
| 论文题目 | Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting |
|---|---|
| 论文链接 | https://arxiv.org/abs/1707.01926 |
| 源码地址 | https://github.com/liyaguang/DCRNN |
| 发表年份-会议/期刊 | 2018 ICLR |
| 关键词 | 交通预测,扩散卷积,递归神经网络,时空依赖,图神经网络 |
摘要
时空预测在神经科学、气候和交通领域有着广泛的应用。交通预测是此类学习任务的一个典型例子。
该任务的挑战在于:(1) 路网中复杂的空间依赖,(2) 道路状况变化带来的非线性时间动态,以及 (3) 长期预测的内在困难。
为了解决这些挑战,我们提出将交通流建模为有向图上的扩散过程,并引入扩散卷积递归神经网络 (DCRNN),这是一种用于交通预测的深度学习框架,结合了交通流中的空间和时间依赖性。具体来说,DCRNN 通过图上的双向随机游走捕捉空间依赖,并使用带有调度采样的编码器-解码器架构来捕捉时间依赖性。
我们在两个真实世界的大规模路网交通数据集上评估了该框架,并观察到其相较于最新基准模型有 12% - 15% 的一致性提升。
DCRNN
1 引言
时空预测对于在动态环境中运行的学习系统至关重要。它在自动驾驶车辆操作、能源和智能电网优化、物流和供应链管理等领域有着广泛的应用。在本文中,我们研究了一个重要任务:基于路网的交通预测,这是智能交通系统的核心组成部分。交通预测的目标是根据传感器网络的历史交通速度和基础路网,预测未来的交通速度。
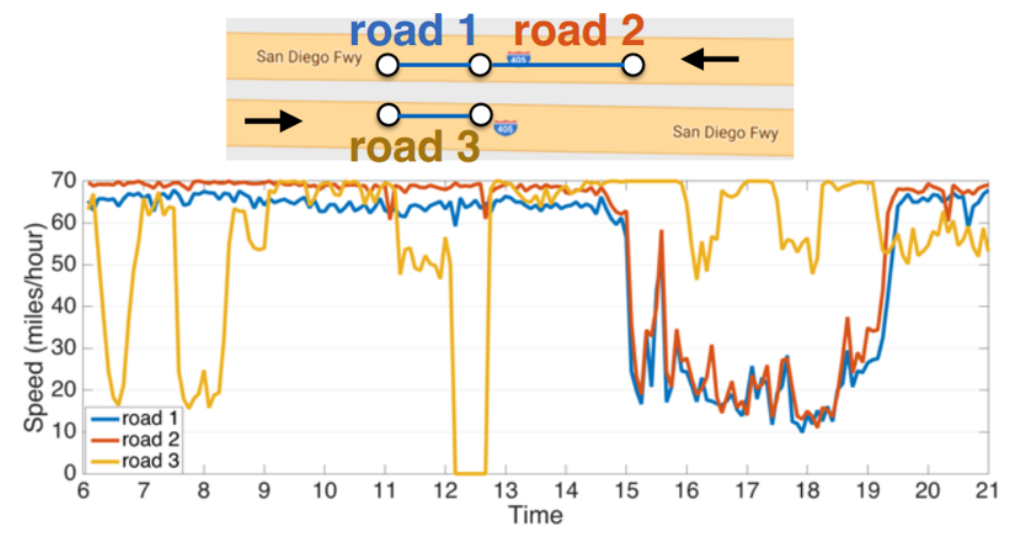
该任务的主要挑战在于复杂的时空依赖关系以及长期预测的内在困难。一方面,交通时间序列表现出强烈的时间动态。反复出现的事件如高峰时段或事故会导致非平稳性,从而使长期预测变得困难。另一方面,路网中的传感器包含复杂而独特的空间关联。图1举例说明了这一点。道路1和道路2是相关的,而道路1和道路3则不相关。虽然道路1和道路3在欧几里得空间中距离较近,但它们表现出的行为却截然不同。此外,未来的交通速度更多地受到下游交通的影响,而非上游交通。这意味着交通中的空间结构是非欧几里得且有方向性的。
图1:空间相关性主要由路网结构主导。(1) 道路1的交通速度与道路2相似,因为它们位于同一条高速公路。(2) 道路1和道路3位于高速公路的相反方向。尽管在欧几里得空间中彼此接近,但它们的路网距离很大,交通速度差异显著。
交通预测已经被研究了几十年,主要分为两大类:基于知识的方法和基于数据的方法。在交通运输和运筹学中,基于知识的方法通常应用排队论并模拟用户的交通行为。在时间序列领域,基于数据的方法如自回归积分滑动平均模型(ARIMA)和卡尔曼滤波仍然很流行。然而,简单的时间序列模型通常依赖于平稳性假设,而交通数据往往违背这一假设。近年来,交通预测的深度学习模型不断发展,但没有考虑空间结构。
在这项工作中,我们表示了使用有向图的交通传感器之间的配对空间相关性,图中的节点是传感器,边的权重表示由路网距离测量的传感器对之间的接近度。我们将交通流的动态建模为扩散过程,并提出了扩散卷积操作来捕捉空间依赖性。我们进一步提出了扩散卷积递归神经网络(DCRNN),它整合了扩散卷积、序列到序列架构和调度采样技术。在对真实世界的大规模交通数据集进行评估时,DCRNN始终在交通预测的基准测试中大幅优于最新的基准方法。总结如下:
-
我们研究了交通预测问题,并将交通的空间依赖性建模为有向图上的扩散过程。我们提出了扩散卷积,它具有直观的解释性,且能够高效计算。
-
我们提出了扩散卷积递归神经网络(DCRNN),这是一种整体方法,通过使用扩散卷积和序列到序列学习框架以及调度采样,捕捉时间序列中的空间和时间依赖性。DCRNN不仅限于交通领域,还可以广泛应用于其他时空预测任务。
-
我们在两个大规模的真实世界数据集上进行了广泛的实验,提出的方法在基准测试中相比最新的基准方法获得了显著的提升。
2 方法
我们将时空交通预测的学习问题形式化,并描述如何使用扩散卷积递归神经网络来建模依赖结构。
2.1 交通预测问题
交通预测的目标是根据先前观察到的来自路网上 N N N 个相关传感器的交通流,预测未来的交通速度。我们可以将传感器网络表示为一个加权有向图 G = ( V , E , W ) G = (\mathcal{V}, \mathcal{E}, \mathbf{W}) G=(V,E,W),其中 V \mathcal{V} V 是节点的集合, ∣ V ∣ = N |\mathcal{V}| = N ∣V∣=N, E \mathcal{E} E 是边的集合, W ∈ R N × N \mathbf{W} \in \mathbb{R}^{N \times N} W∈RN×N 是加权邻接矩阵,表示节点之间的接近度(例如,基于它们的路网距离的函数)。将观察到的交通流表示为图信号 X ∈ R N × P \mathbf{X} \in \mathbb{R}^{N \times P} X∈RN×P,其中 P P P 是每个节点的特征数量(例如,速度、流量)。设 X ( t ) \mathbf{X}^{(t)} X(t) 表示在时刻 t t t 观察到的图信号,交通预测问题的目标是学习一个函数 h ( ⋅ ) h(\cdot) h(⋅),将历史图信号 T ′ T' T′ 映射到未来的 T T T 个图信号,给定一个图 G G G:
[ X ( t − T ′ + 1 ) , ⋯ , X ( t ) ; G ] → h ( ⋅ ) [ X ( t + 1 ) , ⋯ , X ( t + T ) ] [\mathbf{X}^{(t-T'+1)}, \cdots, \mathbf{X}^{(t)}; G] \xrightarrow{h(\cdot)} [\mathbf{X}^{(t+1)}, \cdots, \mathbf{X}^{(t+T)}] [X(t−T′+1),⋯,X(t);G]h(⋅)[X(t+1),⋯,X(t+T)]
2.2 空间依赖建模
我们通过将交通流与扩散过程相关联来建模空间依赖性,该过程明确捕捉了交通动态的随机性。此扩散过程由有向图 G G G 上的随机游走表征,重启概率为 α ∈ [ 0 , 1 ] \alpha \in [0, 1] α∈[0,1],状态转移矩阵为 D O − 1 W D_O^{-1} \mathbf{W} DO−1W。其中 D O = diag ( W 1 ) D_O = \text{diag}(\mathbf{W} \mathbf{1}) DO=diag(W1) 是出度对角矩阵, 1 ∈ R N \mathbf{1} \in \mathbb{R}^N 1∈RN 表示全 1 向量。经过多次迭代后,此马尔可夫过程收敛到一个稳态分布 P ∈ R N × N \mathbf{P} \in \mathbb{R}^{N \times N} P∈RN×N,其第 i i i 行 P i , : \mathbf{P}_{i,:} Pi,: 表示从节点 v i ∈ V v_i \in \mathcal{V} vi∈V 的扩散可能性,因此表示相对于节点 v i v_i vi 的接近度。以下引理提供了稳态分布的闭式解。
引理 2.1 (Teng et al., 2016)扩散过程的稳态分布可以表示为图上的无限随机游走的加权组合,其形式为:
P = ∑ k = 0 ∞ α ( 1 − α ) k ( D O − 1 W ) k \mathbf{P} = \sum_{k=0}^{\infty} \alpha(1-\alpha)^k (D_O^{-1} \mathbf{W})^k P=k=0∑∞α(1−α)k(DO−1W)k
其中 k k k 是扩散步数。在实践中,我们使用有限的 K K K 步截断的扩散过程,并为每一步分配一个可训练的权重。我们还包括反向扩散过程,这样双向扩散为模型提供了更大的灵活性来捕捉来自上下游交通的影响。
扩散卷积,得到的扩散卷积操作定义为:
X
:
,
p
⋆
G
f
θ
=
∑
k
=
0
K
−
1
(
θ
k
,
1
(
D
O
−
1
W
)
k
+
θ
k
,
2
(
D
I
−
1
W
⊤
)
k
)
X
:
,
p
\mathbf{X}_{:,p} \star_G f_\theta = \sum_{k=0}^{K-1} \left( \theta_{k,1} (D_O^{-1} \mathbf{W})^k + \theta_{k,2} (D_I^{-1} \mathbf{W}^\top)^k \right) \mathbf{X}_{:,p}
X:,p⋆Gfθ=k=0∑K−1(θk,1(DO−1W)k+θk,2(DI−1W⊤)k)X:,p
其中 θ ∈ R K × 2 \theta \in \mathbb{R}^{K \times 2} θ∈RK×2 是滤波器的参数, D O − 1 W , D I − 1 W ⊤ D_O^{-1} \mathbf{W}, D_I^{-1} \mathbf{W}^\top DO−1W,DI−1W⊤ 分别表示扩散过程和逆向扩散过程的转移矩阵。通常,计算卷积会比较昂贵。然而,如果图 G G G 是稀疏的,则方程 (2) 可以使用递归的稀疏-稠密矩阵乘法高效计算,总时间复杂度为 O ( K ∣ E ∣ ) ≪ O ( N 2 ) O(K |\mathcal{E}|) \ll O(N^2) O(K∣E∣)≪O(N2)。更多细节见附录 B。
扩散卷积层,通过方程 (2) 定义的卷积操作,我们可以构建一个扩散卷积层,该层将
P
P
P 维的特征映射到
Q
Q
Q 维的输出。将参数张量表示为
Θ
∈
R
Q
×
P
×
K
×
2
=
[
θ
]
q
,
p
\Theta \in \mathbb{R}^{Q \times P \times K \times 2} = [\theta]_{q,p}
Θ∈RQ×P×K×2=[θ]q,p,扩散卷积层定义为:
H
:
,
q
=
a
(
∑
p
=
1
P
X
:
,
p
⋆
G
f
θ
q
,
p
,
:
,
:
)
for
q
∈
{
1
,
⋯
,
Q
}
\mathbf{H}_{:,q} = a \left( \sum_{p=1}^{P} \mathbf{X}_{:,p} \star_G f_{\theta_{q,p,:,:}} \right) \quad \text{for } q \in \{1, \cdots, Q\}
H:,q=a(p=1∑PX:,p⋆Gfθq,p,:,:)for q∈{1,⋯,Q}
其中 X ∈ R N × P \mathbf{X} \in \mathbb{R}^{N \times P} X∈RN×P 是输入, H ∈ R N × Q \mathbf{H} \in \mathbb{R}^{N \times Q} H∈RN×Q 是输出, { f θ q , p , : , : } \{f_{\theta_{q,p,:,:}}\} {fθq,p,:,:} 是滤波器, a a a 是激活函数(例如,ReLU,Sigmoid)。扩散卷积层学习图结构数据的表示,我们可以使用基于随机梯度的方法对其进行训练。
与谱图卷积的关系,扩散卷积定义在有向图和无向图上。对于无向图,我们可以证明,许多现有的基于图的卷积操作(包括流行的谱图卷积,如 ChebNet)可以看作是扩散卷积的特例(经过相似变换)。设 D D D 表示度矩阵, L = D − 1 / 2 ( D − W ) D − 1 / 2 L = D^{-1/2}(D - \mathbf{W})D^{-1/2} L=D−1/2(D−W)D−1/2 表示归一化图拉普拉斯矩阵,以下命题展示了它们之间的联系。
命题 2.2. 谱图卷积定义为
X
:
,
p
⋆
G
f
θ
=
Φ
F
(
θ
)
Φ
⊤
X
:
,
p
\mathbf{X}_{:,p} \star_G f_\theta = \Phi F(\theta) \Phi^\top \mathbf{X}_{:,p}
X:,p⋆Gfθ=ΦF(θ)Φ⊤X:,p
谱图拉普拉斯矩阵的特征值分解为 L = Φ Λ Φ ⊤ L = \Phi \Lambda \Phi^\top L=ΦΛΦ⊤,并且 F ( θ ) = ∑ k = 0 K − 1 θ k Λ k F(\theta) = \sum_{k=0}^{K-1} \theta_k \Lambda^k F(θ)=∑k=0K−1θkΛk,等价于扩散卷积,通过相似变换得到,当图 G G G 是无向图时成立。
2.3 时间动态建模
我们利用循环神经网络(RNNs)来建模时间依赖性。特别地,我们使用门控循环单元(GRU)(Chung et al., 2014),这是一个简单但强大的 RNNs 变体。我们用扩散卷积替换 GRU 中的矩阵乘法,从而形成我们提出的扩散卷积门控循环单元(DCGRU)。
r ( t ) = σ ( Θ r ⋆ G [ X ( t ) , H ( t − 1 ) ] + b r ) r^{(t)} = \sigma (\Theta_r \star_G [\mathbf{X}^{(t)}, \mathbf{H}^{(t-1)}] + b_r) r(t)=σ(Θr⋆G[X(t),H(t−1)]+br)
C ( t ) = tanh ( Θ C ⋆ G [ X ( t ) , ( r ( t ) ⊙ H ( t − 1 ) ) ] + b C ) \mathbf{C}^{(t)} = \tanh (\Theta_C \star_G [\mathbf{X}^{(t)}, (r^{(t)} \odot \mathbf{H}^{(t-1)})] + b_C) C(t)=tanh(ΘC⋆G[X(t),(r(t)⊙H(t−1))]+bC)
u ( t ) = σ ( Θ u ⋆ G [ X ( t ) , H ( t − 1 ) ] + b u ) u^{(t)} = \sigma (\Theta_u \star_G [\mathbf{X}^{(t)}, \mathbf{H}^{(t-1)}] + b_u) u(t)=σ(Θu⋆G[X(t),H(t−1)]+bu)
H ( t ) = u ( t ) ⊙ H ( t − 1 ) + ( 1 − u ( t ) ) ⊙ C ( t ) \mathbf{H}^{(t)} = u^{(t)} \odot \mathbf{H}^{(t-1)} + (1 - u^{(t)}) \odot \mathbf{C}^{(t)} H(t)=u(t)⊙H(t−1)+(1−u(t))⊙C(t)
其中 X ( t ) , H ( t ) \mathbf{X}^{(t)}, \mathbf{H}^{(t)} X(t),H(t) 分别表示在时间 t t t 的输入和输出, r ( t ) , u ( t ) r^{(t)}, u^{(t)} r(t),u(t) 是时间 t t t 的重置门和更新门。 ⋆ G \star_G ⋆G 表示方程 (2) 中定义的扩散卷积, Θ r , Θ u , Θ C \Theta_r, \Theta_u, \Theta_C Θr,Θu,ΘC 是对应滤波器的参数。类似于 GRU,DCGRU 可以用于构建循环神经网络层,并通过时间反向传播训练。
在多步预测中,我们采用序列到序列架构(Sutskever et al., 2014)。编码器和解码器都是使用 DCGRU 的循环神经网络。在训练期间,我们将历史时间序列送入编码器,并使用其最终状态来初始化解码器。解码器根据之前的真实观测生成预测。在测试时,真实观测被模型自己生成的预测所替代。训练和测试输入分布之间的差异会导致性能下降。为了解决这个问题,我们在模型中引入了调度采样(Bengio et al., 2015),在第 i i i 次迭代中,我们以 ϵ i \epsilon_i ϵi 的概率输入真实观测,或以 1 − ϵ i 1 - \epsilon_i 1−ϵi 的概率输入模型的预测。在训练过程中, ϵ i \epsilon_i ϵi 逐渐减少到 0 以允许模型学习测试分布。
通过同时建模空间和时间依赖性,我们构建了一个扩散卷积递归神经网络(DCRNN)。DCRNN 的模型架构如图2所示。整个网络通过最大化生成目标未来时间序列的可能性,使用时间反向传播进行训练。DCRNN 能够捕捉时间序列中的时空依赖性,并且可以应用于各种时空预测问题。
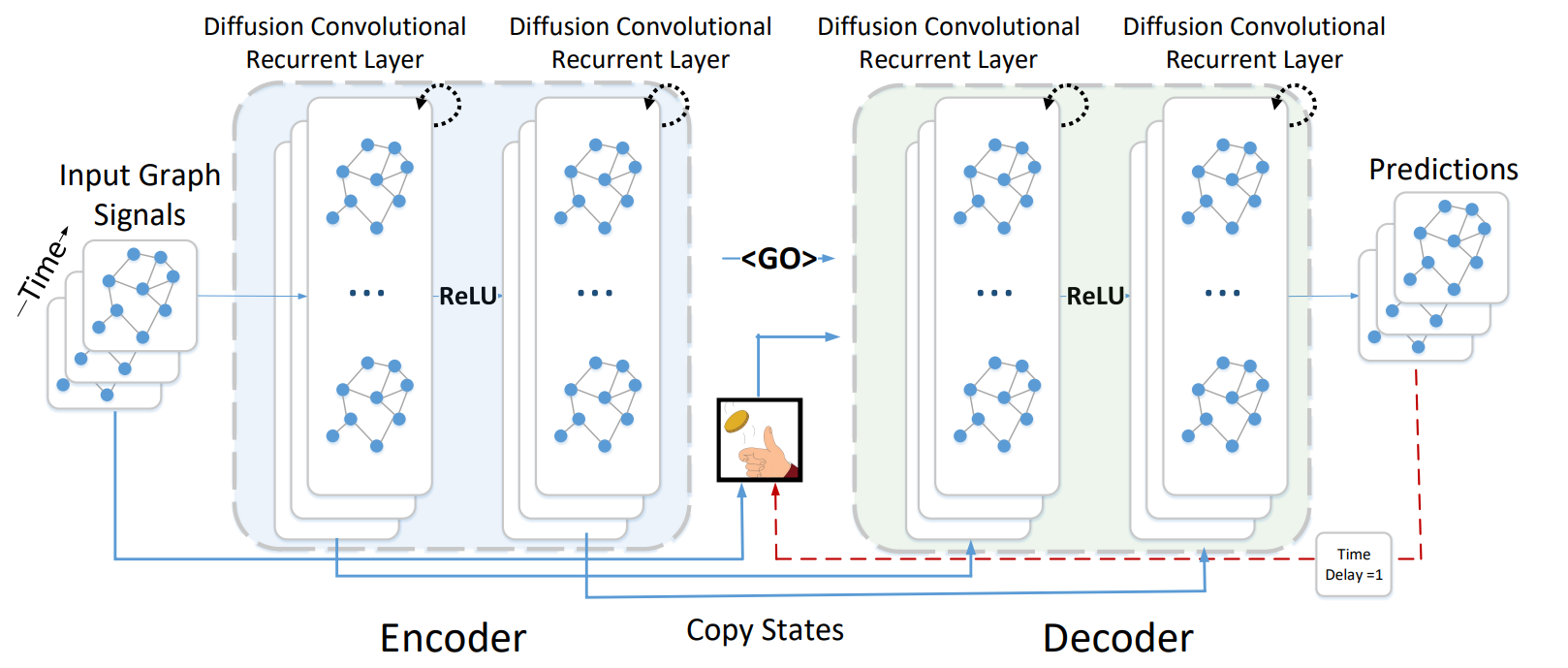
图2:扩散卷积递归神经网络的系统架构,专为时空交通预测设计。历史时间序列被输入到编码器中,其最终状态用于初始化解码器。解码器基于之前的真实值或模型输出进行预测。
3 相关工作
交通预测是交通运输和运筹研究中的经典问题,主要基于排队论和仿真。数据驱动的交通预测方法已经受到广泛关注,更多详细信息可以参考最近的综述文章。然而,现有的机器学习模型要么对数据施加了强烈的平稳性假设(例如,自回归模型),要么无法解释高度非线性的时间依赖性。深度学习模型为时间序列预测问题带来了新的希望。例如,Yu等人和Laptev等人使用深度递归神经网络(RNN)研究了时间序列预测。卷积神经网络(CNN)也被应用于交通预测。Zhang等人将路网转换为常规的二维网格,并应用传统的CNN来预测人群流量。Cheng等人提出了DeepTransport,通过显式收集上下游邻近道路来建模空间依赖,并在这些邻近道路上进行卷积。
最近,CNN被推广到基于谱图理论的任意图上。Bruna等人首次提出了图卷积神经网络(GCN),该网络结合了谱图理论和深度神经网络。Defferrard等人提出了ChebNet,通过快速局部卷积滤波器改进了GCN。Kipf和Welling简化了ChebNet,并在半监督分类任务中取得了最先进的性能。Seo等人将ChebNet与RNN结合,用于结构化序列建模。Yu等人将传感器网络建模为无向图,并应用ChebNet和卷积序列模型进行预测。上述谱卷积方法的一个限制是,它们通常要求图是无向图,以便进行有意义的谱分解。
从谱域转向顶点域,Atwood和Towsley提出了扩散卷积神经网络(DCNN),该网络将卷积定义为图结构输入中每个节点上的扩散过程。Hechtlinger等人提出了GraphCNN,通过对每个节点与其 p p p 个最近邻居进行卷积,将卷积推广到图。然而,这两种方法都没有考虑时间动态,主要处理静态图设置。
我们的方法与上述方法不同,既在问题设置上不同,也在图上的卷积公式上不同。我们将传感器网络建模为加权有向图,这比网格或无向图更现实。此外,提出的卷积是使用双向图随机游走定义的,并进一步与序列到序列学习框架集成,以及调度采样以建模长期时间依赖性。
4 实验
我们在两个真实世界的大规模数据集上进行了实验:
(1)METR-LA:该交通数据集包含从洛杉矶县高速公路的回路检测器中收集的交通信息。我们选择了207个传感器,并收集了从2012年3月1日至2012年6月30日的4个月数据进行实验。
(2)PEMS-BAY:该交通数据集由加利福尼亚州交通局(CalTrans)性能测量系统(PeMS)收集。我们选择了325个传感器,并收集了从2017年1月1日至2017年5月31日的6个月数据进行实验。两个数据集的传感器分布如下:
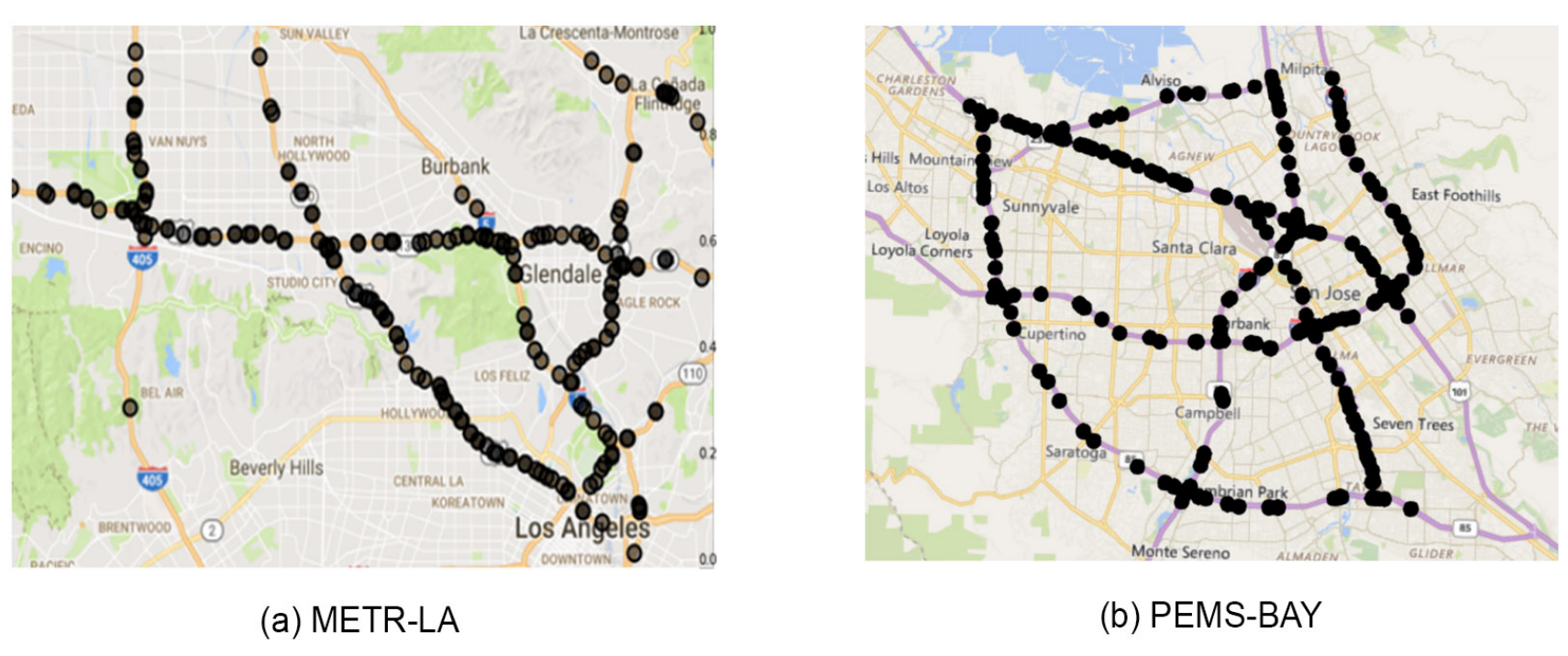
在这两个数据集中,我们将交通速度读取汇总为5分钟的窗口,并应用Z-Score归一化。70%的数据用于训练,20%用于测试,剩余的10%用于验证。为了构建传感器图,我们计算了传感器之间的成对路网距离,并使用加权高斯核构建邻接矩阵。
W i j = exp ( − dist ( v i , v j ) 2 σ 2 ) W_{ij} = \exp\left(-\frac{\text{dist}(v_i, v_j)^2}{\sigma^2}\right) Wij=exp(−σ2dist(vi,vj)2)
当 dist ( v i , v j ) ≤ κ \text{dist}(v_i, v_j) \leq \kappa dist(vi,vj)≤κ 时, W i j W_{ij} Wij 表示传感器 v i v_i vi 和传感器 v j v_j vj 之间的边权重, dist ( v i , v j ) \text{dist}(v_i, v_j) dist(vi,vj) 表示传感器 v i v_i vi 到传感器 v j v_j vj 的路网距离, σ \sigma σ 是距离的标准差, κ \kappa κ 是阈值。
4.1 实验设置
我们将DCRNN与广泛使用的时间序列回归模型进行了比较,包括:
- HA:历史平均值,模型将交通流作为季节性过程,使用加权平均作为预测值。
- ARIMA kal _{\text{kal}} kal:自回归积分滑动平均模型与卡尔曼滤波,广泛应用于时间序列预测。
- VAR:向量自回归,使用线性支持向量机进行回归任务。
- SVR:支持向量回归,使用线性支持向量机进行回归任务。
- 前馈神经网络(FNN):前馈神经网络,具有两个隐藏层和L2正则化。
- 循环神经网络(RNN):全连接的LSTM隐藏单元。
所有基于神经网络的方法均使用Tensorflow实现,并使用Adam优化器进行训练。
4.2 交通预测性能比较
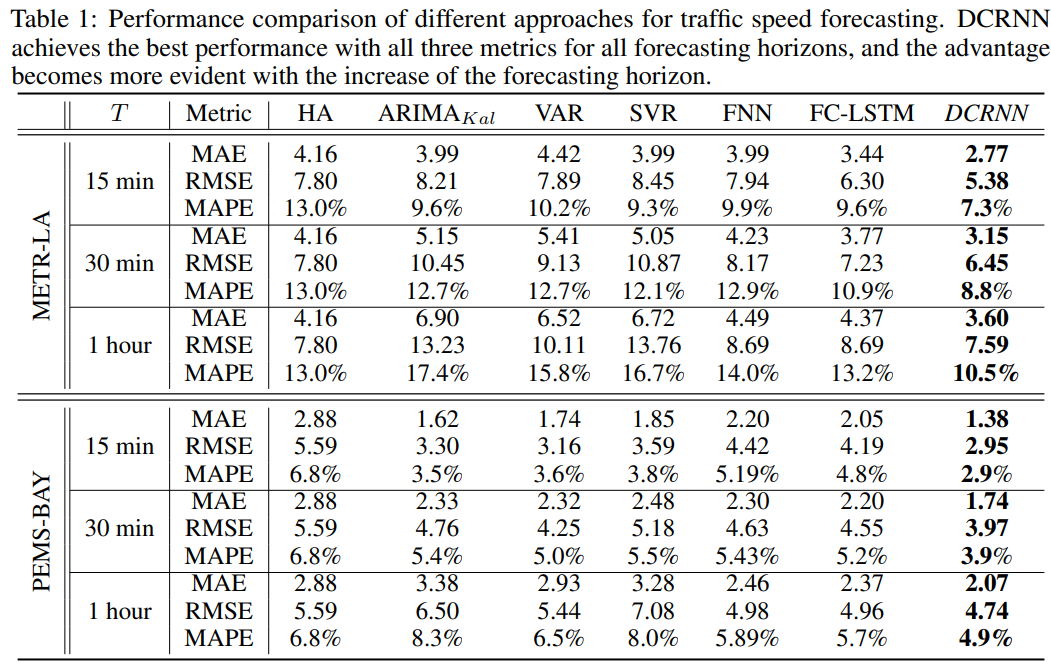
表1展示了在两个数据集上15分钟、30分钟和1小时预测的不同方法的比较。基于交通预测中常用的三种指标对这些方法进行评估,包括:
(1) 平均绝对误差(MAE)
(2) 平均绝对百分比误差(MAPE)
(3) 均方根误差(RMSE)。
计算中排除了缺失值。这些指标的详细公式在附录E.2中提供。
我们观察到以下现象:
(1) 基于RNN的方法,包括FC-LSTM和DCRNN,通常优于其他基准,这强调了建模时间依赖性的重要性。
(2) DCRNN在所有预测时间范围内的所有指标上都取得了最佳性能,这表明了时空依赖性建模的有效性。
(3) 深度神经网络方法,包括FNN、FC-LSTM和DCRNN,在长期预测(如1小时)的性能优于线性基准模型。
这是因为随着预测范围的增加,时间依赖性变得越来越非线性。此外,由于历史平均法不依赖于短期数据,因此其性能不受预测范围小幅增加的影响。
请注意,METR-LA数据集(洛杉矶,以复杂的交通状况著称)的交通预测比PEMS-BAY(湾区)数据集更具挑战性。因此,我们将METR-LA作为后续实验的默认数据集。
4.3 空间依赖建模的效果
为了进一步研究空间依赖建模的效果,我们将DCRNN与以下变体进行比较:
(1) DCRNN-NoConv,忽略空间依赖性,通过用单位矩阵替换扩散卷积中的转移矩阵(方程2),这实质上意味着传感器的预测只能从其自身的历史读数中推断。
(2) DCRNN-UniConv,只使用正向随机游走转移矩阵进行扩散卷积;图3展示了这三种模型具有相似参数数量的学习曲线。
没有扩散卷积,DCRNN-NoConv的验证误差显著较高。此外,DCRNN实现了最低的验证误差,这表明了使用双向随机游走的有效性。直觉是,双向随机游走赋予模型捕捉上下游交通影响的能力和灵活性。
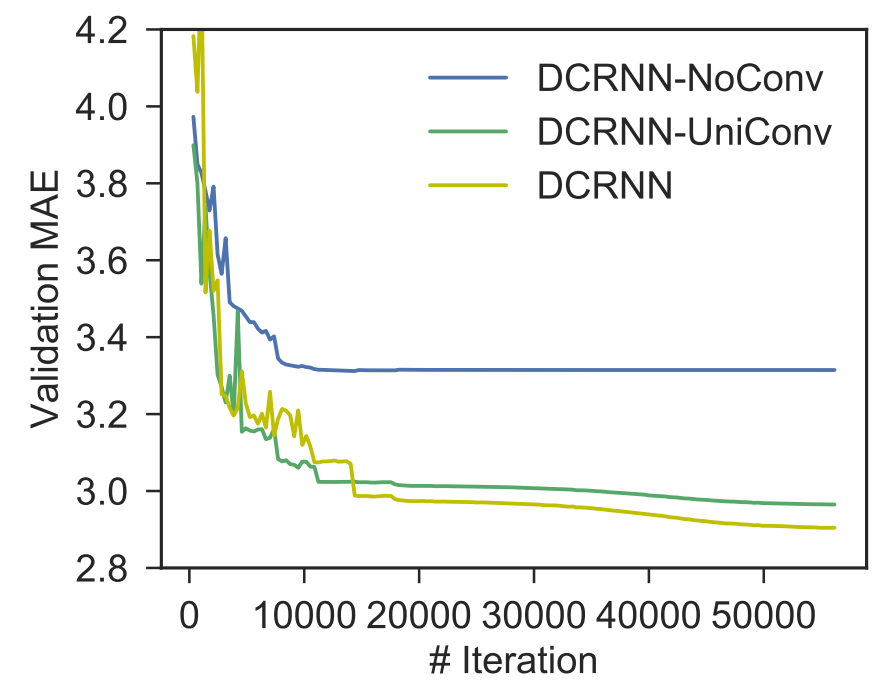
图2:扩散卷积递归神经网络的系统架构,专为时空交通预测设计。历史时间序列被输入到编码器中,其最终状态用于初始化解码器。解码器基于之前的真实值或模型输出进行预测。
为了研究图构建的影响,我们通过设置
W
^
i
j
=
max
(
W
i
j
,
W
j
i
)
\hat{W}_{ij} = \max(W_{ij}, W_{ji})
W^ij=max(Wij,Wji) 来构建无向图,其中
W
^
\hat{W}
W^ 是新的对称权重矩阵。然后我们开发了DCRNN的一个变体,称为GCRNN,它使用ChebNet图卷积(方程5)并具有大致相同数量的参数。表2展示了METR-LA数据集中DCRNN和GCRNN的比较。DCRNN始终优于GCRNN。直觉是,有向图更好地捕捉了传感器之间的非对称相关性。

图4展示了不同参数的影响。 K K K 大致对应于滤波器接收场的大小,而单元数对应于滤波器的数量。较大的 K K K 使模型能够以增加学习复杂性为代价捕捉更广泛的空间依赖性。我们观察到,随着 K K K 的增加,验证数据集上的误差先快速下降,然后略有增加。对单元数变化的类似行为也被观察到。
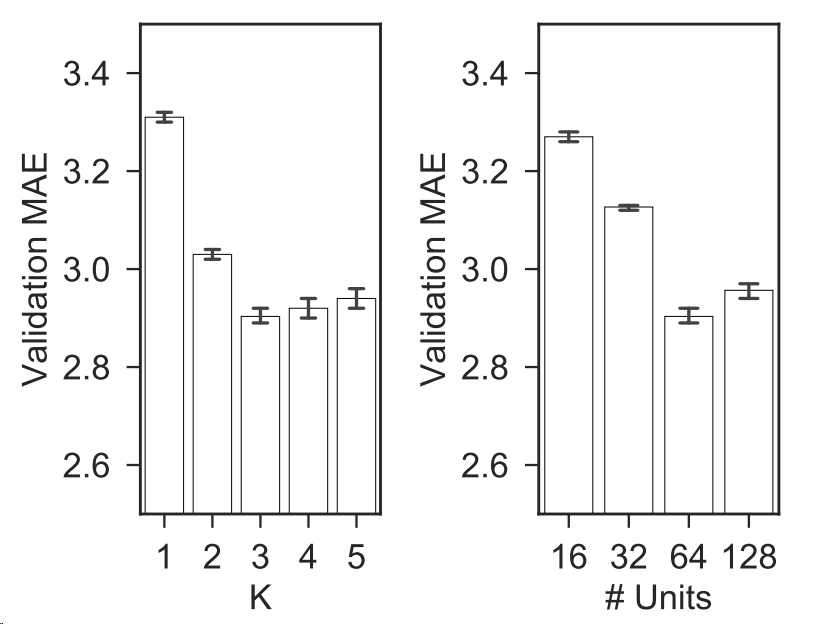
图4: K K K 和 DCRNN每层中的单元数量的影响。 K K K 对应于滤波器的接收场宽度,单元数量对应于滤波器的数量。
4.4 时间依赖建模的效果
为了评估时间建模(包括序列到序列框架以及调度采样机制)的效果,我们进一步设计了DCRNN的三个变体:
(1) DCNN:将历史观测值串联为一个固定长度向量并将其输入到堆叠的扩散卷积层中,以预测未来时间序列。我们训练了一个单步预测模型,并将上一步的预测结果作为输入提供给模型,以进行多步预测。
(2) DCRNN-SEQ:使用编码器-解码器序列到序列学习框架进行多步预测。
(3) DCRNN:类似于DCRNN-SEQ,但增加了调度采样。
图5展示了这些方法在不同预测范围下的MAE比较。我们观察到:
(1) DCRNN-SEQ在很大程度上优于DCNN,符合建模时间依赖性的重要性。
(2) DCRNN取得了最佳结果,并且随着预测范围的增加,其优势变得更加明显。
这主要是因为模型经过训练,可以在多步预测过程中处理自己的错误,因此较少受到错误传播问题的影响。我们还训练了一个始终将输出作为输入进行多步预测的模型。然而,其性能远远低于其他三种强调调度采样重要性的变体。
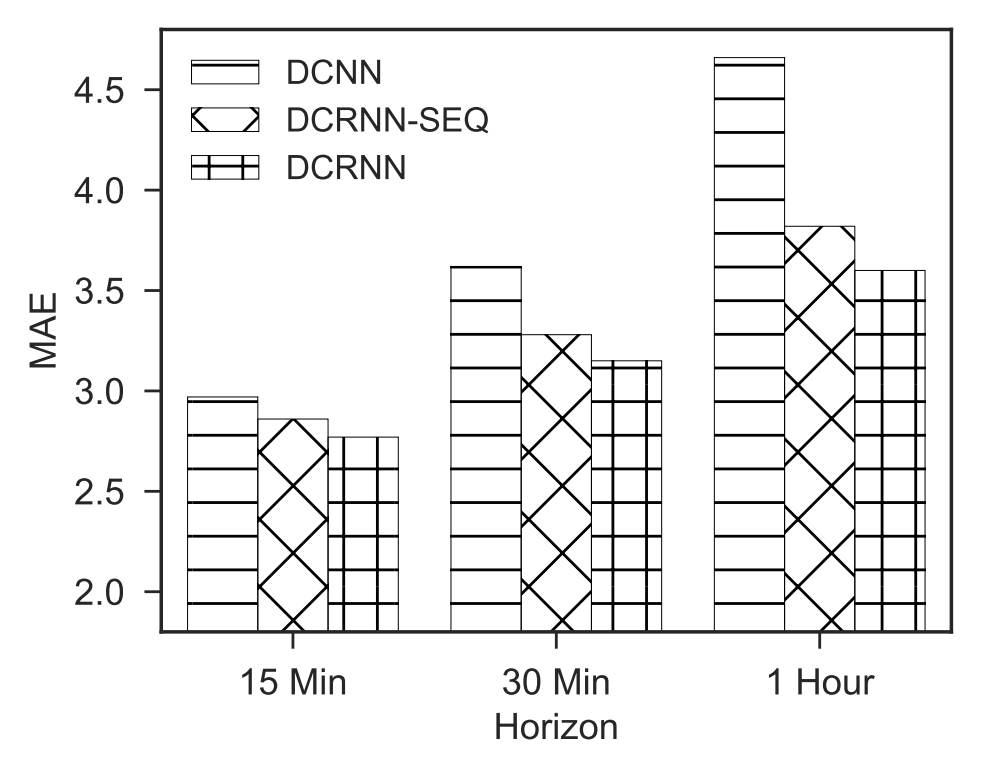
图5:不同DCRNN变体的性能比较。DCRNN结合序列到序列框架和调度采样,在验证数据集上取得了最低的MAE。随着预测范围的增加,这一优势变得更加明显。
4.5 模型解释
为了更好地理解模型,我们可视化了预测结果以及学习到的滤波器。图6展示了1小时预测的可视化结果。我们有以下观察:
(1) DCRNN在交通速度中存在小幅波动时生成了平滑的均值预测(图6(a))。这反映了模型的稳健性。
(2) 与基线方法(例如FC-LSTM)相比,DCRNN更可能准确预测交通速度的突然变化。如图6(b)所示,DCRNN预测了高峰时段的开始和结束。这是因为DCRNN捕捉了空间依赖性,能够利用邻近传感器中的速度变化来进行更准确的预测。
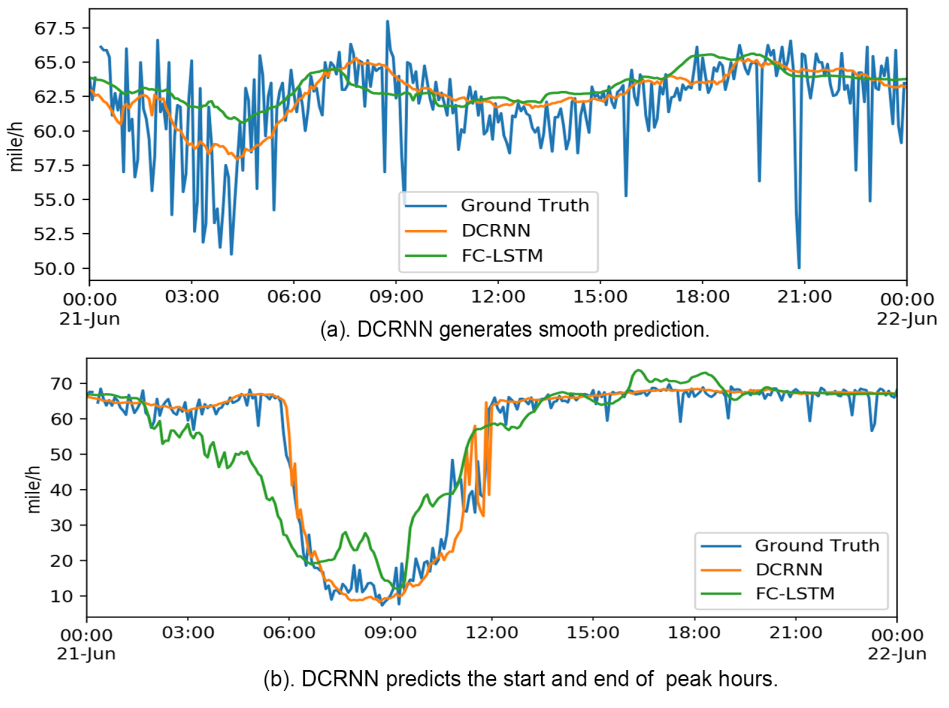
图6:交通时间序列预测可视化。DCRNN生成平滑的预测,通常在预测高峰时段的开始和结束方面表现更好。
图7展示了以不同节点为中心的学习到的滤波器示例。星号表示中心,颜色表示权重。我们可以观察到:(1) 权重在中心附近良好地局部化,并且(2) 权重根据路网距离扩散。

图7:在METR-LA数据集上, K = 3 K=3 K=3 时学习到的局部滤波器的可视化。星号表示中心,颜色代表权重。我们观察到权重集中在中心附近,并沿着路网扩散。
5 结论
在本文中,我们将基于路网的交通预测形式化为一个时空预测问题,并提出了捕捉时空依赖性的扩散卷积递归神经网络。具体来说,我们使用双向图随机游走来建模空间依赖性,并使用循环神经网络来捕捉时间动态。我们进一步集成了编码器-解码器架构和调度采样技术,以提高长期预测的性能。在两个大规模真实世界的交通数据集上进行评估时,我们的方法相比基准模型取得了显著更好的预测效果。对于未来的工作,我们将研究以下两个方面:(1) 将提出的模型应用于其他时空预测任务;(2) 当底层图结构发生变化时(例如,移动对象的 K K K 最近邻图),建模时空依赖性。