DataStream API编程模型
1.【Flink-Scala】DataStream编程模型之数据源、数据转换、数据输出
2.【Flink-scala】DataStream编程模型之 窗口的划分-时间概念-窗口计算程序
前言
本小节我想把 窗口计算中 的触发器和驱逐器讲完
然后开始水位线,延迟数据处理,状态编程等。
1.触发器
触发器决定了窗口何时由窗口计算函数进行处理。
(触发器就类比枪的扳机,触发后 计算函数开始计算,计算函数在【Flink-scala】DataStream编程模型之 窗口的划分-时间概念-窗口计算程序)
每个窗口分配器都带有一个默认触发器。如果默认触发器不能满足业务需求,就需要自定义触发器。
实现自定义触发器的方法很简单,只需要继承Trigger接口并实现它的方法即可。
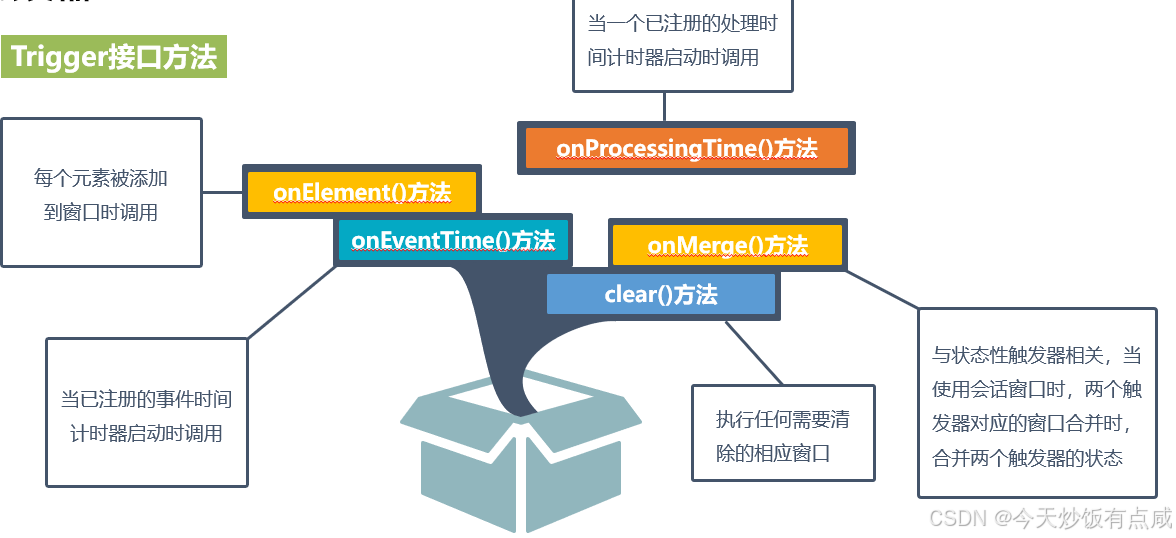
Trigger接口有五种方法,允许触发器对不同的事件作出反应,
具体如下:
- onElement()方法:每个元素被添加到窗口时调用;
- onEventTime()方法:当一个已注册的事件时间计时器启动时调用;
- onProcessingTime()方法:当一个已注册的处理时间计时器启动时调用;
- onMerge()方法:与状态性触发器相关,当使用会话窗口时,两个触发器对应的窗口合并时,合并两个触发器的状态;
- clear()方法:执行任何需要清除的相应窗口。
触发器通过 TriggerContext 来管理和检查状态。
在触发器中,我们通常会使用 状态 来记录窗口中的一些信息,如已处理的事件数量或累计的值。这些状态决定了窗口是否应当触发计算。
触发器中的 TriggerResult 有几个重要的结果:
CONTINUE:表示窗口继续等待更多的事件,不触发计算。
FIRE:表示触发窗口计算并输出结果。
PURGE:表示删除某些数据,通常在某些特殊场景下使用。
1.1 代码示例
假设股票价格数据流连续不断到达系统,现在需要对到达的数据进行监控,每到达5条数据就触发计算。实现该功能的代码如下:
import java.util.Calendar
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.state.ReducingStateDescriptor
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.source.RichSourceFunction
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.triggers.{Trigger, TriggerResult}
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import scala.util.Random
case class StockPrice(stockId:String,timeStamp:Long,price:Double)
object TriggerTest {
def main(args: Array[String]) {
//创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置程序并行度
env.setParallelism(1)
//设置为处理时间
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
//创建数据源,股票价格数据流
val source = env.socketTextStream("localhost", 9999)
//指定针对数据流的转换操作逻辑
val stockPriceStream = source
.map(s => s.split(","))
.map(s=>StockPrice(s(0).toString,s(1).toLong,s(2).toDouble))
val sumStream = stockPriceStream
.keyBy(s => s.stockId)
.timeWindow(Time.seconds(50))
.trigger(new MyTrigger(5))
.reduce((s1, s2) => StockPrice(s1.stockId,s1.timeStamp, s1.price + s2.price))
//打印输出
sumStream.print()
//程序触发执行
env.execute("Trigger Test")
}
class MyTrigger extends Trigger[StockPrice, TimeWindow] {
//触发计算的最大数量
private var maxCount: Long = _
//记录当前数量的状态
private lazy val countStateDescriptor: ReducingStateDescriptor[Long] = new ReducingStateDescriptor[Long]("counter", new Sum, classOf[Long])
def this(maxCount: Int) {
this()
this.maxCount = maxCount
}
override def onProcessingTime(time: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = {
TriggerResult.CONTINUE
}
override def onEventTime(time: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = {
TriggerResult.CONTINUE
}
override def onElement(element: StockPrice, timestamp: Long, window: TimeWindow, ctx: Trigger.TriggerContext): TriggerResult = {
val countState = ctx.getPartitionedState(countStateDescriptor)
//计数状态加1
countState.add(1L)
if (countState.get() >= this.maxCount) {
//达到指定指定数量
//清空计数状态
countState.clear()
//触发计算
TriggerResult.FIRE
} else {
TriggerResult.CONTINUE
}
}
//窗口结束时清空状态
override def clear(window: TimeWindow, ctx: Trigger.TriggerContext): Unit = {
println("窗口结束时清空状态")
ctx.getPartitionedState(countStateDescriptor).clear()
}
//更新状态为累加值
class Sum extends ReduceFunction[Long] {
override def reduce(value1: Long, value2: Long): Long = value1 + value2
}
}
}
注意 这一行代码:
val sumStream = stockPriceStream
.keyBy(s => s.stockId)
.timeWindow(Time.seconds(50))
.trigger(new MyTrigger(5))
.reduce((s1, s2) => StockPrice(s1.stockId,s1.timeStamp, s1.price + s2.price))
在该代码中,MyTrigger 是一个自定义触发器,它控制在窗口中积累一定数量的事件后触发计算。
具体来说,窗口中的数据会根据 StockPrice 的数量来决定是否触发计算,而不是依赖于时间 。
接下来分析代码,
def this(maxCount: Int) {
this()
this.maxCount = maxCount
}
这是它的主构造函数,它接受一个 maxCount 参数,表示在触发器中窗口内允许的最大元素数量。也就是说,窗口中的元素数达到 maxCount 时,触发器会触发计算(即调用 TriggerResult.FIRE)。
.trigger(new MyTrigger(5))表示创建一个 MyTrigger 的实例,并传入一个 maxCount 为 5 的参数,意思是窗口中最大允许 5 个元素,达到该数量后,窗口会触发计算。
private lazy val countStateDescriptor: ReducingStateDescriptor[Long] = new ReducingStateDescriptor[Long]("counter", new Sum, classOf[Long])
lazy:表示这是一个延迟初始化的变量。只有在第一次使用 countStateDescriptor 时,才会初始化它。这在性能优化上有作用,避免了不必要的初始化开销。
ReducingStateDescriptor 是 Flink 提供的一个状态描述符,它用于定义一个可减少的状态。这个状态会随着事件的到来不断累积,并且可以执行自定义的聚合操作。在 ReducingStateDescriptor 中,状态值的更新是通过 ReduceFunction 来实现的。
在这里,ReducingStateDescriptor[Long] 定义了一个状态,它的值是 Long 类型,并且该状态将执行 聚合操作(即对 Long 类型的值进行合并)。
ReducingStateDescriptor 的构造函数接受三个参数:
1.状态名称:“counter”
这是该状态的名称,用于在 Flink 的状态后端存储中标识该状态。
2.聚合操作:new Sum
这是一个 ReduceFunction 的实例,它定义了如何合并状态。在这个例子中,Sum 类是一个自定义的 ReduceFunction,用于对 Long 类型的值进行加法操作。
3.状态类型:classOf[Long]
这是状态的类型。classOf[Long] 表示状态值的类型是 Long,用于在 Flink 的状态管理中描述状态类型。
ClassOf(Long)这是 Scala 反射机制的语法,用于获取 Long 类型的 Class 对象。它在这里用于指定状态值的类型,以便 Flink 的状态管理能够正确地处理状态。
接下来的几个方法**TriggerResult.CONTINUE* 表示继续,不触发计算。
接下来是onElement方法
val countState = ctx.getPartitionedState(countStateDescriptor)
然后计数器+1,加到5就触发。
看是否到达maxcount。到达就触发,不到达就不触发,
自己的疑惑:才开始看代码的时候我一直纠结ctx( ctx.getPartitionedState(countStateDescriptor))这是从哪里来的,这个是
org.apache.flink.streaming.api.windowing.triggers.Trigger
下面的实例化对象,直接使用即可。
代码最后:
Sum类:它的作用是在状态更新时执行对状态的累加操作。
为什么用 Sum 作为累加器?
由于我们在 Trigger 中的 onElement 方法使用了 ctx.getPartitionedState(countStateDescriptor) 来获取一个 ReducingState(累加状态),这个状态将会不断地被更新,每次一个新元素进入时,都会触发 reduce 操作。
Sum 类就是定义了如何对这个 ReducingState 状态进行累加操作。
ReduceFunction 提供了累加器的逻辑,这样当多个元素进来时,value1 和 value2 就会被相加,最终在窗口中保持一个累积的状态。
2.驱逐器
学完上面的,学个单词:Evictor
驱逐器是Flink窗口机制的一个可选择组件。

驱逐 汉语意思就是 赶走,作用就是对进入窗口前后的数据进行驱逐(就是不接收,不要,你走 )
Flink内部实现了三种驱逐器,包括CountEvictor、DeltaEvictor和TimeEvictor。
三种驱逐器的功能如下:
CountEvictor:保持在窗口中具有固定数量的记录,将超过指定大小的数据在窗口计算之前删除;
DeltaEvictor:使用DeltaFunction和一个阈值,来计算窗口缓冲区中的最后一个元素与其余每个元素之间的差值,并删除差值大于或等于阈值的元素;
TimeEvictor:以毫秒为单位的时间间隔(interval)作为参数,对于给定的窗口,找到元素中的最大的时间戳max_ts,并删除时间戳小于max_ts - interval的所有元素。
在使用窗口函数之前被逐出的元素将不被处理。
默认情况下,所有内置的驱逐器在窗口函数之前使用。
和触发器一样,用户也可以通过实现Evictor接口完成自定义的驱逐器。
自定义驱逐器时,需要复写Evictor接口的两个方法:
evictBefore()和evictAfter()。
其中,evictBefore()方法定义数据在进入窗口函数计算之前执行驱逐操作的逻辑,
evictAfter()方法定义数据在进入窗口函数计算之后执行驱逐操作的逻辑。
2.1 代码示例
这个代码在做的事:统计窗口内股票价的平均值,并删除小于0的记录
import java.time.Duration
import java.util
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.evictors.Evictor
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.runtime.operators.windowing.TimestampedValue
import org.apache.flink.util.Collector
case class StockPrice(stockId:String,timeStamp:Long,price:Double)
object EvictorTest {
def main(args: Array[String]) {
//设置执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置程序并行度
env.setParallelism(1)
//设置为处理时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//创建数据源,股票价格数据流
val source = env.socketTextStream("localhost", 9999)
//指定针对数据流的转换操作逻辑
val stockPriceStream = source
.map(s => s.split(","))
.map(s=>StockPrice(s(0).toString,s(1).toLong,s(2).toDouble))
val sumStream = stockPriceStream
.assignTimestampsAndWatermarks(
WatermarkStrategy
//为了测试方便,这里把水位线设置为0
.forBoundedOutOfOrderness[StockPrice](Duration.ofSeconds(0))
.withTimestampAssigner(new SerializableTimestampAssigner[StockPrice] {
override def extractTimestamp(element: StockPrice, recordTimestamp: Long): Long = element.timeStamp
}
)
)
.keyBy(s => s.stockId)
.timeWindow(Time.seconds(3))
.evictor(new MyEvictor()) //自定义驱逐器
.process(new MyProcessWindowFunction()) //自定义窗口计算函数
//打印输出
sumStream.print()
//程序触发执行
env.execute("Evictor Test")
}
class MyEvictor() extends Evictor[StockPrice, TimeWindow] {
override def evictBefore(iterable: java.lang.Iterable[TimestampedValue[StockPrice]], i: Int, w: TimeWindow, evictorContext: Evictor.EvictorContext): Unit = {
val ite: util.Iterator[TimestampedValue[StockPrice]] = iterable.iterator()
while (ite.hasNext) {
val elment: TimestampedValue[StockPrice] = ite.next()
println("驱逐器获取到的股票价格:" + elment.getValue().price)
//模拟去掉非法参数数据
if (elment.getValue().price <= 0) {
println("股票价格小于0,删除该记录")
ite.remove()
}
}
}
override def evictAfter(iterable: java.lang.Iterable[TimestampedValue[StockPrice]], i: Int, w: TimeWindow, evictorContext: Evictor.EvictorContext): Unit = {
//不做任何操作
}
}
class MyProcessWindowFunction extends ProcessWindowFunction[StockPrice, (String, Double), String, TimeWindow] {
// 一个窗口结束的时候调用一次(一个分组执行一次),不适合大量数据,全量数据保存在内存中,会造成内存溢出
override def process(key: String, context: Context, elements: Iterable[StockPrice], out: Collector[(String, Double)]): Unit = {
// 聚合,注意:整个窗口的数据保存到Iterable,里面有很多行数据
var sumPrice = 0.0;
elements.foreach(stock => {
sumPrice = sumPrice + stock.price
})
out.collect(key, sumPrice/elements.size)
}
}
}
myEvictor 是我们自定义的驱逐器类,它实现了 Evictor[StockPrice, TimeWindow] 接口.
在Evictor类中定义了before和after两个方法。
这着重看before,after没做什么。
override def evictBefore(
iterable: java.lang.Iterable[TimestampedValue[StockPrice]],
i: Int,
w: TimeWindow,
evictorContext: Evictor.EvictorContext
): Unit = {
val ite: util.Iterator[TimestampedValue[StockPrice]] = iterable.iterator()
while (ite.hasNext) {
val elment: TimestampedValue[StockPrice] = ite.next()
println("驱逐器获取到的股票价格:" + elment.getValue().price)
if (elment.getValue().price <= 0) {
println("股票价格小于0,删除该记录")
ite.remove()
}
}
参数的迭代器里,每个元素都是TimestampedValue[StockPrice]。
i表示要处理的数据量。
evictorContext:这是 Evictor.EvictorContext 类型,它提供了访问驱逐器上下文的接口。在此方法中并未使用,通常它可以用于管理驱逐操作的状态或者提供更多的上下文信息。
while里面的代码就不解释啦。
这里的参数太长,且陌生,多解释一下。
在窗口中运行输入
stock_1,1602031567000,8
stock_1,1602031568000,-4
stock_1,1602031569000,3
stock_1,1602031570000,-8
stock_1,1602031571000,9
stock_1,1602031572000,10
输出后的结果是:
驱逐器获取到的股票价格:8.0
驱逐器获取到的股票价格:-4.0
股票价格小于0,删除该记录
(stock_1,8.0)
驱逐器获取到的股票价格:3.0
驱逐器获取到的股票价格:-8.0
股票价格小于0,删除该记录
驱逐器获取到的股票价格:9.0
(stock_1,6.0)
驱逐器获取到的股票价格:10.0
(stock_1,10.0)
驱逐器会在每个窗口开始时检查所有输入的事件,并对那些满足特定条件的事件(在本例中,股票价格 <= 0)进行处理并移除。
stock_1, 1602031567000, 8 — 股票价格大于0,保留。
stock_1, 1602031568000, -4 — 股票价格小于0,驱逐。
stock_1, 1602031569000, 3 — 股票价格大于0,保留。
stock_1, 1602031570000, -8 — 股票价格小于0,驱逐。
stock_1, 1602031571000, 9 — 股票价格大于0,保留。
stock_1, 1602031572000, 10 — 股票价格大于0,保留。
驱逐器输出的处理结果:
窗口 1(时间区间:1602031567000 - 1602031570000,窗口大小 3秒):
该窗口内剩下的有效记录:stock_1, 1602031567000, 8 和 stock_1, 1602031569000, 3(-4 和 -8 被驱逐)。
计算平均价格:(8 + 3) / 2 = 5.5
输出: (stock_1, 8.0)(按窗口内第一个事件的 stockId 输出)
窗口 2(时间区间:1602031569000 - 1602031572000,窗口大小 3秒):
该窗口内剩下的有效记录:stock_1, 1602031569000, 3 和 stock_1, 1602031571000, 9(-8 被驱逐)。
计算平均价格:(3 + 9) / 2 = 6.0
输出: (stock_1, 6.0)(按窗口内第一个事件的 stockId 输出)
窗口 3(时间区间:1602031571000 - 1602031574000,窗口大小 3秒):
该窗口内剩下的有效记录:stock_1, 1602031571000, 9 和 stock_1, 1602031572000, 10。
计算平均价格:(9 + 10) / 2 = 9.5
输出: (stock_1, 10.0)(按窗口内第一个事件的 stockId 输出)
输出后的结果是:
驱逐器获取到的股票价格:8.0
驱逐器获取到的股票价格:-4.0
股票价格小于0,删除该记录
(stock_1,8.0)
驱逐器获取到的股票价格:3.0
驱逐器获取到的股票价格:-8.0
股票价格小于0,删除该记录
驱逐器获取到的股票价格:9.0
(stock_1,6.0)
驱逐器获取到的股票价格:10.0
(stock_1,10.0)
总结
以上就是今天要讲的内容,触发器和驱逐器。下一小节应该讲水位线啦。