系列文章目录
GLM-4 (1) - 推理+概览
GLM-4 (2) - RoPE
GLM-4 (3) - GLMBlock
GLM-4 (4) - SelfAttention
文章目录
前言
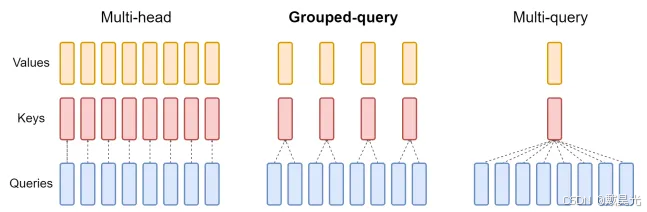
Attention是Transformer架构核心。刚开始使用的一般是multi-head attention,本质上是希望在维度上进行切分,效果类似于CNN中多个通道。如果头的个数是n_head,那么query, key, value都被切分成n_head份,分别做self attention操作,最后将结果拼接。
后面又开发出了multi-query/grouped-query attention,也就是说query还是和之前一样,但是key & value会在多个头之间共享。实验结果表明,multi-query attention大大提升了解码速度;同时考虑到kv_cache缓存,multi-query / grouped-query attention大大减小了存储每个头的键和值所需的内存开销。
MQA(multi-query attention)论文:https://arxiv.org/pdf/1911.02150
GQA(grouped-query attention)论文:https://arxiv.org/pdf/2305.13245
一、概述
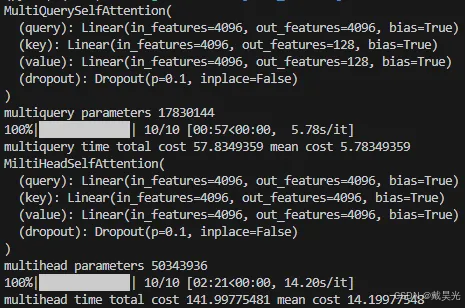
根据上图,我们很容易理解3种注意力的区别。chatGLM2中的Multi Query Attention这篇博客中介绍了multi-head attention和multi-query attention的区别,其实就是简单的将key和value由原来的n_head份变成1份,节省了参数量,并且提升了速度。博客也给出demo代码,测试了两者的速度差异。这边为了本篇记录的完整性,摘录一下代码。
import os
os.environ['CUDA_VISIBLE_DEVICES'] = "1"
import math
import torch.nn as nn
import torch
from tqdm import tqdm
import time
class MiltiHeadSelfAttention(nn.Module):
def __init__(self, num_attention_heads, hidden_size):
super().__init__()
self.num_attention_heads = num_attention_heads
self.attention_head_size = int(hidden_size / num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(hidden_size, self.all_head_size)
self.key = nn.Linear(hidden_size, self.all_head_size)
self.value = nn.Linear(hidden_size, self.all_head_size)
self.dropout = nn.Dropout(0.1)
def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states):
mixed_query_layer = self.query(hidden_states)
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
attention_probs = self.dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
return context_layer
class MultiQuerySelfAttention(nn.Module):
def __init__(self, num_attention_heads, hidden_size):
super().__init__()
self.num_attention_heads = num_attention_heads
self.attention_head_size = int(hidden_size / num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(hidden_size, self.all_head_size)
self.key = nn.Linear(hidden_size, self.attention_head_size)
self.value = nn.Linear(hidden_size, self.attention_head_size)
self.dropout = nn.Dropout(0.1)
def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states):
# hidden_states (B, L, D)
mixed_query_layer = self.query(hidden_states)
# query_layer (B, h, L, d)
query_layer = self.transpose_for_scores(mixed_query_layer)
# 每个key、value head参数都是一样的,只计算一次
key = self.key(hidden_states)
# key_layer (B, 1, L, d)
key_layer = key.unsqueeze(1)
value = self.value(hidden_states)
# value_layer (B, 1, L, d)
value_layer = value.unsqueeze(1)
# key_layer (B, 1, d, L)
key_layer = key_layer.transpose(-1, -2)
# 广播算法 (B, h, L, d) * (B, 1, d, L) => (B, h, L, d) * (B, h, d, L) = (B, h, L, L)
attention_scores = torch.matmul(query_layer, key_layer)
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
attention_probs = self.dropout(attention_probs)
# 广播算法 (B, h, L, L) * (B, 1, L, d) =>(B, h, L, L) * (B, h, L, d)= (B, h, L, d)
context_layer = torch.matmul(attention_probs, value_layer)
# (B, h, L, d) => (B, L, h, d)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
# (B,L, h*d) => (B,L,D)
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
# (B,L, h*d) => (B,L,D)
context_layer = context_layer.view(new_context_layer_shape)
return context_layer
if __name__ == '__main__':
seed = 100
num_attention_heads, hidden_size = 32, 4096
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
device = "cuda:0"
embeddings = torch.randn(5, 128, hidden_size).to(device)
multiquery = MultiQuerySelfAttention(num_attention_heads, hidden_size).to(device)
print(multiquery)
total = 0
for name, param in multiquery.named_parameters():
if len(param.size()) == 2:
total += param.shape[0] * param.shape[1]
else:
total += param.shape[0]
print(f"multiquery parameters {total}")
count = 100
start = time.time()
for _ in tqdm(range(count), ncols=50):
input = embeddings.clone()
for _ in range(100):
for i in range(24):
ouput = multiquery(input)
input = torch.cat([input, ouput[:, -1:, :]], dim=1)
end = time.time()
print(f"multiquery time total cost {round(end - start, 8)} mean cost {round((end - start) / count, 8)}")
multihead = MiltiHeadSelfAttention(num_attention_heads, hidden_size).to(device)
print(multihead)
total = 0
for name, param in multihead.named_parameters():
if len(param.size()) == 2:
total += param.shape[0] * param.shape[1]
else:
total += param.shape[0]
print(f"multihead parameters {total}")
count = 100
start = time.time()
for _ in tqdm(range(count), ncols=50):
input = embeddings.clone()
for _ in range(100):
for i in range(24):
ouput = multihead(input)
input = torch.cat([input, ouput[:, -1:, :]], dim=1)
end = time.time()
print(f"multihead time total cost {round(end - start, 8)} mean cost {round((end - start) / count, 8)}")
不太富裕,单卡3090测试结果表明multi-query attention提速超过两倍。
二、multi-head attention
nanoGPT项目是一个很好的学习大模型的项目,multi-head attention实现的也很优雅,特地提一嘴,代码实现如下:
import math
from typing import Optional
import torch
import torch.nn as nn
from torch import Tensor
import torch.nn.functional as F
from model import GPTConfig
from transformers import GPT2Model
class CausalSelfAttention(nn.Module):
"""
自注意力
"""
def __init__(self, config: GPTConfig):
super().__init__()
assert config.n_embd % config.n_head == 0
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)
# 线性投影层
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
# 正则化dropout
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
# 是否可以使用pytorch内置scaled点积注意力
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention') and self.dropout == 0.0
if not self.flash:
print("WARNING: using slow attention. Flash Attention atm needs PyTorch nightly and dropout=0.0")
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
def forward(self, x: Tensor, valid_length: Optional[Tensor]) -> Tensor: # : torch.Tensor
"""
前向传播
"""
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# 计算query, key, value, shape都是(batch_size, n_head, sequence_length, n_embd / n_head)
q, k, v = self.c_attn(x).split(split_size=self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
# 点积注意力计算
if self.flash:
y = nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout,
is_causal=True)
else:
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1))) # (B, nh, T, T)
# 直接不使用valid_length
att = att.masked_fill(self.bias[:, :, :T, :T] == 0, float("-inf"))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (batch_size, n_head, sequence_length, n_embd / n_head)
y = y.transpose(1, 2).contiguous().view(B, T, C) # (B, T, C)
# 输出投影
y = self.resid_dropout(self.c_proj(y)) # (B, T, C)
return y
这边一直都是多维矩阵的乘法,最后y = y.transpose(1, 2).contiguous().view(B, T, C)实现了如下维度转换,也就是多头结果的拼接:(B, n_head, T, C // n_head) -> (B, T, n_head, C // n_head) -> (B, T, C)。
三、multi-query / grouped-query attention
在GLM-4中,同时用多种方式进行了实现,并且包含了multi-head attention和multi-query attention,但是这边主要探究后者。注:我输入了it is me,此时seq_len=8。
- attention_scores为什么要做缩放的出处是?
CORE_ATTENTION_CLASSES = {
"eager": CoreAttention,
"sdpa": SdpaAttention, # 点积注意力
"flash_attention_2": FlashAttention2
}
class SelfAttention(torch.nn.Module):
"""Parallel self-attention layer abstract class.
Self-attention layer takes input with size [s, b, h]
and returns output of the same size.
"""
def __init__(self, config: ChatGLMConfig, layer_number, device=None):
super(SelfAttention, self).__init__()
# GLMBlock层数,后面用于attention_scores缩放
self.layer_number = max(1, layer_number)
# 投影(输出)层大小,理论上和hidden_size一致
self.projection_size = config.kv_channels * config.num_attention_heads # 4096
# Per attention head and per partition values.
self.hidden_size_per_attention_head = self.projection_size // config.num_attention_heads # 128
self.num_attention_heads_per_partition = config.num_attention_heads # 32
self.multi_query_attention = config.multi_query_attention # True,使用multi_query_attention
# multi-head时的大小
self.qkv_hidden_size = 3 * self.projection_size
# multi-query时的大小
if self.multi_query_attention:
self.num_multi_query_groups_per_partition = config.multi_query_group_num
self.qkv_hidden_size = (
self.projection_size + 2 * self.hidden_size_per_attention_head * config.multi_query_group_num
)
self.query_key_value = nn.Linear(config.hidden_size, self.qkv_hidden_size,
bias=config.add_bias_linear or config.add_qkv_bias,
device=device, **_config_to_kwargs(config)
)
# 选择注意力实现方式
self.core_attention = CORE_ATTENTION_CLASSES[config._attn_implementation](config, self.layer_number)
# 线性输出层
self.dense = nn.Linear(self.projection_size, config.hidden_size, bias=config.add_bias_linear,
device=device, **_config_to_kwargs(config)
)
def _allocate_memory(self, inference_max_sequence_len, batch_size, device=None, dtype=None):
if self.multi_query_attention:
num_attention_heads = self.num_multi_query_groups_per_partition
else:
num_attention_heads = self.num_attention_heads_per_partition
return torch.empty(
inference_max_sequence_len,
batch_size,
num_attention_heads,
self.hidden_size_per_attention_head,
dtype=dtype,
device=device,
)
def forward(
self, hidden_states, attention_mask, rotary_pos_emb, kv_cache=None, use_cache=True
):
# hidden_states: [b, sq, h]
# =================================================
# Pre-allocate memory for key-values for inference.
# =================================================
# =====================
# Query, Key, and Value
# =====================
# Attention heads [b, sq, h] --> [b, sq, (np * 3 * hn)]
# 上述注释是针对multi-head的,multi-query的key和value维度与query不同,
# 比如为[1, 8, 4096] --> [1, 8, 4608], 4608 = 4096 (q) + 2 * (2 * 128) (kv)
mixed_x_layer = self.query_key_value(hidden_states)
# split获取qkv
if self.multi_query_attention:
(query_layer, key_layer, value_layer) = mixed_x_layer.split(
[
self.num_attention_heads_per_partition * self.hidden_size_per_attention_head, # q: 32 * 128
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head, # k: 2 * 128
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head, # v: 2 * 128
],
dim=-1,
)
query_layer = query_layer.view(
query_layer.size()[:-1] + (self.num_attention_heads_per_partition, self.hidden_size_per_attention_head)
) # [batch_size, seq_len, num_head, hidden_size_per] -> [1, 8, 32, 128]
key_layer = key_layer.view(
key_layer.size()[:-1] + (self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head)
) # [1, 8, 2, 128]
value_layer = value_layer.view(
value_layer.size()[:-1]
+ (self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head)
) # [1, 8, 2, 128]
else:
new_tensor_shape = mixed_x_layer.size()[:-1] + \
(self.num_attention_heads_per_partition,
3 * self.hidden_size_per_attention_head)
mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
# [b, sq, np, 3 * hn] --> 3 [b, sq, np, hn]
(query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
# [b, sq, np, hn] -> [b, np, sq, hn] # 将head/query_group放到dim=1的位置
query_layer, key_layer, value_layer = [k.transpose(1, 2) for k in [query_layer, key_layer, value_layer]]
# apply relative positional encoding (rotary embedding)
if rotary_pos_emb is not None:
# (1, 32, 8, 128) (1, 32, 8, 128), (1, 8, 32, 2)
query_layer = apply_rotary_pos_emb(query_layer, rotary_pos_emb)
# (1, 2, 8, 128) (1, 2, 8, 128), (1, 8, 32, 2)
key_layer = apply_rotary_pos_emb(key_layer, rotary_pos_emb)
# adjust key and value for inference
if kv_cache is not None: # 第一轮过后,kv_cache: tuple(2 * torch.Size(1, 2, 8, 128))
cache_k, cache_v = kv_cache
key_layer = torch.cat((cache_k, key_layer), dim=2) # (1, 2, 8+1, 128)
value_layer = torch.cat((cache_v, value_layer), dim=2)
if use_cache:
if kv_cache is None: # 第一轮的时候kv_cache=None
# key_layer.unsqueeze(0).unsqueeze(0): [1, 1, batch_size, np, seq_len, hn]
# kv_cache: [1, 2 (k & v), batch_size, np, seq_len, hn] 即 (1, 2, 1, 2, 8, 128)
kv_cache = torch.cat((key_layer.unsqueeze(0).unsqueeze(0), value_layer.unsqueeze(0).unsqueeze(0)),
dim=1)
else:
kv_cache = (key_layer, value_layer)
else:
kv_cache = None
if self.multi_query_attention:
key_layer = key_layer.unsqueeze(2) # (1, 2, 8, 128) -> (1, 2, 1, 8, 128)
key_layer = key_layer.expand(
-1, -1, self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition, -1, -1
) # (1, 2, 32 // 2, 8, 128)
key_layer = key_layer.contiguous().view(
key_layer.size()[:1] + (self.num_attention_heads_per_partition,) + key_layer.size()[3:]
) # (1, 32, 8, 128)
value_layer = value_layer.unsqueeze(2)
value_layer = value_layer.expand(
-1, -1, self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition, -1, -1
)
value_layer = value_layer.contiguous().view(
value_layer.size()[:1] + (self.num_attention_heads_per_partition,) + value_layer.size()[3:]
)
# ==================================
# core attention computation
# ==================================
# query_layer, key_layer, value_layer shape相同,都是(1, 32, 8, 128)
context_layer = self.core_attention(query_layer, key_layer, value_layer, attention_mask) # (1, 8, 4096)
# 线性输层:[b, sq, h],即(1, 8, 4096)
output = self.dense(context_layer)
# [batch_size, seq_len, hidden_dim], [1, 2 (k & v), batch_size, num_group, seq_len, hn(每个头对应的维度)]
return output, kv_cache # (1, 8, 4096), (1, 2, 1, 2, 8, 128)
1.SdpaAttention
上面说到了,代码中包含了attention的多种实现方式,具体而言如下:
CORE_ATTENTION_CLASSES = {
"eager": CoreAttention, # 原始实现
"sdpa": SdpaAttention, # 点积attention,对应实现方式是torch.nn.functional.scaled_dot_product_attention
"flash_attention_2": FlashAttention2 # 使用flash_attention_2
}
由于SdpaAttention是代码中默认的实现方式(配置文件中有写),所以这边先说一下它。此时在trans_cli_demo.py中不需要做任何多余的动作,一切交给配置文件:
# trans_cli_demo.py
tokenizer = AutoTokenizer.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
encode_special_tokens=True
)
model = AutoModel.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
# attn_implementation="flash_attention_2", # Use Flash Attention
# torch_dtype=torch.bfloat16, #using flash-attn must use bfloat16 or float16
device_map="auto").eval()
代码中SdpaAttention集成自CoreAttention,但实际它两的区别仅在于:SdpaAttention使用的是torch的模块直接求解注意力,而CoreAttention则是手搓了attention的forward部分。代码部分我已经给出了详细注释。总的来说:
- 遵从attention计算公式:
只是需要合理的变换tensor的shape,并使用矩阵相乘来完成该计算; - 注意这边是单向注意力。
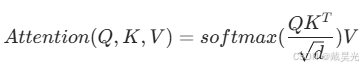
# SdpaAttention
class SdpaAttention(CoreAttention):
def forward(self, query_layer, key_layer, value_layer, attention_mask): # query(/key/value)_layer: (batch_size, num_head, seq_len, dim_per_head), 需要注意的是,此前key/value_layer: (batch_size, num_query_group, seq_len, dim_per_head)
if attention_mask is None and query_layer.shape[2] == key_layer.shape[2]: # shape: (1, 32, 8, 128)
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
is_causal=True,
dropout_p=self.config.attention_dropout if self.training else 0.0)
else:
if attention_mask is not None:
attention_mask = ~attention_mask
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
attention_mask,
dropout_p=self.config.attention_dropout if self.training else 0.0)
context_layer = context_layer.transpose(1, 2).contiguous() # shape: (1, 8, 32, 128)
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
context_layer = context_layer.reshape(*new_context_layer_shape) # (1, 8, 4096)
return context_layer
# CoreAttention
class CoreAttention(torch.nn.Module):
def __init__(self, config: ChatGLMConfig, layer_number):
super(CoreAttention, self).__init__()
self.config = config
self.apply_query_key_layer_scaling = config.apply_query_key_layer_scaling # True
self.attention_softmax_in_fp32 = config.attention_softmax_in_fp32 # True
if self.apply_query_key_layer_scaling:
self.attention_softmax_in_fp32 = True
self.layer_number = max(1, layer_number) # GLMBlock或者是attention的层数(1~40)
self.is_causal = True
projection_size = config.kv_channels * config.num_attention_heads # 投影层尺寸:4096 = 128 * 32
# Per attention head and per partition values.
self.hidden_size_per_partition = projection_size # 4096
self.hidden_size_per_attention_head = projection_size // config.num_attention_heads # 根据头的个数均分:128 = 4096 // 32
self.num_attention_heads_per_partition = config.num_attention_heads # 32
coeff = None
self.norm_factor = math.sqrt(self.hidden_size_per_attention_head) # 注意力公式种的根号d
if self.apply_query_key_layer_scaling: # 不同的层,会有不同的缩放系数(很熟悉,但是需要找找出处)
coeff = self.layer_number
self.norm_factor *= coeff # TODO: WHY
self.coeff = coeff
self.attention_dropout = torch.nn.Dropout(config.attention_dropout)
def forward(self, query_layer, key_layer, value_layer, attention_mask):
# [b, np, sq, sk] 即(batch_size, num_head, seq_len, seq) (1, 32, 8, 8)。这边query_layer和key_layer形状是相同的
output_size = (query_layer.size(0), query_layer.size(1), query_layer.size(2), key_layer.size(2))
# [b, np, sq, hn] -> [b * np, sq, hn] (1, 32, 8, 128) -> (32, 8, 128)
query_layer = query_layer.view(output_size[0] * output_size[1], output_size[2], -1)
# [b, np, sk, hn] -> [b * np, sk, hn] (1, 32, 8, 128) -> (32, 8, 128)
key_layer = key_layer.view(output_size[0] * output_size[1], output_size[3], -1)
# preallocting input tensor: [b * np, sq, sk] query_layer和key_layer矩阵相乘 -> (1*32, 8, 8)
matmul_input_buffer = torch.empty(
output_size[0] * output_size[1], output_size[2], output_size[3], dtype=query_layer.dtype,
device=query_layer.device
)
# Raw attention scores. [b * np, sq, sk]
matmul_result = torch.baddbmm(
matmul_input_buffer, # 这个量不需要管,因为与之相乘的beta=0.0
query_layer, # [b * np, sq, hn]
key_layer.transpose(1, 2), # [b * np, hn, sk]
beta=0.0,
alpha=(1.0 / self.norm_factor), # 这边矩阵batch相乘有个缩放系数
)
# change view to [b, np, sq, sk]
attention_scores = matmul_result.view(*output_size)
# ===========================
# Attention probs and dropout
# ===========================
# attention scores and attention mask [b, np, sq, sk]
if self.attention_softmax_in_fp32:
attention_scores = attention_scores.float() # (1, 32, 8, 8)
if self.coeff is not None:
attention_scores = attention_scores * self.coeff
if attention_mask is None and attention_scores.shape[2] == attention_scores.shape[3]:
attention_mask = torch.ones(output_size[0], 1, output_size[2], output_size[3],
device=attention_scores.device, dtype=torch.bool) # (batch_size, 1, seq_len, seq_len)
attention_mask.tril_() # 下三角都为True,其余是False
attention_mask = ~attention_mask # 取反,下三角都是False
if attention_mask is not None:
attention_scores = attention_scores.masked_fill(attention_mask, float("-inf")) # 下三角保持,其余部分注意力分数都为-inf。也就是单向的
attention_probs = F.softmax(attention_scores, dim=-1) # (1, 32, 8, 8)
attention_probs = attention_probs.type_as(value_layer)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.attention_dropout(attention_probs)
# query layer shape: [b * np, sq, hn]
# value layer shape: [b, np, sk, hn]
# attention shape: [b, np, sq, sk]
# context layer shape: [b, np, sq, hn]
output_size = (value_layer.size(0), value_layer.size(1), query_layer.size(1), value_layer.size(3)) # (batch_size, num_head, seq_len, dim_per_head) (1, 32, 8, 128)
# change view [b * np, sk, hn]
value_layer = value_layer.view(output_size[0] * output_size[1], value_layer.size(2), -1) # (1 * 32, 8, 128)
# change view [b * np, sq, sk]
attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1) # (1 * 32, 8, 8)
# matmul: [b * np, sq, hn]
context_layer = torch.bmm(attention_probs, value_layer) # (1 * 32, 8, 128)
# change view [b, np, sq, hn]
context_layer = context_layer.view(*output_size) # (1, 32, 8, 128)
# [b, np, sq, hn] --> [b, sq, np, hn]
context_layer = context_layer.transpose(1, 2).contiguous() # 序列维度前置,(1, 8, 32, 128)
# [b, sq, np, hn] --> [b, sq, hp]
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,) # 多头合并,(1, 8, 4096)
context_layer = context_layer.reshape(*new_context_layer_shape)
return context_layer
2.CoreAttention
这边说一下CoreAttention。如果要使用它,除了在原始配置文件中修改成"attn_implementation": "eager",同时在创建模型时做如下修改(此博客中也提到了):
tokenizer = AutoTokenizer.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
encode_special_tokens=True
)
model = AutoModel.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
attn_implementation="eager",
# attn_implementation="flash_attention_2", # Use Flash Attention
# torch_dtype=torch.bfloat16, #using flash-attn must use bfloat16 or float16
device_map="auto").eval()
model.config._attn_implementation_internal = "eager" # 这边一定要注明,否则还是sdpa
具体的代码和注释已经在上面展示过了,它是自己实现forward,学习它更有助于我们理解attention机制。
3.FlashAttention2
暂时忽略
总结
- multi-query / grouped-query attention是比multi-head attention参数两更少的注意力,解码速度大大增加;
- 由于kv_cache缓存,multi-query / grouped-query attention大大减小了存储每个头的键和值所需的内存开销。