超详细的canal使用总结
canal的介绍
canal,译意为水道/管道/沟渠,从官网的介绍中可以知道,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
这是一张官网提供的示意图:
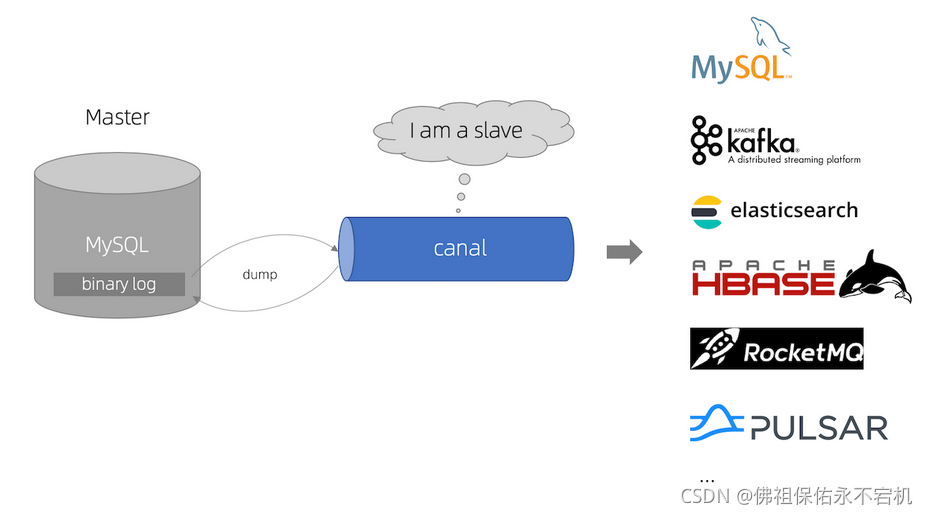
官网的解释最权威,我就直接引用一下官网的原话,另,附上官网地址:https://github.com/alibaba/canal
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
MySQL主备复制原理
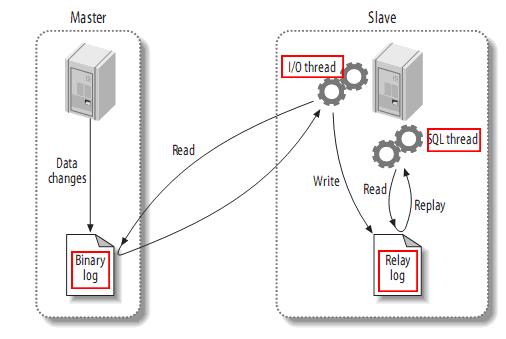
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
canal的部署
目标
利用canal实现mysql->kafka场景。
环境准备
在开始之前,我们要先准备好利用canal实现mysql->kafka场景所需要的环境,包括安装mysql,kafka,zookeeper。官方想得还是很周到的,专门提供了安装方式。
- zookeeper安装方式链接:https://github.com/alibaba/canal/wiki/Zookeeper-QuickStart
- kafka安装方式链接:https://github.com/alibaba/canal/wiki/Kafka-QuickStart
- mysql的安装方式不知道是不是我眼花,没在官网上找到,所以自己找了篇文章:https://www.cnblogs.com/wangpeng00700/p/13539856.html
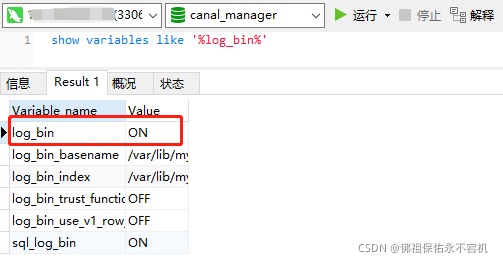
当然光是这些还不够,因为canal是基于mysql增量日志解析来实现的同步,mysql必须要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式。如果之前已经安装了mysql,不清楚是否开启了的,可以通过以下命令查看。如果为ON,就表示已经开启了。我这里为了方便直接用Navicat进行查看了。
show variables like '%log_bin%'
如果没有,那么需要调整一下/etc/my.cnf ,my.cnf 中配置如下。
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant。但是我为了方便,下面的例子是直接用的root用户,不建议学我。
-- 创建canal的用户
CREATE USER canal IDENTIFIED BY 'canal';
-- 进行授权
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
下载安装包
本次例子以1.1.5版本为例,首先从官网上下载canal.deployer-1.1.5.tar.gz和canal.admin-1.1.5.tar.gz两个包,canal.admin-1.1.5.tar.gz是canal的核心之一,canal-admin设计上是为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,方便更多用户快速和安全的操作。canal有两种使用方式:1、独立部署 2、内嵌到应用中。 而deployer模块主要用于独立部署canal server,这次的例子采用独立部署的方式。
安装包官网下载地址:https://github.com/alibaba/canal/releases。
安装包下载完成后,将它分别解压到系统对应的目录下,例如:/opt/lxf/canal,因为这次除了admin外还有deployer,所以还需在/opt/lxf/canal目录下再分别建admin和deployer两个目录。找到安装包,分别使用tar zxvf canal.admin-1.1.5.tar.gz -C /opt/lxf/canal/admin和tar zxvf canal.deployer-1.1.5.tar.gz -C /opt/lxf/canal/deployer命令将其解压到对应的目录下。
admin解压后可以看到4个文件夹:bin、conf、lib、logs。
deployer解压后可以看到5个文件夹:bin、conf、lib、logs、plugin。
配置admin
先进入到admin下面的conf中,找到application.yml,通过vi编辑器修改里面的内容。
server:
port: 8089 # 配置端口
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 192.168.1.121:3306 # 配置数据库ip和端口
database: canal_manager # 配置数据库名
username: root # 配置登录用户
password: 123456 # 配置登录密码
driver-class-name: com.mysql.jdbc.Driver # 配置驱动
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
# 配置链接canal-server的admin用户账号和密码
canal:
adminUser: admin
adminPasswd: admin
然后同样在conf目录下,可以找一个canal_manager.sql文件,这里面是canal需要执行的SQL脚本,它可以帮助我们初始化数据库。使用命令:mysql -h主机地址 -u用户名 -p用户密码,可连接mysql数据库。连接上之后再使用source命令执行canal_manager.sql文件。例如:
# 连接mysql数据库
mysql -h 127.0.0.1 -u root -p 123456
# 导入初始化SQL
source /opt/lxf/canal/admin/conf/canal_manager.sql
如果linux上不方便操作,也可以将canal_manager.sql文件拷贝到windows系统里,用数据库管理工具(例如:Navicat)执行SQL脚本。
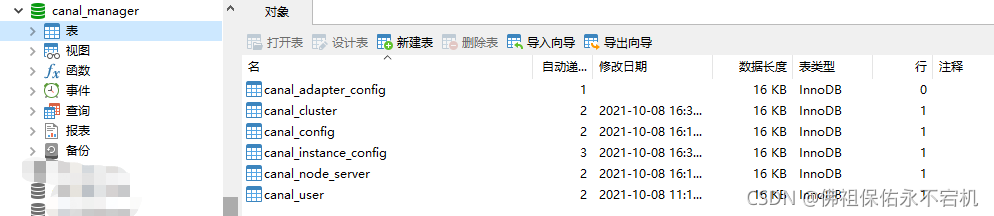
执行了SQL脚本后,可以看到数据库里已经完成了初始化。
当确认无误后,进入到admin下的bin目录,执行命令./startup.sh,通过脚本启动。这个时候admin已经启动起来了,如果想要停止的话,可执行./stop.sh。
注意:执行前,需要先安装jdk,因为canal是基于java实现的。可自己去官网下载tar.gz包进行安装,或者系统版本是CentOS、Fedora或RedHat这样支持yum的,可执行安装命令:yum install -y java-1.8.0-openjdk-devel.x86_64。安装完成后,输入java -version验证,如下图表示安装成功。

配置deployer
先进入deployer下的conf目录下,找到canal.properties文件,使用vi编辑器修改。
#################################################
######### common argument #############
#################################################
# tcp bind ip
# canal server绑定的本地IP信息,如果不配置,默认选择一个本机IP进行启动服务
canal.ip =
# register ip to zookeeper
# canal server注册到外部zookeeper、admin的ip信息 (针对docker的外部可见ip)
canal.register.ip =
# canal server提供socket服务的端口
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
# admin管理指令链接端口
canal.admin.port = 11110
# admin管理指令链接的ACL配置,用户名
canal.admin.user = admin
# admin管理指令链接的ACL配置,这个密码是admin,这是密码加密后的字符串
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
# canal server链接zookeeper集群的链接信息,有多个时以,隔开
canal.zkServers =
# flush data to zk
# canal持久化数据到zookeeper上的更新频率,单位毫秒
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# server模式,可选项,包含tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = tcp
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
# canal内存store中可缓存buffer记录数,需要为2的指数
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
# 内存记录的单位大小,默认1KB,和buffer.size组合决定最终的内存使用大小
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
# canal内存store中数据缓存模式
# 1. ITEMSIZE : 根据buffer.size进行限制,只限制记录的数量
# 2. MEMSIZE : 根据buffer.size * buffer.memunit的大小,限制缓存记录的大小
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
# 是否开启心跳检查
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
# 心跳检查sql,与上面的开启联合使用
canal.instance.detecting.sql = select 1
# 心跳检查频率,单位秒
canal.instance.detecting.interval.time = 3
# 心跳检查失败重试次数
canal.instance.detecting.retry.threshold = 3
# 心跳检查失败后,是否开启自动mysql自动切换
# 说明:比如心跳检查失败超过阀值后,如果该配置为true,canal就会自动链到mysql备库获取binlog数据
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
# canal发生mysql切换时,在新的mysql库上查找binlog时需要往前查找的时间,单位秒
# 说明:mysql主备库可能存在解析延迟或者时钟不统一,需要回退一段时间,保证数据不丢
canal.instance.fallbackIntervalInSeconds = 60
# network config
# 网络链接参数,SocketOptions.SO_RCVBUF
canal.instance.network.receiveBufferSize = 16384
# 网络链接参数,SocketOptions.SO_SNDBUF
canal.instance.network.sendBufferSize = 16384
# 网络链接参数,SocketOptions.SO_TIMEOUT
canal.instance.network.soTimeout = 30
# binlog filter config
# 是否使用druid处理所有的ddl解析来获取库和表名
canal.instance.filter.druid.ddl = true
# 是否忽略dcl语句
canal.instance.filter.query.dcl = false
# 是否忽略dml语句
canal.instance.filter.query.dml = false
# 是否忽略ddl语句
canal.instance.filter.query.ddl = false
# 是否忽略binlog表结构获取失败的异常(主要解决回溯binlog时,对应表已被删除或者表结构和binlog不一致的情况)
canal.instance.filter.table.error = false
# 是否dml的数据变更事件(主要针对用户只订阅ddl/dcl的操作)
canal.instance.filter.rows = false
# 是否忽略事务头和尾,比如针对写入kakfa的消息时,不需要写入
canal.instance.filter.transaction.entry = false
# 是否忽略插入
canal.instance.filter.dml.insert = false
# 是否忽略修改
canal.instance.filter.dml.update = false
# 是否忽略删除
canal.instance.filter.dml.delete = false
# binlog format/image check
# 支持的binlog format格式列表
canal.instance.binlog.format = ROW,STATEMENT,MIXED
# 支持的binlog image格式列表
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
# ddl语句是否单独一个batch返回(比如下游dml/ddl如果做batch内无序并发处理,会导致结构不一致)
canal.instance.get.ddl.isolation = false
# parallel parser config
# 是否开启binlog并行解析模式(串行解析资源占用少,但性能有瓶颈, 并行解析可以提升近2.5倍+)
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
# binlog并行解析的异步ringbuffer队列(必须为2的指数)
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
# 是否开启tablemeta的tsdb能力
canal.instance.tsdb.enable = true
# 主要针对h2-tsdb.xml时对应h2文件的存放目录,默认为conf/xx/h2.mv.db
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
# jdbc url的配置
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
# jdbc username的配置
canal.instance.tsdb.dbUsername = canal
# jdbc password的配置
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
# 转储快照间隔时间,默认24小时
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
# 清除快照过期时间,默认15天
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
# 当前server上部署的instance列表
canal.destinations = example
# conf root dir
# conf/目录所在的路径
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
# 开启instance自动扫描
canal.auto.scan = true
# instance自动扫描的间隔时间,单位秒
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
# 全局的tsdb配置方式的组件文件
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
# 全局配置加载方式
canal.instance.global.mode = spring
# 全局lazy模式
canal.instance.global.lazy = false
# 全局的manager配置方式的链接信息
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
# 全局的spring配置方式的组件文件
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
### 以下为MQ的相关配置,配置具体含义根据对应的MQ解释,下面以kafka为例说明
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
# 是否为json格式 如果设置为false,对应MQ收到的消息为protobuf格式,需要通过CanalMessageDeserializer进行解码
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
# 配置单个或多个kafka访问地址(支持集群)
kafka.bootstrap.servers = 127.0.0.1:9092
# kafka中的acks参数
kafka.acks = all
# kafka服务端指定压缩算法的参数compression.type
kafka.compression.type = none
# kafka批处理大小
kafka.batch.size = 16384
# 延时
kafka.linger.ms = 1
# kafka最大请求量
kafka.max.request.size = 1048576
# 内存缓冲的大小
kafka.buffer.memory = 33554432
# kafka重试机制中的max.in.flight.requests.per.connection参数
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
# 是否开启kafka的kerberos认证
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
因为我们的目标是实现mysql->kafka场景,只需调整部分配置即可,以下是我自己的配置。
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.serverMode = kafka
canal.mq.flatMessage = true
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 192.168.1.112:9092
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
当确认无误后,进入到deployer下的bin目录,执行命令./startup.sh,通过脚本启动。这个时候deployer已经启动起来了,如果想要停止的话,可执行./stop.sh。
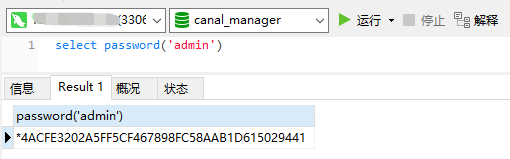
配置里面的canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441对于不了解的人可能有点懵,其实很简单,就是mysql生成的密码,对应着admin用户的配置。运行select password('admin')得到密码,把前面的*去掉,就是4ACFE3202A5FF5CF467898FC58AAB1D615029441了。
验证
到了这一步,canal基本上已经没什么问题了,这个时候就需要去验证一下。首先进入logs目录下,查看对应的admin和deployer日志,日志正常表示启动过程无误。这时就可以访问canal的后台了,在浏览器中输入:http://ip:8089/ 访问,默认账号:admin,密码:123456。这默认的账号密码是我们执行canal_manager.sql文件的时候创建的,其中有一段sql语句是这样的。

如果需要,我们可以自己修改它的SQL脚本,或者在执行后,在数据库里新增或修改canal_user表里的用户数据。通过查看源码可以知道,密码的核心加密方式是SHA-1,进行加密的源码如下:
public static final String scrambleGenPass(byte[] pass) throws NoSuchAlgorithmException {
MessageDigest md = MessageDigest.getInstance("SHA-1");
byte[] pass1 = md.digest(pass);
md.reset();
byte[] pass2 = md.digest(pass1);
return SecurityUtil.byte2HexStr(pass2);
}
/**
* bytes转换成十六进制字符串
*/
public static String byte2HexStr(byte[] b) {
StringBuilder hs = new StringBuilder();
for (byte value : b) {
String hex = (Integer.toHexString(value & 0XFF));
if (hex.length() == 1) {
hs.append("0" + hex);
} else {
hs.append(hex);
}
}
return hs.toString();
}
在知道了它的加密方式的情况下,我们可以自己调整用户信息。有需要的话,可以自己下载源码调整加密方式后打包重新部署。
注意:若无法访问,可尝试关闭防火墙后再试:systemctl stop firewalld。另,启动防火墙:systemctl start firewalld,查看防火墙状态:systemctl status firewalld。
核心概念
打开页面可以看到,canal-admin提供了集群、server和instance管理。
canal-admin的核心模型主要有:
- instance,对应canal-server里的instance,一个最小的订阅mysql的队列
- server,对应canal-server,一个server里可以包含多个instance
- 集群,对应一组canal-server,组合在一起面向高可用HA的运维
简单解释:
- instance因为是最原始的业务订阅诉求,它会和 server/集群 这两个面向资源服务属性的进行关联,比如instance A绑定到server A上或者集群 A上,
- 有了任务和资源的绑定关系后,对应的资源服务就会接收到这个任务配置,在对应的资源上动态加载instance,并提供服务
- 动态加载的过程,有点类似于之前的autoScan机制,只不过基于canal-admin之后可就以变为远程的web操作,而不需要在机器上运维配置文件
- 将server抽象成资源之后,原本canal-server运行所需要的canal.properties/instance.properties配置文件就需要在web ui上进行统一运维,每个server只需要以最基本的启动配置 (比如知道一下canal-admin的manager地址,以及访问配置的账号、密码即可)
集群管理
在集群管理下新建一个集群,ZK地址即为zookeeper的地址。
配置项:
- 修改集群/删除集群,属于基本的集群信息维护和删除
- 主配置,主要是指集群对应的canal.properties配置,设计上一个集群的所有server会共享一份全局canal.properties配置 (如果有个性化的配置需求,可以创建多个集群)
- 查看server,主要是指查看挂载在这个集群下的所有server列表

如果要自己修改主配置里的canal.properties,可点击载入模板按钮,之后会自动生成默认的一套模板,这套默认模板其实就是admin下conf目录中的canal-template.properties。在这里修改完成后,点击保存按钮即可。canal.properties的配置即可应用到当前集群上了。
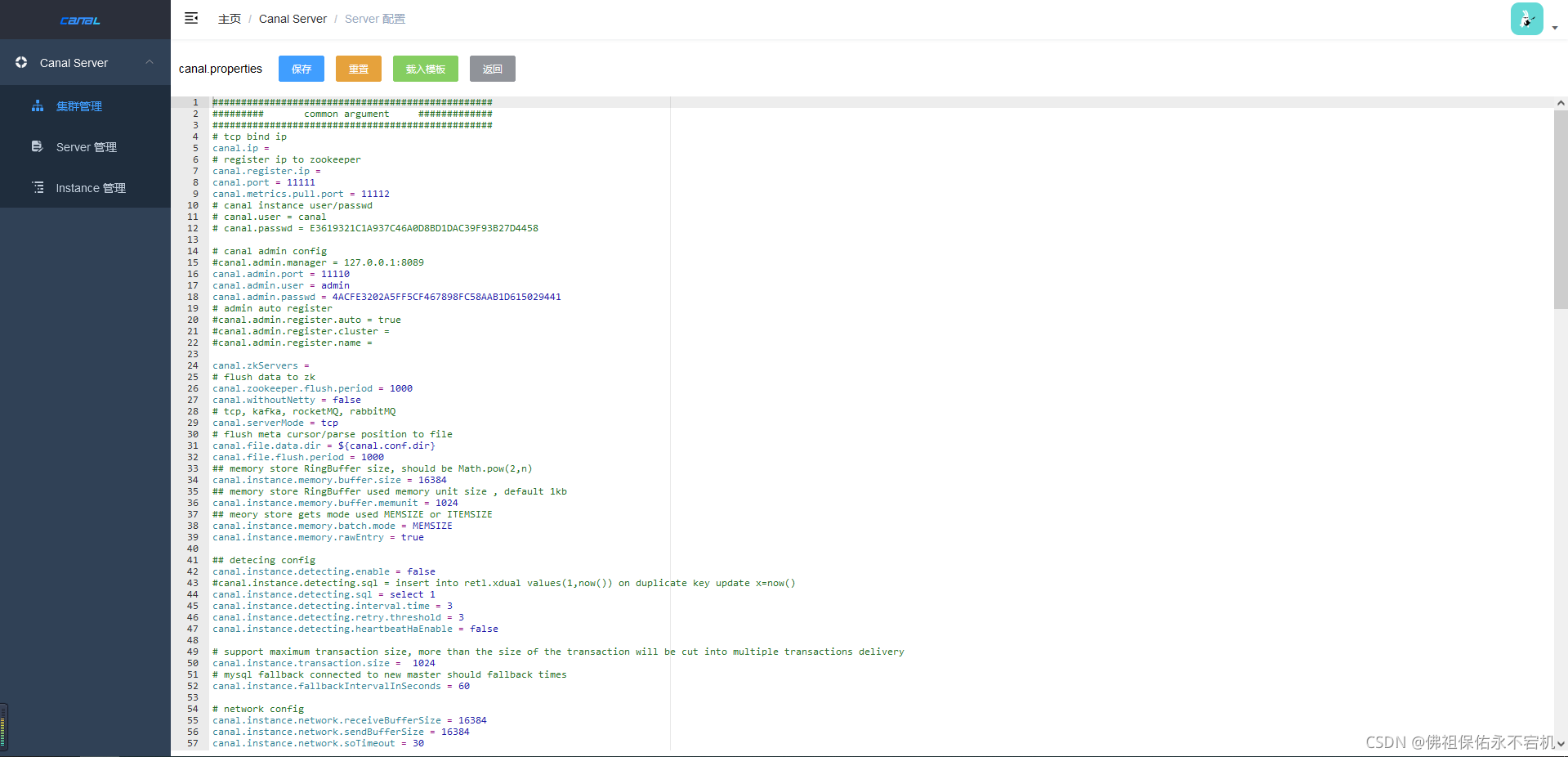
Server管理
在server管理页面中,点击新建Server按钮,创建一个或多个server。
配置项:
- 所属集群,可以选择为单机 或者 集群。一般单机Server的模式主要用于一次性的任务或者测试任务
- Server名称,唯一即可,方便自己记忆
- Server Ip,机器ip
- admin端口,canal 1.1.4版本新增的能力,会在canal-server上提供远程管理操作,默认值11110
- tcp端口,canal提供netty数据订阅服务的端口
- metric端口, promethues的exporter监控数据端口 (未来会对接监控)
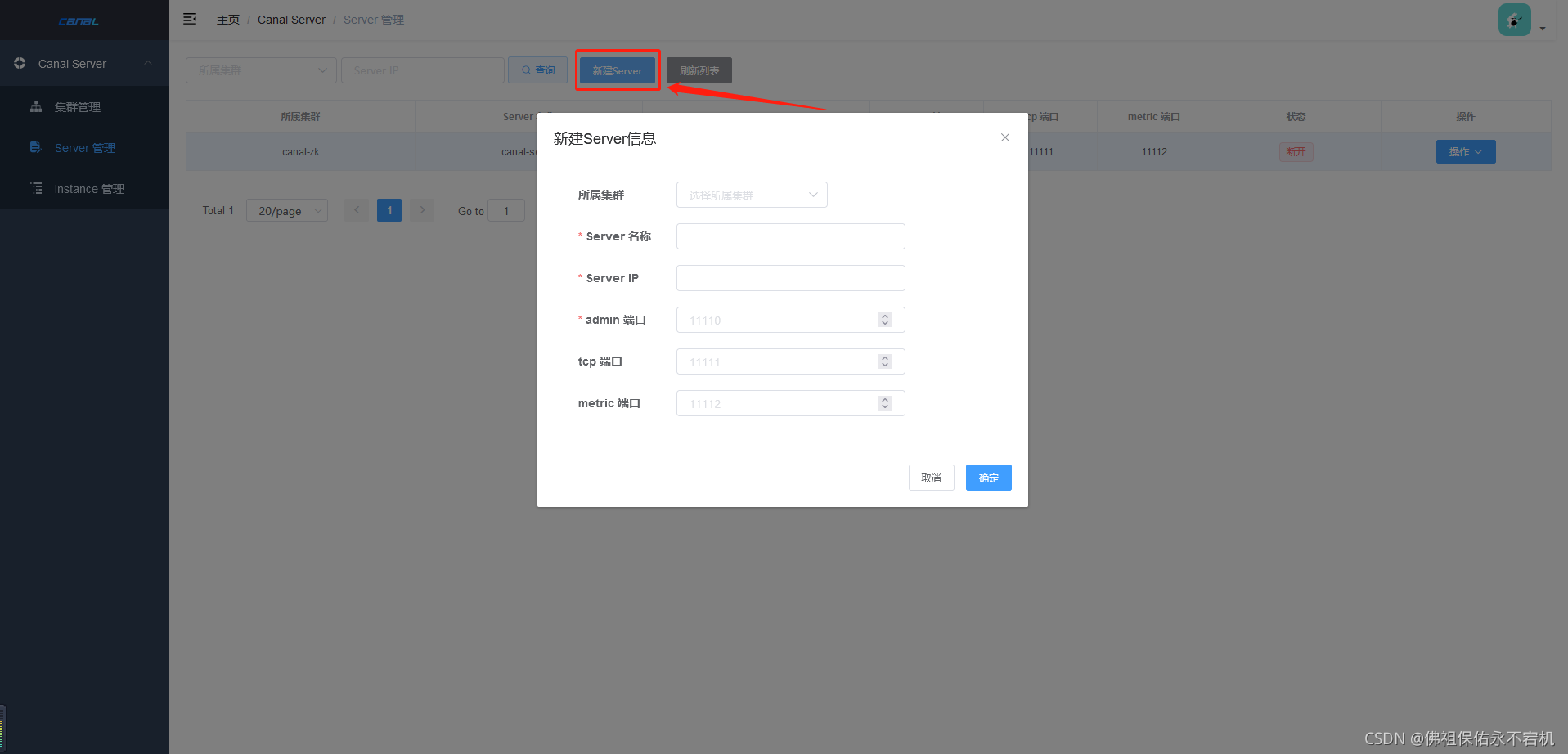
在完成server配置后,我们可以点击操作,对server进行变更。
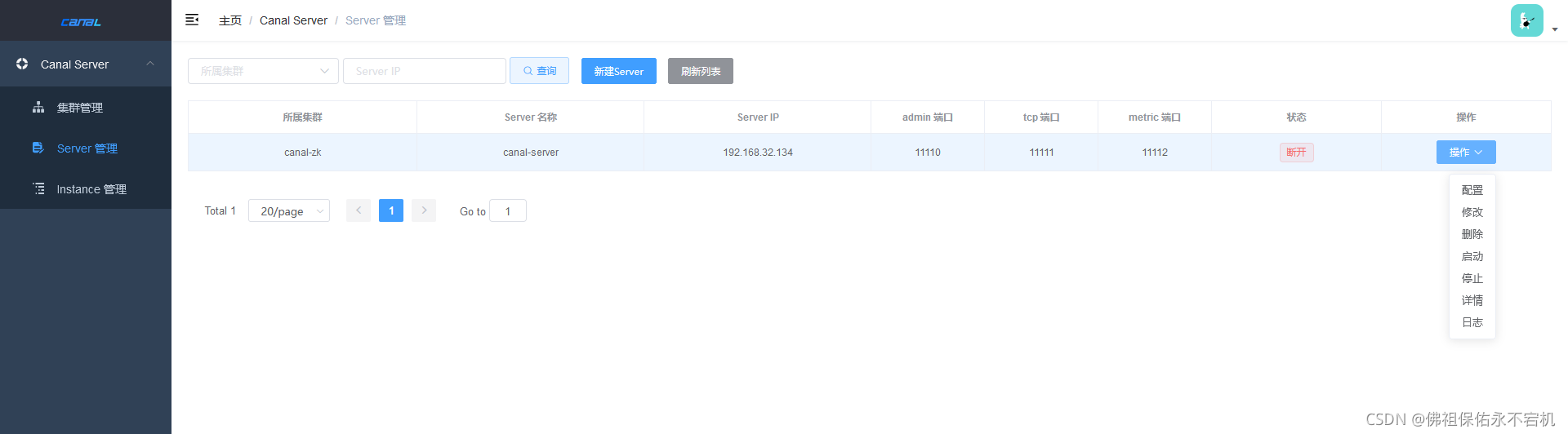
注意:1.在配置了集群的情况下,不允许单独修改server。2.状态为断开时,表示无法连接服务,需检查服务是否正常。并且这时是无法进行启动或停止的操作。


正常情况下,状态栏应该是启动。如果状态为停止,可在操作下点击启动尝试启动,如果状态为断开,请查看logs下的日志信息排查问题。
Instance管理
在Instance管理的管理页面中点击新建Instance按钮,创建一个Instance。
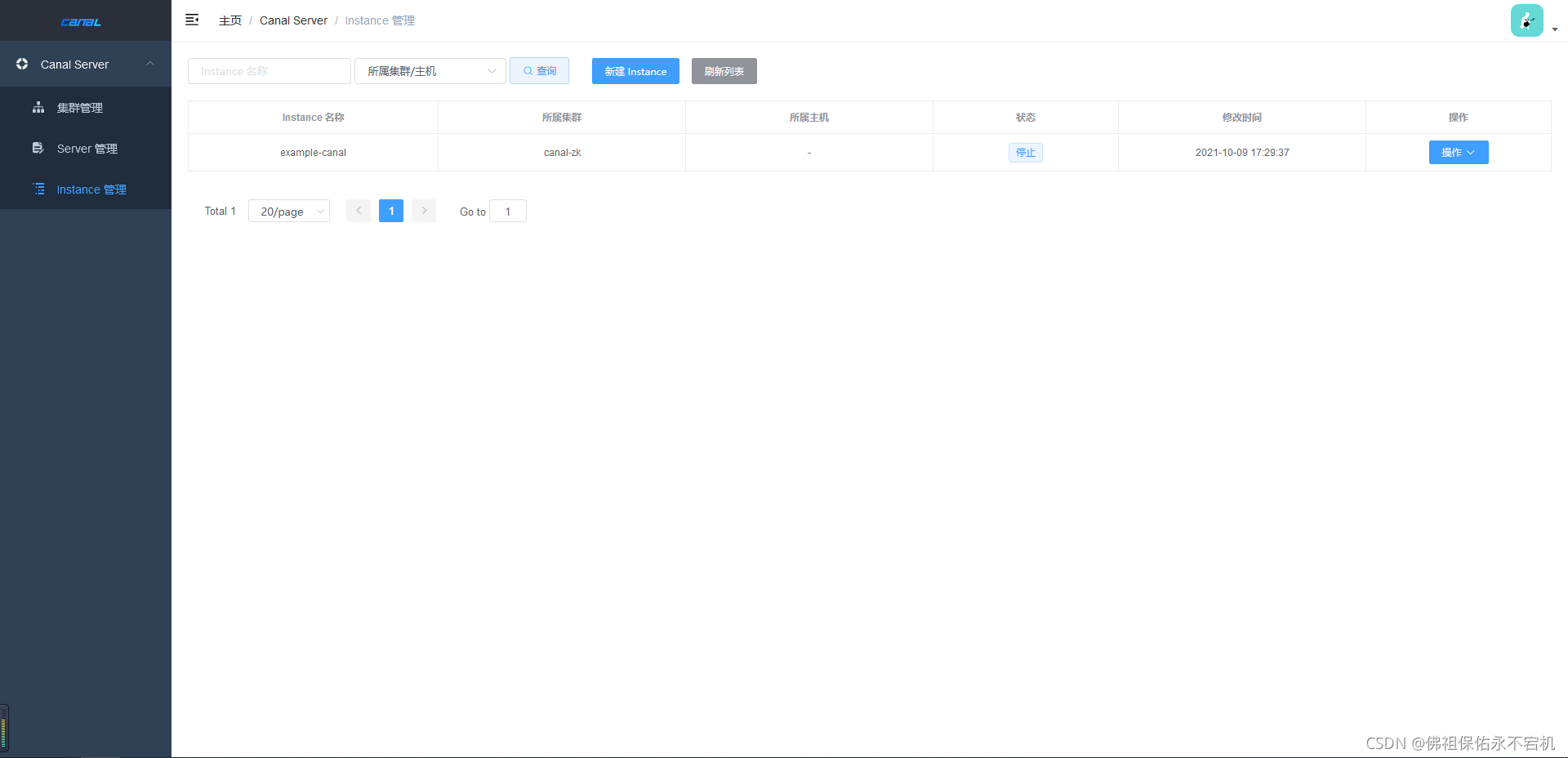
配置项:
- 修改,主要就是维护instance.properties配置,做了修改之后会触发对应单机或集群server上的instance做动态reload
- 删除,相当于直接执行instance stop,并执行配置删除
- 启动/停止,对instance进行状态变更,做了修改会触发对应单机或集群server上的instance做启动/停止操作
- 日志,主要针对instance运行状态时,获取对应instance的最后100行日志,比如example/example.log
正常情况下,状态栏应该是启动。如果未启动,可在操作下点击启动尝试启动。
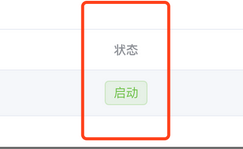
点击会跳转到这个页面,点击载入模板按钮会加载一套默认的instance.properties配置模板,这套默认模板其实就是admin下conf目录中的instance-template.properties。在导入的模板中修改成我们需要的配置。然后选择我们的所属集群,填写Instance名称,点击保存即可。
这一步最主要的就是关联我们的集群/server(单机)以及维护instance.properties。我自己的配置如下,因为是写的一个例子,所以配置比较简单,也不规范,后期可以根据自己的情况调整。
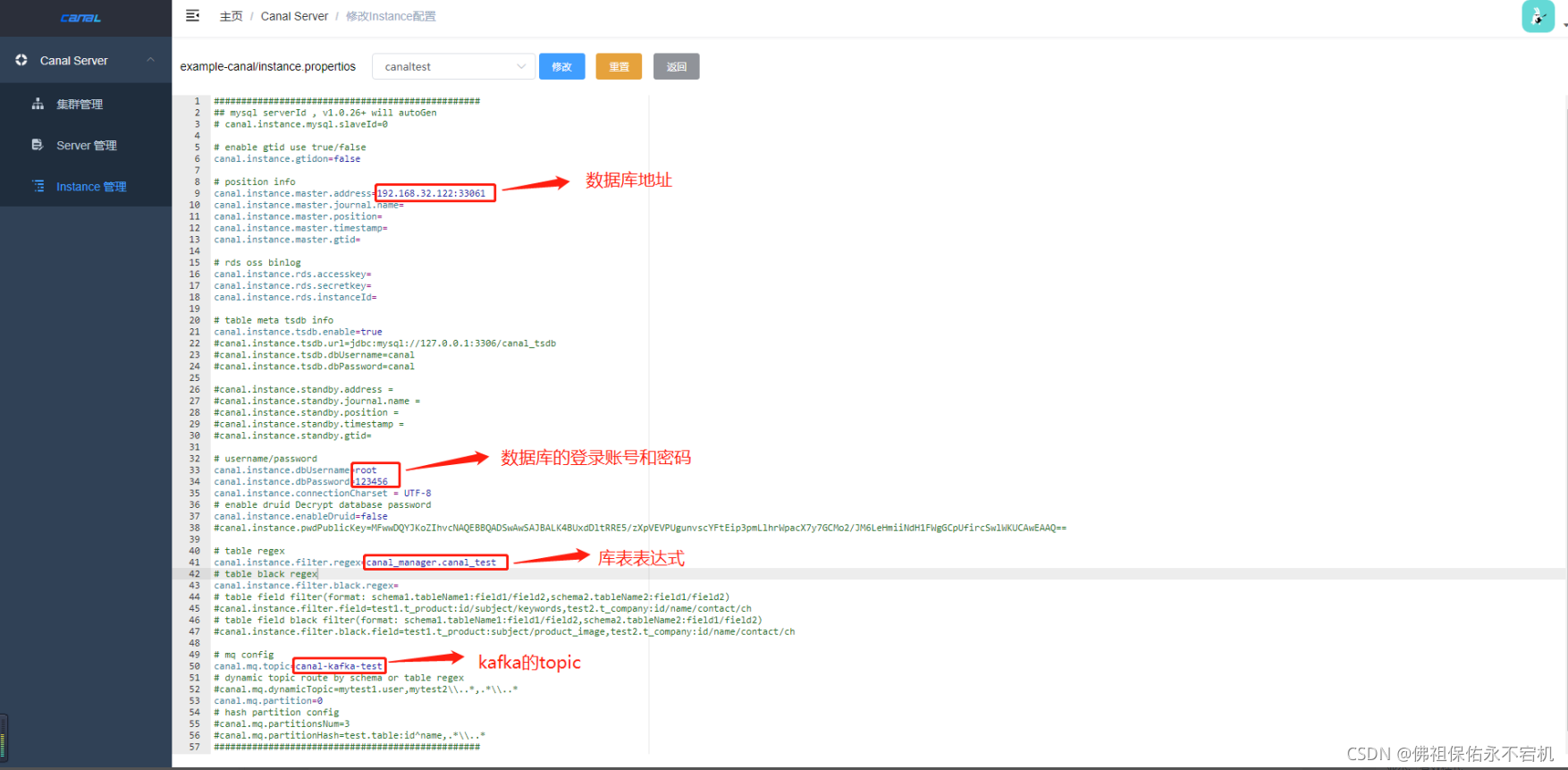
其中,canal.instance.filter.regex的配置是mysql 数据解析关注的表,使用Perl正则表达式。多个正则之间以逗号(,)分隔,转义符需要双斜杠(\) 。
常见例子:
-
所有表:.* or .\…
-
canal schema下所有表: canal\…*
-
canal下的以canal打头的表:canal\.canal.*
-
canal schema下的一张表:canal.test1
-
多个规则组合使用:canal\…*,mysql.test1,mysql.test2 (逗号分隔)
注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
另外,canal.mq.topic配置中可以写之前不存在的topic,这样它就会帮我们创建一个新的topic。我们可以结合自己的业务需求,设置匹配规则,建议MQ开启自动。如果像我例子中那样,有可能有时候不够用,多topic的话可以用canal.mq.dynamicTopic,来看看官方的解释。
canal.mq.dynamicTopic 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema 或 schema.table,多个配置之间使用逗号或分号分隔
- 例子1:test\.test 指定匹配的单表,发送到以test_test为名字的topic上
- 例子2:.\… 匹配所有表,则每个表都会发送到各自表名的topic上
- 例子3:test 指定匹配对应的库,一个库的所有表都会发送到库名的topic上
- 例子4:test\…* 指定匹配的表达式,针对匹配的表会发送到各自表名的topic上
- 例子5:test,test1\.test1,指定多个表达式,会将test库的表都发送到test的topic上,test1\.test1的表发送到对应的test1_test1 topic上,其余的表发送到默认的canal.mq.topic值
为满足更大的灵活性,允许对匹配条件的规则指定发送的topic名字,配置格式:topicName:schema 或 topicName:schema.table
- 例子1: test:test\.test 指定匹配的单表,发送到以test为名字的topic上
- 例子2: test:.\… 匹配所有表,因为有指定topic,则每个表都会发送到test的topic下
- 例子3: test:test 指定匹配对应的库,一个库的所有表都会发送到test的topic下
- 例子4:testA:test\…* 指定匹配的表达式,针对匹配的表会发送到testA的topic下
- 例子5:test0:test,test1:test1\.test1,指定多个表达式,会将test库的表都发送到test0的topic下,test1\.test1的表发送到对应的test1的topic下,其余的表发送到默认的canal.mq.topic值
另外,多分区,可以使用canal.mq.partitionsNum、canal.mq.partitionHash,它们主要控制是否多分区以及分区的partition的路由计算,针对命中条件的可以做到按表级做分区、pk级做分区等,canal.mq.partitionsNum是用来设置散列模式的分区数,而canal.mq.partitionHash和canal.mq.dynamicTopic类似,来看看官方的解释。
canal.mq.partitionHash 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔
- 例子1:test\.test:pk1^pk2 指定匹配的单表,对应的hash字段为pk1 + pk2
- 例子2:.\…:id 正则匹配,指定所有正则匹配的表对应的hash字段为id
- 例子3:.\…: p k pk pk 正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找)
- 例子4: 匹配规则啥都不写,则默认发到0这个partition上
- 例子5:.\… ,不指定pk信息的正则匹配,将所有正则匹配的表,对应的hash字段为表名
- 按表hash: 一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题)
- 例子6: test\.test:id,.\…* , 针对test的表按照id散列,其余的表按照table散列
注意:大家可以结合自己的业务需求,设置匹配规则,多条匹配规则之间是按照顺序进行匹配(命中一条规则就返回)
更多详细信息可查看官网对支持的MQ的解释:https://github.com/alibaba/canal/wiki/Canal-Kafka-RocketMQ-QuickStart
最后如何验证我们的instance配置是否生效,可以在我们的deployer下的conf目录下,看到一个与我们创建的instance同名的文件夹,我们刚刚创建的instance名称为example-canal,这个文件夹在最开始的时候肯定没有的,而是在我们创建完这个instance后生成的,这时就表明我们的instance创建成功了。

创建测试表
为了测试,我就在canal_manger库下创建了一张测试用的表。这张表就是刚刚在instance.properties中库表表达式里指向的表,SQL脚本如下,当然这只是测试,做法并不规范。
CREATE TABLE `canal_test` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`context` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '内容',
`insert_time` datetime DEFAULT NULL COMMENT '插入时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='canal测试表';
在创建了表之后,我们可以通过新增一条数据去测试我们刚刚的部署和配置是否成功。
INSERT INTO `canal_manager`.`canal_test`(`id`, `context`, `insert_time`) VALUES (8, '测试', '2021-10-09 15:04:41');
完成验证
最后一步就是查看kafka的数据,看看mysql中添加的数据是否真的会传到kafka中。查看kafka数据的方式有很多,我这里通过一个可视化工具kafka tool进行查看,安装也很简单,选择一个本地安装目录,然后下一步下一步就完事了。这里附上官网下载地址:https://www.kafkatool.com/download.html。
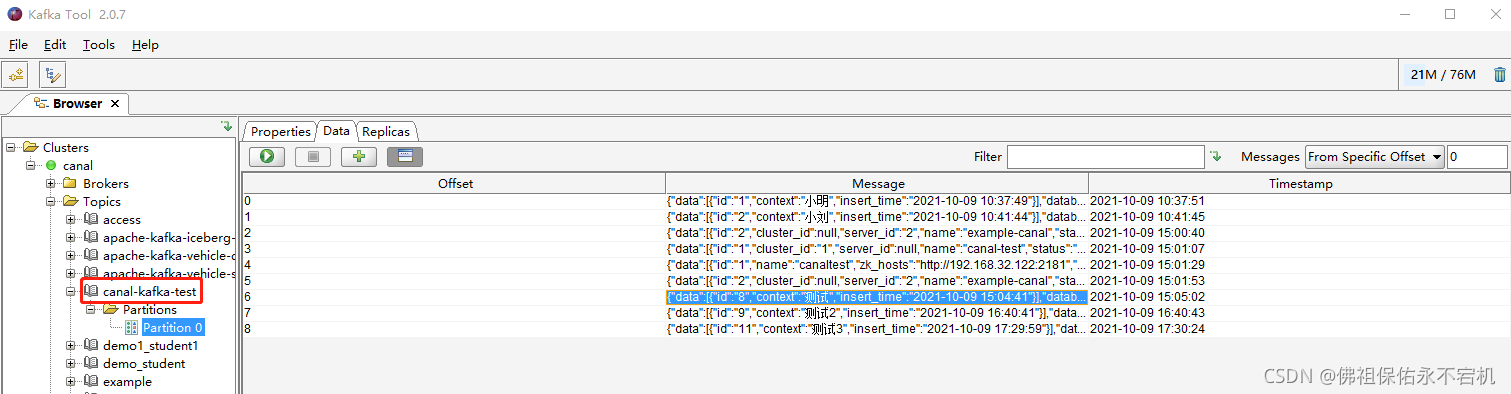
通过kafka tool工具可以看到,里面有一个canal-kafka-test的topic,这个topic是我之前没有的,也就是说instance.properties配置已经生效了,它已经帮我创建好了。另外可以看到canal-kafka-test的下面有我们之前在mysql数据库中添加的数据,当然我之前测试时就已经反复添加和删除过多条数据了,所以截图里可以看到其实是有8条数据的。
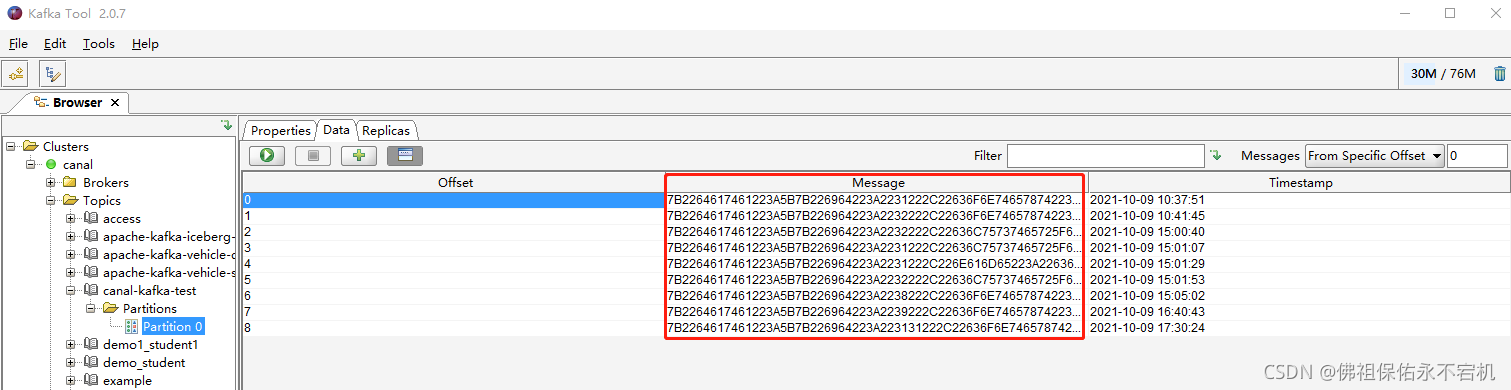
如果在使用kafka tool工具的时候发现有这种情况,message中的数据不像是我们原本的数据,那可以修改一下这里的配置,将点击canal-kafka-test,把key和message对应的content types都从Byte Array改为String就可以了。
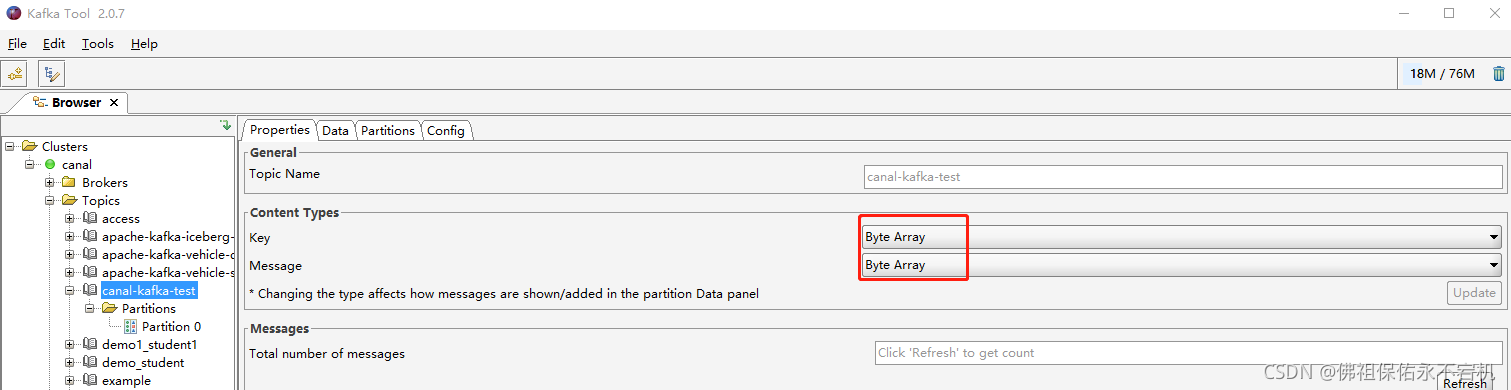
到这里,基本上已经没有什么问题了,验证成功。
canal客户端
canal提供了canal客户端API,可以帮助我们连接canal服务,消费数据。由于我的例子里没有要用到客户端的地方,并且官方提供了完整的API和样例代码。我直接上链接:https://github.com/alibaba/canal/wiki/ClientExample。
全量同步
在canal做增量同步之前,我们一般需要做一次全量同步,不然以前的数据就没有同步过来。canal也提供了全量同步的方法,目前我找到的有两种:1.在instance.properties中是可以进行配置的,2.通过ClientAdapter进行全量同步。
ClientAdapter
ClientAdapter顾名思义,就是canal提供的适配器,相当于客户端,会从canal-server中获取数据,然后对数据进行同步,增量同步和全量同步都可以用它。具体什么意思呢,就是说我们可以偷个懒,不用通过ClientAPI去编写我们的客户端了,直接拿着ClientAdapter改一改里面的配置就能用,当然,个性化需求得需要我们自己编写客户端去实现。
在使用前,先从官网中下载下来。如图所示,下载canal.adapter-1.1.5.tar.gz,安装包官网下载地址:https://github.com/alibaba/canal/releases。
下载后我们可以解压出来看看,找到adapter下的conf目录,可以看到1.1.5版本是支持的哪几种,有es、hbase、kudu、rdb(关系型数据库)。
然后我们可以看看application.yml里面是怎么样的。
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
#客户端消费模式,对应下面的consumerProperties
mode: tcp #tcp kafka rocketMQ rabbitMQ
#是否以json字符串传递数据,仅对mq生效
flatMessage: true
#集群配置
zookeeperHosts:
#每次同步的批数量
syncBatchSize: 1000
#重试次数,-1为无限次
retries: 0
#配置超时
timeout:
#下面是安全密钥配置
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer 连接canal server的配置
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer 连接kafka的配置
kafka.bootstrap.servers: 127.0.0.1:9092
kafka.enable.auto.commit: false
kafka.auto.commit.interval.ms: 1000
kafka.auto.offset.reset: latest
kafka.request.timeout.ms: 40000
kafka.session.timeout.ms: 30000
kafka.isolation.level: read_committed
kafka.max.poll.records: 1000
# rocketMQ consumer 连接rocketMQ的配置
rocketmq.namespace:
rocketmq.namesrv.addr: 127.0.0.1:9876
rocketmq.batch.size: 1000
rocketmq.enable.message.trace: false
rocketmq.customized.trace.topic:
rocketmq.access.channel:
rocketmq.subscribe.filter:
# rabbitMQ consumer 连接rabbitMQ的配置
rabbitmq.host:
rabbitmq.virtual.host:
rabbitmq.username:
rabbitmq.password:
rabbitmq.resource.ownerId:
#数据源
# srcDataSources:
# defaultDS:
# url: jdbc:mysql://127.0.0.1:3306/mytest?useUnicode=true
# username: root
# password: 121212
#下面开始canal适配器的配置
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1 #一份数据可被多个groupId消费,同groupId并发执行,同一groupId内的adapters顺序执行
outerAdapters: #输出配置
- name: logger #日志
#输出到关系型数据库,也就是rdb
# - name: rdb
# key: mysql1 #这个是输出到mysql
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password: 121212
# - name: rdb
# key: oracle1 #这个是输出到oracle
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1 #这个是输出到postgres
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000
# - name: hbase #这个是输出到hbase
# properties:
# hbase.zookeeper.quorum: 127.0.0.1
# hbase.zookeeper.property.clientPort: 2181
# zookeeper.znode.parent: /hbase
# - name: es #这个是输出到es
# hosts: 127.0.0.1:9300 # 127.0.0.1:9200 for rest mode
# properties:
# mode: transport # or rest
# # security.auth: test:123456 # only used for rest mode
# cluster.name: elasticsearch
# - name: kudu #这个是输出到kudu
# key: kudu
# properties:
# kudu.master.address: 127.0.0.1 # ',' split multi address
可以看到,上游支持的消息来源有canal server、kafka、rocketMQ、rabbitMQ,下游支持接收的有mysql、oracle、postgres、hbase、es、kudu。那大概怎么配置其实也可以猜到了,就是先将总配置文件application.yml配置好,然后进入到具体的文件夹中去配置适配器表映射文件。比如:现在我想要输出到hbase,那么我先把application.yml配置好,然后进入到hbase目录下继续hbase的相关配置。然后有需要的话,再调整一下其他配置,最后直接启动canal adapter。
那么具体怎么配置,怎么使用的,那当然是看官网了,官网地址:https://github.com/alibaba/canal/wiki/ClientAdapter。如果还是不清楚的,借用一下这位大神的文章,讲的很清楚:https://blog.csdn.net/Day_Day_No_Bug/article/details/116748553。
instance.properties
因为本次例子是实现mysql->kafka场景,所以用ClientAdapter不太现实,那就还有另一种方式。在instance.properties中,其实就已经提供了一种全量同步的方式,那就是通过下面三项配置,去指定读取binlog日志中的数据。在我们新增instance的时候,可以在instance.properties里配置一下,下面是我的例子。
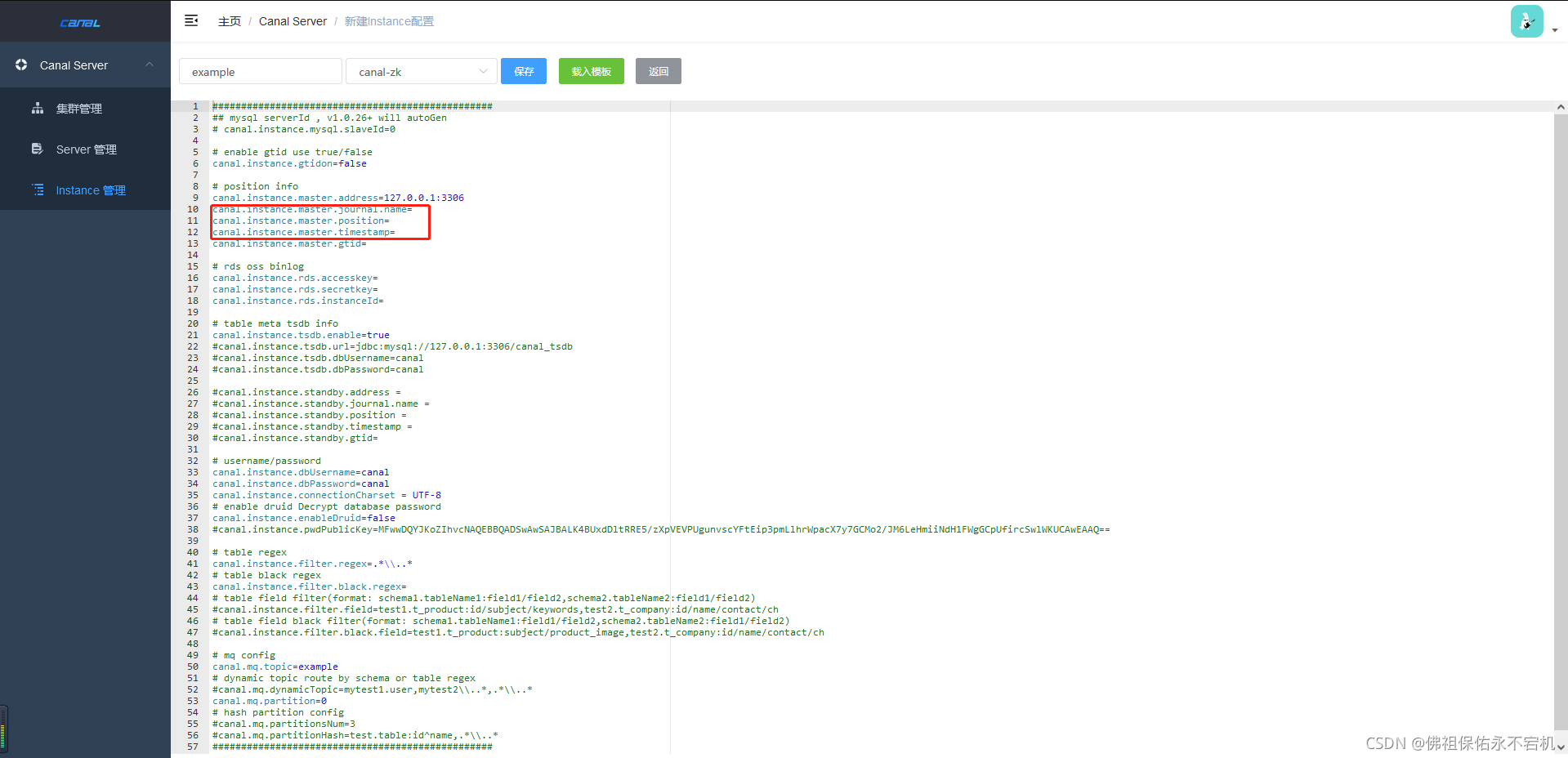
# mysql日志文件,起始的binlog文件
canal.instance.master.journal.name=mysql-bin.000080
# 获取日志的起始binlog位点,一般写个0就行,因为全量同步基本上都是全部数据都要
canal.instance.master.position=0
# 获取日志的起始时间戳
canal.instance.master.timestamp=1634110736
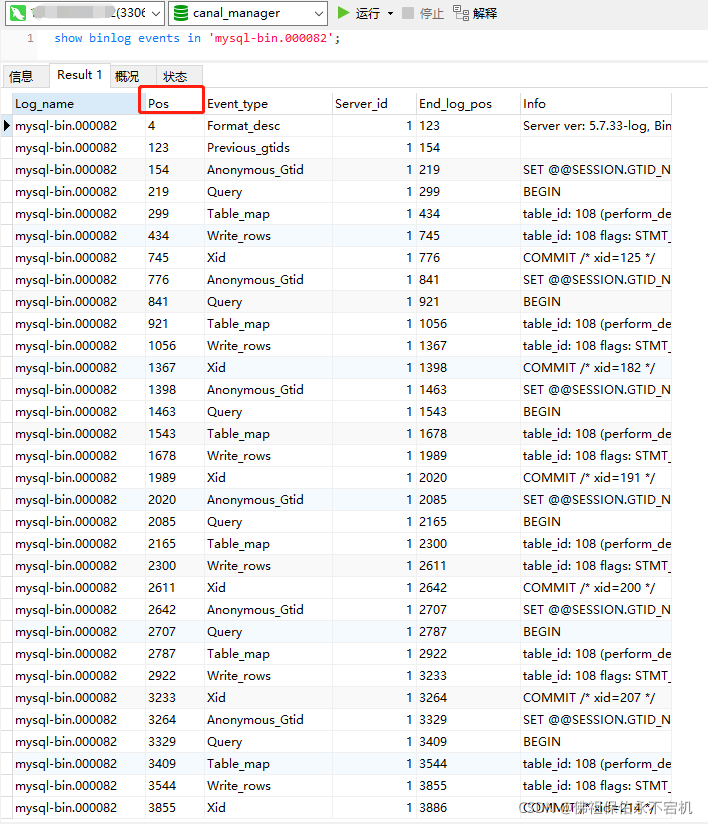
binglog文件名,可以通过show master logs获取mysql binlog日志列表。canal.instance.master.journal.name指向的哪个binlog,就从哪个日志文件开始读取。
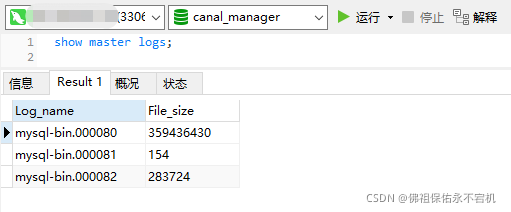
show binlog events in 'mysql-bin.000082'命令可以查看日志,里面包含了位点信息。
其实这3个属性设置,主要就是用来定位具体binlog位点,好让canal知道从哪个binlog文件,binlog文件的哪个位置开始进行同步(注意:这只是我们进行全量同步的配置,如果不指定任何信息,默认从当前数据库的位点,进行启动。在mysql执行这个命令:show master status,可查看位点状态),方式有两个:
-
通过
canal.instance.master.journal.name+canal.instance.master.position的方式定位,精确指定一个binlog位点,进行启动。# binlog日志文件名 canal.instance.master.journal.name='mysql-bin.000082' # binlog具体位点 canal.instance.master.position=3329 -
通过
canal.instance.master.timestamp时间戳定位,指定一个时间戳,canal会自动遍历mysql binlog,找到对应时间戳的binlog位点后,进行启动。# 时间戳 canal.instance.master.timestamp=1634110736
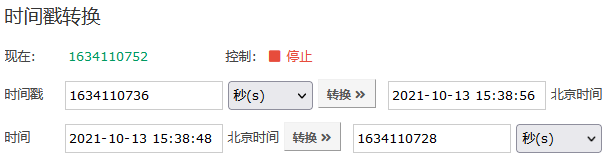
canal.instance.master.timestamp是需要填写时间戳的,如果对时间戳没什么概念,那么可以网上搜索时间戳转换器,它可以帮我们转换时间戳。
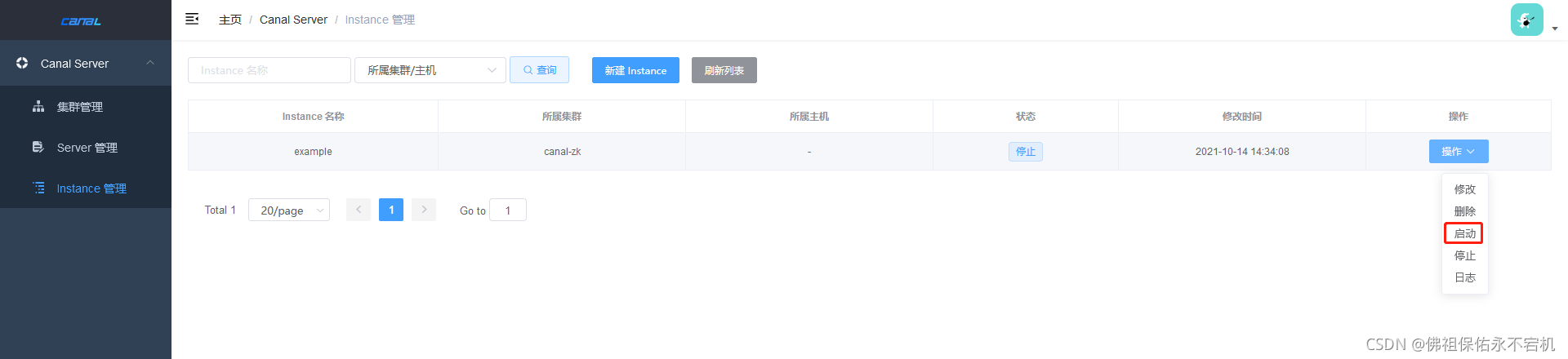
如果是之前就已经新增了instance,可以找到对应的instance直接点击修改,进入页面调整instance.properties。
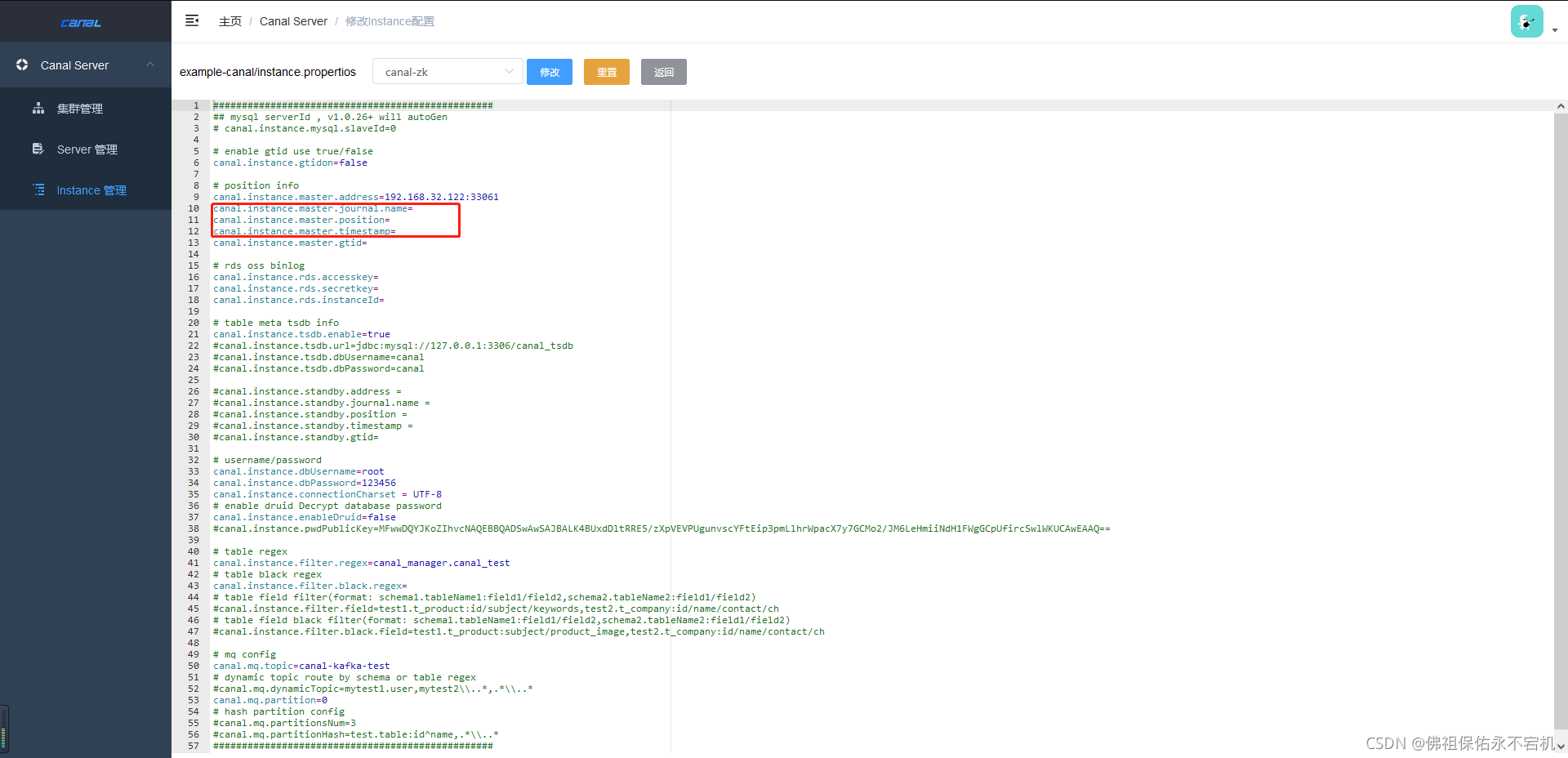
修改了instance.properties文件后,找到当初生成的instance目录,将里面的meta.dat删除,因为这个文件记录了当前instance的状态信息。如果还把它留着的话,那么有可能不会生效。可以看看里面的内容,里面包含了消费的位置、时间戳、日志文件、数据库ip端口,客户端等等一系列的信息。
在instance管理中将刚刚修改的instance先停止,然后再启动一下就行了,这个时候刚刚增加的全量同步配置就会生效。如果最后不行,可以手动重启一下canal试试。

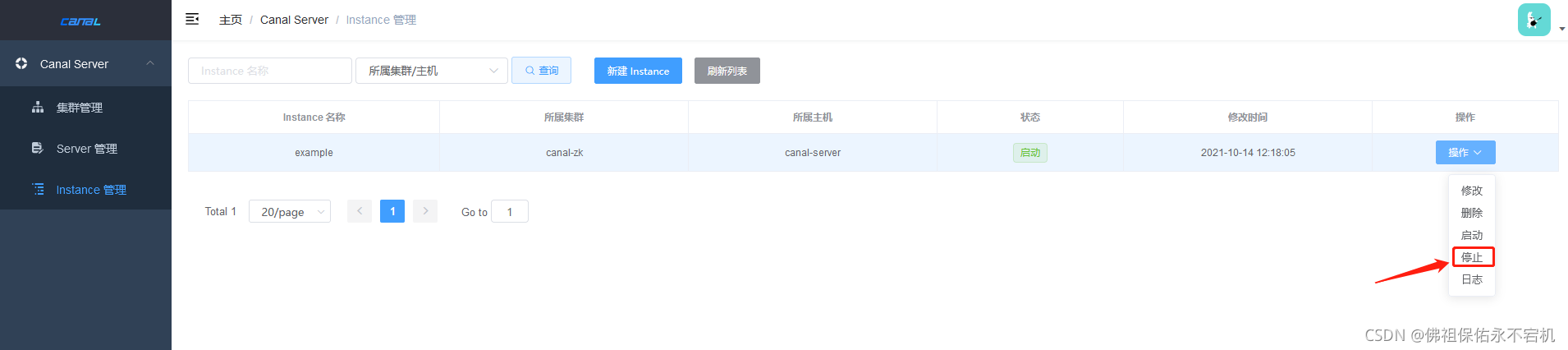
如果以上方式不行,那就来个粗暴点的方式,找到刚刚的meta.dat文件,直接修改里面的内容,将 "position"的值改成4, 将"journalName"改成起始binlog文件名,timestamp时间戳要改到你想读取数据的位置,保存后重启canal。但是这种方式我不知道能不能行,网上找到的,感觉上能成。
拓展
因为自身的一些业务需求,有时候我们可能想要一些canal本身没有提供的功能。比如,对于canal用户的密码,不想使用SHA-1,想用MD5或者自己的一套加密算法,又或者对于放入MQ的message我想使用自己定义的一套json格式的数据,不想使用官方原本定义的json格式。这些都是可以实现的,因为官方是开源的,很多东西都可以自己操作,这就是开源的好处之一。
就拿刚刚举的两个例子,其实官方并没有提供能够操作的接口,但是canal是开源的呀,所以可以自己改代码。源码就是官网上的最后两个,根据实际情况随便下载其中一个即可,我是下载的zip。
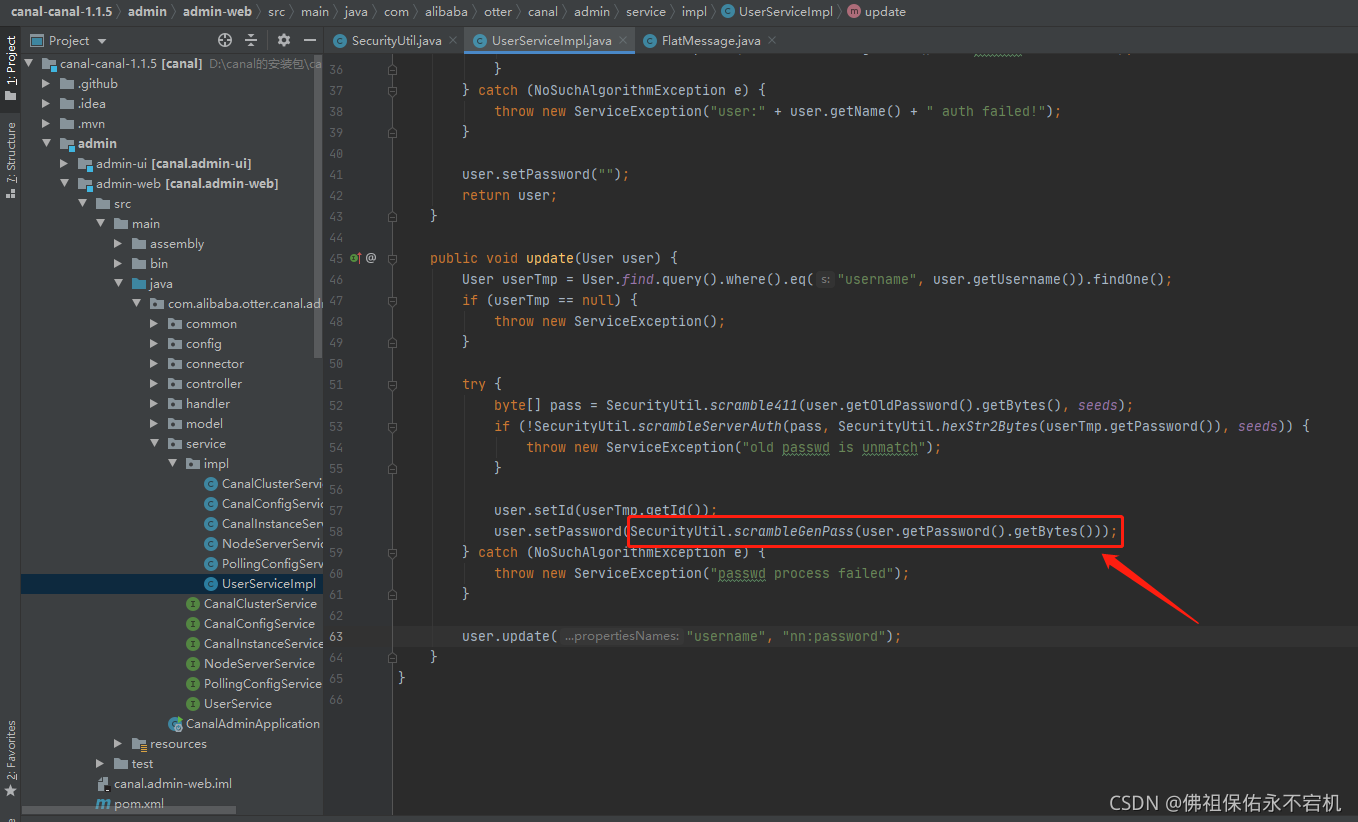
- 修改加密方式:我们可以通过找到修改密码的地方去寻找加密方式,其实修改用户密码是通过调用修改用户信息接口,直接找到加密工具类进行加密,就是下面截图里的这样。都已经找到加密的方式了,那么接下来修改也就很简单了。
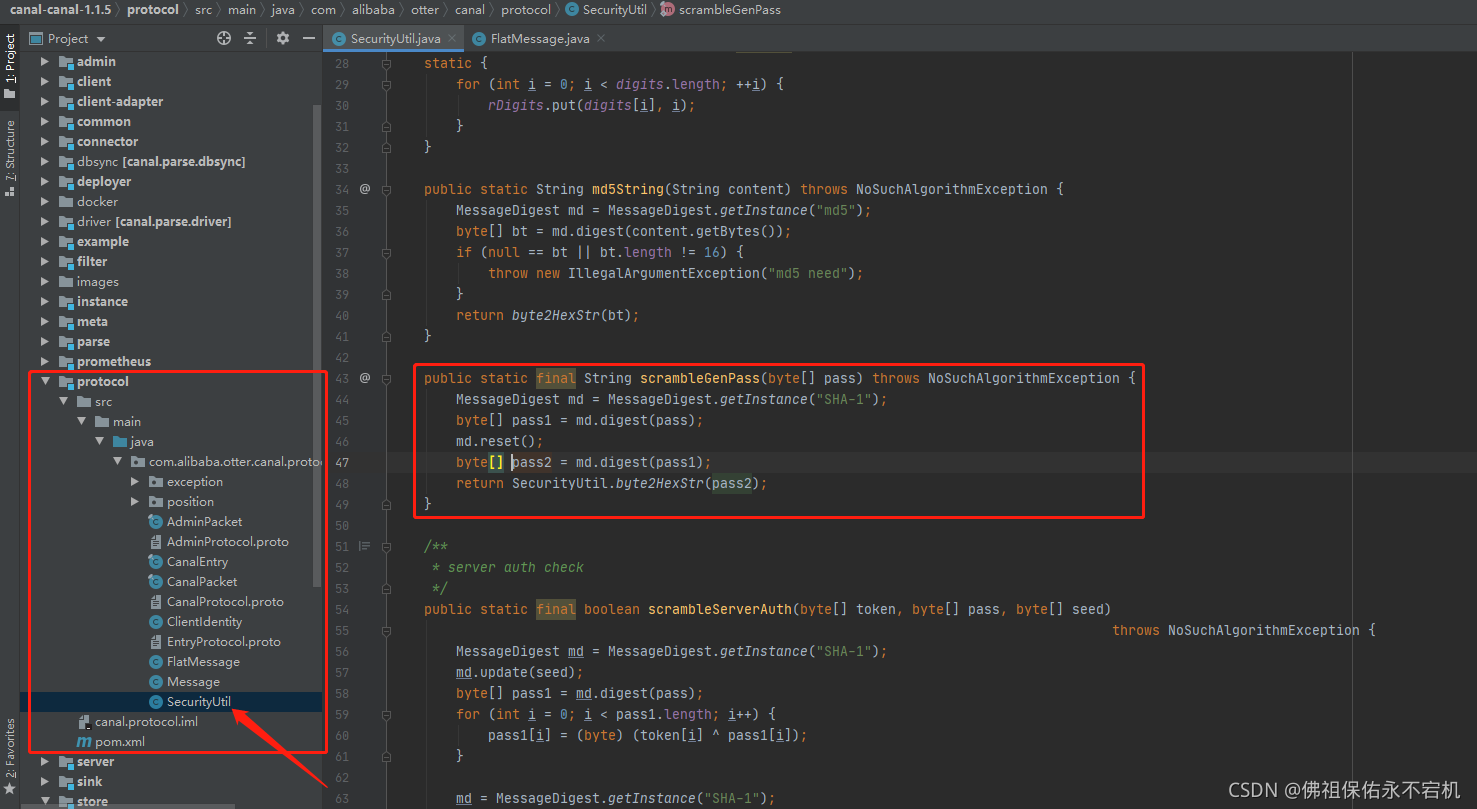
- 自定义json:其实最主要的就是找到FlatMessage这个类,可以看到FlatMessage类的属性和我们message中的数据格式是一样的。如果需要自定义json,那么只需要把FlatMessage类按照自己的需求修改了,然后将其他有用到FlatMessage类的地方也一同修改了就完成了。
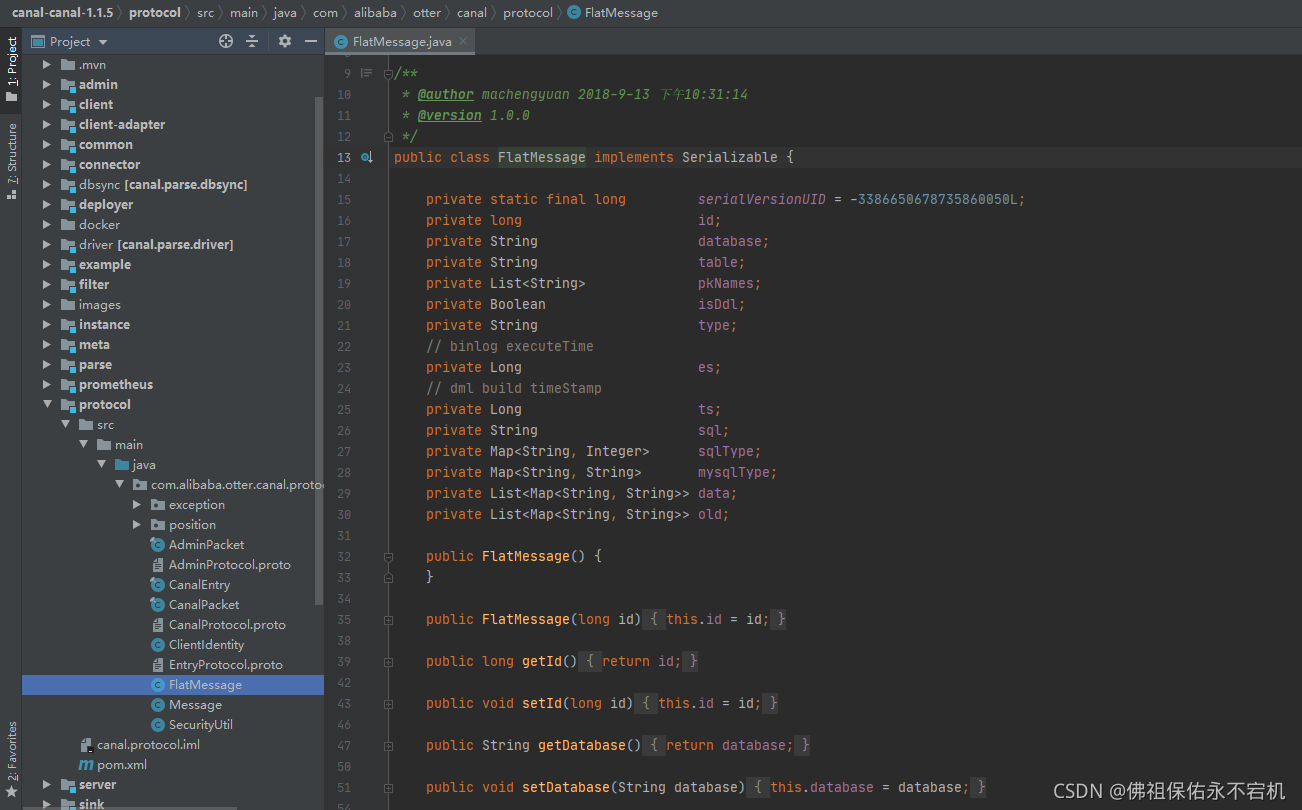

以上两个例子只是很简单的调整,但是如果有复杂的调整也是一样的操作。当按照自己的需求调整完成后,打包源代码,重新部署一下就好了。