于是载入完整版视频
conda activate video_features
cd video_features
python main.py \
feature_type=r21d \
device="cuda:0" \
video_paths="[/home/ubuntu/low/0.mp4,/home/ubuntu/low/1.mp4,/home/ubuntu/low/2.mp4,/home/ubuntu/low/3.mp4,/home/ubuntu/low/4.mp4,/home/ubuntu/low/5.mp4,/home/ubuntu/low/6.mp4,/home/ubuntu/low/7.mp4,/home/ubuntu/low/8.mp4,/home/ubuntu/low/9.mp4,/home/ubuntu/low/10.mp4,/home/ubuntu/low/12.mp4,/home/ubuntu/low/13.mp4,/home/ubuntu/low/14.mp4,/home/ubuntu/low/15.mp4,/home/ubuntu/low/16.mp4,/home/ubuntu/low/17.mp4,/home/ubuntu/low/18.mp4,/home/ubuntu/low/19.mp4,/home/ubuntu/low/20.mp4,/home/ubuntu/low/21.mp4,/home/ubuntu/low/22.mp4,/home/ubuntu/low/23.mp4,/home/ubuntu/low/24.mp4,/home/ubuntu/low/25.mp4,/home/ubuntu/low/26.mp4,/home/ubuntu/low/27.mp4,/home/ubuntu/low/28.mp4,/home/ubuntu/low/29.mp4,/home/ubuntu/low/30.mp4,/home/ubuntu/low/31.mp4,/home/ubuntu/low/32.mp4,/home/ubuntu/low/33.mp4,/home/ubuntu/low/34.mp4,/home/ubuntu/low/35.mp4,/home/ubuntu/low/36.mp4,/home/ubuntu/low/37.mp4,/home/ubuntu/low/38.mp4,/home/ubuntu/low/39.mp4,/home/ubuntu/low/40.mp4,/home/ubuntu/low/41.mp4,/home/ubuntu/low/42.mp4,/home/ubuntu/low/43.mp4,/home/ubuntu/low/44.mp4,/home/ubuntu/low/45.mp4,/home/ubuntu/low/46.mp4,/home/ubuntu/low/47.mp4,/home/ubuntu/low/48.mp4,/home/ubuntu/low/49.mp4,/home/ubuntu/low/50.mp4,/home/ubuntu/low/51.mp4,/home/ubuntu/low/52.mp4,/home/ubuntu/low/53.mp4,/home/ubuntu/low/54.mp4,/home/ubuntu/low/55.mp4,/home/ubuntu/low/56.mp4,/home/ubuntu/low/57.mp4,/home/ubuntu/low/58.mp4,/home/ubuntu/low/59.mp4,/home/ubuntu/low/60.mp4,/home/ubuntu/low/61.mp4,/home/ubuntu/low/62.mp4,/home/ubuntu/low/63.mp4,/home/ubuntu/low/64.mp4,/home/ubuntu/low/65.mp4,/home/ubuntu/low/66.mp4,/home/ubuntu/low/67.mp4,/home/ubuntu/low/68.mp4,/home/ubuntu/low/69.mp4]"并且把支持的feature_type尝试个遍,clip、i3d、r21d、raft、resnet、s3d、timm和vggish共八个
率先试一下r21d,对69个视频处理过后会生成什么,修改configs中的r21d.yml文件
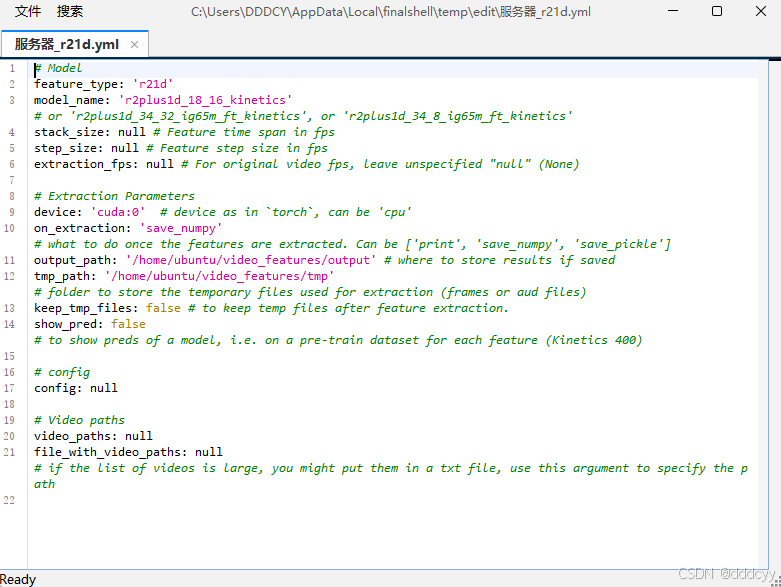
把output_path指代清楚,并且把on_extraction这里换成我prefer的numpy形式
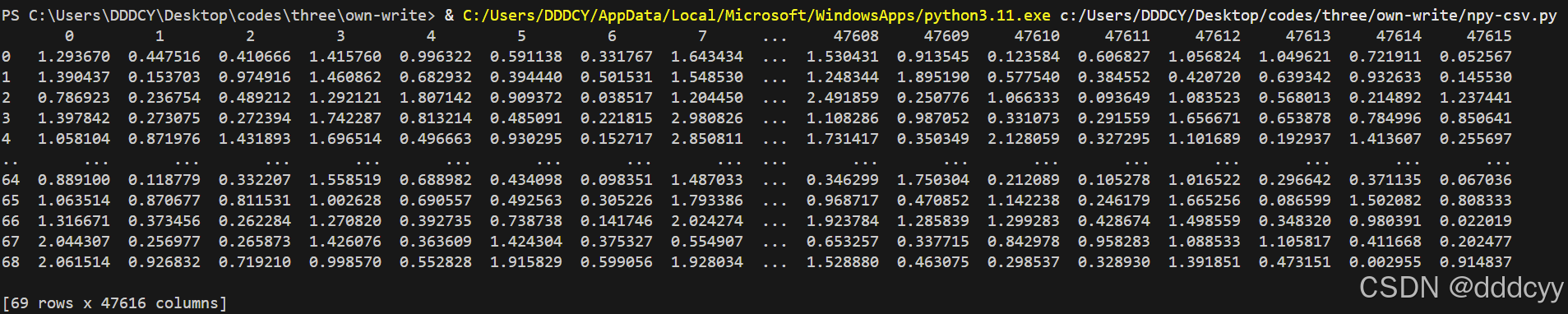
运行完之后,把output_path当中的文件夹下载到window,写一个代码把生成的69个.npy文件整合到一个csv文件中,供我跑机器学习。npy——>csv代码如下
import numpy as np
import pandas as pd
import os,re
from itertools import chain
numpy_os = "C:/Users/DDDCY/Desktop/fsdownload/r2plus1d_18_16_kinetics"
csv_os = "C:/Users/DDDCY/Desktop/result/features"
def natural_sort_key(s):
"""
按文件名的结构排序,即依次比较文件名的非数字和数字部分
"""
sub_strings = re.split(r'(\d+)', s)
sub_strings = [int(c) if c.isdigit() else c for c in sub_strings]
return sub_strings
filenames = os.listdir(numpy_os)
filename = sorted(filenames, key=natural_sort_key)
df = pd.DataFrame()
for file in filename:
input = np.load(numpy_os+'/'+file)
x = list(chain.from_iterable(input))
dx = pd.DataFrame(x)
dy = dx.transpose()
df = pd.concat([df,dy])
df = df.reset_index(drop=True)
df.to_csv(csv_os+'/r21d.csv',sep=',',index="None")每个视频其实输出的特征是一个93 rows x512 columns 的向量,但是考虑到如果再增加一个维度,变成三维张量,机器学习算法不好处理。所以我把每个视频的二维向量转化为一维。结果就如下了。
既然拿到了特征,我就赶忙去跑一下机器学习。还是先跑个回归吧