1. 基本概念
1.1 机器学习定义
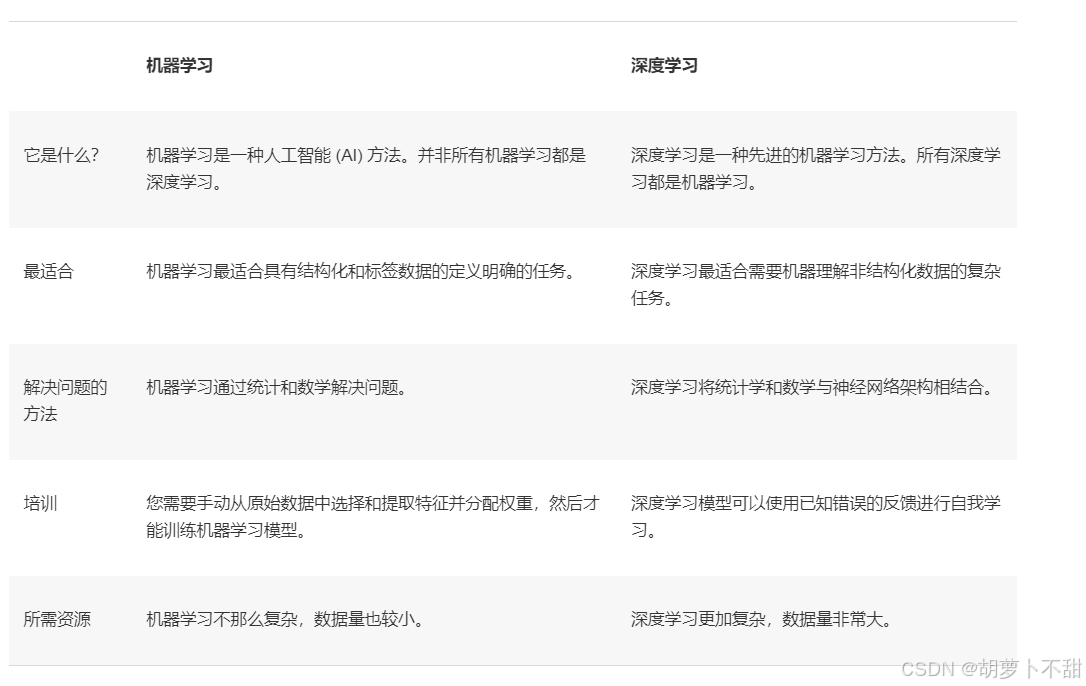
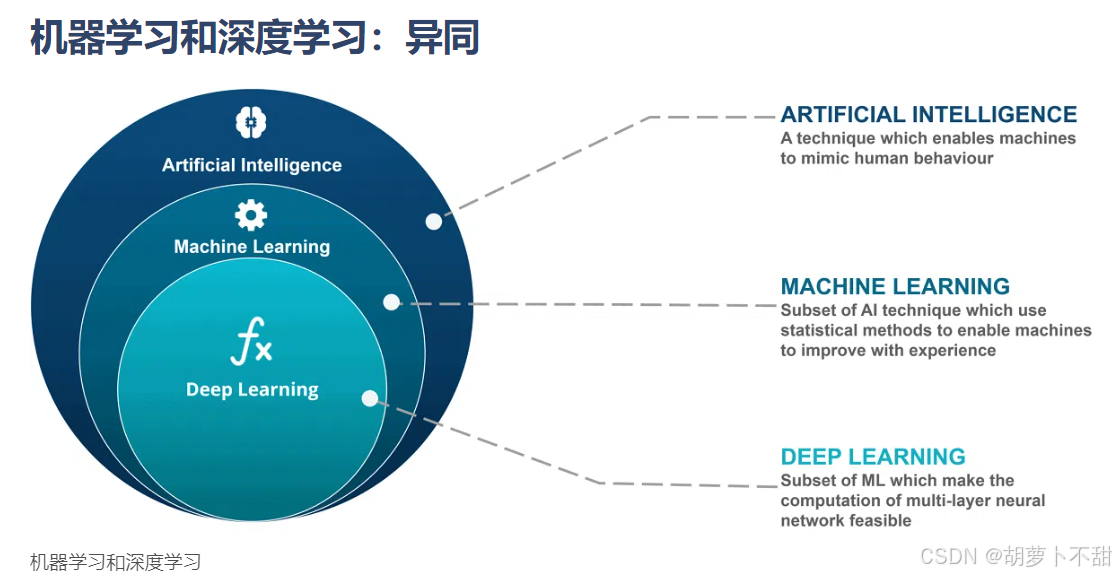
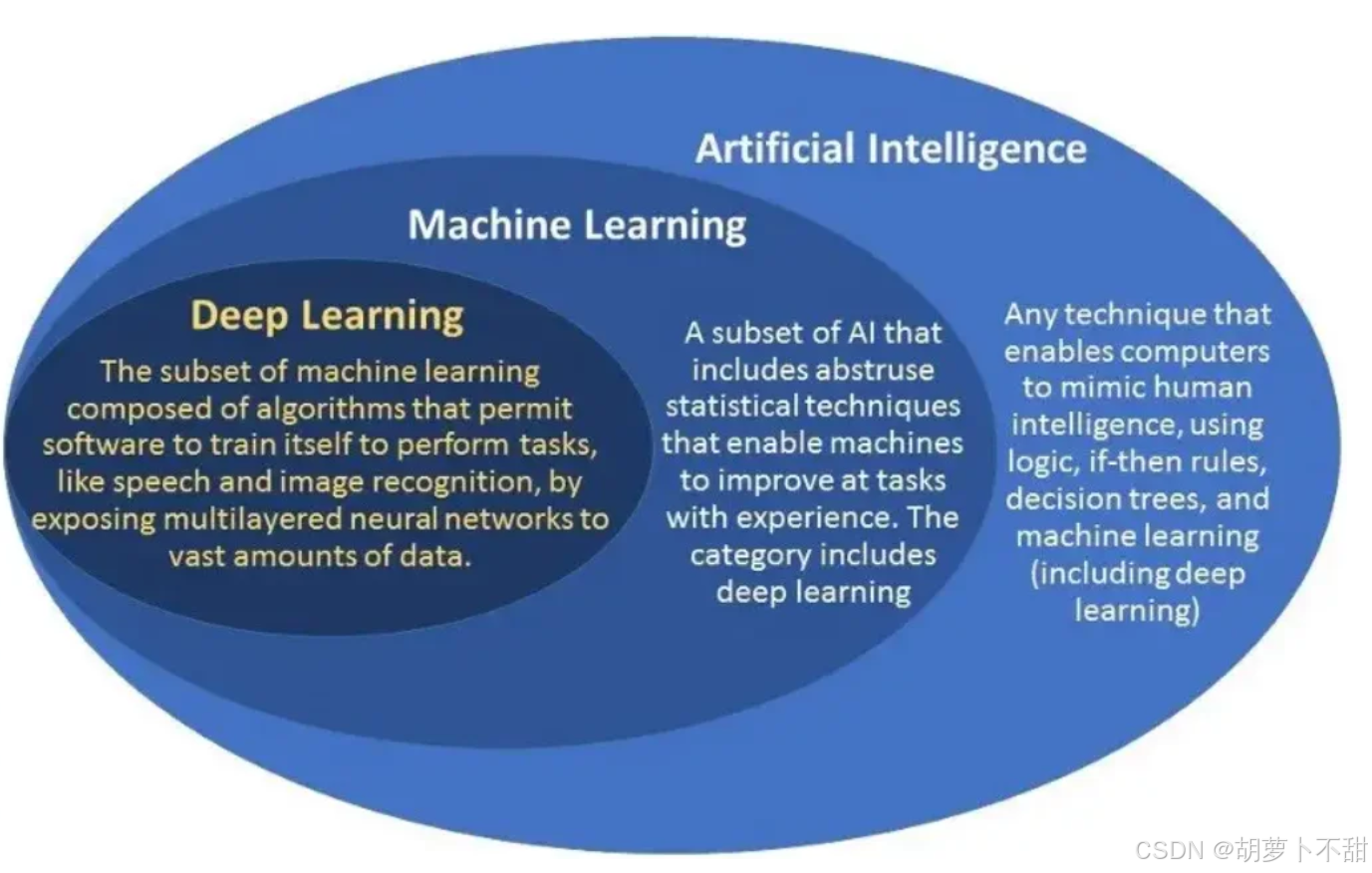
机器学习是人工智能的一个核心分支,它赋予计算机系统无需明确编程即可学习和改进的能力。通过分析大量数据,机器学习算法能够识别数据中的模式和趋势,从而做出预测或决策。这种方法通常涉及统计模型和优化技术,目的是构建能够从经验中学习的系统。
- 数据驱动:机器学习模型依赖于数据来提高其性能,这些数据可以是结构化的(如表格数据)或非结构化的(如文本或图像)。
- 算法多样性:机器学习领域包含了多种算法,包括但不限于决策树、支持向量机、聚类算法、降维技术等。
- 应用广泛:机器学习在金融、医疗、教育、制造业等多个行业都有应用,用于信用评分、疾病诊断、个性化推荐等任务。
1.2 深度学习定义
深度学习是机器学习的一个子集,它基于人工神经网络的概念,特别是那些具有多个非线性变换的层(即深度)。深度学习模型能够自动从原始数据中提取复杂的特征,而无需人为干预。
- 层次结构:深度学习模型由多个层次的神经元组成,每一层都对输入数据进行转换和抽象,从而捕捉数据的复杂特征。
- 自动特征提取:与传统机器学习方法相比,深度学习能够自动从原始数据中学习特征,减少了对人工特征工程的依赖。
- 计算密集型:深度学习模型通常需要大量的计算资源,包括高性能的GPU,以训练大规模的数据集和复杂的模型结构。
- 代表性模型:深度学习中的代表性模型包括卷积神经网络(CNNs)、循环神经网络(RNNs)、生成对抗网络(GANs)等。
2. 方法论
2.1 特征工程
特征工程是机器学习工作流程中的关键步骤,它涉及到从原始数据中提取出能够代表数据特征的变量,这些变量对于建立模型至关重要。在机器学习中,特征工程通常需要领域专家的深入参与,以确保所选特征对于预测任务是有意义的。
- 手动特征提取:在机器学习中,特征提取往往需要手动进行,数据科学家需要根据问题域知识来选择和构造特征。例如,在图像识别任务中,可能需要提取颜色、纹理、形状等特征;在文本分析中,则可能涉及到词频、TF-IDF等文本特征。
- 特征选择:特征选择是指从大量候选特征中选择最有用的特征子集的过程。这可以通过各种技术实现,如递归特征消除(RFE)、基于模型的特征选择等。
- 深度学习的自动特征提取:与机器学习不同,深度学习模型能够自动从数据中学习特征。例如,卷积神经网络(CNN)在图像处理中能够自动学习到图像的层次化特征,从简单的边缘和纹理到复杂的物体部分。
2.2 模型复杂度
模型复杂度是指模型的参数数量和结构的复杂性。机器学习模型通常较为简单,而深度学习模型则具有更高的复杂度。
- 机器学习模型的复杂度:机器学习模型如决策树、支持向量机等,通常参数较少,结构简单,易于理解和解释。这些模型在小数据集上表现良好,但可能难以捕捉数据中的复杂模式。
- 深度学习模型的复杂度:深度学习模型,如深度神经网络,通常包含数百万甚至数十亿个参数。这些模型能够捕捉数据中的复杂和非线性关系,但需要大量的数据和计算资源来训练。
- 过拟合风险:随着模型复杂度的增加,过拟合的风险也随之增加。过拟合是指模型在训练数据上表现良好,但在未见过的数据上表现不佳的现象。为了防止过拟合,常用的技术包括正则化、dropout、早停(early stopping)等。
- 计算资源需求:深度学习模型由于其复杂性,通常需要高性能的计算资源,如GPU或TPU。这些资源使得训练过程更加高效,但也增加了研究和部署的成本。相比之下,机器学习模型可以在普通的CPU上运行,对计算资源的要求较低。
3. 计算资源
3.1 算法复杂性
在机器学习和深度学习中,算法的复杂性直接影响了所需的计算资源。以下是对这两种技术在算法复杂性方面的比较:
-
机器学习算法的复杂性:机器学习算法通常较为简单,参数较少,例如线性回归、逻辑回归等。这些算法的数学模型相对直观,计算过程也较为直接,因此对计算资源的需求较低。例如,一个简单的决策树算法可能只需要几分钟就能在一台普通的个人电脑上完成训练。
-
深度学习算法的复杂性:深度学习算法,尤其是那些具有多个隐藏层的网络,参数数量巨大,计算过程涉及大量的矩阵运算。例如,一个大型的卷积神经网络(CNN)可能包含数百万甚至数十亿个参数,需要高性能的GPU或TPU来加速训练过程。深度学习模型的训练可能需要数小时甚至数天的时间,并且需要大量的内存和存储资源。
-
计算资源的需求:机器学习算法由于其简单性,通常可以在个人电脑或小型服务器上运行,而不需要专门的硬件加速。然而,深度学习模型则需要强大的计算能力,这通常意味着需要访问GPU集群或云计算资源。例如,训练一个大型的图像识别模型可能需要数十个GPU并行工作。
-
数据规模的影响:随着数据规模的增加,机器学习算法的性能可能会下降,因为它们可能无法有效地处理大量数据。而深度学习算法则能够利用其层次结构来处理大规模数据集,尽管这需要更多的计算资源。例如,深度学习在处理数百万张图片的数据集时,能够通过分布式训练来加速学习过程。
-
优化算法的选择:在机器学习中,优化算法的选择通常较为简单,如梯度下降、随机梯度下降等。而在深度学习中,为了处理复杂的模型和大数据集,可能需要更高级的优化技术,如Adam、RMSprop等,这些算法在计算上更为复杂。
-
实时应用的挑战:在需要实时响应的应用中,机器学习模型由于其简单性和较低的资源需求,更容易部署。而深度学习模型可能需要额外的优化才能满足实时性要求,例如通过模型压缩、量化或使用专门的硬件加速。
-
环境适应性:机器学习模型由于其较低的复杂性,更容易适应不同的计算环境,包括资源受限的设备。而深度学习模型则可能需要特定的硬件支持,限制了其在资源受限环境中的应用。
综上所述,机器学习和深度学习在算法复杂性上有显著差异,这直接影响了它们在计算资源需求上的差异。机器学习模型因其简单性而更适合资源受限的环境,而深度学习模型则需要强大的计算资源来处理其复杂的结构和大规模的数据集。
4. 应用场景
4.1 机器学习应用
机器学习在各个行业中有着广泛的应用,以下是一些典型的应用场景:
- 金融行业:机器学习被用于信用评分、欺诈检测、算法交易等。例如,根据一项研究,使用机器学习模型的银行能够将信用卡欺诈检测的准确率提高到85%以上。
- 医疗保健:在医疗领域,机器学习用于疾病诊断、个性化治疗计划和患者监护。一项研究表明,机器学习算法在识别皮肤癌方面的准确率与专业医生相当,甚至更高。
- 制造业:机器学习在制造业中的应用包括预测性维护、供应链优化和产品质量控制。据估计,通过使用机器学习进行预测性维护,企业可以减少高达50%的设备故障。
- 客户服务:机器学习驱动的聊天机器人和推荐系统在客户服务领域越来越受欢迎。例如,某电商平台通过机器学习推荐系统,提高了30%的销售额。
- 网络安全:机器学习被用于入侵检测系统和恶意软件识别。一项报告指出,使用机器学习的网络安全解决方案可以减少大约70%的误报。
4.2 深度学习应用
深度学习由于其强大的数据处理能力,在一些特定领域展现出了卓越的性能:
- 图像识别:深度学习,尤其是卷积神经网络(CNN),在图像识别和分类任务中取得了革命性的进展。例如,深度学习模型在ImageNet大规模视觉识别挑战赛中的错误率从2010年的28%降低到了2017年的2.3%。
- 自然语言处理:深度学习模型如循环神经网络(RNN)和Transformer在机器翻译、情感分析和语音识别等领域取得了显著成果。据报道,深度学习驱动的语音识别系统的准确率已经达到了95%以上。
- 自动驾驶:深度学习在自动驾驶汽车的感知和决策系统中发挥着关键作用。例如,某自动驾驶公司使用深度学习模型处理来自车辆传感器的数据,提高了行驶的安全性和可靠性。
- 游戏和模拟:深度学习被用于训练AI玩家,这些玩家在复杂的策略游戏中与人类玩家竞争。著名的AlphaGo就是使用深度学习训练的,它在围棋比赛中击败了世界冠军。
- 生物信息学:深度学习在蛋白质结构预测、基因表达分析等生物信息学任务中显示出了巨大潜力。一项研究显示,深度学习模型在预测蛋白质结构方面比传统方法更准确,为药物设计和疾病研究提供了新的可能性。
深度学习的应用通常需要大量的标注数据和计算资源,但它在处理复杂模式和高维度数据方面的能力使其在许多领域成为首选技术。
5. 总结
在本研究报告中,我们探讨了机器学习和深度学习的定义、方法论、计算资源需求以及在不同应用场景中的表现。以下是对这两项技术的主要区别和联系的总结:
5.1 定义与理论基础
机器学习作为人工智能的一个分支,侧重于通过数据驱动的方法使计算机系统能够学习和改进。它涵盖了多种算法,如决策树和支持向量机,这些算法能够从数据中学习并做出预测或决策。深度学习则是机器学习的一个子集,它使用多层神经网络来模拟人脑的处理方式,自动提取数据中的复杂特征。
5.2 方法论差异
在特征工程方面,机器学习通常需要手动特征提取和选择,而深度学习能够自动从数据中学习特征,减少了对人工干预的依赖。模型复杂度方面,机器学习模型相对简单,参数较少,而深度学习模型则具有更高的复杂度和参数数量,这使得它们能够捕捉更复杂的数据模式,但同时也增加了过拟合的风险。
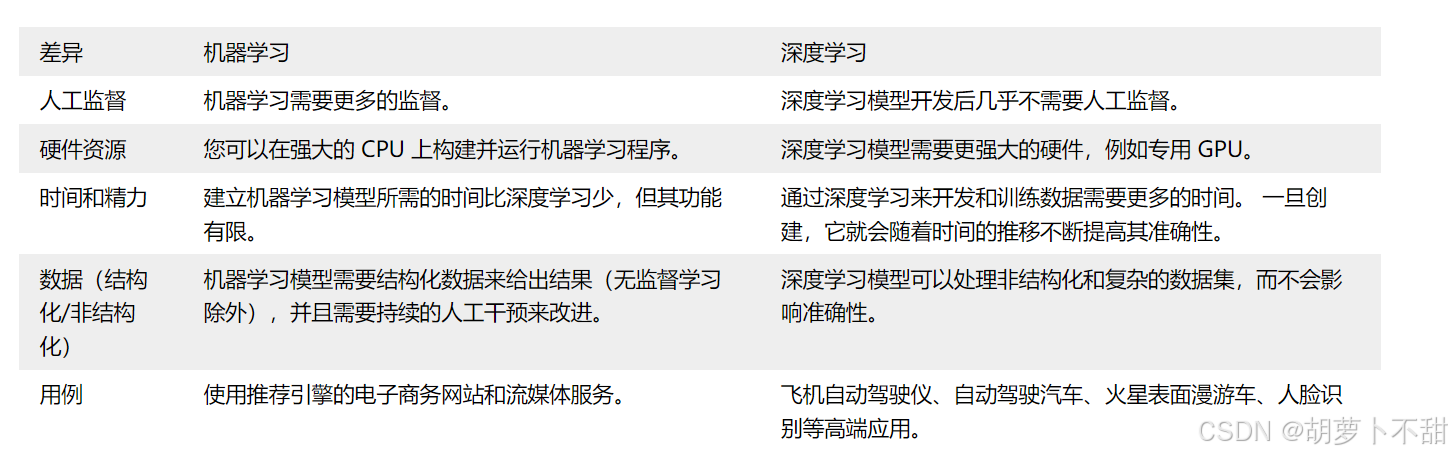
5.3 计算资源
机器学习算法通常计算复杂性较低,可以在普通的硬件上运行,而深度学习算法则需要大量的计算资源,如GPU或TPU,以及相应的内存和存储资源。深度学习模型的训练过程通常更为耗时和资源密集。
5.4 应用场景
机器学习在金融、医疗、制造业等多个行业中有广泛应用,特别是在数据量不是特别大且问题定义明确的场景下。深度学习则在图像识别、自然语言处理、自动驾驶等需要处理复杂模式和高维度数据的领域中展现出了卓越的性能。
5.5 综合比较
总的来说,机器学习和深度学习各有优势和适用场景。机器学习在数据量较小、问题定义明确的场景下更为有效,而深度学习则在处理大规模复杂数据集和识别复杂模式方面更为强大。随着计算资源的日益丰富和算法的不断进步,这两种技术都在不断地推动人工智能领域的发展,并在实际应用中取得了显著的成果。
复制再试一次分享