap的基本结构后,我们继续深入学习HashMap如何存储数据。此处的核心是如何产生hash值,该值用来对应数组的存储位置。
我们的目的是将”key-value两个对象“成对存放到HashMap的Entry[]数组中。参考以下步骤:
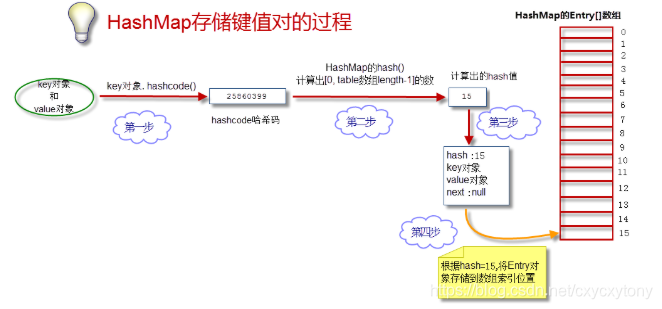
1、获取key对象的hashcod,首先调用key对象的hashcode()方法,获得hashcode。
2、根据hashcode计算出hash值(要求在[0, 数组长度-1]区间),hashcode是一个整数,我们需要将它转化成[0, 数组长度-1]的范围。我们要求转化后的hash值尽量均匀地分布在[0,数组长度-1]这个区间,减少“hash冲突”。(这里涉及到的哈希算法,有兴趣的朋友可以去看数据结构,本文不再赘述)
3、生成Node对象,如上所述,一个Node对象包含4部分:key对象、value对象、hash值、指向下一个Entry对象的引用。我们现在算出了hash值。下一个Node对象的引用为null。
4、将Node对象放到table数组中,如果本Node对象对应的数组索引位置还没有放Entry对象,则直接将Entry对象存储进数组,如果对应索引位置已经有Node对象,则将已有Node对象的next指向本Entry对象,形成链表。
总结上述过程: 当添加一个元素(key-value)时,首先计算key的hasn值,以此确定插入数组中的位置,但是可能存在同一hash值得元素已经被放在数组同一位置了,这时就添加到同一hash值得元素的前面,他们在数组的同一位置,就形成了链表,通一个链表上的Hash值是相同的,所以说数组存放的是链表。JDK8中,当链表长度大于8时,链表就转换为红黑树,这样又大大提高了查找的效率。
5.1.3、取数据过程get(key)
我们需要通过key对象获得“键值对”对象,进而返回value对象。明白了存储数据过程,取数据就比较简单了,参见以下步骤:
1、获得key的hashcode,通过hash()散列算法得到hash值,进而定位到数组的位置。
2、在链表上挨个比较key对象。调用equals()方法,将key对象和链表上所有节点的key进行比较,知道碰到返回true的节点对象为止。
3、返回equals()为true的节点对象的value对象。
明白了存取数据的过程,我们再来看一下 hashcode()和equals 方法的关系:
Java中规定,两个内容相同(equals()为true)的对象必须具有相等的hashCode。因为如果equals()为true而两个对象的hashcode不同;那在整个存储过程中就发生了悖论。
5.1.4、扩容问题
HashMap的位桶数组,初始大小为16。实际使用时,显然大小是可变的。如果位桶数组中的元素达到(0.75*数组 length), 就重新调整数组大小变为原来2倍大小
5.1.5、补充HashTable
HashTable类和HashMap用法几乎一样,底层实现几乎一样,只不过HashTable的方法添加了synchronized挂念子确保线程同步检查,效率较低。
HashMap和HashTable的区别:
- HashMap线程不安全,效率高。允许key或value为null。
- HashTable线程安全,效率低。不允许key或value为null。
- 继承的父类不同,HashMap继承自AbstractMap类。HashTable继承字Dictionary,Dictionary类是一个已经废弃的类。
5.2、TreeMap
TreeMap是红黑二叉树的典型实现。
TreeMap和HashMap实现了同样的接口Map,因此,用法对于调用者来说没有区别。HashMap效率高于TreeMap,在需要排序的Map时才选用TreeMap。
6、Set接口
Set接口继承自Collection,Set接口中没有新增方法,方法和Collection保持完全一致。我们在前面通过List学习的方法,在Set中仍然适用。
Set容器特点:无序、不可重复。
无序指Set中的元素没有索引,我们只能遍历查找;
不可重复指不允许加入重复的元素。更确切地讲,新元素如果和Set中某个元素通过equals()犯法对比为true,则不能加入;甚至,Set中也只能放入一个null元素,不能多个。
Set常用地实现类有:HashSet、TreeSet等,我们一般使用HashSet。
6.1、HashSet底层实现
HashSet是采哈希算法实现,底层实际是用HashMap实现地(HashSet本质就是一个简化版地HashMap),因此,查询效率和增删效率都比较高。我们来看一下HashSet的源码:
我们发现里面有个map属性,这就是HashSet的核心秘密。我们再看add()方法
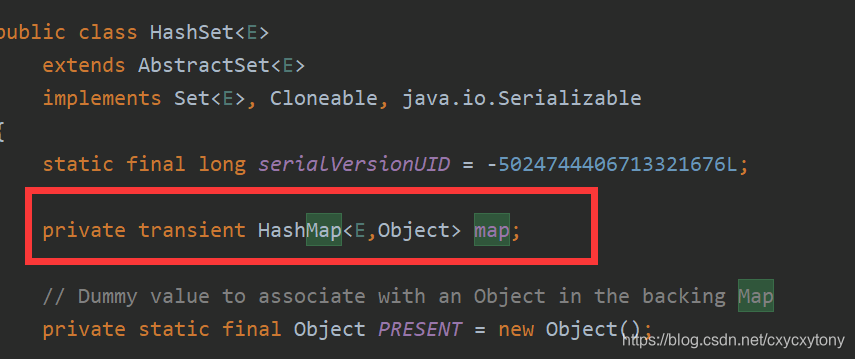
发现增加一个元素说白了就是在map中增加一个键值对,键对象就是这个元素,值对象是名为PRESENT的Object对象。

说白了,就是”往set中加入元素,本质就是把这个元素作为key加入到了内部的map中 “。
由于map中key都是不可重复的,因此,Set天然具有”不可重复“的特性。
6.2、TreeSet的使用和底层实现
TreeSet底层实际使用TreeMap实现的,内部维持了一个简化版的TreeMap,通过key来存储Set的元素。TreeSet内部需要对存储的元素进行排序,因此,我们对应的类需要实现Comparable接口。这样,才能根据compareTo()方法比较对象之间的大小,才能进行内部排序。
public class Test {
public static void main(String[] args) {
User u1 = new User(1001, "张三", 18);
User u2 = new User(2001, "李四", 5);
Set<User> set = new TreeSet<User>();
set.add(u1);
set.add(u2);
}
}
class User implements Comparable<User> {
int id;
String uname;
int age;
public User(int id, String uname, int age) {
this.id = id;
this.uname = uname;
this.age = age;
}
/**
* 返回0 表示 this == obj 返回正数表示 this > obj 返回负数表示 this < obj
*/
@Override
public int compareTo(User o) {
if (this.id > o.id) {
return 1;
} else if (this.id < o.id) {
return -1;
} else {
return 0;
}
}
}
注意:
1、由于是二叉树,需要对元素做内部排序。如果放入TreeSet中的类没有实现Comparable接口,则会抛出异常:java.lang.ClassCastException.
2、TreeSet中不能放入null元素。
7、使用Iterator迭代器遍历容器元素
7.1、迭代器遍历List
public void listOne(){
List<String> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
list.add("a"+i);
}
System.out.println(list);
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
String temp = iterator.next();
System.out.print(temp+"\t");
// 删除3结尾的字符串
if (temp.endsWith("3")){
iterator.remove();
}
}
System.out.println();
System.out.println(list);
}
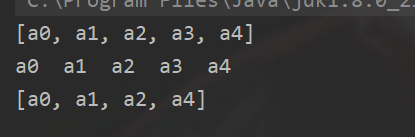
7.2、迭代器遍历Set
public void setOne(){
Set<String> set = new HashSet<>();
for (int i = 0; i < 5; i++) {
set.add("a"+i);
}
System.out.println(set);
for (Iterator<String> iterator = set.iterator();iterator.hasNext();){
String temp = iterator.next();
System.out.print(temp+"\t");
}
System.out.println();
System.out.println(set);
}
7.3、迭代器遍历Map(一)
public void mapOne(){
Map<String, String> map = new HashMap<String, String>();
map.put("A", "TonyOne");
map.put("B", "TonyTwo");
Set<Map.Entry<String, String>> entries = map.entrySet();
Iterator<Map.Entry<String, String>> iterator = entries.iterator();
while (iterator.hasNext()){
Map.Entry<String, String> it = iterator.next();
System.out.println(it.getKey()+"->"+it.getValue());
}
}
7.4、迭代器遍历Map(二)
public void mapTwo(){
Map<String, String> map = new HashMap<String, String>();
map.put("A", "TonyOne");
map.put("B", "TonyTwo");
Set<String> strings = map.keySet();
Iterator<String> iterator = strings.iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println(key+"->"+map.get(key));
}
}
8、遍历集合的方法总结
8.1、遍历List的四种方法
8.1.1、遍历List方法一:普通for循环
for(int i=0;i<list.size();i++){//list为集合的对象名
String temp = (String)list.get(i);
System.out.println(temp);
}
8.1.2、遍历List方法二:增强for循环(使用泛型!)
for (String temp : list) {
System.out.println(temp);
}
8.1.3、遍历List方法三:使用Iterator迭代器(一)
for(Iterator iter= list.iterator();iter.hasNext();){
String temp = (String)iter.next();
System.out.println(temp);
}
8.1.4、遍历List方法四:使用Iterator迭代器(二)
Iterator iter =list.iterator();
while(iter.hasNext()){
Object obj = iter.next();
iter.remove();//如果要遍历时,删除集合中的元素,建议使用这种方式!
System.out.println(obj);
}
8.2、遍历Set的两种方法
8.2.1、遍历Set方法一:增强for循环
for(String temp:set){
System.out.println(temp);
}
8.2.2、遍历Set方法二:使用Iterator迭代器
for(Iterator iter = set.iterator();iter.hasNext();){
String temp = (String)iter.next();
System.out.println(temp);
}
8.3、遍历Map的三种方法
8.3.1、遍历Map方法一:根据key获取value
// 将所有键放入一个Set中
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.println(key+"->"+map.get(key));
}
8.3.2、遍历Map方法二:使用entrySet
Set<Map.Entry<String, String>> entries = map.entrySet();
Iterator<Map.Entry<String, String>> iterator = entries.iterator();
while (iterator.hasNext()){
Map.Entry<String, String> it = iterator.next();
System.out.println(it.getKey()+"->"+it.getValue());
}
8.3.3、遍历Map方法三:使用迭代器
Set<String> strings = map.keySet();
Iterator<String> iterator = strings.iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println(key+"->"+map.get(key));
}
这个方法是将方法一变得复杂了!
9、Collections工具类
类java.util.Collections 提供了对Set、List、Map进行排序、填充、查找元素的辅助方法。
- void sort(List) //对List容器内的元素排序,排序的规则是按照升序进行排序。
- void shuffle(List) //对List容器内的元素进行随机排列。
- oid reverse(List) //对List容器内的元素进行逆续排列 。
- void fill(List, Object) //用一个特定的对象重写整个List容器。
- int binarySearch(List, Object)//对于顺序的List容器,采用折半查找的方法查找特定对象。
学习连接:https://www.sxt.cn/Java_jQuery_in_action/nine-collections.html