熵

信息增益
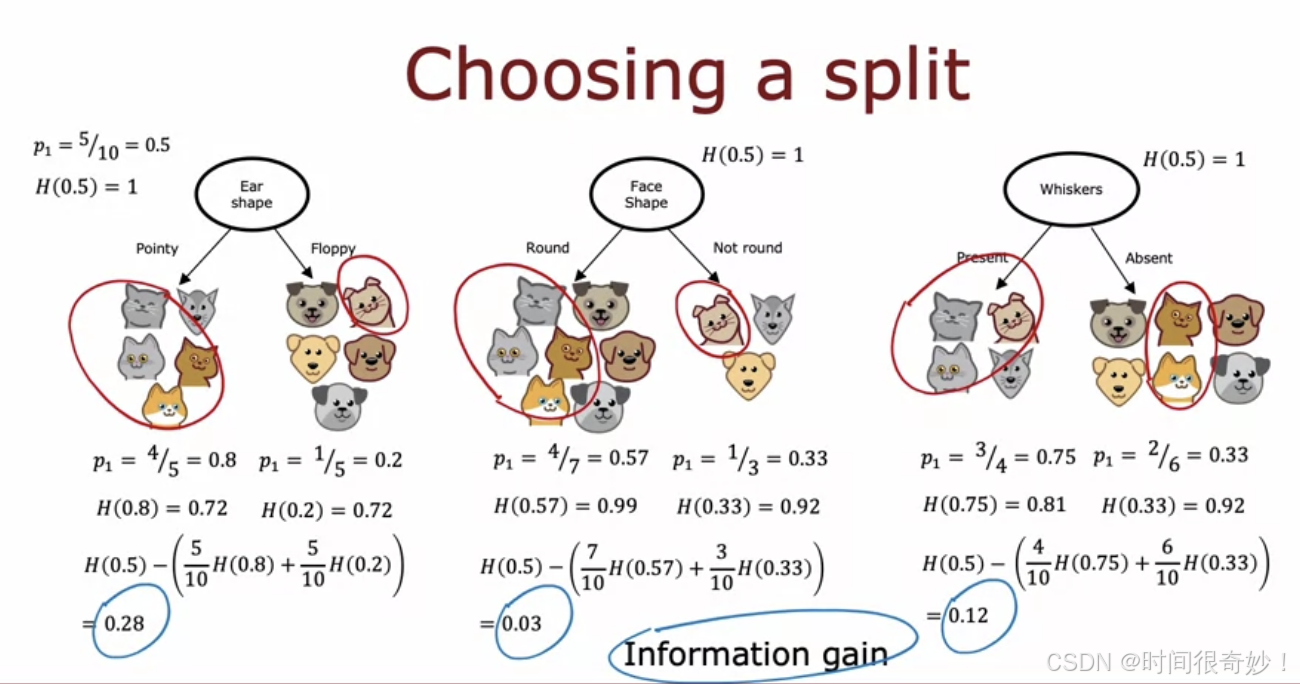
信息增益描述的是在分叉过程中获得的熵减,信息增益即熵减。
熵减可以用来决定什么时候停止分叉,当熵减很小的时候你只是在不必要的增加树的深度,并且冒着过拟合的风险

决策树训练(构建)过程

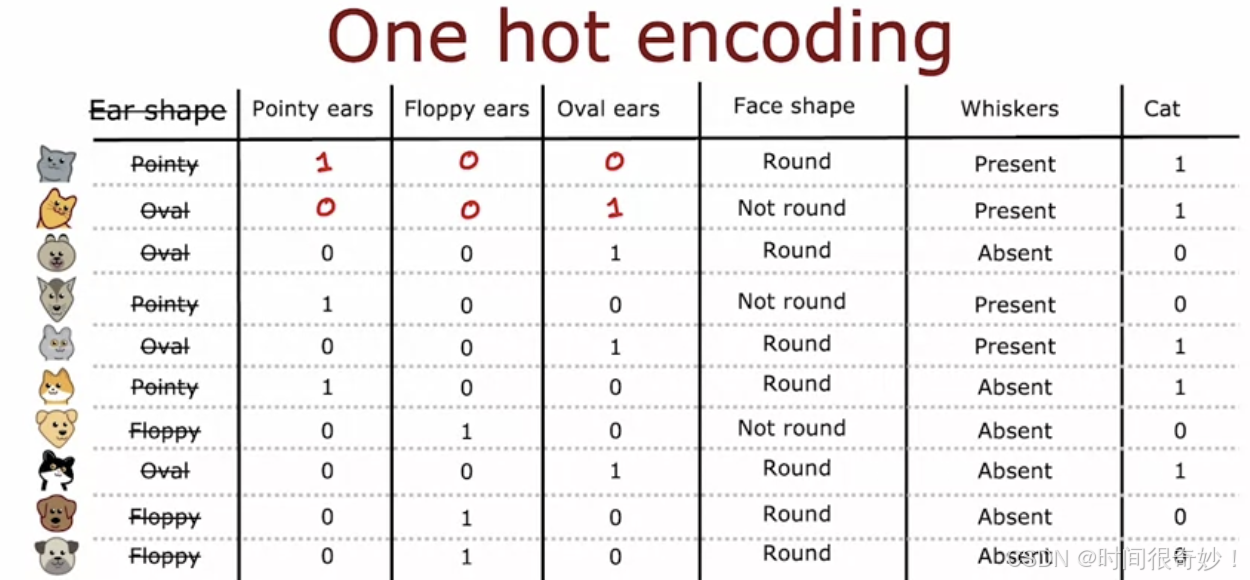
离散值特征处理:One-Hot编码
一个具有 N 个取值的离散特征可以转换为 N 个二进制特征,每个二进制特征对应一个可能的取值。
连续值特征处理:
计算不同阈值的熵减,选取熵减最大的阈值作为分叉阈值

回归树
回归树用来预测一个连续值,训练时跟决策树的区别是训练时最小化方差,而决策树是最大化熵减

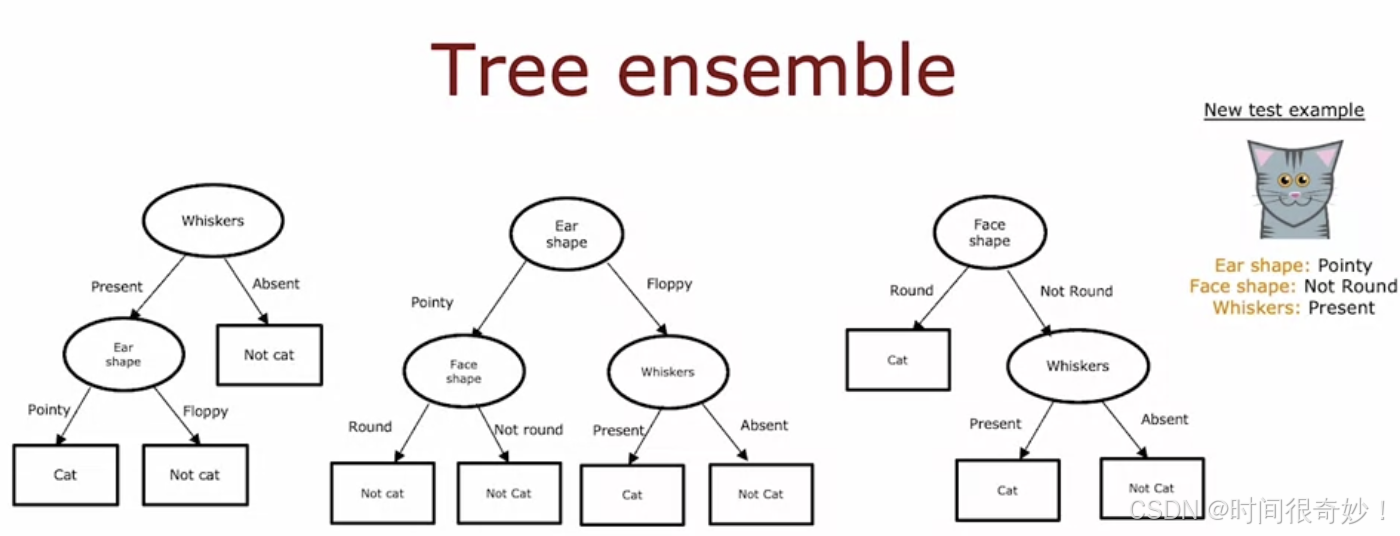
集成树
单个决策树的一个缺点是对数据的变化比较敏感,我们需要尝试降低树的敏感度提高鲁棒性,此时我们可以构建集成树,即一组决策树
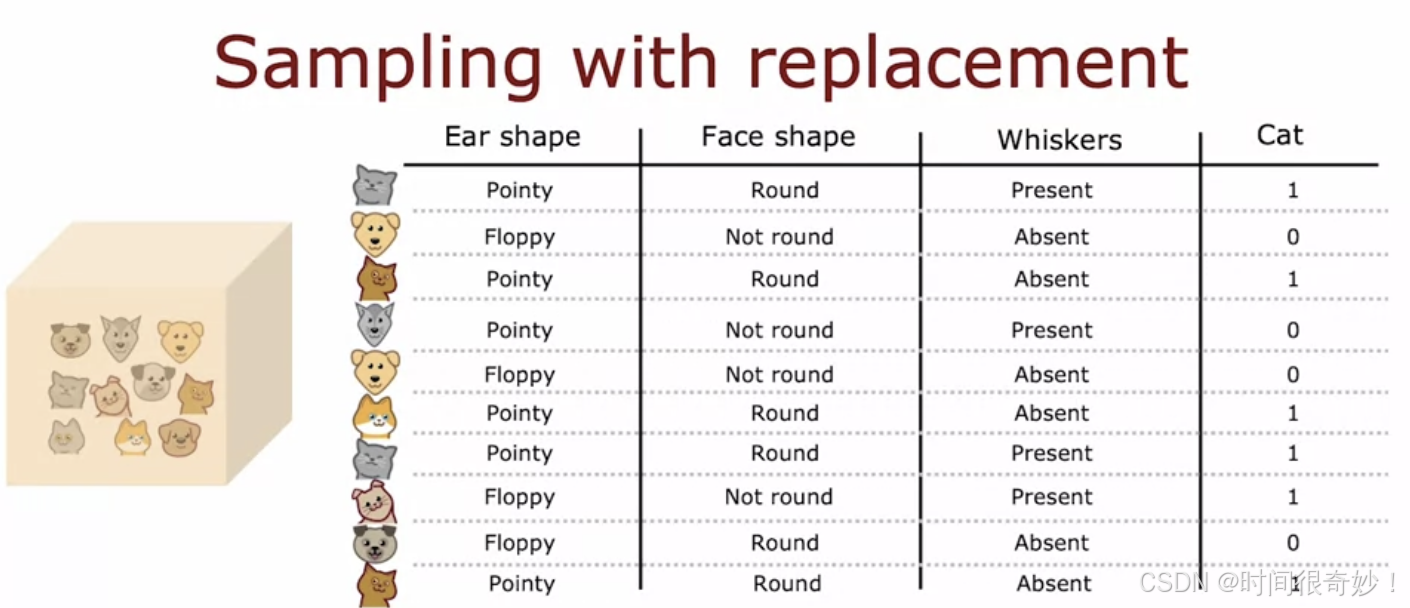
有放回抽样(sample with replacement)
从训练集中随机取出一个之后放回,确保它在后续抽取中仍有可能被再次抽到。
随机森林
利用有放回抽样,我们可以连续抽样并组成新的训练集,使用新的训练集训练一棵新的树。重复该行为可以生成多棵树,称为随机森林。
如果有 n 个特征,一般要生成 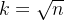

XGBoost
对随机森林的提升:从第二次迭代开始,不是等概率随机抽样,而是让上一轮预测错误的样本有更大的概率被抽样到,以类似错误修正的方式训练树。


决策树与神经网络的选择
决策树在结构化数据下可用,非结构化数据不推荐;可解释
