公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !

你是否也想要拥有一个属于自己的AI助理,可以回答各种问题、协助工作和学习?
现在,通过ollama和AnythingLLM,你可以在本地快速部署大型语言模型llama3,并结合个人文档构建专属知识库。不需要复杂配置,就能体验智能对话和高效问答的乐趣。赶快行动起来,拥抱AI时代,享受属于自己的个人助理吧!
为什么选择ollama和AnythingLLM:
1. 本地化部署,保护隐私 通过ollama和AnythingLLM,你可以在自己的设备上本地部署大型语言模型,无需将个人数据上传到云端,有效保护了隐私安全。
2. 专属知识库,内容个性化 AnythingLLM支持上传和构建个人文档知识库,AI助手的回答将基于你上传的材料,使内容更加贴合个人需求。
3. 免费且开源,无需付费 ollama和AnythingLLM都是免费开源软件,无需为使用付费,极大降低了使用成本。
4. 界面简洁友好,易于上手 两款软件界面设计简洁友好,操作步骤简单直观,即使是新手也可以快速上手。
5. 支持多种大模型,效果出色 ollama支持部署多种大型语言模型,如llama、stablelm等,AnythingLLM则可与其无缝对接,发挥大模型的优秀对话和问答能力。
总之,通过这两款软件,用户可以在本地便捷构建属于自己的AI知识助理,兼顾隐私、个性化和性能,是大模型本地化部署的优秀选择。
使用 Ollama+ AnythingLLM 在本地部署 llama3 大模型

Ollama是一个基于开源项目Alpaca的本地大语言模型部署工具。它的主要作用如下:
1. 本地部署大型语言模型 Ollama允许用户在自己的计算设备(如桌面电脑、笔记本电脑等)上本地部署和运行一些流行的大型语言模型,如LLaMA、Alpaca、GPT-J等,无需连接互联网或云服务。这样可以最大限度地保护用户的隐私和数据安全。
2. 模型运行和管理 通过命令行界面,Ollama提供了一系列命令,用于下载、安装、运行和管理本地的语言模型。用户可以方便地运行模型进行文本生成、问答等任务。
3. 开源且免费使用 Ollama作为开源项目,代码和模型均可免费获取和使用,无需付费订阅,降低了使用大模型的门槛。
4. 跨平台支持 Ollama支持多种主流操作系统,如Windows、Linux和MacOS,便于在不同平台上使用。
5. 与其他工具配合使用 Ollama可以与其他工具如AnythingLLM、LMStudio等配合使用,构建本地个性化的AI应用系统,实现如知识库问答、文本生成、智能辅助写作等功能。
总的来说,Ollama为用户提供了一种本地化、隐私安全且低成本的方式来使用大型语言模型,满足了个人和小型团队对大模型应用的需求,是大模型本地化部署的有益尝试。
1. 安装ollama
• Ollama官网[1]:https://ollama.com/
• Ollama下载地址[2]:https://ollama.com/download
打开以后注册并下载即可
安装没有什么好说的,找到自己的系统安装即可,因为我的电脑没有搞虚拟机,所以就直接安装Windows的版本了
2. 下载模型并运行Ollama
安装Ollama以后,通过管理员打开powershell
输入Ollama,只要出现下面这些,说明安装成功了

打开Ollama的模型[3]的网页:https://ollama.com/library

我们以llm3为例,双击进入

常用的命令有
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command可以看到页面中让执行Ollamarun llama3即可
一般来说run是用来跑模型的,但是如果本地没有这个模型的话,Ollama会自动下载
PS:国内的网络问题不知道有没有解决,下载模型的时候偶尔速度很快,但是很多时候速度很慢以至于提示TLS handshake timeout,这种情况建议重启电脑或者把Ollama重启一下(不知道为啥,我同步打开GitHub的时候速度会明显快一些,可能也是错觉)
下载完成以后我们输入Ollamalist可以查下载了哪些模型

这里我们直接输入Ollamarun llama3,就可以开始对话了

3. 下载并配置AngthingLLM
AnythingLLM是一个开源的本地知识库构建与问答系统工具,主要用于将各种形式的文档数据构建为知识库,并基于本地部署的大型语言模型(如LLaMA、Alpaca等)提供个性化的问答服务。
它的主要功能包括:
1. 知识库构建 AnythingLLM支持将PDF、网页、Word文档、Markdown等多种格式的文件转化为结构化的知识库,方便后续检索和问答。
2. 与大模型集成 通过与Ollama等工具的集成,AnythingLLM可以在本地部署和调用各种大型语言模型,实现模型微调、生成式问答等功能。
3. 个性化问答 基于构建的知识库和部署的语言模型,AnythingLLM能为用户提供高度个性化和专业化的问答服务,回答内容紧密依托于用户上传的文档资料。
4. 界面友好 AnythingLLM提供了简洁友好的图形界面,无需复杂配置,便于用户快速上手使用。
5. 开源免费 作为开源项目,AnythingLLM可以免费获取和使用,也鼓励社区贡献和二次开发。
总的来说,AnythingLLM为用户提供了一种方便、隐私友好的方式,基于自己的数据在本地构建个性化的知识库问答系统,避免了将敏感数据上传云端的隐私风险,是本地部署大模型应用的重要一环。
• AngthingLLM官网[4]:https://useanything.com
• AngthingLLM下载链接[5]:https://useanything.com/download
同样的选择对应的系统版本即可
在使用前,需要启动Ollama服务
执行Ollamaserve,Ollama默认地址为:http://127.0.0.1:11434[6]
然后双击打开AngthingLLM
因为我已经配置过,所以不好截图最开始的配置界面了,不过都能在设置里面找到
首先是LLM Preference,LLM provider选择Ollama,URL填写默认地址,后面的模型选择llama3,token填4096

Embedding Preferenc同样选择Ollama,其余基本一致,max我看默认8192,我也填了8192

Vector Database就直接默认的LanceDB即可

此时我们新建工作区,名字就随便取,在右边就会有对话界面出现了

此时你就有了自己本地的语言模型了
如果模型实在下不下来,也可以搞离线模型
Windows系统下Ollama存储模型的默认路径是C:\Users\wbigo.ollama\models,modelscope模型库网址[7]。
说实话,llama3-8B我感觉挺拉胯的,可能英文好一些,中文的话使用不如qwen。
AnythingLLM构建专用知识库(问答增加个人文档)
AnythingLLM的文档说明链接:https://docs.useanything.com/faq/why-is-llm-not-using-docs
首先打开Ollama的服务

然后打开AnythingLLM,点击要用的工作区上的按钮(上传文件,支持多种文件类型(PDF,TXT,DOC等)

点击Click to upload or drag and drop,选择要引用的文档
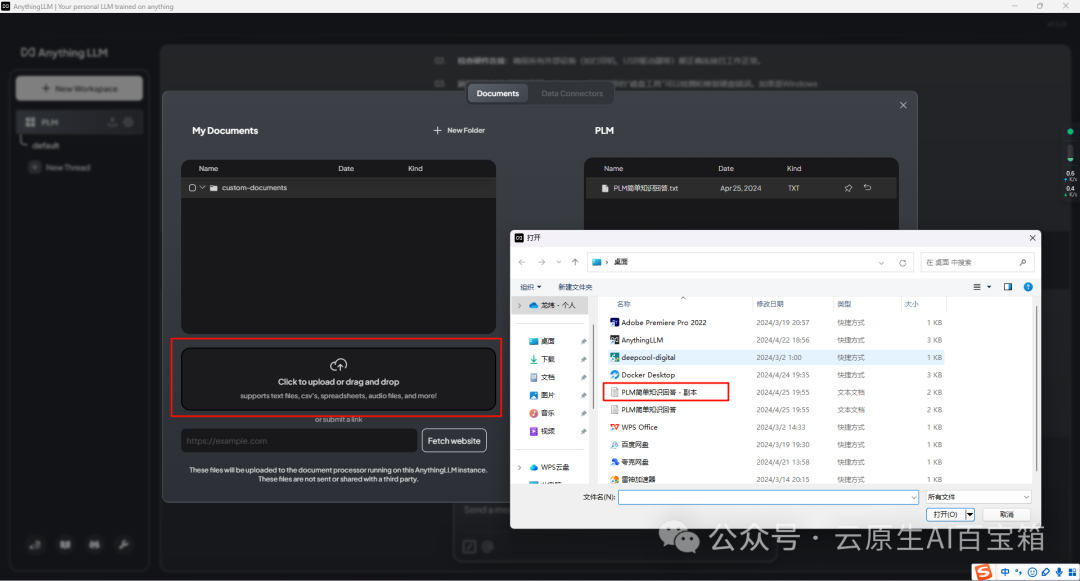
点击Move to Workspace,加载文档

点击Save and Embed

等待加载,提示Workspace updated successfully的时候说明加载完了

加载完成后就可以使用了,直接对话即可,回答的信息里面同时还可以显示引用文本(文件删除并不影响使用)

但是有一说一,感觉对文档的解析不是很智能,有时候会加些奇怪的附件说明从而导致内容产生歧义。可能和提示词,基础模型有关系,但使用确实方便多了。
AI超级阅读法
如何利用大模型来提升阅读理解能力,以下是我根据《基于 Ollama+AnythingLLM 的 AI 超级阅读法》提供的"AI超级阅读法"整理的表格:
| 步骤 | 任务 | 说明 |
| 第一步骤:粗读文档 | 1. 提取文档元数据 | 给文档打上领域、学科或专有名词标签 |
| 2. 一句话总结 | 用一句话概括文档主旨 | |
| 3. 写摘要 | 总结内容并写成详细摘要 | |
| 4. 列出大纲 | 越详细地列出文档大纲越好 | |
| 第二步骤:详读文档 | 1. 叙述大纲内容 | 详细阐述每一部分大纲的内容 |
| 2. 总结结论 | 总结文档的主要结论 | |
| 3. 列出学习收获 | 列举从文档中可以学到的知识点 | |
| 4. 提出疑问 | 针对内容提出可能的3个疑问 | |
| 第三步骤:个性化进阶阅读 | 1. 分析提取推荐语 | 分析结构提取大意,并写推荐语句 |
| 2. 获取文中独特见解 | 一句话总结作者最独特的观点见解 | |
| 3. 原文是什么 | 列出对应原文语句 | |
| 4. 解释生词名词 | 对不熟悉的词语和专有名词请求解释 | |
| 5. 改写用简单语言解释 | 要求用通俗易懂的语言重新解释 |
完整内容如下,我们使用以下 prompt 发给 AnythingLLM
第一步骤:粗读文档
1. 提取文档的元数据(阅读文章内容后给文章打上标签,标签通常是领域、学科或专有名词)
2. 一句话总结这份文档;
3. 总结内容并写成摘要;
4. 越详细地列举文档的大纲,越详细越好;
在阅读了第一步的结果的基础上,紧接着继续追问
第二步骤:详读文档:
1. 请详细叙述大纲中每一部分的内容,
2. 总结文档的结论;
3. 列举读这篇文档,我可以学到哪些知识?
4. 针对文档的内容,提出三个用户在阅读的过程中可能会有的疑问。
第三步骤:个性化进阶阅读文档:
1. 分析文档内容与结构,提取文章大意和写推荐语分析文档内容与结构,提取文章大意和写推荐语。提取金句和写推荐语,方便向朋友们推荐文档。
2. 一句话快速获取文中最独特的知识看文章的时候,我们通常会学到一些大家都知道的“常识”。但更厉害的是,有时候我们还能从文章里读到作者独到的见解,那些跟“常识”不一样的观点。这就像是捡到了宝,因为这些“反常识”的东西,往往都是作者亲身体验后总结出来的。而我们呢,只需要读读文章,就能学到别人的经验,多划算啊!更妙的是,这些独到的见解经常能和我们已经知道的知识碰撞出火花,让我们有更多的想法。
3. 更进一步,这个知识、见解、证据在文中的原文是什么?如果你对总结里的某个知识点、见解、案例挺感兴趣的,想了解一下原文是怎么描述的,你可以自己读读原文。不过,如果你觉得这样太麻烦,也可以告诉大模型,让它帮你把文档中那个观点的原话找出来,这样你就不用费心去找了。
4. 辅导阅读,对不懂的部分、高深专业名词进行追问如果遇到一些不熟悉的名词,也可以随时向大模型请教:“嘿,这个词是什么意思啊?”建议直接把名词放到问题里,让大模型来解释一下。
5. 还不懂,可要求改写,用高中生可以听懂的语言解释当你还是读得一头雾水,感觉作者的文字像是来自外太空,完全不知道他在说啥时,怎么办?别担心,我有个超赞的小技巧分享给你!试试这样告诉大模型:“嘿,能不能用高中生都能懂的话给我解释下这个XXX?”这样一来,大模型就会用简单明了的方式给你提示,让你秒懂!当然啦,这个“高中生”只是个比喻,如果你觉得内容太简单或太复杂,也可以换成“大学生”或“小学生”。不过通常来说,“高中生”是个不错的平衡点,既不会过于简单,也不会让你感到压力山大。
大模型能力阅读很强,但还有一些不足:
1. 判断误解现象大模型有时会被误导性案例或语境蒙骗,得出与原文意思相反的总结,这是目前大模型在理解复杂语义上的一个短板。
2. 结果不一致性 不同大模型对同一文本的总结往往存在差异,这体现了它们在知识理解上的偏差,也说明单一大模型的能力仍有限制。
3. 非规范文本处理能力不足 大模型更擅长处理形式化的文书内容,而对于访谈记录、会议纪要等非正式语料,由于结构随意、表达不规范,大模型的理解和概括能力会受到一定影响。
大模型无疑是人工智能发展的重要方向,相信随着该领域的深入研究,这些挑战终将迎刃而,,大模型的阅读理解能力将得到极大增强,为人类带来更多实际应用价值。
引用链接
[1] Ollama官网: https://ollama.com/[2] Ollama下载地址: https://ollama.com/download[3] Ollama的模型: https://ollama.com/library[4] AngthingLLM官网: https://useanything.com[5] AngthingLLM下载链接: https://useanything.com/download[6] http://127.0.0.1:11434: http://127.0.0.1:11434/[7] modelscope模型库网址: https://modelscope.cn/models
本文转载自:「云原生AI百宝箱」,原文:https://url.hi-linux.com/yBeCF,版权归原作者所有。欢迎投稿,投稿邮箱: [email protected]。

🚀 最近,我们建立了一个技术交流微信群。目前群里已加入了不少行业内的大神,有兴趣的同学可以加入和我们一起交流技术,在 「奇妙的 Linux 世界」 公众号直接回复 「加群」 邀请你入群。
📕 关注『奇妙的 Linux 世界』公众号,带你开启有趣新生活!更多好用好玩的软件资源,可访问 https://666666.dev 免费获取。

你可能还喜欢
点击下方图片即可阅读

与 ChatGPT 共舞:利用人工智能解决 Traefik 配置难题的独特体验
点击上方图片,『美团|饿了么』外卖红包天天免费领


更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!