Floyd算法精讲:
思路
首先分析题目,本题给出的是一个带权无向图,而要求的是,多个,从start到end的最短路径长度,即多源最短路径。
用到Floyd算法,Floyd实际上用到了动态规划。比如说1→5的最短路径长度可以由1→3的最短路径和3→5的最短路径组成,其中的3 也可以是别的节点,那么就是1→5的最短路径由1→k,k→5的最短路径的最短组成,k∈[1, n]
动规五部曲
- dp数组及含义:
本题的dp数组直接用grid图,dp[i][j][k]:表示从节点 i 到节点 j 的以[1, …, k]集合中的一个节点为中间节点的最短路径 - 递归公式
以是否选择 k 来分类: - i 到 j 的最短路径经过k:dp[i][k][k - 1] + dp[k][j][k - 1]
- i 到 j 的最短路径不经过k:dp[i][j][k - 1]
因为是求最短路径,所以是两种情况求min - 初始化
分为两个部分初始化,1是最开始的无向图,2是grid中除无向图的其它部分。 - 1.无向图:grid[i][j][k]:双向图中 i – j 这条边的权值为w,应该给grid[i][j][0]赋值,给其它k赋值的话相当于已经定义了从i 到 j 经过k(k≠0)的最短路径长度了,但是实际上不一定是的。注意是双向图,grid[i][j][0]和grid[j][i][0]都要赋值
-
- 除无向图外的其它部分,因为是要求最小值,而题目给出权值最大为10000,因此其余部分初始化为10005(大数)
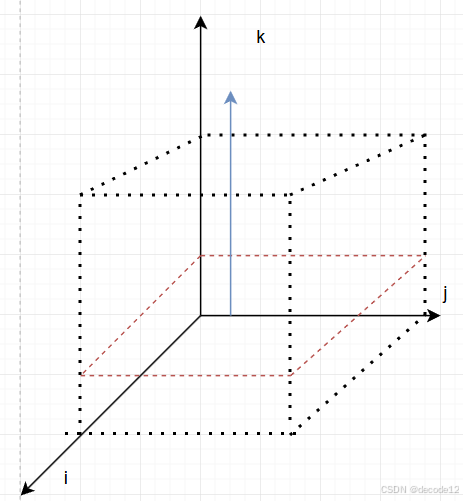
- 遍历方式
由初始化可知,我们最开始初始化了k=0的由 i 和 j 组成的平面,即下图中红色线下的平面。因此应当按照蓝色箭头的方向遍历,先遍历k再遍历 i 和 j ,至于 i 和 j 遍历的顺序都可以
- 举例:
不太好举例,如果要举例的话,应当是k确定输出二维 i j 平面
代码
def main():
n, m = map(int, input().split())
grid = [[[10005] * (n + 1) for _ in range(n + 1)] for _ in range(n + 1)]
# 初始化
for _ in range(m):
u, v, w = map(int, input().split())
grid[u][v][0] = w
grid[v][u][0] = w
# floyd
for k in range(1, n + 1):
for i in range(1, n + 1):
for j in range(1, n + 1):
grid[i][j][k] = min(grid[i][k][k - 1] + grid[k][j][k - 1], grid[i][j][k - 1])
# 输出
q = int(input())
for _ in range(q):
start, end = map(int, input().split())
if grid[start][end][n] == 10005:
print(-1)
else:
print(grid[start][end][n])
if __name__ == '__main__':
main()
空间优化
方法1:
由递推公式可得,grid[i][j][k]只与dp[i][j][k - 1]相关,因此只定义dp[i][j][0]和dp[i][j][1]即可
方法2:
使用二维数组,原来的递推公式为grid[i][j][k] = min(grid[i][k][k - 1] + grid[k][j][k - 1], grid[i][j][k - 1])
转换为二维数组的话,递推式中的grid[i][j][k - 1]换成grid[i][j](赋值前是上一个k对应的值)
而grid[i][k][k - 1] + grid[k][j][k - 1]换成grid[i][k] + grid[k][j]。
- 如果grid[i][k]是这一轮k的,且比上一轮k的要小,说明找到了更短的 i → k的路径,那么基于更小的grid[i][k]去计算grid[i][j]没问题。
- 如果grid[i][k]是这一轮k的,且比上一轮k的要大,不可能这么更新grid[i][k]
- grid[i][k]是上一轮的,那么正好是递推公式中的。
因此没有必要区分 grid[i][k] 和grid[k][j]是属于k - 1层还是k层的。
递归公式
grid[i][j] = min(grid[i][k] + grid[k][j], grid[i][j])
代码
def main():
n, m = map(int, input().split())
grid = [[10005] * (n + 1) for _ in range(n + 1)] # 邻接矩阵
# 初始化
for _ in range(m):
u, v, w = map(int, input().split())
grid[u][v] = w
grid[v][u] = w
# floyd
for k in range(1, n + 1):
for i in range(1, n + 1):
for j in range(1, n + 1):
grid[i][j] = min(grid[i][k] + grid[k][j], grid[i][j])
# 输出
q = int(input())
for _ in range(q):
start, end = map(int, input().split())
if grid[start][end] == 10005:
print(-1)
else:
print(grid[start][end])
if __name__ == '__main__':
main()
floyd算法是从节点出发算最短路径的,因此适合于稠密图
A*算法精讲(A star算法):
思路
首先分析题目:骑士可以走的地方有八个位置,棋盘大小为1000 × 1000(棋盘的x和y坐标在[1, 1000]区间内,包含边界),给出n个测试样例,每行有起始位置和目标位置,输出从起点到目标的最短路径长度。
本题是一个网状格,求最短路径,相当于一个不带权的无向图,最直观的思路就是广搜。但是因为地图很大,且n也可能很大,所以可能会超时
采用Astar,使用启发式函数影响广搜或者dijstra从队列中取元素的优先顺序。
以BFS的A*为例
A*与BFS的区别在于,A *是有方向的去遍历,而BFS只是一圈一圈搜索。而A * 的方向由启发式函数来确定,本题中启发式函数影响的是队列中元素的排序,通过给队列中的每个节点赋一个权值达到,而权值是通过计算起点到当前节点的距离 + 当前节点到目标节点的距离来实现。
其中起点到当前节点的距离可以用起点到当前节点经过的路径长度来得到
当前节点到目标节点的距离有三种计算方式:
- 曼哈顿距离:d = abs(x1 - x2) + abs(y1 - y2)
- 欧式距离:d = sqrt((x1 - x2) ^ 2 + (y1 - y2) ^2)
- 切比雪夫距离:d = max(abs(x1 - x2), abs(y1 - y2))
本题采用欧式距离才能最大程度的体现点与点之间的距离。
本题起点到当前节点的距离有两种方式:
- 起点到当前节点的步数:step[next_node] = step[cur_node] + 1
- 精细一点,不平方的欧式距离:step[next_node] = step[cur_node] + 5 # 11 + 22 = 5,但是还需要额外的变量保存起点到当前节点的步数。
因此采用第一种方式最好。
总结一下,本题采用优先级队列来保存要经过的节点,优先级即权值的计算方式在上面,因为求的是最短距离,因此权值越低的节点越先被选中,也就是小顶堆。
最后一些细节:1.将节点加入队列前要先判断是否越界,以及该节点之前是否遍历过了, 2.因为要记录起始到目标的最短距离,用了字典记录了源点到当前节点的距离,因此可以用字典判断节点是否在之前遍历过了
import heapq
direction = [(1, 2), (2, 1), (-1, 2), (2, -1), (1, -2), (-2, 1), (-1, -2), (-2, -1)]
def distance(a, b):
return ((a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2) ** 0.5
def bfs(start, end):
pq = [(distance(start, end), start)]
step = {start: 0} # 从源点出发走的距离
while pq:
curval, curnode = heapq.heappop(pq)
if curnode == end:
return step[curnode]
for di in direction:
nextnode = (curnode[0] + di[0], curnode[1] + di[1])
if nextnode[0] < 1 or nextnode[0] > 1000 or nextnode[1] < 1 or nextnode[1] > 1000:# 越界
continue
step_next = step[curnode] + 1
if nextnode not in step:
step[nextnode] = step_next
heapq.heappush(pq, (distance(nextnode, end) + step_next, nextnode)) # 优先级为距离
return False
def main():
n = int(input())
for _ in range(n):
a1, a2, b1, b2 = map(int, input().split())
print(bfs((a1, a2), (b1, b2)))
if __name__ == '__main__':
main()
A*的时间复杂度由启发式函数决定,
最坏情况下A *退化成广搜,时间复杂度为O(n^2),n为节点数量
最佳情况,从起点直接到终点,时间复杂度为O(dlogd),d为起点到终点的深度
A * 的时间复杂度介于最优和最坏情况下,可以粗略认为其时间复杂度为O(nlogn),n为节点数量
最短路算法总结篇:
文章链接
四个最短路算法:dijstra、bellma_ford、SPFA和floyd
- 不存在负权值求单源最短 :dijstra
- 单源存在负权值:bellman_ford
- 存在负权回路:bellman_ford
- 多源最短:Floyd
图论总结:
学习收获:
Floyd算法,求多源最短路,出现负权值也可以用。基本思考是基于动态规划:即1→3的最短路径可以由1→k最短,k→3最短来求,其中k可以是任意节点。
A*算法,关键在于启发式函数,本题所用的启发式函数在于,将队列变为优先级队列(代码中用的是堆来实现),权值为源点到当前节点距离 + 当前节点到目标节点距离,权值低的优先采用,且节点入队前要先判断是否已经遍历过,同时需要单独的数据结构记录已经遍历过的节点和对应的步数。