QVQ-72B 多模态大模型实践
flyfish
文末有完整源码
QVQ-72B-Preview 是由 Qwen 团队开发的实验性研究模型,专注于增强视觉推理能力。
想象一下,如果我们的大脑里的语言和看东西的能力结合在一起,我们就能更好地理解周围的世界。我们用语言来思考问题,用眼睛记住画面,这样我们就能更好地解决问题。现在,如果我们把这些能力教给电脑,它们能变得更聪明吗?
现在有很多程序,它们用语言来解决问题的能力已经很强了。但是,我们想知道,如果它们还能看懂图片,会不会变得更厉害。这就是为什么要造一个叫做QVQ的程序。这个程序是基于另一个叫做Qwen2-VL-72B的程序做出来的。
QVQ在看图和解决难题方面做得特别好。在一个叫做MMMU的测试里,它得了70.3分,这个分数很高。它在很多和数学有关的测试里都比原来的Qwen2-VL-72B做得好。
模型大小 146.8 GB
问题如图
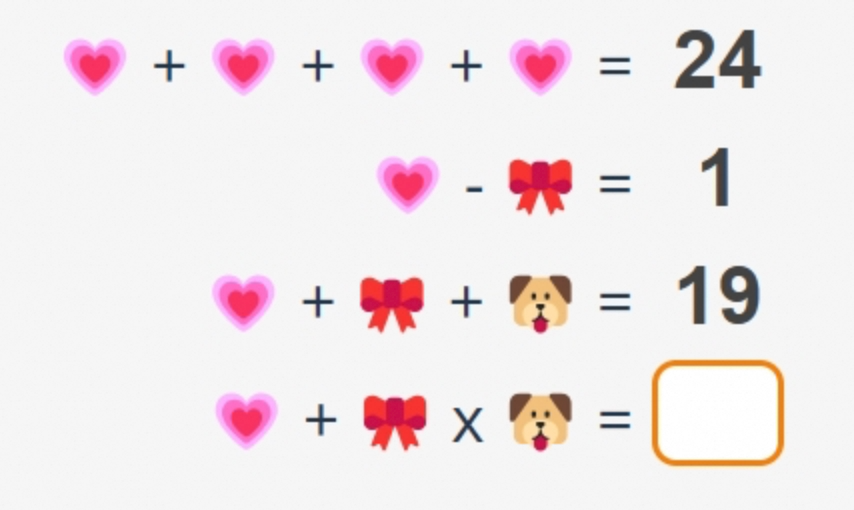
推理结果
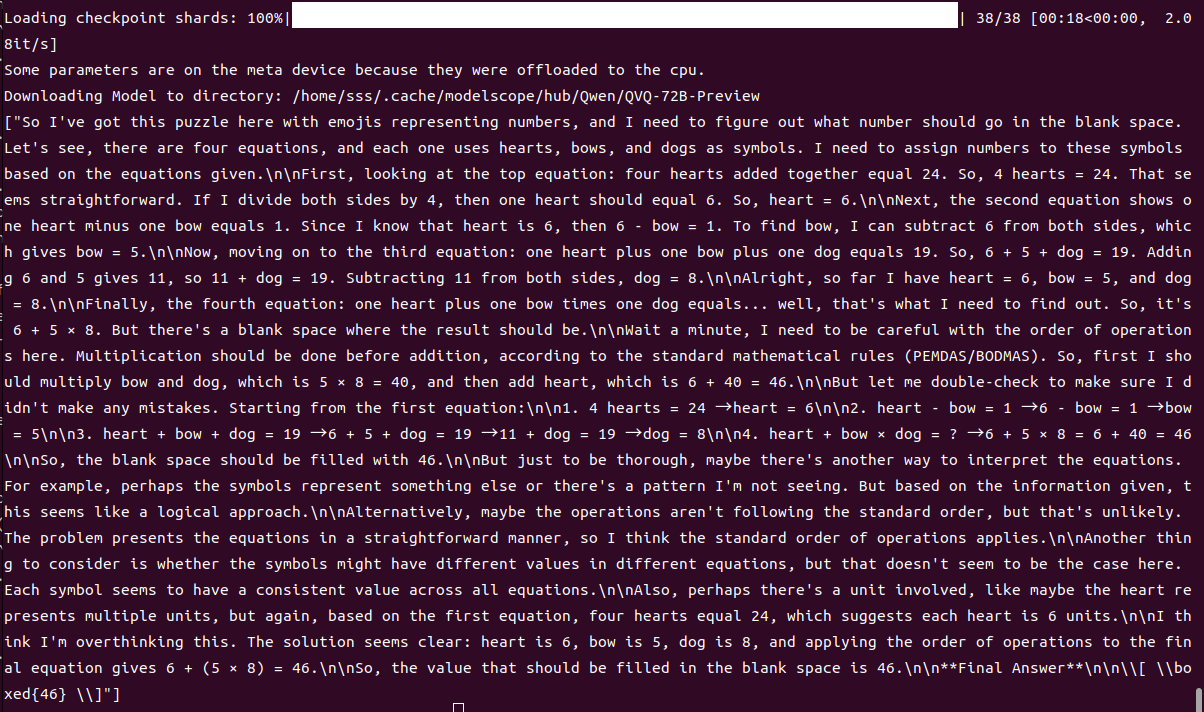
我这里有一个用表情符号代表数字的谜题,需要找出空白处应该填入什么数字。共有四个等式,每个等式使用心形、蝴蝶结和狗作为符号。我需要根据给出的等式为这些符号分配数字。
首先看最上面的等式:四个心形相加等于24。所以,4个心形 = 24。这看起来很直接。如果两边都除以4,那么一个心形应该是6。因此,心形 = 6。
接下来是第二个等式显示一个心形减去一个蝴蝶结等于1。既然我知道心形是6,那么6 - 蝴蝶结 = 1。为了找到蝴蝶结的值,我可以从两边都减去6,这样得到蝴蝶结 = 5。
现在来看第三个等式:一个心形加上一个蝴蝶结再加上一个狗等于19。所以,6 + 5 + 狗 = 19。将6和5相加得到11,所以11 + 狗 = 19。从两边都减去11,得到狗 = 8。
好了,到目前为止我有心形 = 6,蝴蝶结 = 5,狗 = 8。
最后是第四个等式:一个心形加上一个蝴蝶结乘以一个狗等于……嗯,这就是我要找出来的。所以它是6 + 5 × 8。但是空白处的结果是多少呢?
等一下,我需要注意运算顺序。根据标准数学规则(PEMDAS/BODMAS),乘法应该在加法之前完成。所以,首先我应该计算蝴蝶结和狗的乘积,即5 × 8 = 40,然后加上心形,即6 + 40 = 46。
让我再检查一遍确保没有出错。从第一个等式开始:
-
4个心形 = 24 → 心形 = 6
-
心形 - 蝴蝶结 = 1 → 6 - 蝴蝶结 = 1 → 蝴蝶结 = 5
-
心形 + 蝴蝶结 + 狗 = 19 → 6 + 5 + 狗 = 19 → 11 + 狗 = 19 → 狗 = 8
-
心形 + 蝴蝶结 × 狗 = ? → 6 + 5 × 8 = 6 + 40 = 46
所以,空白处应该填入46。
但为了彻底检查,也许还有另一种解释这些等式的方法。例如,符号可能代表其他东西或者存在我没有看到的模式。但根据给定的信息,这似乎是一个合理的解法。
另外,也许运算并不遵循标准顺序,但这不太可能。问题以一种直接的方式呈现了等式,所以我认为标准运算顺序适用。
还需考虑的是符号在不同等式中是否具有不同的值,但这里似乎不是这种情况。每个符号在所有等式中似乎都有一个一致的值。
此外,也许涉及某种单位,比如心形可能代表多个单位,但再次根据第一个等式,四个心形等于24,这意味着每个心形是6个单位。
我认为我可能想多了。解答似乎很清楚:心形是6,蝴蝶结是5,狗是8,并且对最后一个等式应用运算顺序得出6 + (5 × 8) = 46。
因此,空白处应填入的值是46。
最终答案
46 \boxed{46} 46
from modelscope import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
# 设置模型加载的torch数据类型
# bfloat16是为了提升推理效率并减少显存占用
torch_dtype = torch.bfloat16
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/QVQ-72B-Preview",
torch_dtype=torch_dtype, # 设置torch数据类型为bfloat16
device_map="balanced", # 设置模型加载到多GPU上,自动平衡权重
attn_implementation="flash_attention_2", # 使用优化后的Flash Attention
)
# 加载默认的处理器,用于处理输入的文本和图像
processor = AutoProcessor.from_pretrained("Qwen/QVQ-72B-Preview")
# 设置用于处理图像的token范围,根据需要平衡速度和显存使用
# min_pixels和max_pixels决定模型能处理的图片大小范围
# 默认值:4-16384个视觉token
# processor = AutoProcessor.from_pretrained("Qwen/QVQ-72B-Preview", min_pixels=min_pixels, max_pixels=max_pixels)
# 输入消息格式,包括文本和图像
messages = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are a helpful and harmless assistant. You are Qwen developed by Alibaba. You should think step-by-step."}
],
},
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/QVQ/demo.png",
},
{"type": "text", "text": "What value should be filled in the blank space?"},
],
}
]
# 准备用于推理的输入文本
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
# 处理输入中的图像信息
image_inputs, video_inputs = process_vision_info(messages)
# 调用处理器对输入文本和图像进行编码
# 返回的输入包含张量化后的数据
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True, # 自动填充序列长度
return_tensors="pt", # 返回PyTorch格式的张量
)
# 将输入张量移动到GPU上
inputs = inputs.to("cuda")
# 推理:生成输出结果
# 这里设置最大生成的token数量以避免显存不足
generated_ids = model.generate(**inputs, max_new_tokens=8192)
# 截取生成的输出,去掉输入的部分
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
# 将生成的ID转化为自然语言文本
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# 打印生成的文本结果
print(output_text)