天干物燥,小心上火!
为了给大家降降温,于是我决定用Python来采集一点凉快的视频~


需要用到这些
环境
Python 3.10
Pycharm
nodejs
模块
requests
execjs
re
各位看官姥爷要是不想看文章,源码和详细视频讲解我都打包好了。
文末名片自取,点击直达文末

基本流程思路
一、数据来源分析
1、明确需求
-
明确采集的网站以及数据内容
-
数据:视频内容(视频链接)

2、抓包分析
通过浏览器开发者工具分析对应的数据位置
- 打开开发者工具(F12/右键点击检查选择network (网络))
- 刷新网页(让本网页的数据内容重新加载一遍)
- 通过关键字搜索找到对应数据位置
正常视频网站
开发者工具->network (网络)->media (媒体)->视频链接搜索数据对应位置所使用的关键字:视频链接中一段参数
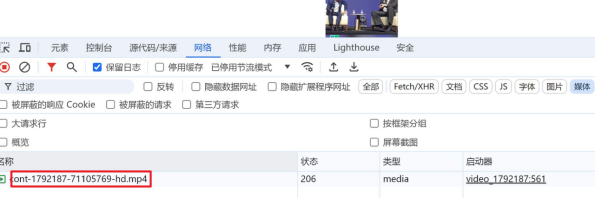
m3u8流媒体文件
把完整的视频内容,分割成N个是片段(xxx.ts), 整个视频片段都存在m3u8文件链接中。
- 搜索数据对应位置所使用的关键字: m3u8
既然所有视频片段都存在m3u8链接中, 为什么不直接请求这个链接获取视频呢?
-可以直接请求m3u8链接下载这个视频内容 (只能单个采集)
-如果你想要实现批量采集, 肯定分析链接生成返回位置。
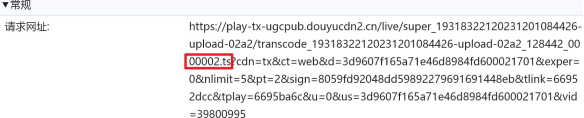
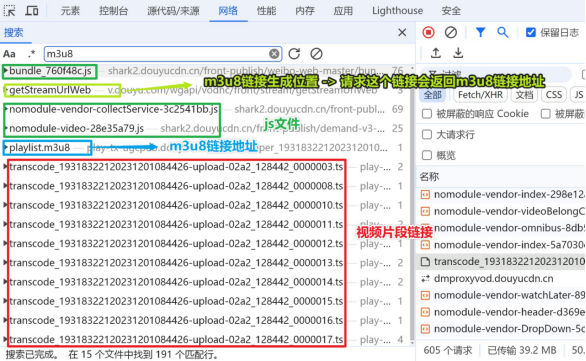
sign加密参数逆向分析
1、根据启动器定位加密位置
2、在代码对应位置, 进行断点调试分析
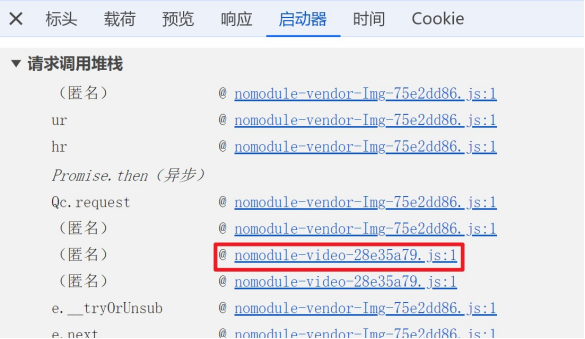
分析调了那个函数, 传入了什么参数, 返回了什么值。
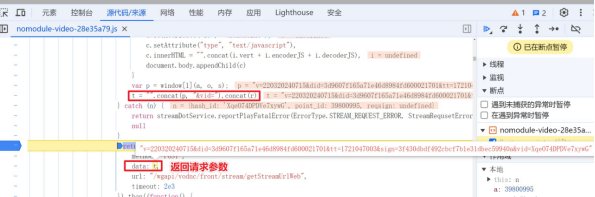
3、js代码函数, 在本地进行调试。
当我们复制js在本地调试, 大概率是会报错的。
原因是因为我们只是复制一部分代码内容 -> 肯定会缺失缺什么补什么
二、代码实现步骤
1、发送请求
模拟浏览器对于url地址发送请求
模拟浏览器
1.可以直接复制
- 开发者工具 -> 网络 -> 点击对应数据包 -> 标头 -> 请求标头(伪装模拟浏览器参数) ->
cookie ua referer
2.代码格式, 复制之后参数放在字典中 (构建完整的键值对)
dit = {'key': 'value'}
请求网址
通过第一步抓包分析找到链接地址, 直接复制即可。
发送请求
一般情况: 使用第三方模块 requests 请求
-请求方法: 开发者工具 -> 网络 -> 点击对应数据包 -> 标头 -> 常规
POST
-请求参数:
POST请求: 需要传递表单数据(请求参数)
在<载荷>中进行查看并且复制粘贴
基本代码
# 导入数据请求模块 import requests """发送请求"""
# 模拟浏览器
headers = {
# User-Agent 用户代理, 表示浏览器基本身份信息
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36'
}
# 请求网址
url = '某鱼wgapi/vodnc/front/stream/getStreamUrlWeb' # 请求参数
data = {
'v': '220320240715',
'did': '3d9607f165a71e46d8984fd600021701', 'tt': '1721045419',
'sign': '8fec57acbecb3f9d245ba4f1c91658da', 'vid':'XqeO74DPDVe7xywG',
}
# 发送请求
response = requests.post(url=url, data=data, headers=headers)
2、获取数据(获取服务器返回响应数据)
{'error': 7, 'msg': '权限不足', 'data': {}}
当我们获取响应数据:
-返回我们需要的数据 (没有问题)
-返回的数据不是我们想要 (被反爬了)
-没有返回数据, 返回空白 (被反爬了)
没得到数据:
1.请求头伪装不够 (加cookie 加防盗链)
2.请求参数/请求头/cookie可能存在加密
基本代码
# 获取响应json数据
json_data = response.json()
"""解析数据: 提取我们需要的数据内容"""
# 提取m3u8链接地址
m3u8_url = json_data['data']['thumb_video']['super']['url']
"""第二次发送请求+获取数据"""
m3u8 = requests.get(url=m3u8_url, headers=headers).text
3、解析数据
提取我们需要的数据内容
# 提取ts链接
ts_list = re.findall(',\n(.*?)\n#', m3u8)
# for循环遍历, 提取列表里面元素
for ts in ts_list:
# 构建完整ts链接
ts_url = '某鱼/live/super_5986523120230730142323-upload-5d87/' + ts
4、保存数据
获取视频内容,保存本地文件夹中。
# 获取每个视频片段内容
ts_content = requests.get(url=ts_url, headers=headers).content
# 保存数据
with open('video\\舞蹈视频.mp4', mode='ab') as f:
# 写入数据
f.write(ts_content)
print(ts_url)
5、批量下载思路
1.通过列表页面抓包分析找到视频ID对应接口
API接口:https://v.某鱼.com/wgapi/vod/center/getAuthorvideosByview?
page=2&limit=30&cid2=0&tag2=0&up_id=Kpdxx1n02daW
2.正常代码,获取视频ID(数字+字母)
hash id title vid
3.请求视频播放页面链接,获取加密js代码
https://v.某鱼.com/show/{hash_id}
4.延用单个视频采集的代码即可
好了,今天分享就到这结束了,我要继续去凉快凉快了~
