一. 双向循环神经网络和代码实现
1. 介绍
在序列学习中,以往假设的目标是:在给定观测的情况下(例如在时间序列的上下文中或在语言模型的上下文中),对下一个输出进行建模,虽然这是一个典型情景,但不是唯一的,例如我们考虑以下三个在文本序列中填空的任务:
- 我
___。 - 我
___饿了。 - 我
___饿了,我可以吃半头猪。
根据可获得的信息量,我们可以用不同的词填空,如“很高兴”(“happy”)、“不”(“not”)和“非常”(“very”)。很明显每个短语的“下文”传达了重要信息(如果有的话),而这些信息关乎到选择哪个词来填空,所以无法利用这一点的序列模型将在相关任务上表现不佳。
例如如果要做好命名实体识别(例如,识别“Green”指的是“格林先生”还是绿色),不同长度的上下文范围重要性是相同的。
2. 双向模型
在前向模式下“从第一个词元开始运行”的循环神经网络,同时需要增加一个“从最后一个词元开始从后向前运行”的双向循环神经网络,下图所示描述了具有单个隐藏层的双向循环神经网络的架构。
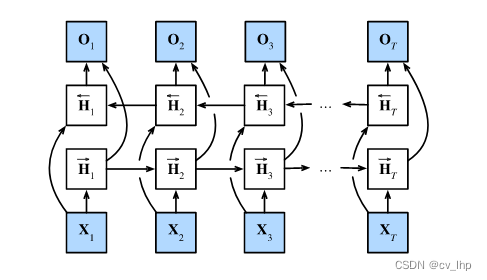
3. 定义
对于任意时间步
t
t
t,给定一个小批量的输入数据
X
t
∈
R
n
×
d
\mathbf{X}_t \in \mathbb{R}^{n \times d}
Xt∈Rn×d(样本数:
n
n
n,每个示例中的输入数:
d
d
d),并且令隐藏层激活函数为
ϕ
\phi
ϕ。在双向架构中,我们设该时间步的前向和反向隐状态分别为
H
→
t
∈
R
n
×
h
\overrightarrow{\mathbf{H}}_t \in \mathbb{R}^{n \times h}
Ht∈Rn×h和
H
←
t
∈
R
n
×
h
\overleftarrow{\mathbf{H}}_t \in \mathbb{R}^{n \times h}
Ht∈Rn×h,其中
h
h
h是隐藏单元的数目。前向和反向隐状态的更新如下:
H
→
t
=
ϕ
(
X
t
W
x
h
(
f
)
+
H
→
t
−
1
W
h
h
(
f
)
+
b
h
(
f
)
)
,
H
←
t
=
ϕ
(
X
t
W
x
h
(
b
)
+
H
←
t
+
1
W
h
h
(
b
)
+
b
h
(
b
)
)
,
\begin{aligned} \overrightarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(f)} + \overrightarrow{\mathbf{H}}_{t-1} \mathbf{W}_{hh}^{(f)} + \mathbf{b}_h^{(f)}),\\ \overleftarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(b)} + \overleftarrow{\mathbf{H}}_{t+1} \mathbf{W}_{hh}^{(b)} + \mathbf{b}_h^{(b)}), \end{aligned}
HtHt=ϕ(XtWxh(f)+Ht−1Whh(f)+bh(f)),=ϕ(XtWxh(b)+Ht+1Whh(b)+bh(b)),
其中,权重
W
x
h
(
f
)
∈
R
d
×
h
,
W
h
h
(
f
)
∈
R
h
×
h
,
W
x
h
(
b
)
∈
R
d
×
h
,
W
h
h
(
b
)
∈
R
h
×
h
\mathbf{W}_{xh}^{(f)} \in \mathbb{R}^{d \times h}, \mathbf{W}_{hh}^{(f)} \in \mathbb{R}^{h \times h}, \mathbf{W}_{xh}^{(b)} \in \mathbb{R}^{d \times h}, \mathbf{W}_{hh}^{(b)} \in \mathbb{R}^{h \times h}
Wxh(f)∈Rd×h,Whh(f)∈Rh×h,Wxh(b)∈Rd×h,Whh(b)∈Rh×h和偏置
b
h
(
f
)
∈
R
1
×
h
,
b
h
(
b
)
∈
R
1
×
h
\mathbf{b}_h^{(f)} \in \mathbb{R}^{1 \times h}, \mathbf{b}_h^{(b)} \in \mathbb{R}^{1 \times h}
bh(f)∈R1×h,bh(b)∈R1×h都是模型参数。
接下来,将前向隐状态
H
→
t
\overrightarrow{\mathbf{H}}_t
Ht和反向隐状态
H
←
t
\overleftarrow{\mathbf{H}}_t
Ht连接起来,获得需要送入输出层的隐状态
H
t
∈
R
n
×
2
h
\mathbf{H}_t \in \mathbb{R}^{n \times 2h}
Ht∈Rn×2h。在具有多个隐藏层的深度双向循环神经网络中,该信息作为输入(相当于当做
X
t
X_{t}
Xt)传递到下一个双向层。
最后,输出层计算得到的输出为
O
t
∈
R
n
×
q
\mathbf{O}_t \in \mathbb{R}^{n \times q}
Ot∈Rn×q(
q
q
q是输出单元的数目):
O t = H t W h q + b q . \mathbf{O}_t = \mathbf{H}_t \mathbf{W}_{hq} + \mathbf{b}_q. Ot=HtWhq+bq.
这里,权重矩阵
W
h
q
∈
R
2
h
×
q
\mathbf{W}_{hq} \in \mathbb{R}^{2h \times q}
Whq∈R2h×q和偏置
b
q
∈
R
1
×
q
\mathbf{b}_q \in \mathbb{R}^{1 \times q}
bq∈R1×q是输出层的模型参数。
事实上这两个方向可以拥有不同数量的隐藏单元,因为这两个方向的隐藏单元是拼接起来的而不是相加在一起。
4. 模型计算代价及其应用
双向循环神经网络的一个关键特性是:使用来自序列两端的信息来估计输出。 也就是说使用来自过去和未来的观测信息来预测当前的观测,但是在对下一个词元进行预测的情况中,这样的模型并不是我们所需的。 因为在预测下一个词元时,我们终究无法知道下一个词元的下文是什么, 所以将不会得到很好的精度。 具体地说在训练期间,我们能够利用过去和未来的数据来估计现在空缺的词; 而在测试期间,我们只有过去的数据,因此精度将会很差,下面的训练和预测结果将说明这一点。
另一个严重问题是,双向循环神经网络的计算速度非常慢。 其主要原因是网络的前向传播需要在双向层中进行前向和后向递归, 并且网络的反向传播还依赖于前向传播的结果,因此梯度求解将有一个非常长的链。
双向层的使用在实践中非常少,并且仅仅应用于部分场合。 例如,填充缺失的单词、词元注释(例如用于命名实体识别:当前词具有一词多意,需要结合上下文判断,或者判断当前词是名词还是动词) 以及作为序列处理流水线中的一个步骤对序列进行编码(例如用于机器翻译)。
5. 双向循环神经网络的错误应用
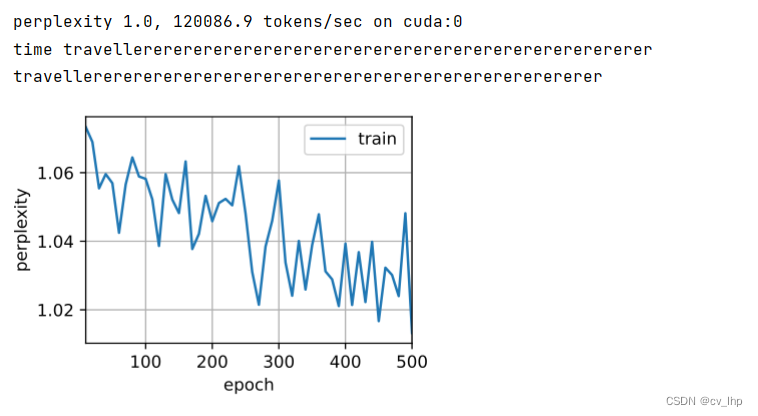
由于双向循环神经网络使用了过去的和未来的数据, 所以我们不能盲目地将这一语言模型应用于任何预测任务。 尽管模型训练出的困惑度是合理的, 但该模型预测未来词元的能力却可能存在严重缺陷。 用下面的代码进行预测当前词的下一个词为例进行引以为戒,以防在错误的环境中使用它们,训练和预测结果如下图所示:虽然训练结果的困惑度为1左右,但预测结果却是很差,很明显预测很差,没有预测出正确结果。双向循环神经网络的错误应用的全部代码如下:
import torch
import d2l.torch
from torch import nn
# 加载数据
batch_size,num_steps = 32,35
train_iter,vocab = d2l.torch.load_data_time_machine(batch_size,num_steps)
vocab_size,num_hiddens,device = len(vocab),256,d2l.torch.try_gpu()
input_size = vocab_size
num_layers = 2
#bidirectional=True表示使用双向的LSTM,num_layers=2表示网络有两层隐藏层,因此此模型为双向深度LSTM循环神经网络
deep_lstm = nn.LSTM(input_size,num_hiddens,num_layers=num_layers,bidirectional=True)
model = d2l.torch.RNNModel(deep_lstm,vocab_size)
model = model.to(device)
# 训练模型
num_epochs,lr = 500,1
d2l.torch.train_ch8(model,train_iter,vocab,lr,num_epochs,device,use_random_iter=False)
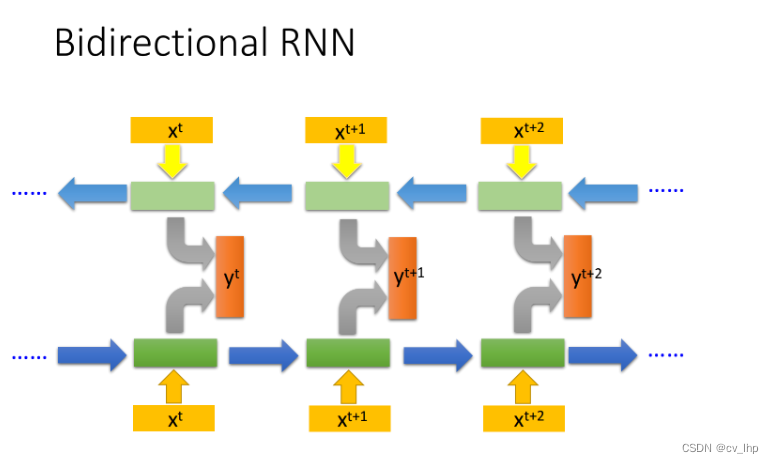
6. 李宏毅机器学习对双向循环神经网络的讲解
Bidirectional RNN
RNN 还可以是双向的,你可以同时训练一对正向和反向的RNN,把它们对应的hidden layer x t x^t xt拿出来拼接在一起,作为输入都接给一个output layer,然后得到最后的 y t y^t yt,如下图所示。
使用Bi-RNN的好处是,NN在产生输出的时候,它能够看到的范围是比较广的,RNN在产生
y
t
+
1
y^{t+1}
yt+1的时候,它不只看了从句首
x
1
x^1
x1开始到
x
t
+
1
x^{t+1}
xt+1的输入,还看了从句尾
x
n
x^n
xn一直到
x
t
+
1
x^{t+1}
xt+1的输入,这就相当于RNN在看了整个句子之后,才决定每个词汇具体要被分配到哪一个槽中,这会比只看句子的前一半效果要更好。
7. 小结
- 在双向循环神经网络中,每个时间步的隐状态由当前时间步的前后数据同时决定。
- 双向循环神经网络主要用于序列编码和给定双向上下文的观测估计。
- 由于梯度链更长,因此双向循环神经网络的训练代价非常高。
- 将前向隐状态 H → t \overrightarrow{\mathbf{H}}_t Ht和反向隐状态 H ← t \overleftarrow{\mathbf{H}}_t Ht连接起来,获得需要送入输出层的隐状态 H t ∈ R n × 2 h \mathbf{H}_t \in \mathbb{R}^{n \times 2h} Ht∈Rn×2h。在具有多个隐藏层的深度双向循环神经网络中,该信息作为输入(相当于当做 X t X_{t} Xt)传递到下一个双向层。
8. 链接
循环神经网络RNN第一篇:李沐动手学深度学习V2-NLP序列模型和代码实现
循环神经网络RNN第二篇:李沐动手学深度学习V2-NLP文本预处理和代码实现
循环神经网络RNN第三篇:李沐动手学深度学习V2-NLP语言模型、数据集加载和数据迭代器实现以及代码实现
循环神经网络RNN第四篇:李沐动手学深度学习V2-RNN原理
循环神经网络RNN第五篇:李沐动手学深度学习V2-RNN循环神经网络从零实现
循环神经网络RNN第六篇:李沐动手学深度学习V2-使用Pytorch框架实现RNN循环神经网络
循环神经网络GRU第七篇:李沐动手学深度学习V2-GRU门控循环单元以及代码实现
循环神经网络LSTM第八篇:李沐动手学深度学习V2-LSTM长短期记忆网络以及代码实现
深度循环神经网络第九篇:李沐动手学深度学习V2-深度循环神经网络和代码实现
双向循环神经网络第十篇:李沐动手学深度学习V2-双向循环神经网络Bidirectional RNN和代码实现