注意:为了简便起见,这里采用邻接矩阵的方式储存图的边信息
图的遍历是指从图中的某一顶点出发,按照某种搜索方法沿着图中的边对图中的所有顶点访问一次且仅访问一次。
注意到树是一种特殊的图,所以树的遍历实际上也可视为一种特殊的图的遍历。
图的遍历算法是求解图的连通性问题、拓扑排序和求关键路径等算法的基础。
图的遍历比树的遍历要复杂得多,因为图的任一顶点都可能和其余的顶点相邻接,所以在访问某个顶点后,可能沿着某条路径搜索又回到该顶点上。为避免同一顶点被访问多次,在遍历图的过程中,必须记下每个已访问过的顶点,为此可以设一个辅助数组visited[]来标记顶点是否被访问过。
图的遍历算法主要有两种:广度优先搜索和深度优先搜索
1.邻接矩阵图的广度优先遍历
广度优先搜索类似于二叉树的层序遍历算法。
基本思想是:
- 首先访问起始顶点V
- 接着由V出发,依次访问V的各个未访问过的邻接顶点W1, W2,…,Wi
- 然后依次访问W1, W2,…,的所有未被访问过的邻接顶点
- 再从这些访问过的顶点出发,访问它们所有未被访问过的邻接顶点直至图中所有顶点都被访问过为止。
- 若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作为始点,重复上述过程,直至图中所有顶点都被访问到为止。
Dijkstra单源最短路径算法和Prim最小生成树算法也应用了类似的思想。
换句话说,广度优先搜索遍历图的过程是以v为起始点,由近至远依次访问和v有路径相通且路径长度为1, 2,…的顶点。
广度优先搜索是一种分层的查找过程,每向前走一步可能访问一批顶点,不像深度优先搜索那样有往回退的情况,因此它不是一个递归的算法。为了实现逐层的访问,算法必须借助一个辅助队列,以记忆正在访问的顶点的下一层顶点
这里使用C++实现从图的某个点开始进行BFS遍历
// 邻接矩阵法存储图结构
#include <iostream>
#include <assert.h>
#include <map>
#include <vector>
#include <stdio.h>
// v:图顶点保存的值。w:边的权值 max:最大权值,代表无穷。flag=true代表有向图。否则就是无向图
template <class v, class w, w max = INT_MAX, bool flag = false>
class graph
{
public:
std::vector<v> _verPoint; // 顶点集合
std::map<v, int> _indexMap; // 顶点与下标的映射
std::vector<std::vector<w>> _matrix; // 邻接矩阵
int _getPosPoint(const v &point)
{
if (_indexMap.find(point) != _indexMap.end())
{
return _indexMap[point];
}
else
{
std::cout << point << " not found" << std::endl;
return -1;
}
}
public:
// 根据数组来开辟邻接矩阵
graph(const std::vector<v> &src)
{
_verPoint.resize(src.size());
for (int i = 0; i < src.size(); i++)
{
_verPoint[i] = src[i];
_indexMap[src[i]] = i;
}
// 初始化邻接矩阵
_matrix.resize(src.size());
for (int i = 0; i < src.size(); i++)
{
_matrix[i].resize(src.size(), max);
}
}
// 添加边的关系,输入两个点,以及这两个点连线边的权值。
void AddEdge(const v &pointA, const v &pointB, const w &weight)
{
// 获取这个顶点在邻接矩阵中的下标
int posA = _getPosPoint(pointA);
int posB = _getPosPoint(pointB);
_matrix[posA][posB] = weight;
if (!flag)
{
// 无向图,邻接矩阵对称
_matrix[posB][posA] = weight;
}
}
// 打印邻接矩阵
void PrintGraph()
{
// 打印顶点对应的坐标
typename std::map<v, int>::iterator pos = _indexMap.begin();
while (pos != _indexMap.end())
{
std::cout << pos->first << ":" << pos->second << std::endl;
pos++;
}
std::cout << std::endl;
// 打印边
printf(" ");
for (int i = 0; i < _verPoint.size(); i++)
{
std::cout << _verPoint[i] << " ";
}
printf("\n");
for (int i = 0; i < _matrix.size(); i++)
{
std::cout << _verPoint[i] << " ";
for (int j = 0; j < _matrix[i].size(); j++)
{
if (_matrix[i][j] == max)
{
// 这条边不通
printf("∞ ");
}
else
{
std::cout << _matrix[i][j] << " ";
}
}
printf("\n");
}
printf("\n");
}
};
#include "matrix.h"
#include <queue>
#include <vector>
using namespace std;
template <class v, class w, w max = INT_MAX, bool flag = false>
void BFS(graph<v, w> &graph, const v begin)
{
int beginPos = graph._getPosPoint(begin);
queue<int> q;
q.push(beginPos);
// 标记数组
vector<bool> visit(graph._matrix.size(), false);
visit[beginPos] = true;
int levelSize = 1;
while (!q.empty())
{
for (int i = 0; i < levelSize; i++)
{
int font = q.front();
cout << font << ":" << graph._verPoint[font];
q.pop();
// 这个节点的周围节点入队列
for (int j = 0; j < graph._verPoint.size(); j++)
{
if (graph._matrix[font][j] != max)
{
if (visit[j] == false)
{
q.push(j);
visit[j] = true;
}
}
}
}
levelSize = q.size();
cout << "\n";
}
cout << "\n";
}
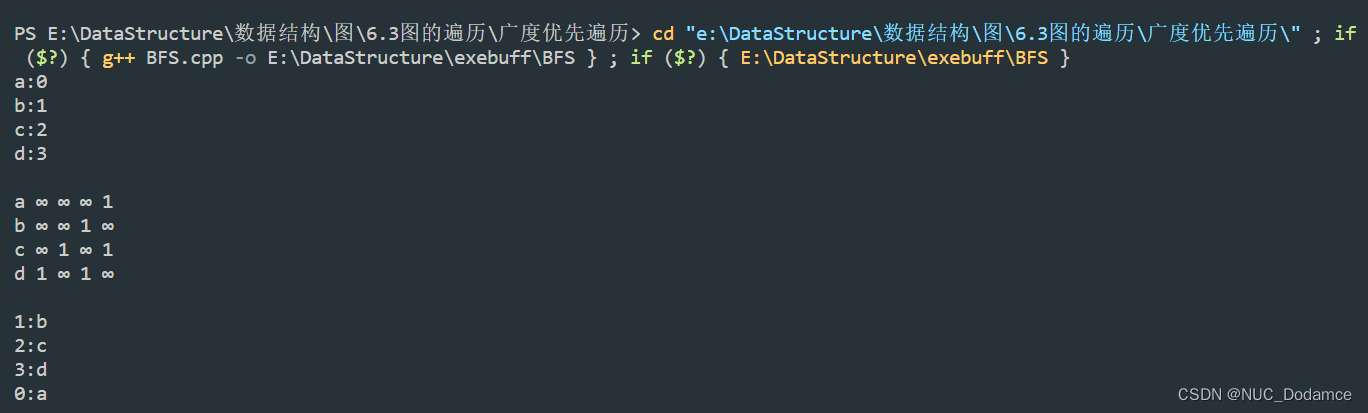
int main(int argc, char const *argv[])
{
vector<char> vet = {'a', 'b', 'c', 'd'};
graph<char, int> graph(vet);
graph.AddEdge('a', 'd', 1);
graph.AddEdge('c', 'b', 1);
graph.AddEdge('c', 'd', 1);
graph.PrintGraph();
BFS(graph, 'b');
return 0;
}
根据代码可知:
如果图是连通图,则上述的遍历方式可以将图全部遍历完毕。
如果不是连通图,最后看标记数组是否全部已经被标记。如果还有点没有标记,则说明这个图不是连通图。此时更改点继续遍历。
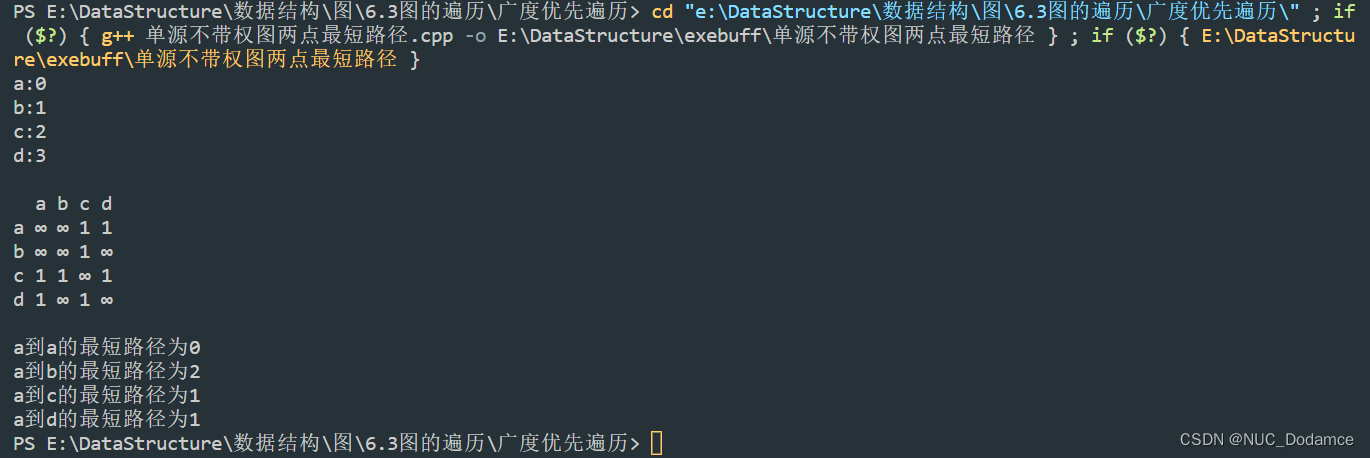
单源非带权图的两点最短路径
利用广度优先遍历也可以求单源非带权图的两点最短路径。
若图G = (V, E)为非带权图,定义从顶点u到顶点v的最短路径d(u, v)为从u到v的任何路径中最少的边数;若从u到v没有通路,则d(u,v)=∞。
使用BFS,我们可以求解一个满足上述定义的非带权图的单源最短路径问题,这是由广度优先搜索总是按照距离由近到远来遍历图中每个顶点的性质决定的
下面是测试代码:
#include "matrix.h"
#include <queue>
#include <vector>
#include <algorithm>
using namespace std;
template <class v, class w, w max = INT_MAX, bool flag = false>
int BFS_FindShortest(graph<v, w> &graph, const v begin, const v end)
{
int beginPos = graph._getPosPoint(begin);
int endPos = graph._getPosPoint(end);
vector<int> ret(graph._verPoint.size(), max); // ret[i]为begin到i的最短路径,最后函数返回值应为ret[endPos],ret[i]=max代表begin到i不通,不是连通图
queue<int> q;
vector<bool> visit(graph._verPoint.size(), false);
ret[beginPos] = 0;
q.push(beginPos);
int levelSize = 1;
visit[beginPos] = true;
int level = 1;
while (!q.empty())
{
for (int i = 0; i < levelSize; i++)
{
int font = q.front();
q.pop();
for (int j = 0; j < graph._verPoint.size(); j++)
{
if (visit[j] == false && graph._matrix[font][j] != max)
{
ret[j] = level;
q.push(j);
visit[j] = true;
}
}
}
levelSize = q.size();
level += 1;
}
// 打印最短路径
for (int i = 0; i < ret.size(); i++)
{
cout << graph._verPoint[beginPos] << "到" << graph._verPoint[i] << "的最短路径为" << ret[i] << std::endl;
}
return ret[endPos];
}
int main(int argc, char const *argv[])
{
vector<char> vet = {'a', 'b', 'c', 'd'};
graph<char, int> graph(vet);
graph.AddEdge('a', 'd', 1);
graph.AddEdge('c', 'b', 1);
graph.AddEdge('c', 'd', 1);
graph.AddEdge('a', 'c', 1);
graph.PrintGraph();
BFS_FindShortest(graph, 'a', 'd');
return 0;
}
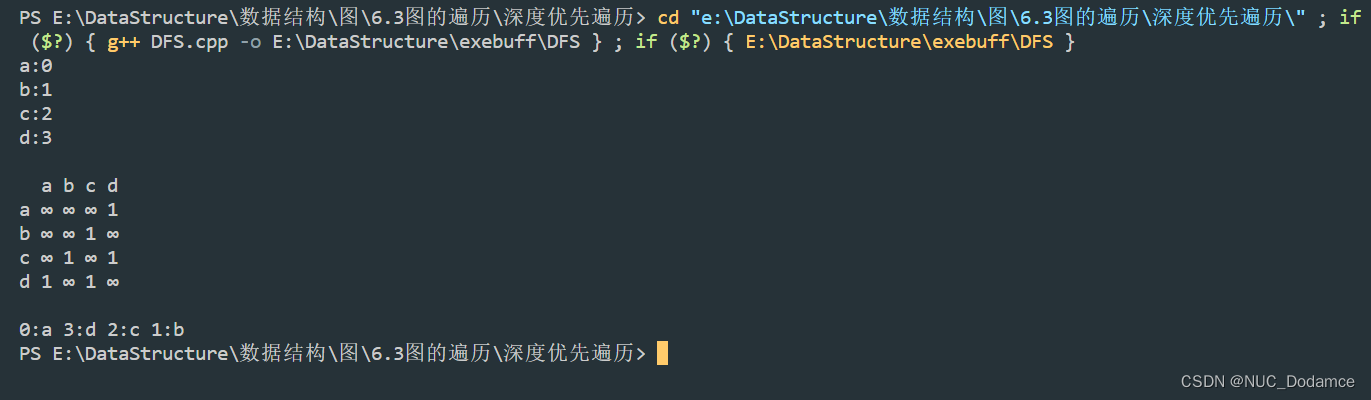
2. 邻接矩阵图的深度优先遍历
与广度优先搜索不同,深度优先搜索类似于树的先序遍历。
如其名称中所暗含的意思一样,这种搜索算法所遵循的搜索策略是尽可能“深”地搜索一个图。
它的基本思想如下:
- 首先访问图中某一起始顶点v
- 然后由v岀发,访问与v邻接且未被访问的任一顶点W
- 再访问与Wi邻接且未被访问的任一顶点
- 重复上述过程。当不能再继续向下访问时,依次退回到最近被访问的顶点
- 若它还有邻接顶点未被访问过,则从该点开始继续上述搜索过程,直至图中所有顶点均被访问过为止。
#include "../广度优先遍历/matrix.h"
using namespace std;
template <class v, class w, w max = INT_MAX, bool flag = false>
void _DFS(graph<v, w> &graph, int beginPos, vector<bool> &visit)
{
cout << beginPos << ":" << graph._verPoint[beginPos] << " ";
visit[beginPos] = true;
// 这个点周围的点进行遍历
for (int i = 0; i < graph._verPoint.size(); i++)
{
if (visit[i] == false && graph._matrix[beginPos][i] != max)
{
_DFS(graph, i, visit);
}
}
}
template <class v, class w, w max = INT_MAX, bool flag = false>
void DFS(graph<v, w> &graph, const v begin)
{
vector<bool> visit(graph._verPoint.size(), false);
int beginPos = graph._getPosPoint(begin);
_DFS(graph, beginPos, visit);
cout << "\n";
}
int main(int argc, char const *argv[])
{
vector<char> vet = {'a', 'b', 'c', 'd'};
graph<char, int> graph(vet);
graph.AddEdge('a', 'd', 1);
graph.AddEdge('c', 'b', 1);
graph.AddEdge('c', 'd', 1);
graph.PrintGraph();
DFS(graph, 'a');
return 0;
}
3. 广度/深度优先遍历生成树和森林
深度优先生成树与森林
深度优先搜索遍历图会产生一棵深度优先生成树。(对连通图调用DFS才能产生深度优先生成树)
否则产生的将是深度优先生成森林
eg:
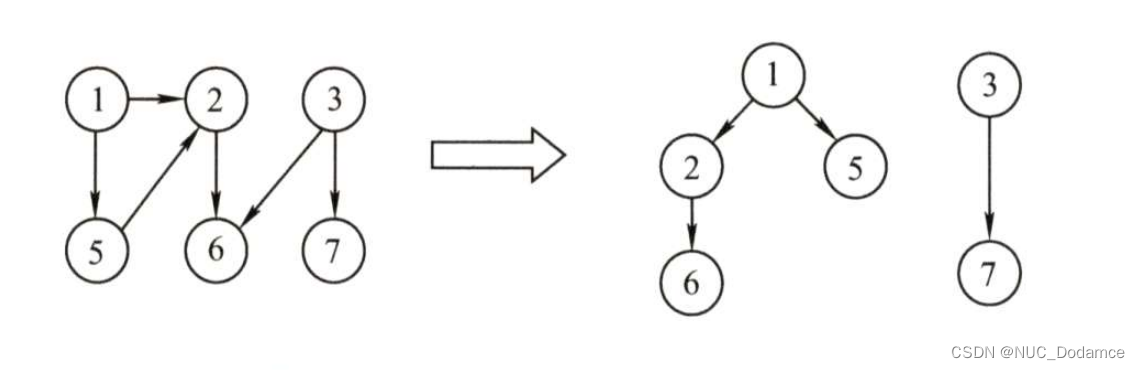
因为图的邻接矩阵是唯一的,所以邻接矩阵的深度优先生成树是唯一的。
而图的邻接表是不唯一的,所以邻接表的深度生成树是不唯一的。
深度优先生成森林步骤:
- 首先找到图的连通分量
- 每一个连通分量使用深度优先遍历生成树。
- 多个连通分量的深度优先生成树构成森林
对每个连通分量进行深度优先搜索,最终得到 3 棵生成树
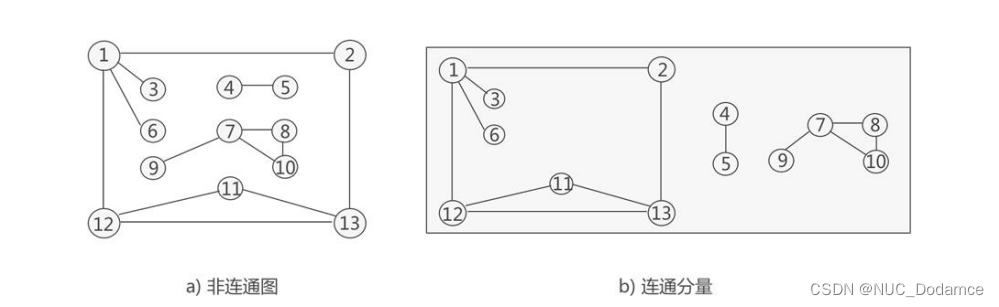
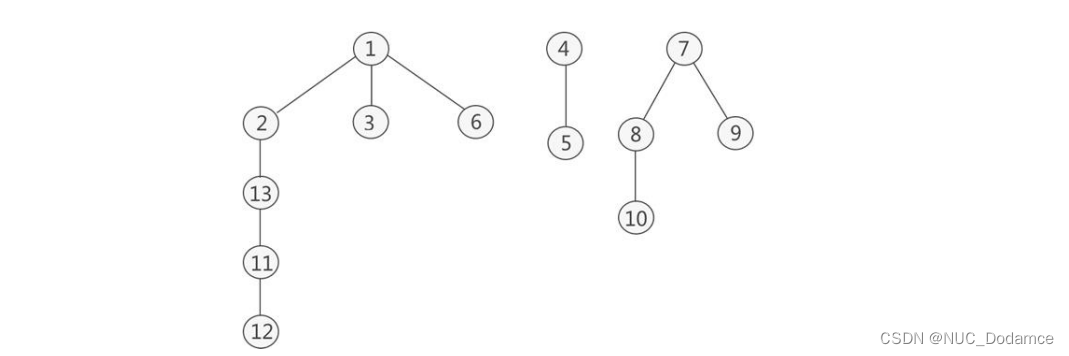
使用深度优先搜索算法遍历非连通图,得到的生成森林就称为深度优先生成森林
根据之前学过的知识
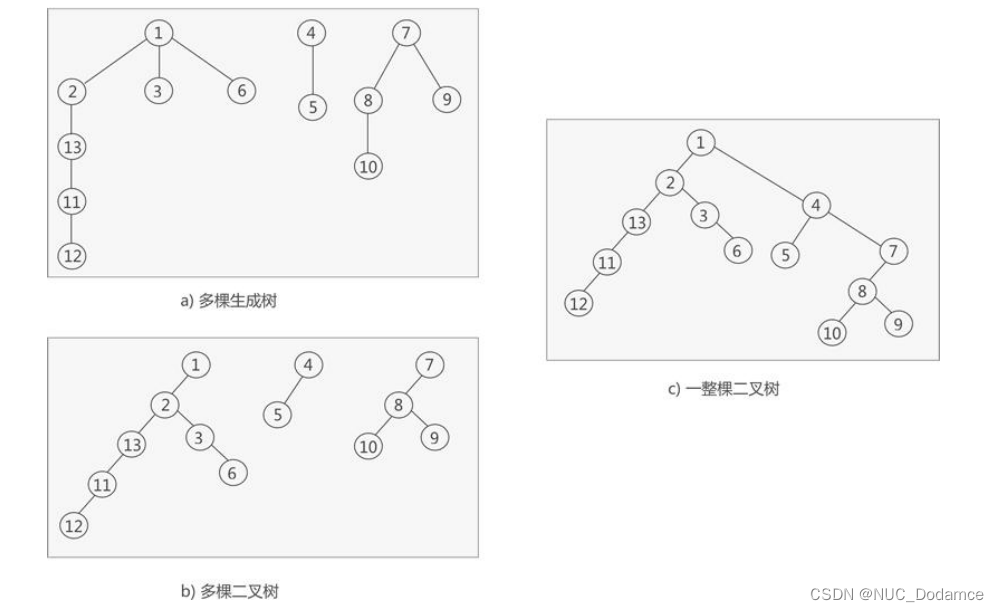
借助孩子兄弟表示法,可以将森林中的每一棵生成树都转换为二叉树,然后再将多棵二叉树合并为一整颗二叉树
广度优先遍历生成树与森林
在广度遍历的过程中,我们可以得到一棵遍历树,称为广度优先生成树(连通图)
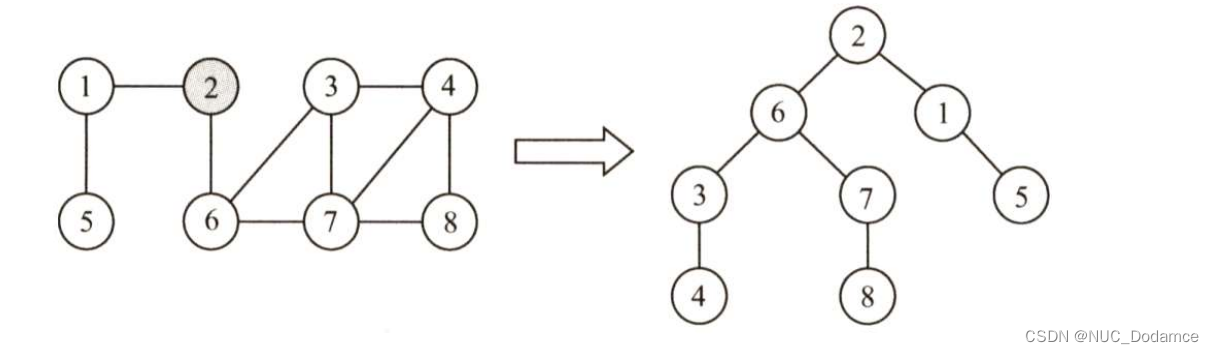
需要注意的是:
一给定图的邻接矩阵存储表示是唯一的,故其广度优先生成树也是唯一的
但由于邻接表存储表示不唯一,故其广度优先生成树也是不唯一的
同样的道理,用广度优先搜索算法遍历非连通图得到的生成森林又称广度优先生成森林。
对于广度优先生成树,其一般是普通的树。
通常先借助孩子兄弟表示法将普通树转换为二叉树,然后再操作二叉树实现自己想要的功能。
这两部分的C++代码比较复杂,貌似考的也不多,先空开。
后序如果在复习备考的时候遇到算法题,应该会补上。(咕咕咕)