一、引言

-
1.什么是顺序表
-
定义:
顺序表是一种基于阵列实现的线性表结构,用连续的存储空间保存表中的数据元素,并按顺序排列。- 底层依赖阵列,支持随机访问。
- 元素之间没有额外的连接信息,如指针或链表节点。
- 通过动态扩容机制克服了静态容量修复的问题。
-
结构特点:
- 数据存储连续在内存中,索引顺序与逻辑顺序一致。
- 支持按索引快速访问元素(时间复杂度为O(1)。
- 对插入、删除操作,移动仓库要素(时间复杂度为)O(n))。
-
-
2.线性表中顺序表与链表的对比
-
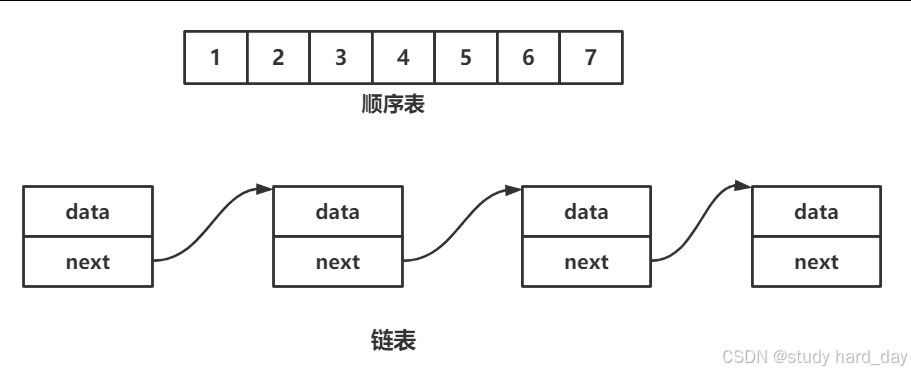
1.线性表介绍:
线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结 构,常见的线性表:顺序表、链表、栈、队列...
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物 理上存储时,通常以数组和链式结构的形式存储。
3. 顺序表能干什么?
顺序表可以实现以下功能:
-
随机访问
- 通过索引快速定位和访问任意位置的元素。
- 例如:
list.get(index)在哦(1)欧拉(1)欧( 1 )返回期限指定位置的元素。
-
动态扩展
- 添加新元素时,如果容量不足,顺序表会自动扩容,容纳更多数据。
- 需要提前知道数据规模,适合处理动态变化的数据。
-
创建和删除
- 支持在任意位置插入或删除元素。
- 在插入和删除时会移动部分数据,效率比链表低,但在小规模操作时性能仍然较差。
-
操作手册
- 顺序表允许通过循环或迭代器遍历所有元素,适合处理线性数据集合。
-
存储社区数据
- 元素按插入顺序排列,适合存储需要保持顺序的数据。
4.为什么要使用顺序表?
优势
-
我们随机访问
- 顺序表的元素存储在连续的内存空间中,支持通过内存下标快速访问,时间复杂度为O(1)。
- 对比链表,链表的随机访问需要遍历节点,效率为。
-
动态大小调整
- 顺序表通过动态扩容机制解决了静态配额容量固定的问题,适合处理数据规模不固定的场景。
- 例如,用户提交的动态列表、动态扩展的集合等。
-
操作简单
- 顺序表的底层是总线,结构清晰,没有链表复杂的指针操作。
缺点与限制
- 写作与写作效率低
- 在非尾部插入或删除元素,需要移动后续数据,时间复杂度为哦(n)在)在)。
- 适合插入和删除少数的场景,不适合间歇更新的场景。
- 内存连续性要求高
- 需要在内存中找到足够大的连续存储空间。
- 如果数据量非常大,内存碎片化可能成为瓶颈。
5. 顺序表使用场景
-
随机访问频繁的场景
- 如:访问学生的学号列表、查询用户的ID集合等。
- 顺序表提供哦(1)欧拉(1)欧( 1 )的随机访问性能,比链表更适合此类需求。
-
数据动态扩展
- 动态吞吐量是顺序表的一大优势,适合处理需要经常增加数据的场景。
- 例如:动态收集用户输入、动态创建任务列表。
-
数据量减少,插入/删除的场景较少
- 在数据量伸缩且不间歇的场景下,顺序表的插入/删除性能可以接受。
- 例如:维护一个常见用户名的列表或管理购物车中的商品。
-
需要顺序存储的场景
- 数据按照逻辑顺序存储,保持插入顺序。
- 例如:消息队列、任务列表。
-
频繁操作的场景
- 顺序表支持高效的线性遍历,适合批量操作或迭代访问。
- 例如:统计一组用户的平均年龄。
-
栈和队列的实现
- 顺序表可以作为栈和队列的底层实现。
- 例如:
- 栈:顺序表尾部的插入和删除非常高效。
- 队列:通过首尾操作实现队列功能。
-
本文目标
- 学习顺序表的核心原理及功能。
- 通过 Java 实现理解其底层细节。
- 对比分析顺序表的性能及其适用场景。
二、顺序表核心功能
以下功能是顺序表的关键操作,每个方法对应不同的算法逻辑:
-
初始化
- 分配存储基础设施,初始化容量,设置当前元素个数为
0。 - 提供一个默认初始化容量,也允许用户创建初始容量。
- 分配存储基础设施,初始化容量,设置当前元素个数为
-
动态扩张
- 当元素插入导致容量不足时,自动分配更大的存储空间。
- 数据迁移到新的存储中,通常扩容为当前容量的两倍。
-
增
- 支持在表尾添加元素(append)。
- 支持在指定索引插入元素,需要移动部分数据。
-
删
- 从指定索引删除元素,需要将后续元素前移。
- 设置已删除的存储空间为
null,避免内存泄漏。
-
查
- 按索引快速访问元素,复杂度为O(1)。
-
清空表
- 将所有存储位置设置为
null,释放占用的内存资源。
- 将所有存储位置设置为
三、顺序表基础代码实现
我们通过接口来写顺序表的个个方法:
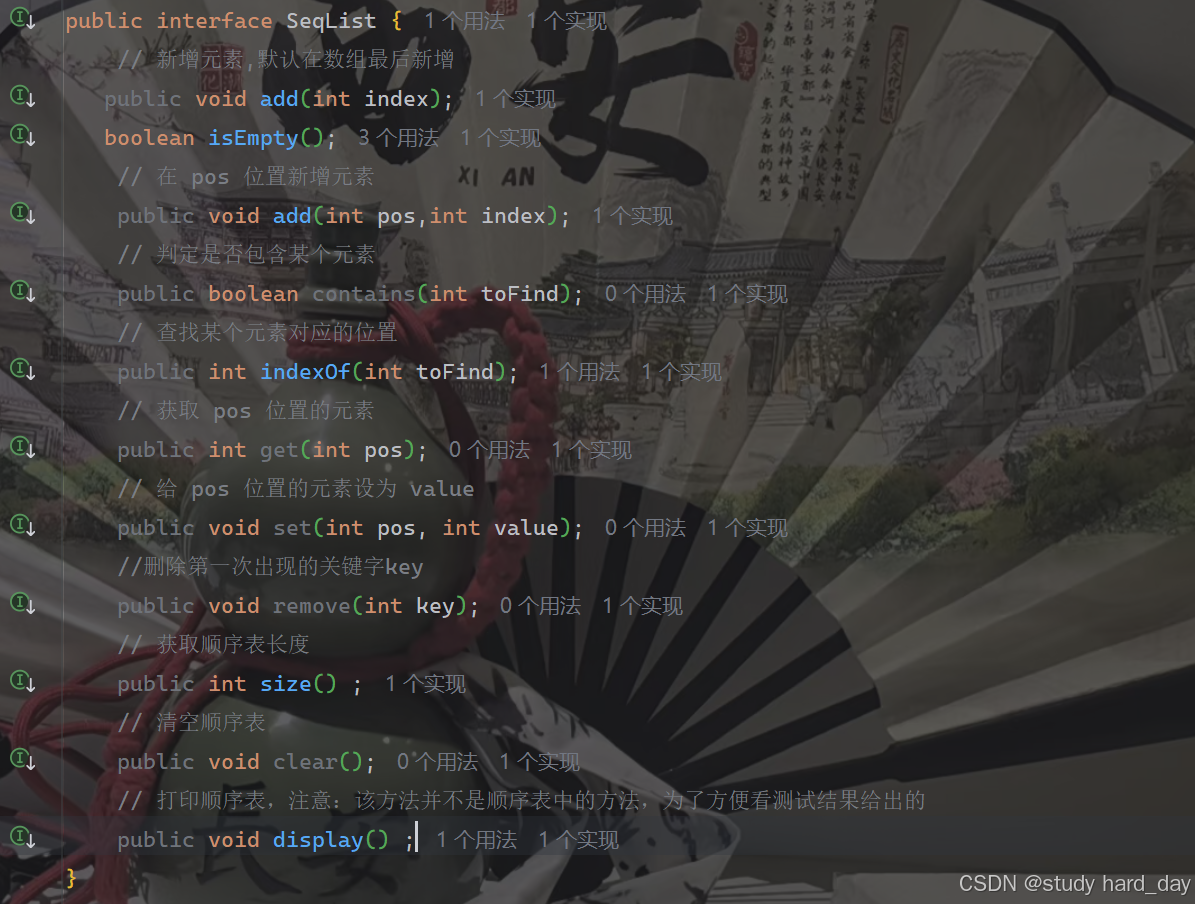
在我们的实现过程中,我们需要先定义一个数组的内容:

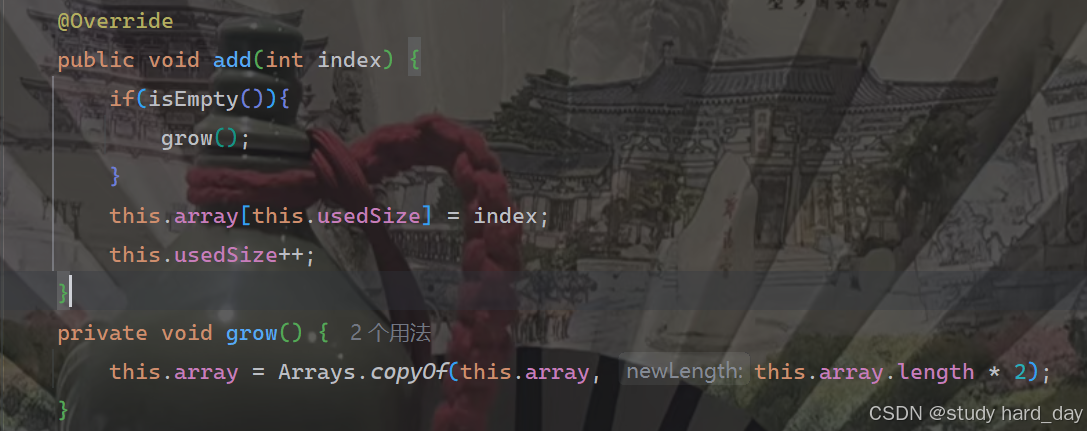
1.新增元素,默认在数组最后新增(add)
在插入数组时,我们需要先考虑,在我们插入这个数据时,数组是否越界,如果不越界我们就正常添加,如果越界了,我们就考虑如何让他不越界(动态扩容):

由此我们新增元素的所有考虑事项就完成了,这个时候我们只需要在数组后面添加元素即可:
2.判断数组是否满了:
如果我们定义的usedSize的值等于数组长度时,此时我们的数组就满了:
不相等就没满:

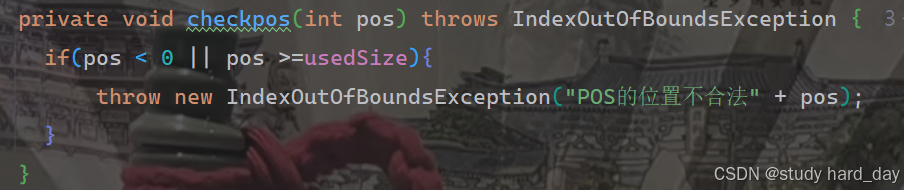
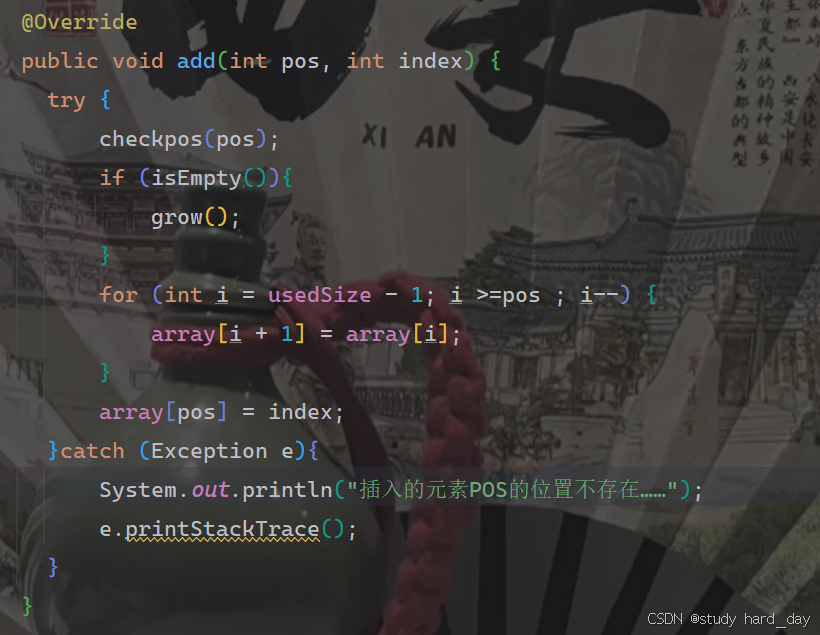
3.在 pos 位置新增元素
注意事项:1.判断我们的pos位置是否合法;
2.判断我们再添加数据时,数组是否越界;
3.满足上面两条我们就可以直接把数组上pos位置的值添加为我们要的值,
在修改时我们要注意从后遍历,如果从前往后遍历的话,我们表中的数据就会发生覆盖的情况
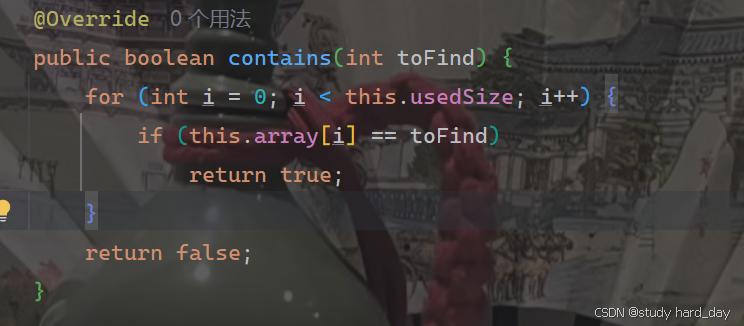
4.判定是否包含某个元素
我们只需要遍历数组中的之即可:
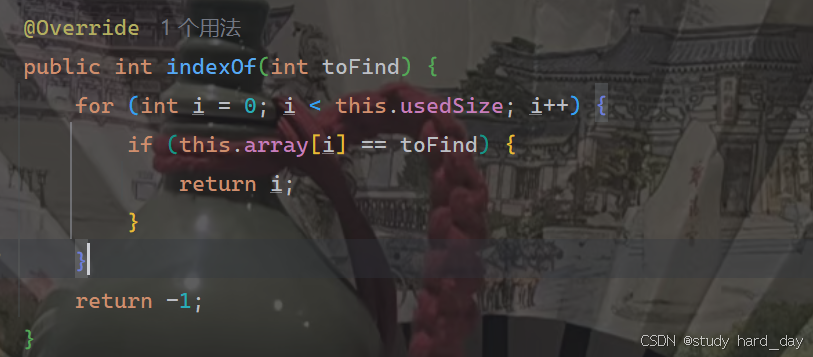
5.查找某个元素对应的位置
我们只需要遍历数组中的之即可,如果有我们就返回下标值,没有就返回-1:
6.获取 pos 位置的元素
1.检查数组情况,看是否有数据
2.判断我们的pos位置是否合法
3.满足上面两条我们就可以直接返回数组上pos位置的值;

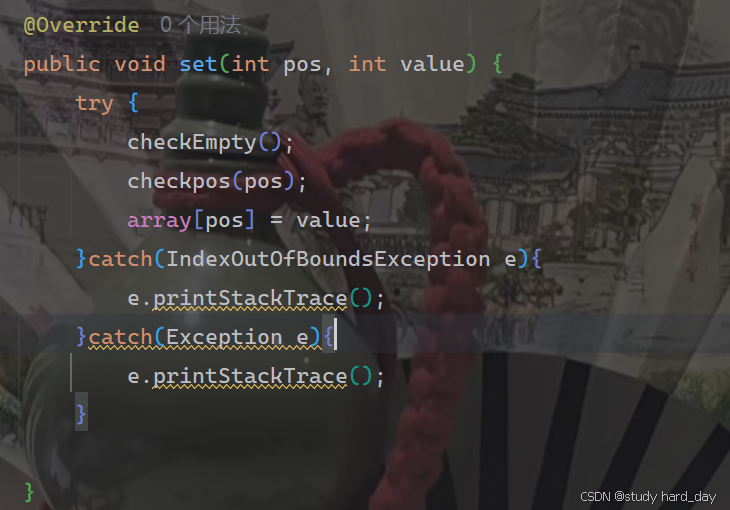
7.给 pos 位置的元素设为 value
1.检查数组情况,看是否有数据
2.判断我们的pos位置是否合法
3.满足上面两条我们就可以直接把数组上pos位置的值改为我们要修改的值
8.删除第一次出现的关键字key
1.检查数组情况,看是否有数据
2.判断我们的pos位置是否合法
3.满足上面两条我们就可以直接把数组上pos位置的值删除我们要的值,
在修改时我们要注意从后遍历,如果从前往后遍历的话,我们表中的数据就会发生覆盖的情况
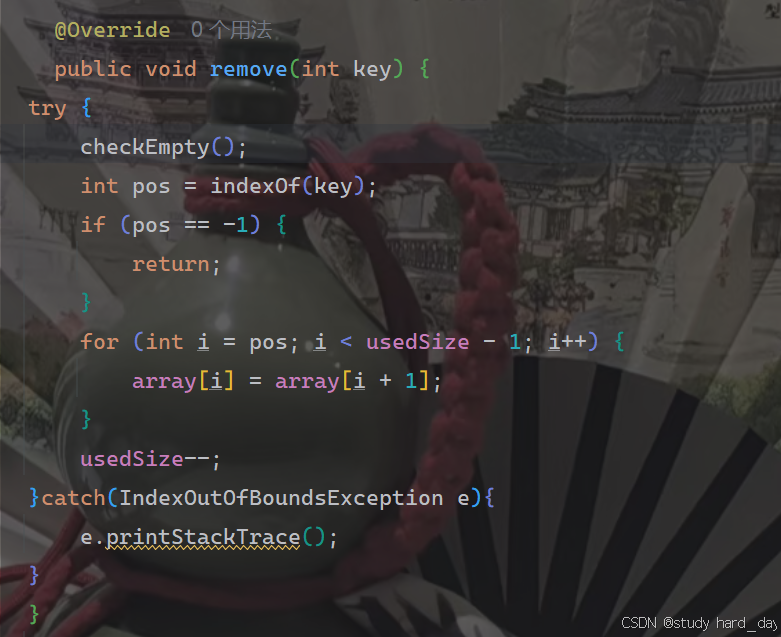
9.获取顺序表长度
直接返回usedSize的之即可,
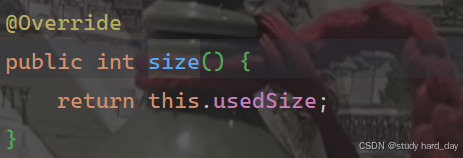
10.清除数据
将usedSize的值修改为0,就可清空数组;
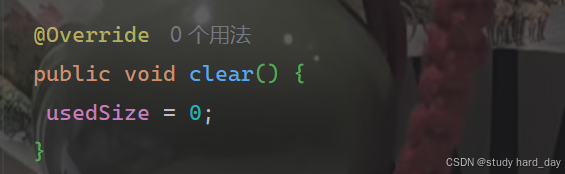
11.打印顺序表
,注意:该方法并不是顺序表中的方法,为了方便看测试结果给出的
我们只需要遍历数组中的之即可
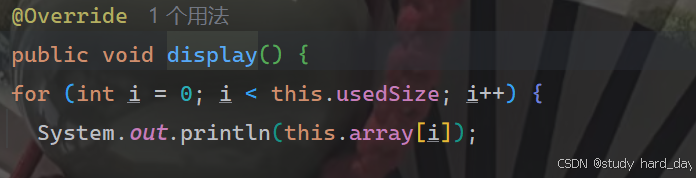
上述步骤都完成后,我们的顺序表就已经全部写好了,此时我们就可以操作顺序表了
四.总结:
在学习顺序表的过程中,我深刻体会到了数据结构设计的精妙之处。虽然顺序表的概念相对简单,但它却为我们理解更复杂的数据结构奠定了坚实的基础。通过实现顺序表的各种操作,我不仅提高了自己的编程能力,更重要的是培养了逻辑思维和解决问题的能力。在处理插入、删除操作中的边界条件和元素移动问题时,需要仔细思考各种可能的情况,这锻炼了我的严谨性和耐心。
同时,我也认识到在实际应用中选择合适的数据结构是多么关键。不能仅仅因为某个数据结构简单易用就盲目使用,而需要根据具体的需求和场景综合考虑其优缺点,权衡利弊后做出选择。顺序表作为数据结构家族中的一员,虽然有其局限性,但在特定的情况下却能发挥出独特的优势。
总之,顺序表的学习是我数据结构学习道路上的重要一步,我将带着从中学到的知识和经验,继续探索更复杂、更强大的数据结构,为解决更复杂的实际问题积累更多的工具和方法。