已有的在移动设备上执行的深度学习模型例如 MobileNet、 ShuffleNet 等都严重依赖于在深度上可分离的卷积运算,而缺乏有效的实现。在本文中,来自加拿大西安大略大学的研究者提出了称为 PeleeNet 的有效架构,它没有使用传统的卷积来实现。PeleeNet 实现了比目前最先进的 MobileNet 更高的图像分类准确率,并降低了计算成本。研究者进一步开发了实时目标检测系统 Pelee,以更低的成本超越了 YOLOv2 的目标检测性能,并能流畅地在 iPhone6s、iPhone8 上运行。
在具有严格的内存和计算预算的条件下运行高质量的 CNN 模型变得越来越吸引人。近年来人们已经提出了很多创新的网络,例如 MobileNets (Howard et al.(2017))、ShuffleNet (Zhang et al.(2017)),以及 ShuffleNet (Zhang et al.(2017))。然而,这些架构严重依赖于在深度上可分离的卷积运算 (Szegedy 等 (2015)),而这些卷积运算缺乏高效的实现。同时,将高效模型和快速目标检测结合起来的研究也很少 (Huang 等 (2016b))。本研究尝试探索可以用于图像分类和目标检测任务的高效 CNN 结构。本文的主要贡献如下:
研究者提出了 DenseNet (Huang et al. (2016a)) 的一个变体,它被称作 PeleeNet,专门用于移动设备。PeleeNet 遵循 DenseNet 的创新连接模式和一些关键设计原则。它也被设计来满足严格的内存和计算预算。在 Stanford Dogs (Khosla et al. (2011)) 数据集上的实验结果表明:PeleeNet 的准确率要比 DenseNet 的原始结构高 5.05%,比 MobileNet (Howard et al. (2017)) 高 6.53%。PeleeNet 在 ImageNet ILSVRC 2012 (Deng et al. (2009)) 上也有极具竞争力的结果。PeleeNet 的 top-1 准确率要比 MobileNet 高 0.6%。需要指出的是,PeleeNet 的模型大小是 MobileNet 的 66%。PeleeNet 的一些关键特点如下:
两路稠密层:受 GoogLeNet (Szegedy et al. (2015)) 的两路稠密层的激发,研究者使用了一个两路密集层来得到不同尺度的感受野。其中一路使用一个 3×3 的较小卷积核,它能够较好地捕捉小尺度的目标。另一路使用两个 3×3 的卷积核来学习大尺度目标的视觉特征。该结构如图 1.a 所示:
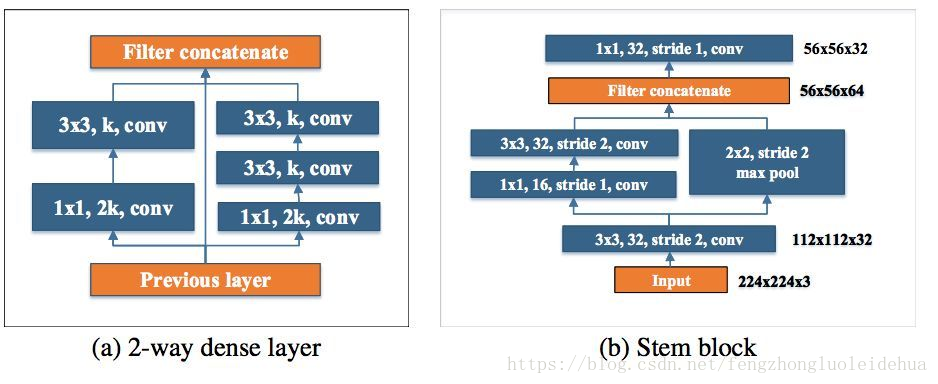
图 1: 两路密集层和 stem 块的结构
瓶颈层通道的动态数量:另一个亮点就是瓶颈层通道数目会随着输入维度的变化而变化,以保证输出通道的数目不会超过输出通道。与原始的 DenseNet 结构相比,实验表明这种方法在节省 28.5% 的计算资源的同时仅仅会对准确率有很小的影响。
没有压缩的转换层:实验表明,DenseNet 提出的压缩因子会损坏特征表达,PeleeNet 在转换层中也维持了与输入通道相同的输出通道数目。
复合函数:为了提升实际的速度,采用后激活的传统智慧(Convolution - Batch Normalization (Ioffe & Szegedy (2015)) - Relu))作为我们的复合函数,而不是 DenseNet 中所用的预激活。对于后激活而言,所有的批正则化层可以在推理阶段与卷积层相结合,这可以很好地加快速度。为了补偿这种变化给准确率带来的不良影响,研究者使用一个浅层的、较宽的网络结构。在最后一个密集块之后还增加了一个 1×1 的卷积层,以得到更强的表征能力。
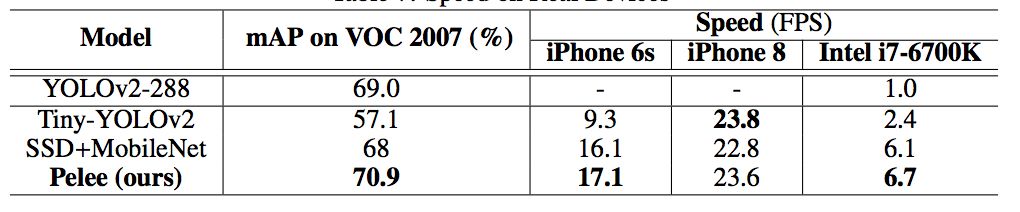
研究者优化了单样本多边框检测器(Single Shot MultiBox Detector,SSD)的网络结构,以加速并将其与 PeleeNet 相结合。该系统,也就是 Pelee,在 PASCAL VOC (Everingham et al. (2010)) 2007 数据集上达到了 76.4% 的准确率,在 COCO 数据集上达到了 22.4% 的准确率。在准确率、速度和模型大小方面,Pelee 系统都优于 YOLOv2 (Redmon & Farhadi (2016))。为了平衡速度和准确率所做的增强设置如下:
特征图选择:以不同于原始 SSD 的方式构建目标检测网络,原始 SSD 仔细地选择了 5 个尺度的特征图 (19 x 19、10 x 10、5 x 5、3 x 3、1 x 1)。为了减少计算成本,没有使用 38×38 的特征图。
残差预测块:遵循 Lee 等人提出的设计思想(2017),即:使特征沿着特征提取网络传递。对于每一个用于检测的特征图,在实施预测之前构建了一个残差 (He et al. (2016)) 块(ResBlock)。ResBlock 的结构如图 2 所示:
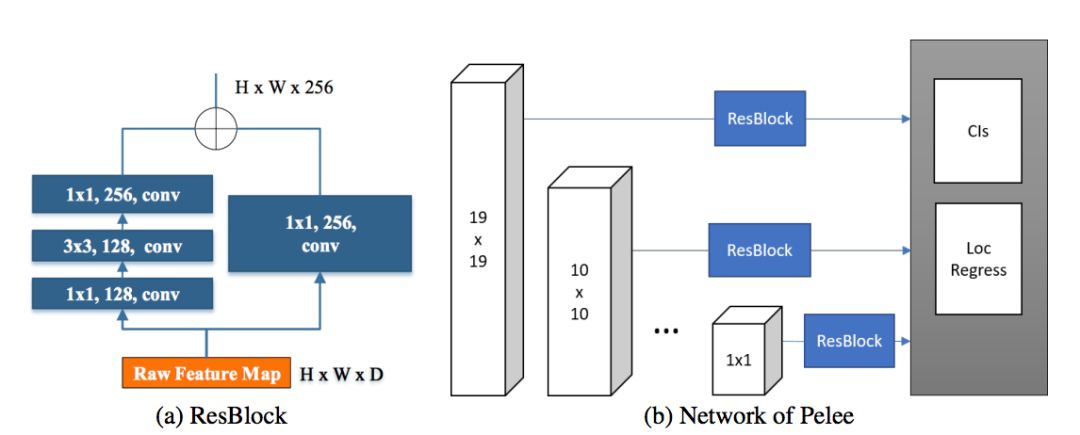
图 2:残差预测块
用于预测的小型卷积核:残差预测块让我们应用 1×1 的卷积核来预测类别分数和边界框设置成为可能。实验表明:使用 1×1 卷积核的模型的准确率和使用 3×3 的卷积核所达到的准确率几乎相同。然而,1x1 的核将计算成本减少了 21.5%。
研究者在 iOS 上提供了 SSD 算法的实现。他们已经成功地将 SSD 移植到了 iOS 上,并且提供了优化的代码实现。该系统在 iPhone 6s 上以 17.1 FPS 的速度运行,在 iPhone8 上以 23.6 FPS 的速度运行。在 iPhone 6s(2015 年发布的手机)上的速度要比在 Intel [email protected] CPU 上的官方算法实现还要快 2.6 倍。