一.什么是全文索引?
全文索引通过分析和处理文本,将文档中的单词分解为词条(tokens),然后存储词条与其所在文档的映射关系。这使得数据库可以快速定位包含特定关键字的记录,而不必对所有文本逐字匹配。
二.实验
CREATE TABLE test (
TEST_ID NUMBER(6),
TEST_NAME VARCHAR2(50),
TEST_DESC VARCHAR2(4000)
);
BEGIN
FOR i IN 1..10000 LOOP
INSERT INTO test (TEST_ID,TEST_NAME,TEST_DESC)
VALUES (
i,
'Product ' || i,
DBMS_RANDOM.STRING('A', 2000)
);
END LOOP;
COMMIT;
END;
/创建一个普通索引
create index idx_test on test(test_desc);查看执行计划,检查索引是否生效
select * from test where test_desc like 'LRbwu%';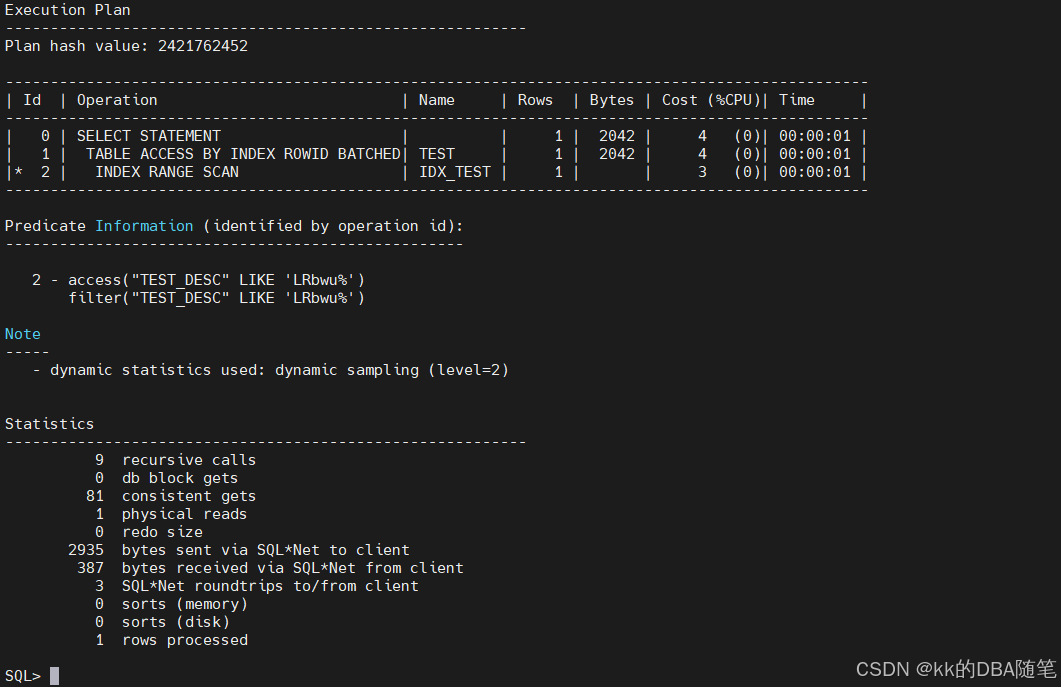
到此,是没有任何问题的,在这种情况中,我们知道test_id 是以什么字符开头的
那么就会有这么一种情况,我们不知道这个内容开头是什么,只知道中间是什么,有什么关键字,那么这种情况 我们就需要<%内容%>,那么这种情况还会走索引吗?
select * from test where test_desc like '%AoaUR%';
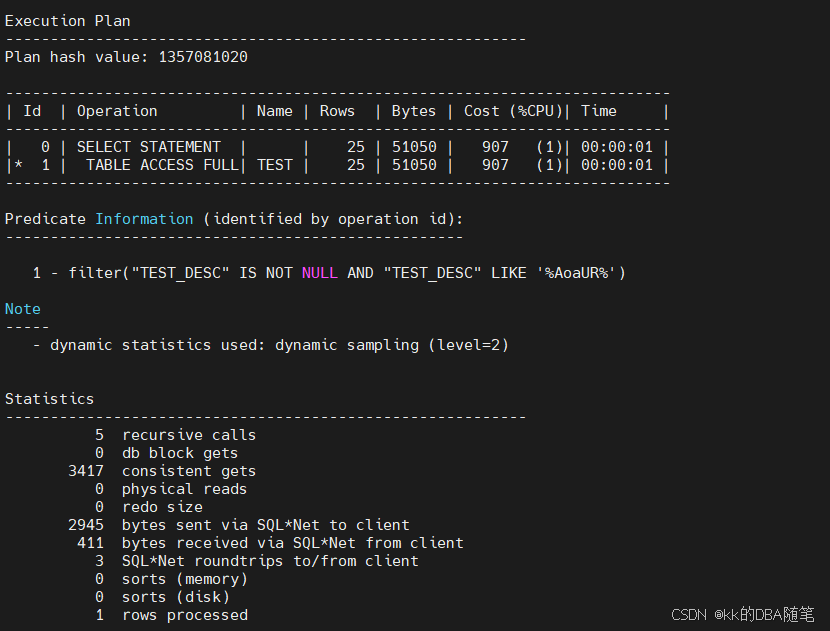
这时候我们发现,走了全表扫描,所以普通的索引解决不了我们只知道关键字,而不知道以什么字符开头的情况。
这也可以理解,B Tree索引只顺序存储了表中列值以及对应的rowid,并且对于索引中字符串的排序,是根据该字符串第一个字符的ASCⅡ码,第一个字符的ASCⅡ码相同,再解析第二个。在这种情况中,我们不知道字符串前面的字符是什么,所以B Tree索引无法使用。
所以这种场景就需要我们今天介绍的内容-全文索引
三.使用全文索引
在使用之前,数据库中必须要系统用户CTXSYS,如果没有则有两种方式来配置
1.dbca配置数据库,这里不做演示,配置后产生了CTXSYS用户

2.跑脚本
/u01/app/oracle/product/19.3.0/dbhome_1/ctx/admin
ls -al catctx.sql在数据库中跑这个脚本就好。
创建全文索引
确认已存在的段
col segment_name for a30
col object_name for a30
select segment_name ,segment_type from user_segments;
create index idx_ctx_test on test(test_desc) indextype is ctxsys.context;
这里我们发现,全文索引可以建立在普通索引之上,意思是表中的一列有索引了,仍然可以建立全文索引,说明全文索引的结构和普通索引的结构肯定是有区别的。
select * from test where contains(test_desc,'LRbwu') > 0;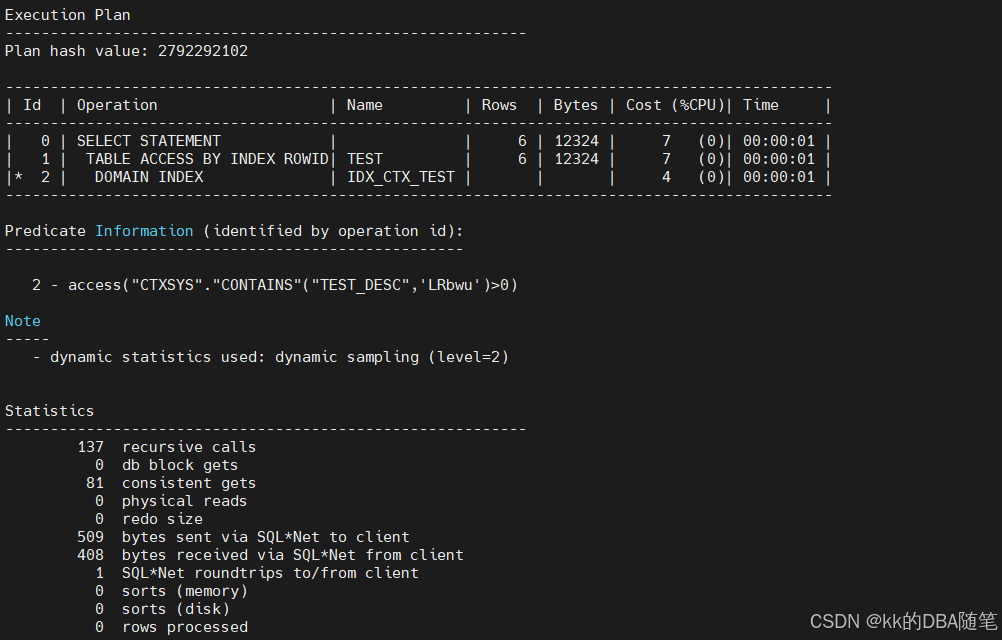
可以看到sql语句走了全文索引。
再查看一下现在的段都有哪些
col segment_name for a30
col object_name for a30
select segment_name ,segment_type from user_segments;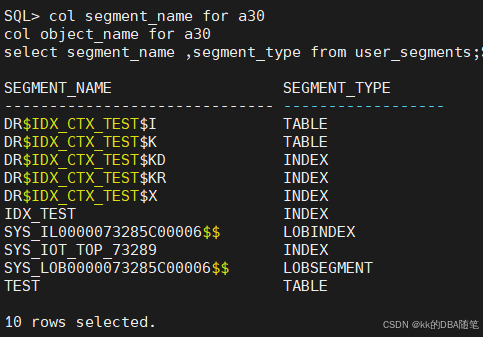
可以看到段多了很多TEST是基本表,剩下的除了IDX_TEST是普通索引,剩下的全是全文索引,
但是我们刚才创建的索引名字是idx_ctx_test,发现找不到,这是因为全文索引只是逻辑上的概念,他没有存储对象,它的实现都依赖这些表。
四.深入全文索引
我们来看看这几张表
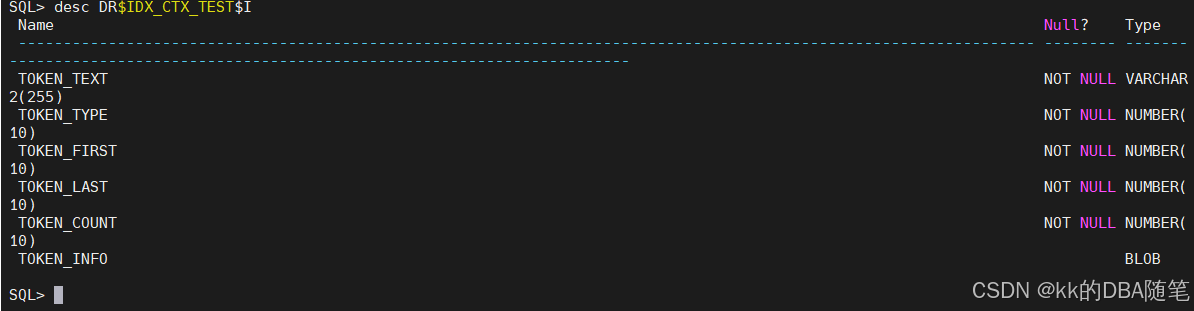
出现的token给他编一个号,并且存储了重复出现的次数(TOKEN_COUNT)
我们随机搜索一个字符串。
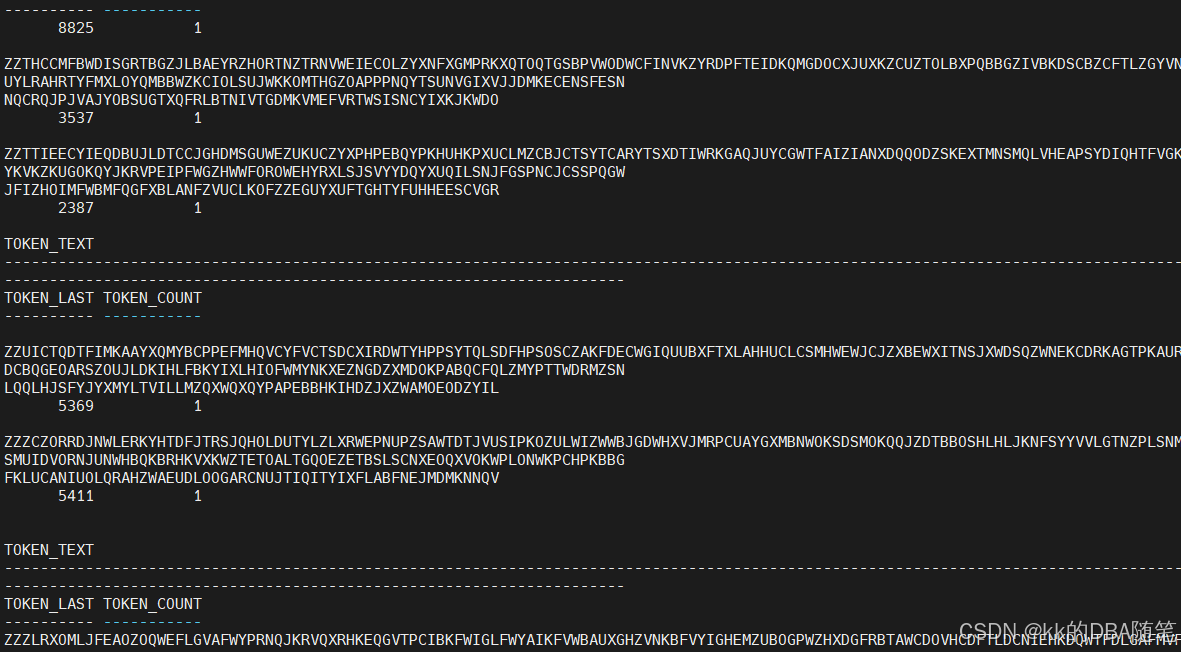
DR$IDX_CTX_TEST$I 这个表把test_desc 这一列的值像字典一样保存出来,编一个号,并且总结出现的次数。但由于我是使用的DBMS_RANDOM.STRING 这个包随机创建的数据,所以这个表非常的大。
编了号之后,仍然不知道这些词在哪个地方,这时候就需要另外一张表 DR$IDX_CTX_TEST$K

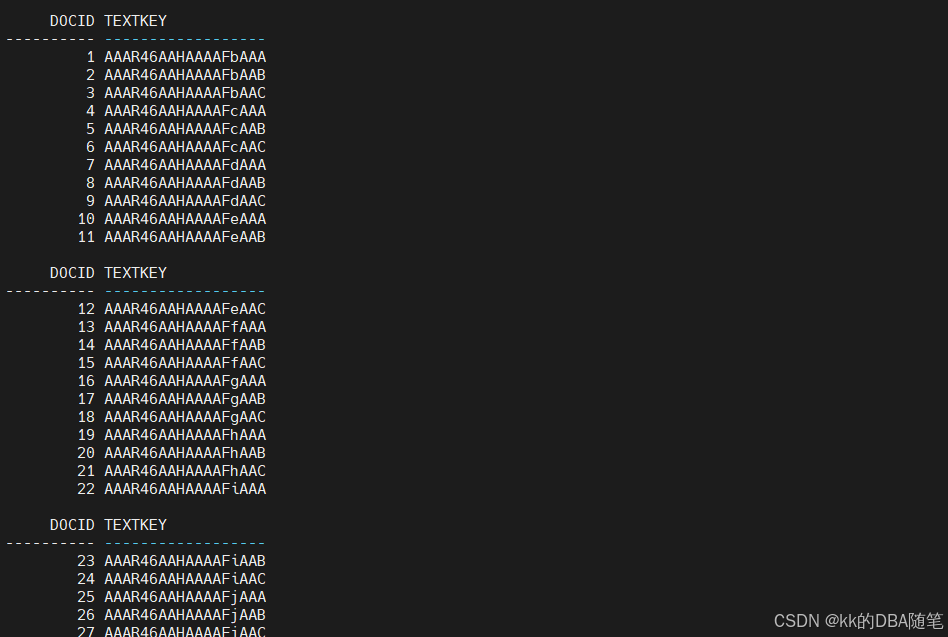
这个TEXTKEY就是rowid了,我们可以根据TESTKEY找到数据了.
也就是说 DR$IDX_CTX_TEST$I 会生成token和编号,DR$IDX_CTX_TEST$K 表示对应的这些编号数据存放在哪里
五.全文索引的维护
在TEST表上做DML操作,看索引与表是否同步4
1.insert
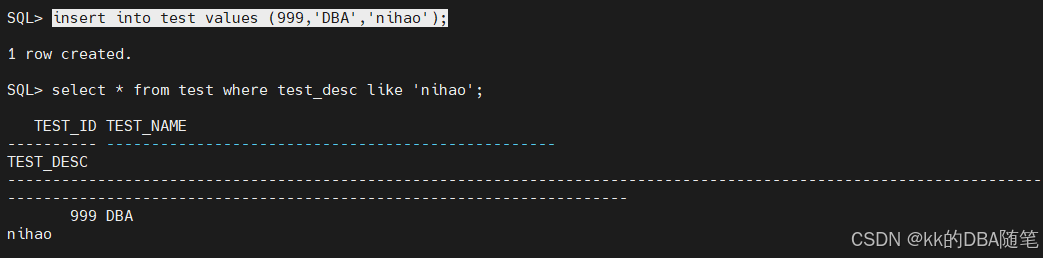
select * from test where test_desc like 'nihao';
insert into test values (999,'DBA','nihao');
此时通过全文索引查找数据,查看是否更新
select * from test where contains(test_desc,'nihao') > 0;
发现全文索引没有更新,这就说明表中的数据变了,而全文索引中的数据没有变。
使用sys查看ctxsys.dR$pending表
select * from ctxsys.dR$pending;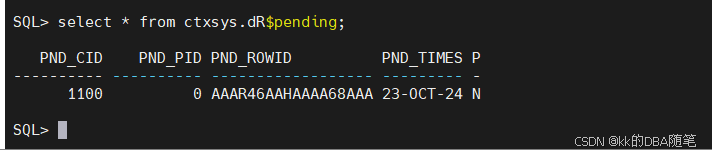
这个表里面的数据就是我刚才插入的数据,只是没有更新到全文索引
这种情况需要重建全文索引。
alter index idx_ctx_test rebuild;再次使用全文索引查询发现更新了

2.delete
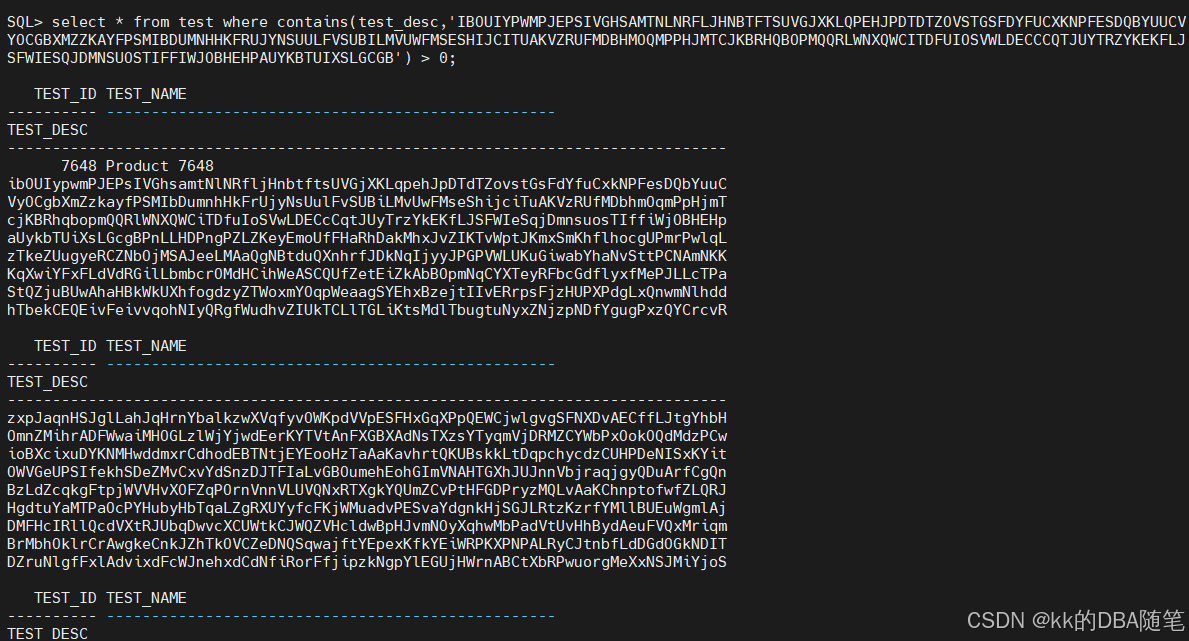
查看全文索引

这里可以发现,delete与insert语句不同,delete后 全文索引也更新了。
3.update,可以自己做实验,update也是不同步全文索引的。
六.全文索引创建同步的方式
一遇到插入的场景就需要重建全文索引,这也太麻烦了,所以,我们可以在创建全局索引的时候指定同步的方式。
提交时同步
create index idx_ctx_test on test(test_desc) indextype is ctxsys.context parameters('sync (on commit)');指定时间同步(建议)
需要给用户 job的权限
grant create job to user1;

例如:每天晚上两点来同步全文索引
create index idx_ctx_test on test(test_desc) indextype is ctxsys.context parameters ('sync (every "trunc(sysdate) + 2/24")');