深度强化学习实验室
官网:http://www.neurondance.com/
论坛:http://deeprl.neurondance.com/
作者:小舟、陈萍
文章来源:转载自机器之心(链接文末)
通用人工智能,用强化学习的奖励机制就能实现吗?
几十年来,在人工智能领域,计算机科学家设计并开发了各种复杂的机制和技术,以复现视觉、语言、推理、运动技能等智能能力。尽管这些努力使人工智能系统在有限的环境中能够有效地解决特定的问题,但却尚未开发出与人类和动物一般的智能系统。
人们把具备与人类同等智慧、或超越人类的人工智能称为通用人工智能(AGI)。这种系统被认为可以执行人类能够执行的任何智能任务,它是人工智能领域主要研究目标之一。关于通用人工智能的探索正在不断发展。近日强化学习大佬 David Silver、Richard Sutton 等人在一篇名为《Reward is enough》的论文中提出将智能及其相关能力理解为促进奖励最大化。

论文地址:https://www.sciencedirect.com/science/article/pii/S0004370221000862
该研究认为奖励足以驱动自然和人工智能领域所研究的智能行为,包括知识、学习、感知、社交智能、语言、泛化能力和模仿能力,并且研究者认为借助奖励最大化和试错经验就足以开发出具备智能能力的行为。因此,他们得出结论:强化学习将促进通用人工智能的发展。
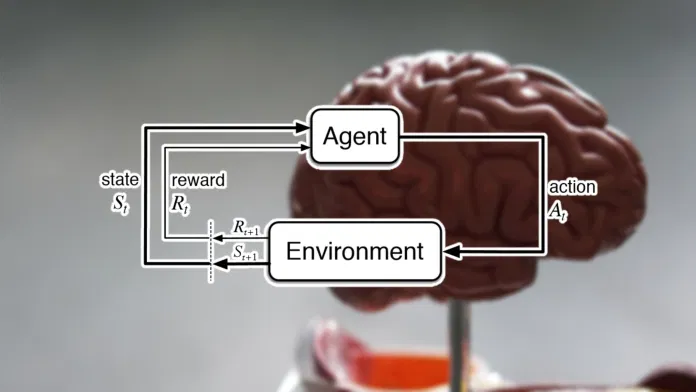
AI 的两条路径
创建 AI 的一种常见方法是尝试在计算机中复制智能行为的元素。例如,我们对哺乳动物视觉系统的理解催生出各种人工智能系统,这些系统可以对图像进行分类、定位照片中的物体、定义物体的边界等。同样,我们对语言的理解也帮助开发了各种自然语言处理系统,比如问答、文本生成和机器翻译。
但这些都是狭义人工智能的实例,只是被设计用来执行特定任务的系统,而不具有解决一般问题的能力。一些研究者认为,组装多个狭义人工智能模块将产生更强大的智能系统,以解决需要多种技能的复杂问题。
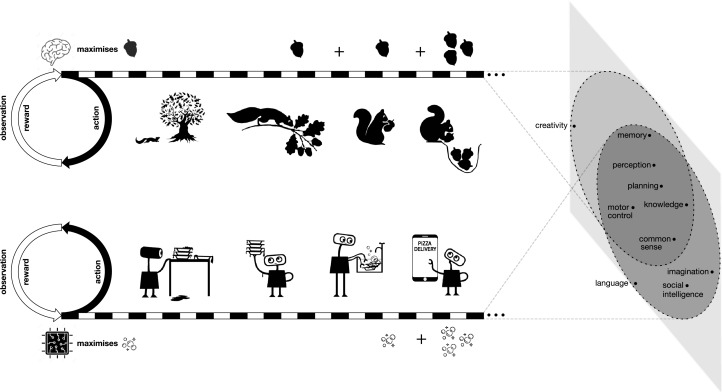
而在该研究中,研究者认为创建通用人工智能的方法是重新创建一种简单但有效的规则。该研究首先提出假设:奖励最大化这一通用目标,足以驱动自然智能和人工智能中至少大部分的智能行为。」
这基本上就是大自然自身的运作方式。数十亿年的自然选择和随机变异让生物不断进化。能够应对环境挑战的生物才能得以生存和繁殖,其余的则被淘汰。这种简单而有效的机制促使生物进化出各种技能和能力来感知、生存、改变环境,以及相互交流。
研究者说:「人工智能体未来所面临的环境和动物与人类面临的自然世界一样,本质上是如此复杂,以至于它们需要具备复杂的能力才能在这些环境中成功生存。」因此,以奖励最大化来衡量的成功,需要智能体表现出相关的智能能力。从这个意义上说,奖励最大化的一般目标包含了许多甚至可能是所有的智能目标。并且,研究者认为最大化奖励最普遍和可扩展的方式是借助与环境交互学习的智能体。
奖励就足够了
与人工智能的许多交互式方法一样,强化学习遵循一种协议,将问题分解为两个随时间顺序交互的系统:做出决策的智能体(解决方案)和受这些决策影响的环境(问题)。这与其他专用协议形成对比,其他专用协议可能考虑多个智能体、多个环境或其他交互模式。
基于强化学习的思想,该研究认为奖励足以表达各种各样的目标。智能的多种形式可以被理解为有利于对应的奖励最大化,而与每种智能形式相关的能力能够在追求奖励的过程中隐式产生。因此该研究假设所有智能及相关能力可以理解为一种假设:「奖励就足够了」。智能及其相关的能力,可以理解为智能体在其环境中的行为奖励最大化。
这一假设很重要,因为如果它是正确的,那么一个奖励最大化智能体在服务于其实现目标的过程中,就可以隐式地产生与智能相关的能力,具备出色智能能力的智能体将能够「适者生存」。研究者从以下几个方面论述了「奖励就足够了」这一假设。
知识和学习
该研究将知识定义为智能体内部信息,例如,知识可以包含于用于选择动作、预测累积奖励或预测未来观测特征的函数参数中。有些知识是先验知识,有些知识是通过学习获得的。奖励最大化的智能体将根据环境情况包含前者,例如借助自然智能体的进化和人工智能体的设计,并通过学习获取后者。随着环境的不断丰富,需求的平衡将越来越倾向于学习知识。
感知
人类需要各种感知能力来积累奖励,例如分辨朋友和敌人,开车时进行场景解析等。这可能需要多种感知模式,包括视觉、听觉、嗅觉、躯体感觉和本体感觉。
相比于监督学习,从奖励最大化的角度考虑感知,最终可能会支持更广泛的感知行为,包括如下具有挑战性和现实形式的感知能力:
动作和观察通常交织在多种感知形式中,例如触觉感知、视觉扫视、物理实验、回声定位等;
感知的效用通常取决于智能体的行为;
获取信息可能具有显式和隐式成本;
数据的分布通常依赖于上下文,在丰富的环境中,潜在数据多样性可能远远超过智能体的容量或已存在数据的数量——这需要从经验中获取感知;
感知的许多应用程序无法获得有标记的数据。
社交智能
社交智能是一种理解其他智能体并与之有效互动的能力。根据该研究的假设,社交智能可以被理解为在智能体环境中的某一智能体最大化累积奖励。按照这种标准智能体 - 环境协议,一个智能体观察其他智能体的行为,并可能通过自身行为影响其他智能体,就像它观察和影响环境的其他方面一样。一个能够预测和影响其他智能体行为的智能体通常可以获得更大的累积奖励。因此,如果一个环境需要社交智能(例如包含动物或人类的环境),奖励最大化将能够产生社交智能。
语言
语言一直是自然和人工智能领域大量研究的一个主题。由于语言在人类文化和互动中起着主导作用,智能本身的定义往往以理解和使用语言的能力为前提,尤其是自然语言。
然而,当前的语言建模本身不足以产生更广泛的与智能相关的语言能力,包括:
语言通常是上下文相关的,不仅与所说的内容相关,还与智能体周围环境中正在发生的其他事情有关,有时需要通过视觉和其他感官模式感知。此外,语言经常穿插其他表达行为,例如手势、面部表情、音调变化等。
语言是有目的并能对环境产生影响的。例如,销售人员学习调整他们的语言以最大化销售额。
语言的具体含义和效用因智能体的情况和行为而异。例如,矿工可能需要有关岩石稳定性的语言,农民可能需要有关土壤肥力的语言。此外,语言可能存在机会成本,例如讨论农业的人并不一定是从事农业工作)。
在丰富的环境中,语言处理不可预见事件的潜在用途可能超出任何语料库的能力。在这些情况下,可能需要通过经验动态地解决语言问题。例如开发一项新技术或找到一种方法来解决一个新的问题。
该研究认为基于「奖励就足够了」的假设,丰富的语言能力,包括所有这些更广泛的能力,都应该源于对奖励的追求。
泛化
泛化能力通常被定义为将一个问题的解决方案转换为另一个问题的解决方案的能力。例如,在监督学习中,泛化可能专注于将从一个数据集(例如照片)学到的解决方案转移到另一个数据集(例如绘画)。
根据该研究的假设,泛化可以通过在智能体和单个复杂环境之间的持续交互流中最大化累积奖励来实现,这同样遵循标准的智能体 - 环境协议。人类世界等环境需要泛化,因为智能体在不同的时间会面对环境的不同方面。例如,一只吃水果的动物可能每天都会遇到一棵新树,这个动物也可能会受伤、遭受干旱或面临入侵物种。在每种情况下,动物都必须通过泛化过去状态的经验来快速适应新状态。动物面临的不同状态并没有被整齐地划分为具有不同标签的任务。相反,状态取决于动物的行为,它可能结合了在不同时间尺度上重复出现的各种元素,可以观察到状态的重要方面。丰富的环境同样需要智能体从过去的状态泛化到未来的状态,以及所有相关的复杂性,以便有效地积累奖励。
模仿
模仿是与人类和动物智能相关的一种重要能力,它可以帮助人类和动物快速获得其他能力,例如语言、知识和运动技能。在人工智能中,模仿通常被表述为通过行为克隆,从演示中学习,并提供有关教师行为、观察和奖励的明确数据时。相比之下,观察学习的自然能力包括从观察到的其他人类或动物的行为中进行的任何形式的学习,并且不要求直接访问教师的行为、观察和奖励。这表明,与通过行为克隆的直接模仿相比,在复杂环境中可能需要更广泛和现实的观察学习能力,包括:
其他智能体可能是智能体的环境的组成部分(例如婴儿观察其母亲),而无需假设存在包含教师数据的特殊数据集;
智能体可能需要学习它自己的状态与另一个智能体的状态之间的关联,或者智能体自己的动作和另一个智能体的观察结果,这可能会产生更高的抽象级别;
其他智能体可能只能被部分观察到,因此他们的行为或目标可能只是被不完美地推断出来;
其他智能体可能会表现出应避免的不良行为;
环境中可能有许多其他智能体,表现出不同的技能或不同的能力水平。
该研究认为这些更广泛的观察学习能力能够由奖励最大化驱动的,从单个智能体的角度来看,它只是将其他智能体视为其环境的组成部分,这可能会带来许多与行为克隆相同的好处。例如样本高效的知识获取,但这需要更广泛和更综合的背景下。
通用智能
基于该研究的假设,通用智能可以理解为通过在单一复杂的环境中最大化一个特殊奖励来实现。例如,自然智能在其整个生命周期中都面向从与自然世界的互动中产生的连续经验流。动物的经验流足够丰富和多样,它可能需要灵活的能力来实现各种各样的子目标(例如觅食、战斗、逃跑等),以便成功地最大化其整体奖励(例如饥饿或繁殖) 。类似地,如果人工智能体的经验流足够丰富,那么单一目标(例如电池寿命或生存)可能隐含地需要实现同样广泛的子目标的能力,因此奖励最大化应该足以产生一种通用人工智能。
强化学习智能体
该研究的主要假设是智能及其相关能力可以被理解为促进奖励最大化,这与智能体的性质无关。因此,如何构建最大化奖励的智能体是一个重要问题。该研究认为这个问题同样可以通过问题本身,即「奖励最大化」来回答。具体来说,研究者设想了一种具有一般能力的智能体,然后从他们与环境交互的持续经验中学习如何最大化奖励。这种智能体,被称之为强化学习智能体。
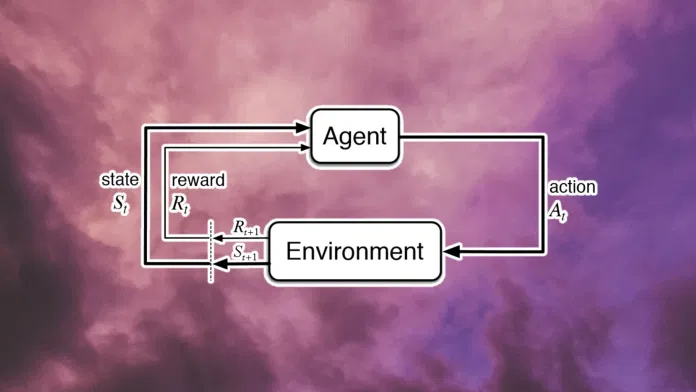
在所有可能的最大化奖励的解决方法中,最自然的方法当然是通过与环境交互,从经验中学习。随着时间的推移,这种互动体验提供了大量关于因果关系、行为后果以及如何积累奖励的信息。与其预先确定智能体的行为(相信设计者对环境的预知),不如赋予智能体发现自己行为的一般能力(相信经验)是很自然的。更具体地说,最大化奖励的设计目标是通过从经验中学习最大化奖励的行为的持续内部过程来实现的。
奖励真的足够了吗?
对于该研究「奖励就足够了」的观点,有网友表示不赞成:「这似乎是对个人效用函数这一共同概念的重新语境化。所有生物都有效用函数,他们的目标是最大化他们的个人效用。效用理论有着深厚而丰富的历史渊源,但本文对效用理论的认识并不多见。Silver 和 Sutton 都是 RL 领域的大牛,但对我而言,这篇论文给我的感觉很糟糕。」
还有网友认为这是重新包装进化论:
如此优秀的两位计算机科学家这是在重新包装进化论?这里的实际意义是什么?如果有足够的时间和复杂性,进化(奖励信号)可以发明智能。这有什么意义?智能需要从奖励中获得就像是在表述「人会呼吸」,这似乎是句废话。
甚至有人质疑「备受尊敬的研究者更容易陷入过度自信」:

还有网友表示:「这篇文章没有对可以做什么和不能做什么设置任何界限。难道无需直接分析函数即可知道在尝试最大化函数时可以或不能出现什么吗?奖励函数与获得这些奖励的系统相结合,完全确定了 “可出现” 行为的空间,而无论出现什么,对它们来说都是智能行为。」

不过,也有人提出了一个合理的问题:

最终目标奖励是否会产生一般的智能,或者是否会产生一些额外的信号?纯奖励信号是否会陷入局部最大值?他们的论点是,对于一个非常复杂的环境,它不会。
但如果你有一个足够复杂的环境,模型有足够的参数,并且你不会陷入局部最大值,那么一旦系统解决了问题中的琐碎,简单的部分,唯一的方法是提高性能,创建更通用的解决方案,即变得更智能。
原文链接:
https://mp.weixin.qq.com/s/XTNyLjZ9KfdtHY4Omb9_4w
完
总结3: 《强化学习导论》代码/习题答案大全
总结6: 万字总结 || 强化学习之路
完
第106篇:奖励机制不合理:内卷,如何解决?
第105篇:FinRL: 一个量化金融自动交易RL库
第104篇:RPG: 通过奖励发现多智能体多样性策略
第103篇:解决MAPPO(Multi-Agent PPO)技巧
第102篇:82篇AAAI2021强化学习论文接收列表
第101篇:OpenAI科学家提出全新强化学习算法
第100篇:Alchemy: 元强化学习(meta-RL)基准环境
第98篇:全面总结(值函数与优势函数)的估计方法
第97篇:MuZero算法过程详细解读
第96篇: 值分布强化学习(Distributional RL)总结
第95篇:如何提高"强化学习算法模型"的泛化能力?
第94篇:多智能体强化学习《星际争霸II》研究
第93篇:MuZero在Atari基准上取得了新SOTA效果
第91篇:详解用TD3算法通关BipedalWalker环境
第88篇:分层强化学习(HRL)全面总结
第85篇:279页总结"基于模型的强化学习方法"
第84篇:阿里强化学习领域研究助理/实习生招聘
第83篇:180篇NIPS2020顶会强化学习论文
第81篇:《综述》多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第77篇:深度强化学习工程师/研究员面试指南
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第15篇:DeepMind开源三大新框架!
第13篇:OpenSpiel(28种DRL环境+24种DRL算法)
第11篇:DRL在Unity自行车环境中配置与实践
第8篇:ReinforceJS库(动态展示DP、TD、DQN)
第5篇:深度强化学习在阿里巴巴的技术演进
第4篇:深度强化学习十大原则
第2篇:深度强化学习的加速方法
第1篇:深入浅出解读"多巴胺(Dopamine)论文"、环境配置和实例分析
