1、image 图片
import gradio as gr
import numpy as np
def imgdeal(input_img):
#处理图像
sepia_filter = np.array([
[0.393, 0.769, 0.189],
[0.349, 0.686, 0.168],
[0.272, 0.534, 0.131]
])
sepia_img = input_img.dot(sepia_filter.T)
sepia_img /= sepia_img.max()
return sepia_img
def imagetest():
#shape设置输入图像大小
demo = gr.Interface(imgdeal, gr.Image(shape=(200, 200)), "image")
demo.launch()
if __name__ == '__main__':
imagetest()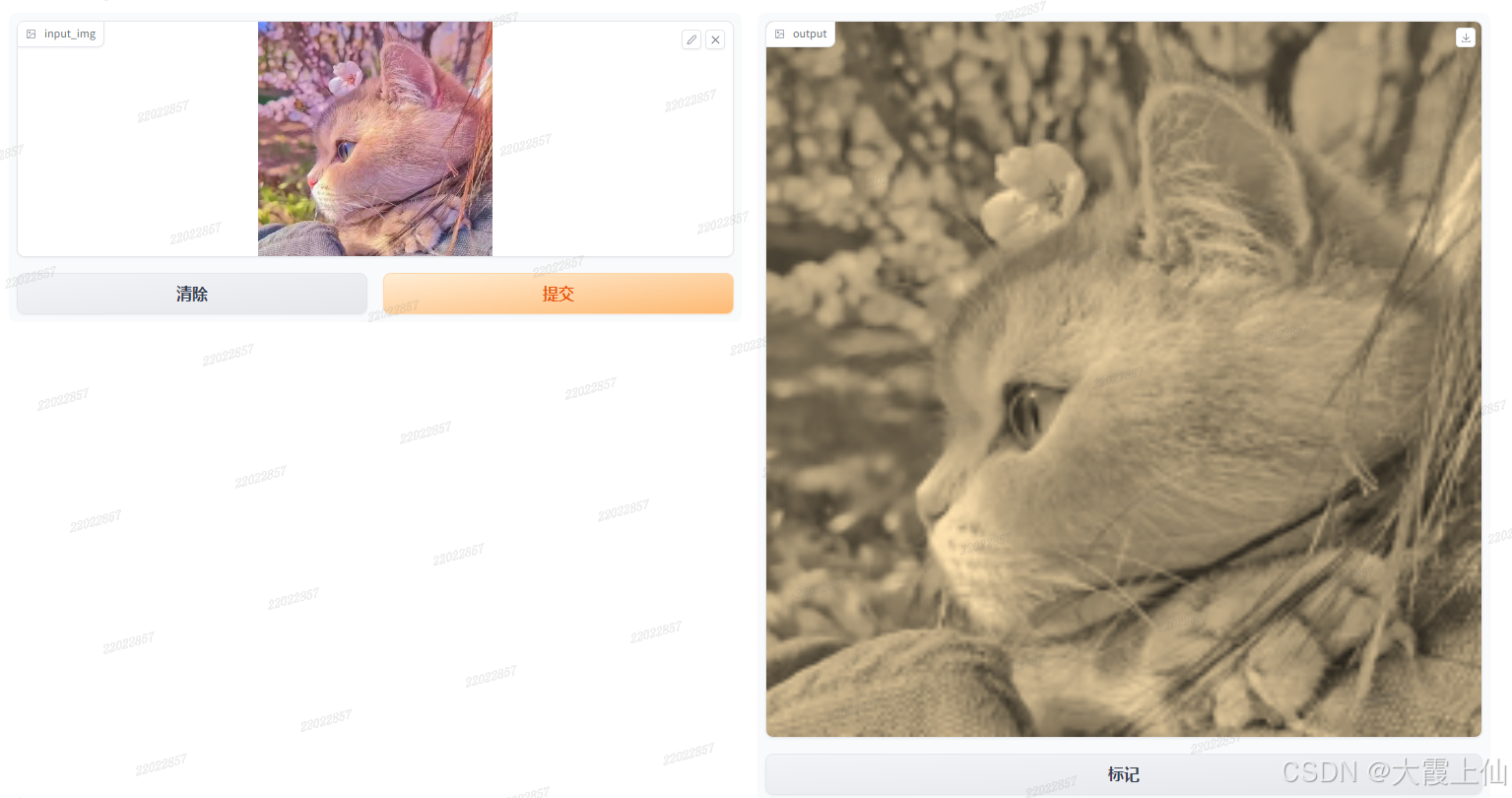
2、audio 音频
import gradio as gr
import librosa
def audio_duration_interface(audio):
duration = librosa.get_duration(filename=audio)
return f"The duration of the audio is: {duration} seconds."
def audiotest():
gr.Interface(fn=audio_duration_interface, inputs=gr.Audio(type="filepath"), outputs=gr.Text()).launch()
if __name__ == '__main__':
audiotest()
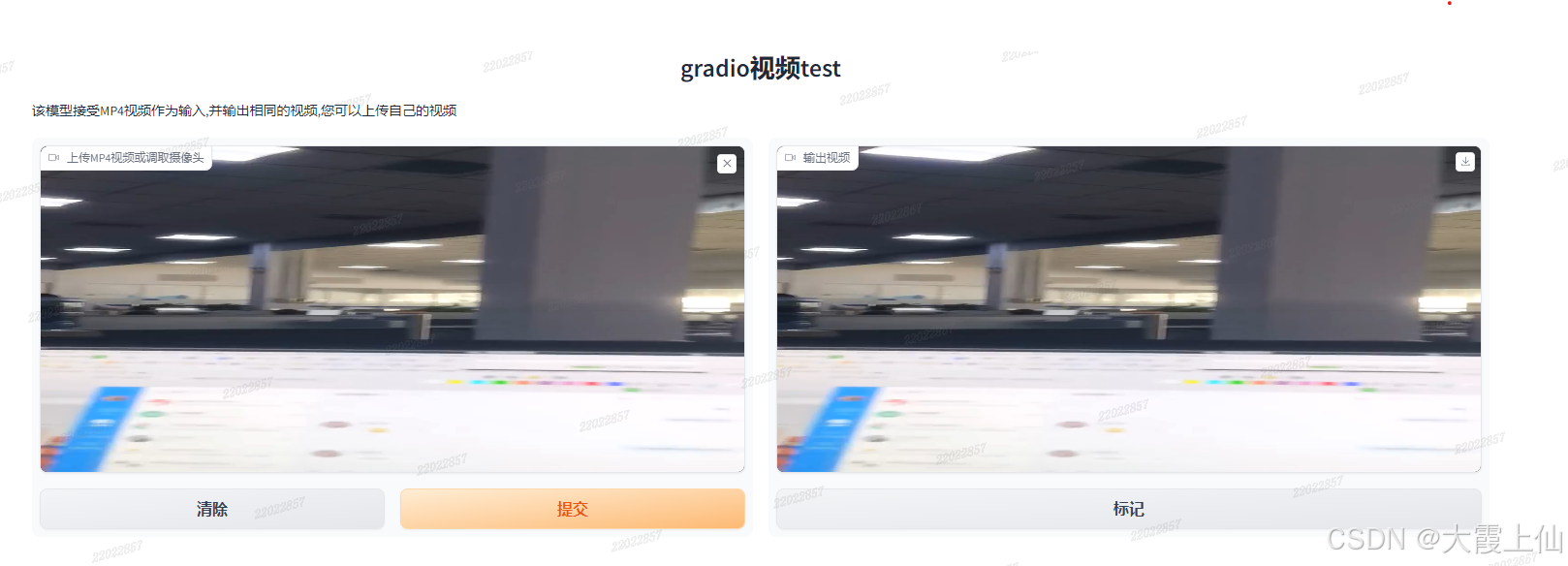
3、vedio 视频
def mymodel(input_video):
print(type(input_video),input_video)
return input_video
# 返回读取的视频
def vediotest():
# 定义输入和输出界面,使用Video输入和Video输出
input_interface = gr.Video(label="上传MP4视频或调取摄像头")
# output_interface = [gr.Image(label="输出图像",show_download_button=True) ,gr.Video(label="输出视频",show_download_button=True)]
output_interface = gr.Video(label="输出视频",format='mp4')
# 设置标题和解释说明
title = "视频姿态检测模型"
description = "该模型接受MP4视频作为输入,并输出相同的视频。您可以上传自己的视频,或者使用摄像头录制。"
# 启动Gradio界面
demo=gr.Interface(mymodel, inputs=input_interface, outputs=output_interface , title=title, description=description)
demo.launch()
if __name__ == '__main__':
vediotest()