go语言中结构体嵌套结构体
这是我的Go lang实验的第三篇。 如果您想阅读以前的文章,请访问:
结构是很酷的类型。 它允许创建用户定义的类型。
基本结构
可以这样声明结构
type person struct {
firstName string
lastName string
}这将声明具有2个字段的struct。
结构变量可以这样声明:
var p1 person
var结构会将p1初始化为零值,因此两个字符串字段均设置为“”。
DOT(。)构造用于访问字段。
如何定义结构变量。
可以通过几种方式创建变量。
var p1 person // Zero value
var p2 = person{} //Zero value
p3 := person{firstName: "James", lastName: "Bond"} //Proper initialization
p4 := person{firstName: "James"} //Partial initialization
p5 := new(person) // Using new operator , this returns pointer
p5.firstName = "James"
p5.lastName = "Bond"结构比较
可以使用“ ==”运算符比较相同类型的结构
p1 := person{firstName: "James", lastName: "Bond"}
p2 := person{firstName: "James", lastName: "Bond"}
if p1 == p2 {
fmt.Println("Same person found!!!!", p1)
} else {
fmt.Println("They are different", p1, p2)
}这显示了纯值的力量,不需要相等或哈希码类型的事物进行比较。 该语言具有一流的支持,可以按值进行比较。
结构转换
Go lang没有强制转换。 它支持转换,不仅适用于结构,还适用于任何类型。
强制转换保留源对象引用并将目标对象的struct / layout放在其顶部,因此在强制转换之后,对源对象所做的任何更改对目标对象都是可见的。
这对于减少内存开销很有好处,但是对于安全性而言,这可能会引起很大的问题,因为值可以从源对象神奇地更改。
在另一端,转换复制源值,因此转换后,源和目标都没有链接。 更改一个不会影响另一个。 这有利于类型安全,并且易于推理代码。
让我们看一下struct的一些转换示例。
type person struct {
firstName string
lastName string
}
type anotherperson struct {
firstName string
lastName string
}
以上两者的结构相同,但是如果没有转换,则无法将这两者分配给彼此。
p1 := person{firstName: "James", lastName: "Bond"}
anotherp1 := anotherperson{firstName: "James", lastName: "Bond"}
p1 = anotherp1 //This is compile time error
p1 = person(anotherp1)//This is allowed编译器非常聪明地指出这两种类型是兼容的并且允许转换。
现在,如果去更改其他人的结构,例如删除字段/新字段/更改顺序,则它变得不兼容,编译器将停止此操作!
当它允许转换时,它将为目标变量分配新的内存并复制该值。
例如
p1 = person(anotherp1)
anotherp1.lastName = "Lee" // Will have not effect on p1结构如何分配
由于它是复合类型,因此了解struct的内存布局对于了解它将产生哪种类型的开销非常有用。
当前的处理器会做一些很酷的事情,以实现快速,安全的读/写。
内存分配将与基础平台的字长(32位或64位)对齐,并且还将根据类型的大小对齐,例如4字节值将与4字节地址对齐。
对齐对于速度和正确性非常重要。
让我们举个例子来理解这一点,在64位平台中,字长为64bit或8字节,因此读取1个字将花费1条指令。
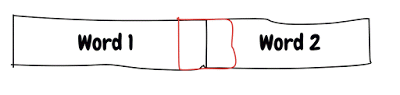
红色显示的值为2个字节,如果红色显示的值分配在2个字中(即,在字的边界处),则将需要执行多次操作来读取/写入值,并且对于写入可能需要某种同步。
由于值只有2个字节,因此可以很容易地将其放入单个字中,因此编译器将尝试将其分配为单个字:
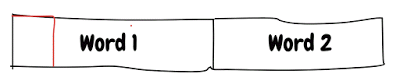
以上分配已针对读/写进行了优化。 结构分配的工作原理相同。
现在,以一个结构示例为例,看看它的内存布局是什么:
type layouttest struct {
b byte
v int32
f float64
v2 int32
}
“ layoutouttest”的布局如下所示:
[1 XX 1 1 1 1 1 X] [1 1 1 1 XXXX] [1 1 1 1 1 1 1 1 1] [1 1 1 1 XXXX]
X –用于填充。
花了4个字来放置此结构,并通过数据类型填充添加了对齐方式。
如果我们计算struct的大小(1 + 4 + 4 + 8 = 17),则它应该适合3个字的值(8 * 3 = 24),但要花4个字(8 * 4 = 32)。 看起来好像浪费了8个字节。
Go使开发人员可以完全控制内存布局。 可以创建更多紧凑的结构来分配3个单词。
type compactlyouttest struct {
f float64
v int32
v2 int32
b byte
}上面的struct按其占用的大小按降序对字段进行了重新排序,这有助于进入下面的内存布局
[1 1 1 1 1 1 1 1 1] [1 1 1 1 1 1 1 1 1] [1 XXXXXXX]
在这种安排中,在填充中浪费的空间更少,您可能会想使用紧凑的表示形式。
您不应该出于几个原因这样做
–这会破坏可读性,因为相关字段会在整个位置移动。
–内存可能不是问题,因此可能只是优化。
–处理器非常聪明,在高速缓存行中读取值而不是字,因此CPU将读取多个字,并且您永远不会看到读取速度变慢的情况。 您可以在cpu-cache-access-pattern文章中了解有关缓存行如何工作的信息。
–过度优化可能会导致错误共享问题,请阅读无错误共享的并发计数器,以了解多线程代码中错误共享的影响。
因此,在进行任何优化之前,先对应用程序进行配置。
Go内置了用于获取内存对齐详细信息和其他类型的静态信息的包。
下面的代码提供了有关内存布局的许多详细信息
var x layouttest
var y compactyouttest
fmt.Printf("Int alignment %v \n", unsafe.Alignof(10))
fmt.Printf("Int8 aligment %v \n", unsafe.Alignof(int8(10)))
fmt.Printf("Int16 aligment %v \n", unsafe.Alignof(int16(10)))
fmt.Printf("Layoutest aligment %v ans size is %v \n", unsafe.Alignof(x), unsafe.Sizeof(x))
fmt.Printf("Compactlayouttest aligment %v and size is %v \n", unsafe.Alignof(y), unsafe.Sizeof(y))
fmt.Printf("Type %v has %v fields and takes %v bytes \n", reflect.TypeOf(x).Name(), reflect.TypeOf(x).NumField(), reflect.TypeOf(x).Size())不安全&反射包提供了许多内部细节,看起来这个想法来自Java。
该博客中使用的代码可从001-struct github获得。
翻译自: https://www.javacodegeeks.com/2019/01/go-lang-struct-works.html
go语言中结构体嵌套结构体