一、什么是目标检测?
在前面的几篇中,我们学习了使用卷积神经网络进行图像分类,比如手写数字识别是用来识别0~9这十个数字。与图像分类处理单个物体的识别不同,目标检测它识别的不仅是物体,还是多个物体,不仅要确定物体的分类,还要确定物体的位置。比如下图:

目标检测不仅要告诉我们这张图片上既有小狗也有小猫,还要告诉小狗处于左边红色方框内,而小猫处于右边的红色方框内。也即目标检测的输出结果是【目标分类+目标坐标】
二、目标检测涉及的概念
1、边界框(bounding box)
检测任务需要同时预测物体的类别和位置,因此需要引入一些跟位置相关的概念。通常使用边界框(bounding box,bbox)来表示物体的位置,边界框是正好能包含物体的矩形框。就像上图中的小狗和小猫外围的红色框,就是两个边界框。
2、边界框位置表示的方法
- xyxy,即(x1,y1,x2,y2)其中(x1,y1)是矩形框左上角的坐标,(x2,y2)是矩形框右下角的坐标。
- xywh,即(x,y,w,h)其中(x,y)是矩形框中心点的坐标,w是矩形框的宽度,h是矩形框的高度。
3、预测框
要完成一项目标检测任务,我们希望模型能够根据输入的图片,输出一些预测的边界框,以及边界框中所包含的物体的类别或者说属于某个类别的概率,例如这种格式: [L,P,x1,y1,x2,y2],其中L是类别标签,P是物体属于该类别的概率。一张输入图片可能会产生多个预测框。
4、锚框
锚框与物体边界框不同,是由人们以某种规则生成出来的一种框。先设定好锚框的大小和形状,再以图像上某一个点为中心画出矩形框。在目标检测任务中,通常会以某种规则在图片上生成一系列锚框,将这些锚框当成可能的候选区域。模型对这些候选区域是否包含物体进行预测,如果包含目标物体,则还需要进一步预测出物体所属的类别。还有更为重要的一点是,由于锚框位置是固定的,它不大可能刚好跟物体边界框重合,所以需要在锚框的基础上进行微调以形成能准确描述物体位置的预测框,模型需要预测出微调的幅度。不同的模型往往有着不同的生成锚框的方式。
5、交并比
在检测任务中,使用交并比(Intersection of Union,IoU)作为衡量指标。这一概念来源于数学中的集合,用来描述两个集合A和B之间的关系,它等于两个集合的交集里面所包含的元素个数,除以它们的并集里面所包含的元素个数,具体计算公式如下:

我们用交并比来描述两个框之间的重合度。两个框可以看成是两个像素的集合,它们的交并比等于两个框重合部分的面积除以它们合并起来的面积,见下图:
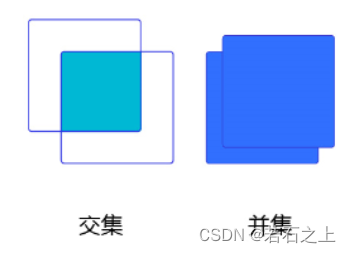
我们在图像分类的时候讲过,我们的神经网络需要建立一个损失函数,那么交并比就是一个很好衡量预测好坏的损失函数。