dijstra(堆优化版)精讲:
思路
之前的dijstra算法是从节点出发的,使用的是邻接矩阵存储图,时间复杂度为O(n^2),但是对于稀疏图来说,使用邻接矩阵存储会浪费很大的存储空间,而且消耗的时间也很长。
因而对于稀疏图,用邻接表存储会更好,并且dijstra算法也可以从边的角度出发,从而降低时间复杂度。而带权值的有向图用邻接表存储的话,邻接表中需要存(节点,权值),最好定义一个Edge结构体,用变量名明确第一个是节点,第二个是权值。
还是dijstra算法三部曲
- 找到非标记的距离源点最近的节点
- 标记该节点
- 更新非标记节点距离源点的距离(即更新miniDist数组)
那么从边的角度出发的话,第一步可以不用遍历,直接找到非标记的最近节点,然后标记该节点,最后更新非标记节点距离源点的距离可以直接用该节点对应的邻接表。
那么我们可以使用堆来优化dijstra算法。 - 首先使用邻接表来存储有向图
- 接着使用小顶堆来保存节点距离源点的距离和对应节点(因为要找的是最近的节点)
- 下面是堆不空时循环:
- 出堆堆顶元素,判断其是否是未标记过的节点(因为每次向堆中压入元素时,原来的元素不一定出堆,比如原来堆中存储(14,节点5),后面又压入了(12,节点5),那么虽然后面出堆了节点5,另一个节点5还在,因此需要判断)
- 标记该节点
- 遍历该节点连接的节点,更新未标记节点距离源点的距离
代码
# from collections import defaultdict
import heapq # 堆的库
class Edge():
def __init__(self, to, val):
self.to = to # 指向的节点
self.val = val # 边的权值
def print_miniDist(miniDist, n):
for i in range(1, n + 1):
print("i: " + str(i) + "miniDist[i]: " + str(miniDist[i]))
def dijstra(graph, n, start, end):
miniDist = [float('inf')] * (n + 1) # 节点编号从1开始
visited = [False] * (n + 1)
miniDist[start] = 0 # 源点到源点的距离为0
pq = [] # 优先级队列,作为堆,小顶堆
heapq.heappush(pq, (0, start)) # 堆中存储的元素为[距离源点距离, 节点]
while pq:
curval, curnode = heapq.heappop(pq) # 弹出堆顶元素
# print("curnode: " + str(curnode) + "curval: " + str(curval))
if visited[curnode]: # 该节点访问过的话,就跳过
continue
# 该节点没有被访问过
visited[curnode] = True # 标记
# print("pass")
# 更新非标记过节点离源点距离
for edge in graph[curnode]:
if not visited[edge.to] and curval + edge.val < miniDist[edge.to]:
miniDist[edge.to] = curval + edge.val
heapq.heappush(pq, (miniDist[edge.to], edge.to))
#print_miniDist(miniDist, n)
#print_miniDist(miniDist, n)
if miniDist[end] == float('inf'): # 从start到不了end
print(-1)
else:
print(miniDist[end])
def main():
n, m = map(int, input().split())
graph = [[] for _ in range(n + 1)]
for _ in range(m):
s, e, v = map(int, input().split())
graph[s].append(Edge(e, v))
dijstra(graph, n, 1, n)
if __name__ == '__main__':
main()
Bellman_ford 算法精讲:
思路
本题是带权有向图,且会有权值为负值的情况,且图中不存在负权回路。
存在负权值,不能用dijstra算法(详见上一次朴素版dijstra算法,或者这么理解,dijstra算法用到了贪心,出现负权值,局部最优推不出全局最优)
本题要用到的是Bellman_ford算法,主要的操作是松弛:
以下图为例:miniDist仍然为源点到节点的最短路径长度,节点2的miniDist要么是miniDist[1] + val,要么是节点2自己的miniDist(来自于其它节点推出的),而miniDist[2] = min(miniDist[2], miniDist[1] + val)
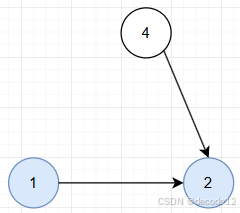
上面这个操作定义为松弛边(1, 2)
对图中所有边松弛1次得到的miniDist相当于从源点经过一条路径到达的节点的最短路径,也就是下面这种
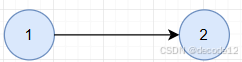
那么对图中所有边松弛2次得到的miniDist是相当于源点经过两条路径到达的节点的最短路径长度,如下图
那么需要对所有边松弛几次才能得到起点(节点1)到终点(节点n)的最短距离呢,节点数量为n,起点到终点,最多是n - 1条边相连。
因此无论图是什么样的,边是什么顺序,对所有边松弛n - 1次就一定能得到起点到终点的最短距离,同时也计算得到了起点到达所有节点的最短距离,因为所有节点与起点连接的边数最多为n - 1条边
代码

def bellman_ford(edges, n, start, end):
miniDist = [float("inf")] * (n + 1) # 节点编号从1开始
miniDist[start] = 0 # 源点到源点距离为0
for _ in range(1, n): # 对所有边松弛 n - 1次
updated = False
for edge in edges:
p1, p2, val = edge[0], edge[1], edge[2] # 边的出发、结尾和权值
# 松弛
# miniDist[p1] != float("inf")防止从未计算过的节点出发
if miniDist[p1] != float("inf") and miniDist[p1] + val < miniDist[p2]:
miniDist[p2] = miniDist[p1] + val
updated = True
if not updated: # 如果不再更新了,就直接break
break
if miniDist[end] == float("inf"):
print("unconnected") # 这里题目要求是输出unconnected
else:
print(miniDist[end])
def main():
n, m = map(int, input().split())
edges = [] # 保存边
for _ in range(m):
s, t, v = map(int, input().split())
edges.append([s, t, v])
bellman_ford(edges, n, 1, n)
if __name__ == '__main__':
main()
python的话,如果不加updated,那么代码会超时
学习收获:
dijstra(堆优化版):针对稀疏图,从边的角度出发进行dijstra算法,使用邻接表存储,同时用小顶堆保存(距离,节点),还是用到了miniDist数组。
Bellman_ford算法:针对存在负权值的带权有向图,主要操作是松弛,实际上就是对所有边松弛n - 1次得到最短距离