Accelerating models on ROCm using PyTorch TunableOp — ROCm Blogs (amd.com)

在这篇博客中,我们将展示如何利用 PyTorch TunableOp 在 AMD GPU 上使用 ROCm 加速模型。我们将讨论通用矩阵乘法(GEMM)的基础知识,展示调优单个 GEMM 的示例,最后通过 TunableOp 演示在 LLM(gemma)上实现的实际性能提升。
注意
PyTorch TunableOp 在 torch v2.3 或更高版本中可用。
要运行此博客中的代码,请参阅附录中的 运行此博客 .
引言
随着模型的规模和复杂性不断增加,以尽可能高效地运行这些模型的需求也在增加。PyTorch TunableOp 提供了一条简便的途径,通过调整底层的 GEMM 操作来实现现有训练和推理任务的适度性能提升。
通用矩阵乘法
GEMM 是神经网络中许多组件(包括全连接层、卷积、注意力机制等)的基本构建块。GEMM 是 Basic Linear Algebra Subprograms (BLAS) 库(如 hipBLAS)的多个组件之一。
GEMM 是一种矩阵乘法操作,其形式为:
C←αAB+βC
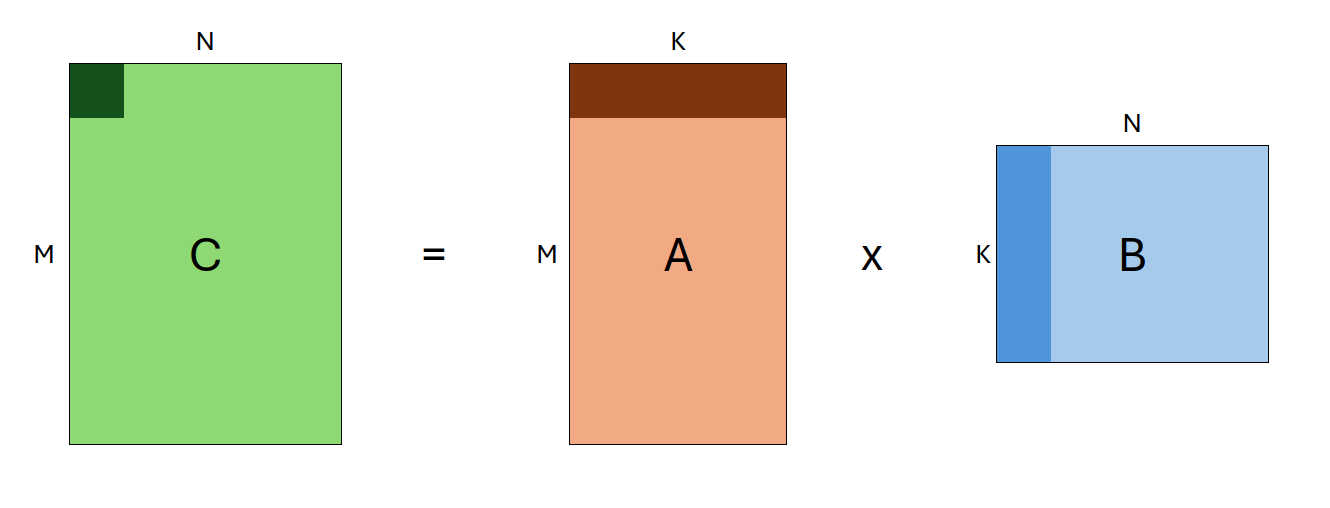
其中 A 和 B 是输入矩阵(可能会转置),α 和 β 是标量,C 是作为输出缓冲区的预先存在的矩阵。A、B 和 C 的形状分别定义为 (M, K)、`(K, N)` 和 (M, N)。因此,单个 GEMM 的定义由以下输入参数组成:`transA, transB, M, N, K`。这些参数统称为*问题规模*。
由于 GEMM 涉及神经网络的许多组件,尽可能快速高效地执行 GEMM 对于提高机器学习任务的性能至关重要。
对于任何给定的 GEMM(由问题规模定义),有许多不同的方法可以解决它!系统上可能存在多个 BLAS 库。每个 BLAS 库可能有多种不同的算法来解决给定的 GEMM,每种算法可以有数百种可能的独特参数组合。因此,*即使是单个 GEMM 也可能有数千种不同的解法*,其性能各不相同。
那么问题来了:当 PyTorch 执行矩阵乘法时,它如何知道哪种 GEMM 算法最快?答案是:它不知道。
在一个非常高的层次上,当你在 PyTorch 中运行矩阵乘法时,`C = A @ B`,会发生以下情况:
-
PyTorch 通过 (ATen) 将矩阵
A和B传递给 BLAS 库 -
BLAS 库使用内置的启发式方法(通常是查找表)来选择解决给定 GEMM 的算法
-
BLAS 库计算结果
C -
结果传递回 PyTorch
然而,这些启发式方法并不总是能够选择最快的算法,这可能取决于许多因素,包括你的具体环境、架构等。这就是 PyTorch TunableOp 的用武之地。
TunableOp 和 BLAS 库
TunableOp 不使用默认的 GEMM 运算,而是会针对您的特定环境_搜索最佳的 GEMM 运算_。它通过首先查询底层 BLAS 库以获取给定 GEMM 的所有解,并对每个解进行基准测试,然后选择最快的解来实现这一目标。TunableOp 之后将这些解写入磁盘,可以在后续运行中使用。这得益于支持调优的 hipBLAS 库。
我们通过设置环境变量 PYTORCH_TUNABLEOP_ENABLED=1 来启用 TunableOp,然后正常运行我们的程序。例如:
PYTORCH_TUNABLEOP_ENABLED=1 python my_model.py
另外,我们可以打开详细模式 PYTORCH_TUNABLEOP_VERBOSE=1 以查看 TunableOp 的执行情况。有关可用选项的完整列表,请参见 TunableOp README。
通过以下示例,我们将深入探讨 TunableOp 的功能。
PyTorch TunableOp
示例1:单个矩阵乘法
为了理解PyTorch TunableOp的工作原理,我们将调优一个单独的矩阵乘法。
首先,我们编写一个简单的Python程序`matmul.py`,具体步骤如下:
-
构造两个输入矩阵`A`和`B`,它们的形状分别为`(M, K)`和`(K, N)`
-
将它们相乘10000次,并记录操作时间
-
打印运算速度
以下是`src/matmul.py`的内容:
import torch
def time_matmul(M, N, K):
n_iter = 10000 # 记录的迭代次数
n_warmup = 10 # 预热迭代次数
t0 = torch.cuda.Event(enable_timing=True)
t1 = torch.cuda.Event(enable_timing=True)
# 构造输入矩阵
A = torch.rand(M, K, device="cuda")
B = torch.rand(K, N, device="cuda")
# 基准测试GEMM
for i in range(n_iter + n_warmup):
if i == n_warmup:
t0.record() # 直到预热完成后开始记录
C = A @ B
# 计算经过的时间
t1.record()
torch.cuda.synchronize()
dt = t0.elapsed_time(t1) / 1000
print(f"{n_iter/dt:0.2f} iter/s ({dt:0.4g}s)")
time_matmul(512, 1024, 2048)
接下来,我们可以运行这个脚本:
python src/matmul.py
输出结果:
11231.81 iter/s (0.8903s)
然后我们启用PyTorch TunableOp,设置环境变量`PYTORCH_TUNABLEOP_ENABLED=1`。我们还可以通过设置`PYTORCH_TUNABLEOP_VERBOSE`打开详细输出,并通过`PYTORCH_TUNABLEOP_FILENAME`指定结果输出文件。
需要注意的是,`PYTORCH_TUNABLEOP_FILENAME`不是必须的,但我们在这里使用它是为了区分不同调优结果。通常情况下,你可以不设置这个变量,这样会写入默认文件`tunableop_results.csv`。
PYTORCH_TUNABLEOP_ENABLED=1\ PYTORCH_TUNABLEOP_VERBOSE=1\ PYTORCH_TUNABLEOP_FILENAME=src/matmul_result.csv\ python src/matmul.py
输出结果:
> reading tuning results from src/matmul_result0.csv could not open src/matmul_result0.csv for reading tuning results missing op_signature, returning null ResultEntry finding fastest for GemmTunableOp_float_NN(nn_1024_512_2048) out of 1068 candidates ├──verify numerics: atol=1e-05, rtol=1e-05 ├──tuning using warmup iters 1 [1.01208 ms] and tuning iters 29 [29.3505 ms] instance id=0, GemmTunableOp_float_NN(nn_1024_512_2048) Default ├──found better instance id=0. 0.280746ms. Default ├──unsupported id=1, GemmTunableOp_float_NN(nn_1024_512_2048) Gemm_Rocblas_1074 ├──unsupported id=2, GemmTunableOp_float_NN(nn_1024_512_2048) Gemm_Rocblas_1075 ... ... ... └──found fastest for GemmTunableOp_float_NN(nn_1024_512_2048) Gemm_Rocblas_4365 4.449s (2248 iter/s) writing file src/matmul_result0.csv
对于一个单独的GEMM操作,调优过程通常少于一分钟,但会产生数千行输出。以下是一些调优输出的关键片段:
-
首先,我们看到TunableOp找到一个GEMM进行调优。形状为(1024, 512, 2048),有4454个候选算法(这个数量可能根据你的环境变化)。
... finding fastest for GemmTunableOp_float_NN(nn_1024_512_2048) out of 4454 candidates ...
-
TunableOp基准测试每个算法以找到最快的。它首先检查算法是否数值稳定,然后记录每个算法的时间。我们可以看到三种不同类型的输出:
-
一些算法不受支持,跳过:
... ├──unsupported id=326, GemmTunableOp_float_TN(tn_1024_512_2048) Gemm_Rocblas_2702 ...
-
在一些情况下,GEMM在初始检查中被发现太慢,被跳过:
... ├──verify numerics: atol=1e-05, rtol=1e-05 ├──skip slow instance id=811, GemmTunableOp_float_NN(nn_512_1024_2048) Gemm_Rocblas_4381 ...
-
剩余的算法被基准测试:
... ├──verify numerics: atol=1e-05, rtol=1e-05 ├──tuning using warmup iters 1 [0.566176 ms] and tuning iters 52 [29.4412 ms] instance id=525, GemmTunableOp_float_TN(tn_1024_512_2048) Gemm_Rocblas_3901 ...
-
-
TunableOp最终会确定最快的算法,并将其写入结果文件 src/matmul_result0.csv。我们可以检查该文件的内容:
Validator,PT_VERSION,2.4.0 Validator,ROCM_VERSION,6.0.0.0-91-08e5094 Validator,HIPBLASLT_VERSION,0.6.0-592518e7 Validator,GCN_ARCH_NAME,gfx90a:sramecc+:xnack- Validator,ROCBLAS_VERSION,4.0.0-88df9726-dirty GemmTunableOp_float_NN,nn_1024_512_2048,Gemm_Hipblaslt_NN_52565,0.0653662
-
结果文件开始的几行是
Validator行,这些行指定生成该文件的环境版本。如果更改这些版本中的任何一个,该结果将不再有效——TunableOp也会检测到这些更改,并且不会加载之前的调优结果,而是重新运行调优。注意
如果由于验证器不匹配重新运行调优,现有的结果文件将被完全覆盖!
-
剩余的行表示为每个遇到的GEMM调优后的解决方案,包含四个字段:
-
操作符名称
-
参数
-
解决方案名称
-
平均执行时间
在我们的例子中,我们只有一个解决方案(名称:`GemmTunableOp_float_NN`),参数为
nn_1024_512_2048。参数中的前两个字母nn表示矩阵A和B都没有转置(`t` 表示转置),后面的三个数字分别是M、`N` 和K。 -
注意:在我们的脚本中,`M=512`,`N=1024`, 但是在解决方案中它们被交换了!这是因为 PyTorch 可以选择转置和交换A和B (因为
AB = C等效于BtAt = Ct), 因此在到达BLAS层之前,`M` 和N被交换。
现在我们已经运行了调优,我们将重新运行上面的脚本。这次,它将拾取并应用调优结果。
PYTORCH_TUNABLEOP_ENABLED=1 PYTORCH_TUNABLEOP_VERBOSE=1 PYTORCH_TUNABLEOP_FILENAME=src/matmul_result.csv python src/matmul.py
输出结果:
reading tuning results from src/matmul_result0.csv Validator,PT_VERSION,2.4.0 Validator,ROCM_VERSION,6.0.0.0-91-08e5094 Validator,HIPBLASLT_VERSION,0.6.0-592518e7 Validator,GCN_ARCH_NAME,gfx90a:sramecc+:xnack- Validator,ROCBLAS_VERSION,4.0.0-88df9726-dirty Loading results GemmTunableOp_float_NN,nn_1024_512_2048,Gemm_Hipblaslt_NN_52565,0.0653662 14488.24 iter/s (0.6902s)
太好了!通过调优,我们达到了大约14500次迭代/秒(相比未优化前约11900次迭代/秒),代表着吞吐量增加了22%!
扩展调优
此外,我们可以在现有调优的基础上进行构建。当启用调优时,新的GEMM(广义矩阵乘法)将在遇到时进行调优,但现有的GEMM不会重新调优,即使在多次运行中也是如此。这在我们对网络设计进行迭代时非常有用,因为我们只需要在遇到新形状时进行调优。
为了演示这一点,可以尝试编辑并运行`src/matmul.py`脚本,将其修改为不同的GEMM大小,例如`128, 256, 512`,然后再次运行。你会看到TunableOp将会在`matmul_results0.csv`文件中添加一行新的解决方案,对于新的GEMM:
Validator,PT_VERSION,2.4.0 Validator,ROCM_VERSION,6.0.0.0-91-08e5094 Validator,HIPBLASLT_VERSION,0.6.0-592518e7 Validator,GCN_ARCH_NAME,gfx90a:sramecc+:xnack- Validator,ROCBLAS_VERSION,4.0.0-88df9726-dirty GemmTunableOp_float_NN,nn_1024_512_2048,Gemm_Hipblaslt_NN_52565,0.0653662 GemmTunableOp_float_NN,nn_256_128_512,Gemm_Rocblas_21,0.00793602
通过这个简单的例子,我们展示了TunableOp如何工作,如何选择和优化GEMM,并直接将我们的PyTorch代码与底层的GEMM调用链接起来。
接下来,让我们进入更复杂的内容。
示例二:Gemma
让我们在一个实际的例子中测试TunableOp:Gemma 2B,这是Google开源的一个轻量级语言模型。当在完整模型上使用TunableOp时,*我们应该尽量减少或避免动态形状*!这是因为TunableOp会对每一个遇到的_唯一GEMM_进行详尽的搜索。如果有数百甚至数千个独特的形状需要调整,这将花费相当长的时间!
在使用大型语言模型进行推理时,动态形状在两个地方引入:
-
填充阶段 - 在此阶段,模型处理输入提示并生成第一个标记。如果输入的长度不同,不同的形状将在模型中流动;对于每个新的输入提示长度,我们将遇到(并调整)多个新的GEMM。
我们通过填充输入序列来解决这个问题. 在极端情况下,我们可以将所有输入填充到最大输入长度。但是,这并不高效,因为对于较短的提示,我们将浪费在填充标记上的大量计算!*一个好的中间方案是离散化输入序列长度,例如填充到8的倍数*(比如序列长度7填充到8,14填充到16等)。事实上,HuggingFace的tokenizers通过 pad_to_multiple_of 参数支持内置的填充。或者,离散化到2的幂数也是一个不错的选择。
-
生成阶段(kv缓存) - 在生成第一个标记之后,LLM通过将上一次迭代的输出传递回输入,自动回归生成后续标记。在生成过程中,我们使用称为*kv缓存*的技术,这是一个推理时的优化,可以减少冗余计算(关于kv缓存的更多详细信息,请参阅此文章)。*然而,这个kv缓存引入了更多的动态形状!*随着每个新标记的生成,kv缓存的大小会增加,在每次迭代中引入多个新的GEMM需要调整。
我们通过使用“静态”kv缓存来解决这个问题。本质上,我们会前期分配一个最大大小的kv缓存,然后在每一步中屏蔽未使用的值。如果模型没有内置支持,设置静态kv缓存可能很困难。我们将在此使用HuggingFace的静态kv缓存,此支持包括Gemma在内的多个模型。
在尝试对LLMs进行`torch.compile`时会遇到上述两个问题,如 PyTorch’s GPT-Fast博文中讨论,然而它们有稍微不同的解决方案。为了解决填充阶段问题,他们使用 动态形状分别编译填充部分的网络,同时为生成阶段使用标准编译和静态kv缓存。
下面显示了`src/llm.py`的内容,我们将用它来对模型的延迟(即batch_size=1)进行评估,并在代码中提供注释说明各部分功能。
注意
由于`gemma`模型是受限访问的,你需要提供自己的Huggingface令牌来下载和运行此脚本。
import os
import torch
import transformers
import click
# Use Click to parse command-line arguments
@click.command
@click.option("--tune", is_flag=True)
def main(tune):
# Set some variables
seq_len = 256 # Max sequence length to generate
n_batches = 8 # Number of batches to time
n_warmup = 2 # Number of warmup batches
prompt = ["Hello Earthlings!"] # Input prompt
# 我们可以通过在代码中设置环境变量来启用调整 - 只要在使用torch之前完成即可。
# 这通常比每次传递环境变量要简便
if tune:
print("Tuning enabled")
os.environ["PYTORCH_TUNABLEOP_ENABLED"] = "1" # Enable tuning
os.environ["PYTORCH_TUNABLEOP_FILENAME"] = "src/llm_result.csv" # Specify output file
# Retrieve the model and tokenizer
model = "google/gemma-2b"
tokenizer = transformers.AutoTokenizer.from_pretrained(model)
model = transformers.AutoModelForCausalLM.from_pretrained(model).to("cuda")
# Set the model to use a static KV cache - see https://huggingface.co/docs/transformers/main/en/llm_optims?static-kv=generation_config#static-kv-cache-and-torchcompile
model.generation_config.cache_implementation = "static"
# Tokenize our input.
# Use padding with `pad_to_multiple_of` to minimize the number of GEMMs to tune
# Larger values => Less GEMMs to tune, but more potential overhead for shorter prompts
inputs = tokenizer(prompt, return_tensors="pt", padding=True, pad_to_multiple_of=8).to("cuda")
# Determine how many tokens to generate. Here, we need to subtract the number of tokens in the prompt to keep the same
# overall sequence length
n_tokens = seq_len - inputs["input_ids"].shape[1] # number of tokens to generate
t0 = torch.cuda.Event(enable_timing=True)
t1 = torch.cuda.Event(enable_timing=True)
for i in range(n_batches + n_warmup):
# Don't start timing until we've finished our warmup iters
if i == n_warmup:
torch.cuda.synchronize()
t0.record()
# Generate!
model.generate(
**inputs,
max_new_tokens=n_tokens, # Force the model to generate exactly n_tokens before stopping
min_new_tokens=n_tokens,
use_cache=True, # Ensure we use the kv-cache
)
# Complete timing, synchronize, and compute elapsed time
t1.record()
torch.cuda.synchronize()
dt = t0.elapsed_time(t1) / 1000
tokens_per_second = n_batches * n_tokens / dt
print(f" Tokens/second: {tokens_per_second:0.4f} ({n_tokens*n_batches} tokens, {dt:0.2f} seconds)")
if __name__ == "__main__":
main()
首先,让我们在未启用调优的情况下运行脚本:
python src/llm.py
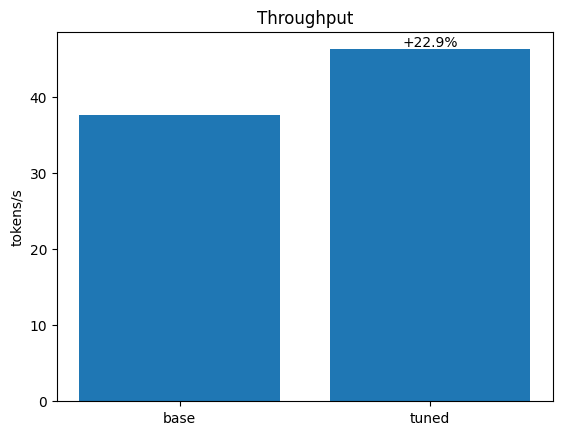
Tokens/second: 37.5742 (1984 tokens, 52.80 seconds)
我们实现了37.6个tokens/s的吞吐量。接下来,让我们启用调优。这里,我们使用命令行参数`--tune`,我们的脚本将解析它,然后为我们设置相关的环境变量。
Tuning will take some time, but will be silent, as we have not turned on verbosity! Feel free to edit the script to turn on verbosity.
python src/llm.py --tune
Tuning enabled Tokens/second: 46.2401 (1984 tokens, 42.91 seconds)
仅仅通过启用调优,我们就获得了22.9%的加速(37.6 -> 46.2 tokens/s)!
结论
PyTorch TunableOp 通过调整模型中的 GEMMs,可以成为加速 AMD 上机器学习工作负载的一种简便且有效的方式。然而,在使用 TunableOp 时需要注意以下几点:
-
调整过程需要时间——根据工作负载的不同,调整可能比运行还要花费更多的时间。然而,这**是一次性的成本**,因为调整结果可以重复使用和扩展。这意味着,对于较长的训练任务和模型服务,以及在迭代开发过程中,调整将特别有效。
-
应避免或尽量减少动态形状,以减少需要调整的独特 GEMMs 的数量。
考虑到这些因素,将 TunableOp 集成到 PyTorch 工作流中,是在 AMD GPU 上实现适度性能提升的一种简便方法,而无需更改现有代码,只需最少的额外工作。
进一步阅读
TunableOp 只是几种推理优化技术之一。要了解更多,请参见 在 AMD GPU 上进行大型语言模型(LLM)推理优化。
附录
运行本博客
前提条件
要运行本文中的代码,您需要具备以下条件:
-
硬件:AMD GPU——请参见兼容 GPU 列表
-
操作系统:Linux——请参见 支持的 Linux 发行版
-
软件:ROCm——请参见 安装说明
安装
运行本文中的代码有两种方式。首先,您可以使用 Docker(推荐),或者您可以构建自己的 Python 环境并直接在主机上运行。
1. 在 Docker 中运行
使用 Docker 是构建所需环境的最简单和最可靠的方法。
-
确保您已安装 Docker。如果没有,请参见 安装说明
-
确保您在主机上安装了
amdgpu-dkms(ROCm 附带),以便从 Docker 内访问 GPU。请参见 ROCm Docker 说明。 -
克隆仓库,并进入博客目录
git clone [email protected]:ROCm/rocm-blogs.git cd rocm-blogs/blogs/artificial-intelligence/pytorch-tunableop
-
构建并启动容器。有关构建过程的详细信息,请参见
dockerfile。这将启动容器中的 Shell。cd docker docker compose build docker compose run blog
2. 在主机上运行
如果您不想使用 Docker,也可以直接在本机器上运行本博客——尽管这需要多做一些工作。
-
前提条件:
-
安装 ROCm 6.0.x
-
确保已安装 Python 3.10
-
安装 PDM——这里用于创建可重现的 Python 环境
-
-
在本博客的根目录中创建 Python 虚拟环境:
pdm sync
-
使用
pdm run前缀运行本文中的命令,例如:pdm run python src/matmul.py