Mybatis @Flush注解分析
在看源码的的时候,发现了@Flush注解。之前没用过,于是就有了这篇文章
注意:这里的执行器的类型肯定是BatchExecutor
先来例子
@Test
public void testShouldSelectClassUsingMapperClass(){
try(
//指定这次查询的执行器器的类型为BATCH。对应的类型为BatchExecutor
SqlSession session = sqlMapper.openSession(ExecutorType.BATCH)
){
ClassMapper mapper = session.getMapper(ClassMapper.class);
long start = System.currentTimeMillis();
// 这个查询就是正常的查询方法
List<ClassDo> classDos = mapper.listClassOwnerStudentByClassId(1, new String[]{"狗蛋"});
System.out.println(classDos);
System.out.println("开始更新");
// 下面是两个更新操作
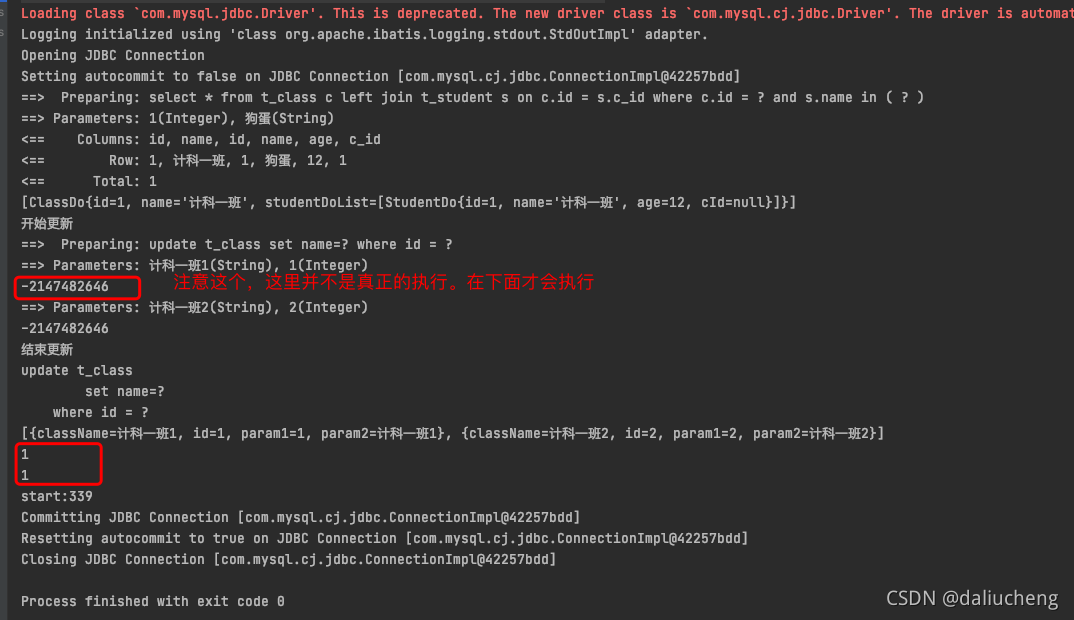
System.out.println(mapper.updateClassNameById(1, "计科一班1"));
System.out.println(mapper.updateClassNameById(2, "计科一班2"));
System.out.println("结束更新");
// 调用flush方法,这个flush方法是我自己写的。返回值为List<BatchResult> ,并且这个flush方法没有对应的Xml。
// 在调用这个方法的时候,才会去真正的更新数据库
for (BatchResult flush : mapper.flush()) {
//更新的sql
System.out.println(flush.getSql());
//更新的参数
System.out.println(flush.getParameterObjects());
//更新影响的行数,这里包括上面的getParameterObjects,这返回值都是一个数组
// 这个批量是以statement为维度的。所以,上面的两个查询都属于一个statement,只是参数不一样
// 所以,getParameterObjects就是一个数组,并且getUpdateCounts也必须是一个数组。
System.out.println(flush.getUpdateCounts());
}
}
public interface ClassMapper {
// 这个没有,必须没有
@Flush
List<BatchResult> flush();
//下面两个都有XMl文件
List<ClassDo> listClassOwnerStudentByClassId(Integer orderId,@Param("array") String[] names);
int updateClassNameById(@Param("id") Integer id,@Param("className") String className);
}
在看结果
1. 注解的作用
先看源码上的注解
/**
* The maker annotation that invoke a flush statements via Mapper interface.
*
* <pre>
* public interface UserMapper {
* @Flush
* List<BatchResult> flush();
* }
* </pre>
*/
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Flush {
}
这个注解就是一个标记接口,通过Mapper的接口来调用刷新statements
2. 注解是怎么发挥作用的?
在方法调用的时候,会调用到MapperProxy的invoke方法,在这里面会构建PlainMethodInvoker,在PlainMethodInvoker里面会包装MapperMethod。在MapperMethod里面构建SqlCommand和MethodSignature,第一个解析@Flush操作就在构建SqlCommand对象。在这里面会如果当前的方法,被@Flush修饰,并且没有对应的Mapper,就将此次查询变为SqlCommandType.FLUSH
- 第一步,解析@Flush注解。
public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) {
// 方法的名字
final String methodName = method.getName();
// method所在的类
final Class<?> declaringClass = method.getDeclaringClass();
// 通过全限定类型名和方法名字从Configuration里面获取MappedStatement。
MappedStatement ms = resolveMappedStatement(mapperInterface, methodName, declaringClass,
configuration);
// 如果ms是null。使用Flush的前提是不要写MapperStatement。
if (ms == null) {
if (method.getAnnotation(Flush.class) != null) {
//此次查询的类型就是FLUSH。
name = null;
type = SqlCommandType.FLUSH;
} else {
throw new BindingException("Invalid bound statement (not found): "
+ mapperInterface.getName() + "." + methodName);
}
} else {
name = ms.getId();
type = ms.getSqlCommandType();
if (type == SqlCommandType.UNKNOWN) {
throw new BindingException("Unknown execution method for: " + name);
}
}
}
- 使用
@Flush注解。
在MapperMethod的execute方法里面会通过Type来确定此次操作的类型,上面已经确定了他的类型是FLUSH。
public Object execute(SqlSession sqlSession, Object[] args) {
Object result; //美其名曰,策略模式
// 类型为FLUSH
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
// 重点就是`flushStatements`方法
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
继续看sqlSession.flushStatements()
跟着上面的代码一直点下去,这里会有多态的情况产生。一种是到BatchExecutor的doFlushStatements方法里面,一种是SimpleExecutor的doFlushStatements的方法。这里最重要的是要走第一种情况。但是下面我会继续两种情况都分析一下。
-
BatchExecutor
statementList是BatchExecutor的属性,在这个方法里面会将之前添加到statementList里面的Statement真正执行,然后将更新的行数封装为batchResult的一个属性。 这就是批量更新。有几个问题?
statementList为什么是一个List
因为一个更新操作里面可能有多个Statement,所有,这里是一个List,
batchResult为什么也是一个List,并且parameterObjects也是一个List,因为多个Statement对应多个Result,parameterObjects是因为,一个Statement可能会调用多次,并且参数值不一样。
那么
statementList和batchResult值是在哪里添加的?@Override public List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException { try { List<BatchResult> results = new ArrayList<>(); if (isRollback) { return Collections.emptyList(); } //遍历statement for (int i = 0, n = statementList.size(); i < n; i++) { //设置查询的参数 Statement stmt = statementList.get(i); applyTransactionTimeout(stmt); BatchResult batchResult = batchResultList.get(i); try { // 这里会调用statement的executeBatch来把之前的准备好的sql批量执行。 // 那么,问题来了,statement是在哪里添加的?batchResult是在哪里添加的? batchResult.setUpdateCounts(stmt.executeBatch()); MappedStatement ms = batchResult.getMappedStatement(); //得到更新的操作 List<Object> parameterObjects = batchResult.getParameterObjects(); // 如果使用了KeyGenerator。 KeyGenerator keyGenerator = ms.getKeyGenerator(); if (Jdbc3KeyGenerator.class.equals(keyGenerator.getClass())) { Jdbc3KeyGenerator jdbc3KeyGenerator = (Jdbc3KeyGenerator) keyGenerator; jdbc3KeyGenerator.processBatch(ms, stmt, parameterObjects); } else if (!NoKeyGenerator.class.equals(keyGenerator.getClass())) { //issue #141 for (Object parameter : parameterObjects) { keyGenerator.processAfter(this, ms, stmt, parameter); } } //关闭Statement closeStatement(stmt); } catch (BatchUpdateException e) { StringBuilder message = new StringBuilder(); message.append(batchResult.getMappedStatement().getId()) .append(" (batch index #") .append(i + 1) .append(")") .append(" failed."); if (i > 0) { message.append(" ") .append(i) .append(" prior sub executor(s) completed successfully, but will be rolled back."); } throw new BatchExecutorException(message.toString(), e, results, batchResult); } // 将结果添加在result里面返回。 results.add(batchResult); } return results; } finally { for (Statement stmt : statementList) { closeStatement(stmt); } currentSql = null; statementList.clear(); batchResultList.clear(); } } -
SimpleExecutor
// 空操作。返回一个空的列表,这没啥可看的。 @Override public List<BatchResult> doFlushStatements(boolean isRollback) { return Collections.emptyList(); }
3. 啥时候给statementList和batchResultList添加值
最简单的方式就是点一下,找到他所有引用的地址,并且找add方法,因为他是一个List嘛
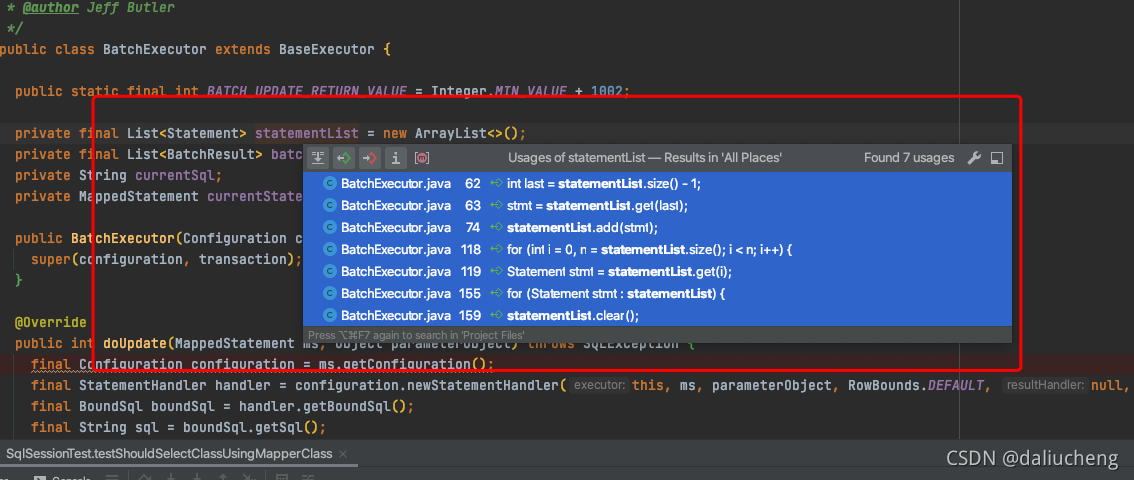
看来只有一个地方调用了add方法
在更新操作的时候才会把构建好的Statement添加到statementList里面,同时还会构建BatchResult,并把他添加在里面。最后调用的是PreparedStatement#addBatch()方法。并且返回了一个固定值。
可以看到BatchResult的几个参数,分别是MapperStatement,sql,parameterObject参数
问题?
-
下面代码中的currentSql是干嘛的?
这就是一个更新的Mapper多次调用只会生成一个Statement和一个BatchResult的
在第一次走到这个方法的时候,currentSql为null,在添加到第一个Statement之后,会赋值currentSql和currentStatement为当前组装好的,如果这个方法第二次调用的时候,就会走到if里面,并且会将这次查询的参数添加到之前的BatchResult的parameterObject属性里面去
// BatchExecutor的doUpdate方法
// 这里的逻辑和之前查询基本一致。都是获取Connection,处理参数,但是这里并没有执行,而是调用了PreparedStatement#addBatch();
@Override
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException {
final Configuration configuration = ms.getConfiguration();
final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, null, null);
final BoundSql boundSql = handler.getBoundSql();
final String sql = boundSql.getSql();
final Statement stmt;
if (sql.equals(currentSql) && ms.equals(currentStatement)) {
int last = statementList.size() - 1;
stmt = statementList.get(last);
applyTransactionTimeout(stmt);
handler.parameterize(stmt);// fix Issues 322
BatchResult batchResult = batchResultList.get(last);
batchResult.addParameterObject(parameterObject);
} else {
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt); // fix Issues 322
currentSql = sql;
currentStatement = ms;
statementList.add(stmt);
batchResultList.add(new BatchResult(ms, sql, parameterObject));
}
handler.batch(stmt);
//可以看到,返回的都是一个固定值 为 Integer.MIN_VALUE + 1002;
return BATCH_UPDATE_RETURN_VALUE;
}
补充说明
在Mybatis中删除和插入和更新都会进对调用到doUpdate方法,上面是以Update举例子。也就是说,除了查询之外,剩下的三种操作都执行批量处理。
总结
Mybatis @Flush是为批量操作做准备的。必须要将执行器的类型设置为BatchExecutor,(可以通过全局设置和获取Session的时候局部设置),并且@Flush标注的方法不能有对应的xml文件。返回值为List,如下所示
@Flush
List<BatchResult> flush();
那么在方法调用的时候,就可以通过调用Mapper的被@Flush修饰的方法来更新。