我们知道Redis是单线程的,keys命令会使线程阻塞,并且keys是以遍历的方式实现的,时间复杂度是 O(n),Redis库中的key越多,查找时阻塞的时间越长,如果这时候有大量的业务请求送达Redis,有可能导致Redis崩溃,所以线上环境都要禁用keys命令的。
而scan命令是通过增量迭代的方式实现的,每次执行都只返回一个下标位置和少量key,我们通过多次调用scan [下标位置]命令,就可以获取所有的集合键。这就像我们吃自助餐的时候勤拿少取一样,每次取的数据量少,所以单次获取的耗时少(但是总的耗时时间肯定比keys命令久)。
另外SCAN也有它自己的问题:
在对键进行增量式迭代的过程中, 键可能会被修改, 所以增量式迭代命令只能对被返回的元素提供有限的保证
本篇博客主要是介绍在RedisTemplate中使用scan,如果要详细的学习scan命令,可以看下面这篇文章http://doc.redisfans.com/key/scan.html
RedisTemplate对hscan、sscan、zscan都有封装好的方法,比如hscan
@Autowired
private StringRedisTemplate redisTemplate;
@Test
public void testHscan() {
Cursor<Map.Entry<Object, Object>> cursor = redisTemplate.boundHashOps("common-channel")
.scan(ScanOptions.scanOptions().match("*").count(1000).build());
Set<String> set = new HashSet<>();
while (cursor.hasNext()) {
Map.Entry<Object, Object> entry = cursor.next();
set.add((String) entry.getKey());
}
System.out.println(set);
}
但是用RedisTemplate执行scan命令就比较麻烦了,因为RedisTemplate没有默认封装scan命令,我们需要借助execute方法来实现
@Autowired
private StringRedisTemplate redisTemplate;
@Test
public void testScan() {
Set<String> execute = redisTemplate.execute(new RedisCallback<Set<String>>() {
@Override
public Set<String> doInRedis(RedisConnection connection) throws DataAccessException {
Set<String> result = new HashSet<>();
//cursor用完要close,这里利用Java7新特性的自动close它
try (Cursor<byte[]> cursor = connection.scan(ScanOptions.scanOptions().match("*").count(1000).build())){
while (cursor.hasNext()) {
byte[] bytes = cursor.next();
result.add(new String(bytes, StandardCharsets.UTF_8));
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return result;
}
});
System.out.println(execute);
}
网上很多文章说这种实现方式cursor 只会被执行一次,其实这是错误的,使用这种方式cursor 会将所有的符合条件的key都返回回来,他只是将游标的移动给封装了起来而已,真正执行查询的语句起始在cursor.hasNext()里面,源码如下:
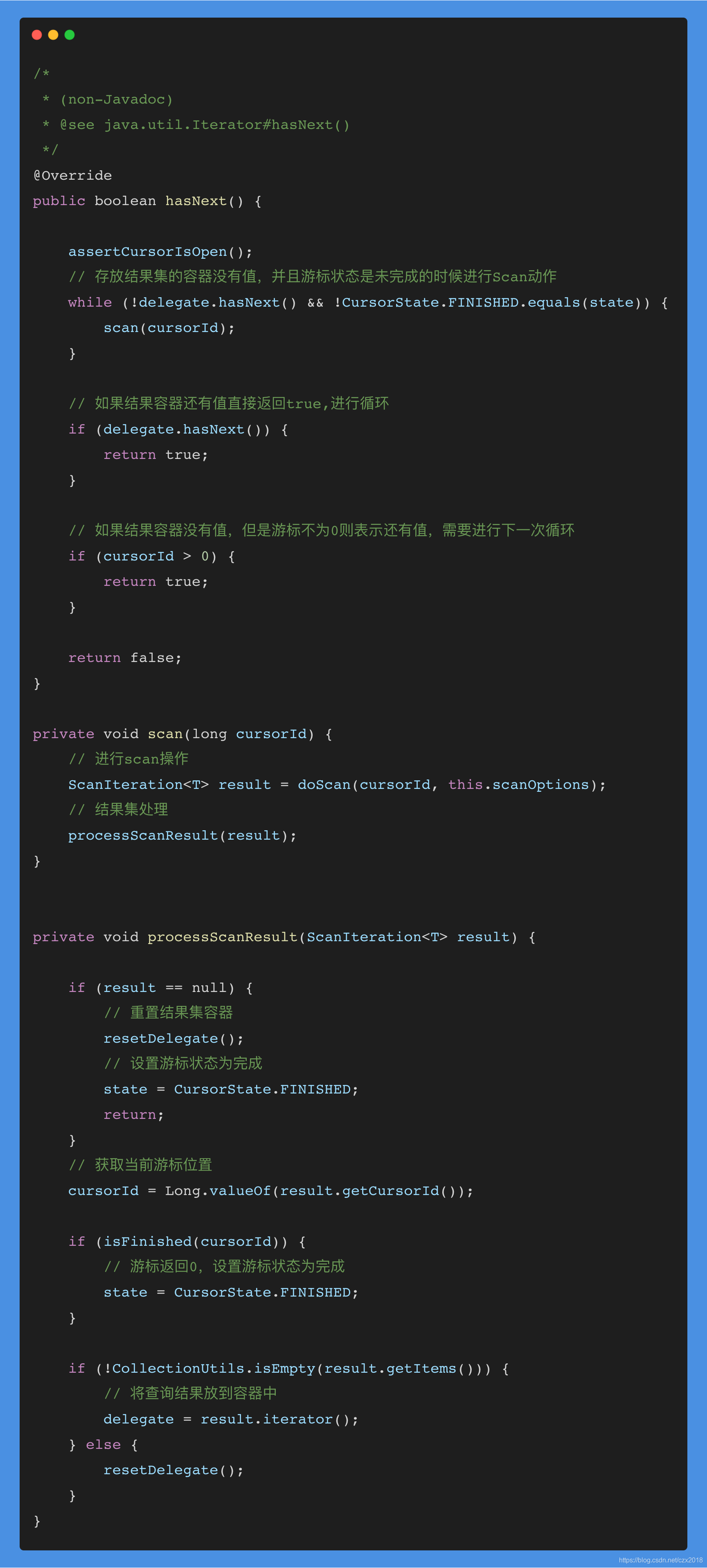
由上面源码我们可以看到游标的移动是在processScanResult()方法中完成。通过state来记录当前游标状态,大致过程为:
1.当存放结果集的容器没有值,并且游标状态是未完成的时候进行Scan动作
2.如果结果容器还有值直接返回true,进行循环
3.如果结果容器没有值,但是游标不为0则表示还有值,需要进行下一次循环