Python Pandas库用法笔记
用于日常学习的积累,如有不足请多多指教。
一、简单了解Pandas
Pandas可以看成是2个缩写单词拼接而成:
·pan(panel) 面板
(data) 数据
(analysis)分析
Pandas→数据处理的工具
Pandas基于matplotlib并以Numpy为基础,能够进行简便的画图和在计算方面有着高性能的优势
1.1 Pandas的优势
- 便捷的数据处理能力
- 读取文件更方便(处理文件的缺失值更方便)
- 具有Matplotlib、Numpy的画图和计算的功能
二、基础处理
2.1 DataFrame
2.1.1 DataFrame的结构
既有行索引,又有列索引的二维数组
pd.DataFrame(arr,index,columns)
#index为行索引
#columns为列索引
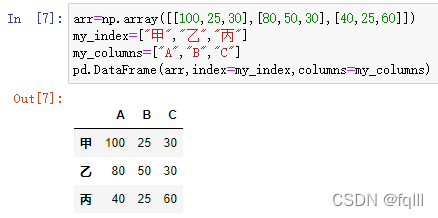
- 代码示例:
import pandas as pd
import numpy as np
arr=np.array([[100,25,30],[80,50,30],[40,25,60]])
my_index=["甲","乙","丙"]
my_columns=["A","B","C"]
pd.DataFrame(arr,index=my_index,columns=my_columns)
结果:
2.1.2 DataFrame的属性
shape、index、columns、values
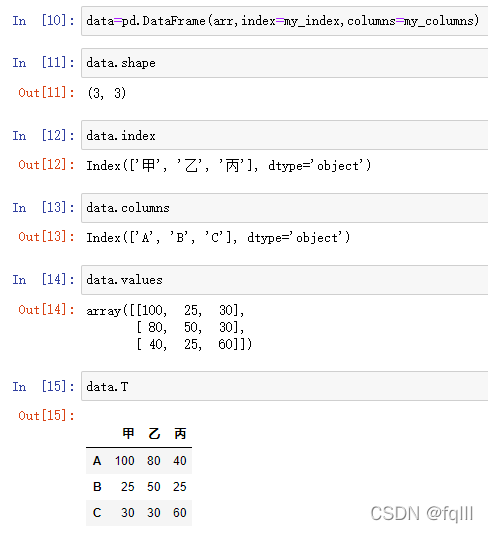
- 代码示例:
data=pd.DataFrame(arr,index=my_index,columns=my_columns)
#形状
data.shape
#行索引
data.index
#列索引
data.columns
#值
data.values
#转置
data.T
结果:
2.1.3 DataFrame的方法
#data=pd.DataFrame(arr,index=my_index,columns=my_columns)
#取头num行
data.head(num)
#取尾num行
data.tail(num)
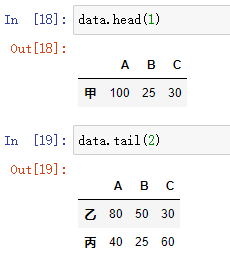
- 代码示例:
#取头1行
data.head(1)
#取尾2行
data.tail(2)
结果:
2.1.4 DataFrame的索引
1. 修改行列索引值
==注意:==修改索引必须整体一起修改
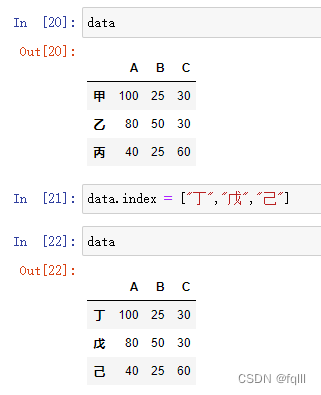
- 代码示例:
#data=pd.DataFrame(arr,index=my_index,columns=my_columns)
data.index = ["丁","戊","己"]
结果:
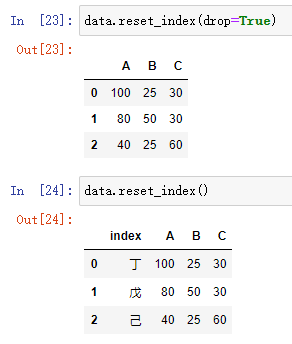
2. 重置索引
reset_index(drop)
#drop:
# drop=True:删除原来的索引
# drop=False(默认):不删除原来的索引
- 代码示例:
#data=pd.DataFrame(arr,index=my_index,columns=my_columns)
data.reset_index(drop=True)
data.reset_index()
结果:
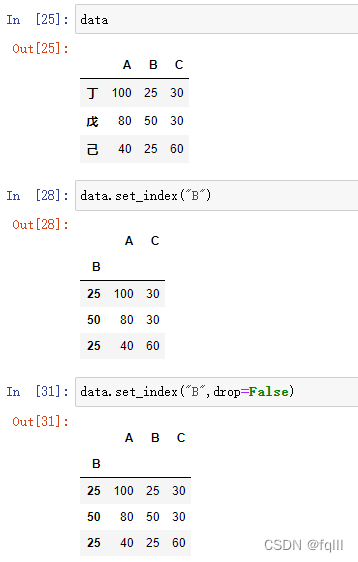
3. 设置某列值为新索引
#data=pd.DataFrame(arr,index=my_index,columns=my_columns)
data.set_index(keys,drop)
#keys:列索引名称
#drop:
# drop=True(默认):删除指定的列
# drop=False:不删除指定的列
- 代码示例:
#data=pd.DataFrame(arr,index=my_index,columns=my_columns)
data.set_index("B")
data.set_index("B",drop=False)
结果:
2.2 Series
series结构只有行索引
DataFrame可以看成是Series的容器
#创建一个Series
pd.Series(ndarray,index)
- 代码示例:
pd.Series(np.arange(4),index=["甲","乙","丙","丁"])
结果:

2.2.1 Series属性
index、values
- 代码示例:
#sr=data.iloc[1,:]
sr.index
sr.values
结果:

2.3 基本数据操作
2.3.1 索引操作
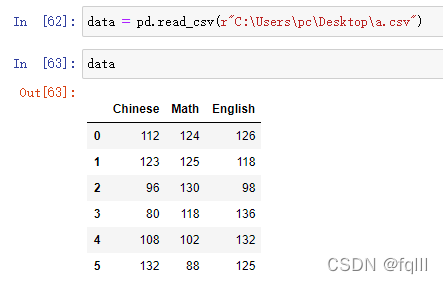
准备数据:
data = pd.read_csv(r"C:\Users\pc\Desktop\a.csv")
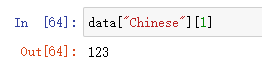
1. 直接索引
必须先列后行
data["Chinese"][1]
2. 按名字索引
loc
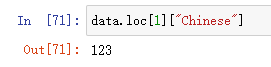
data.loc[1]["Chinese"]
3. 按数字索引
iloc
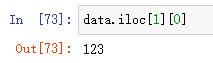
data.iloc[1][0]
2.3.2 排序
1. 对内容排序
1) DataFrame
data.sort_values(key,ascending)
#ascending=False:降序
#ascending=True:升序
- 代码示例:
#data = pd.read_csv(r"C:\Users\pc\Desktop\a.csv")
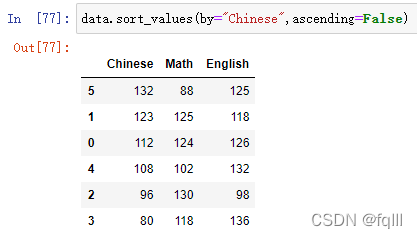
data.sort_values(by="Chinese",ascending=False)
结果:
2) Series
sr.sort_values(ascending)
- 代码示例:
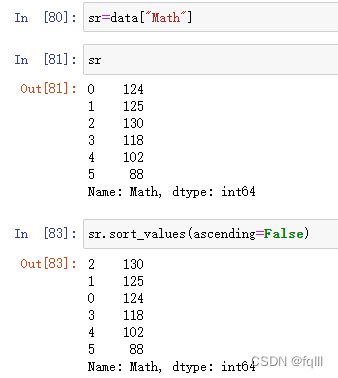
sr=data["Math"]
sr.sort_values(ascending=False)
结果:
2. 对索引排序
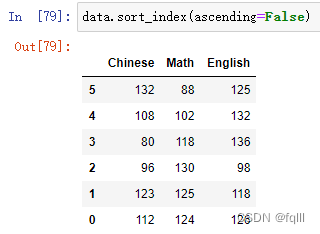
1) DataFrame
data.sort_index()
- 代码示例:
data.sort_index(ascending=False)
结果:
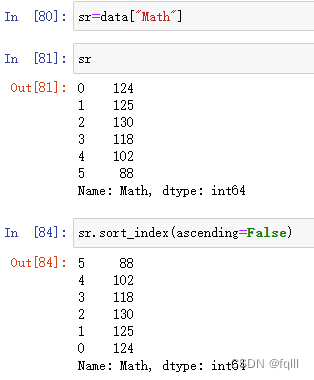
2) Series
sr.sort_index(ascending)
- 代码示例
#sr=data["Math"]
sr.sort_index(ascending=False)
结果:
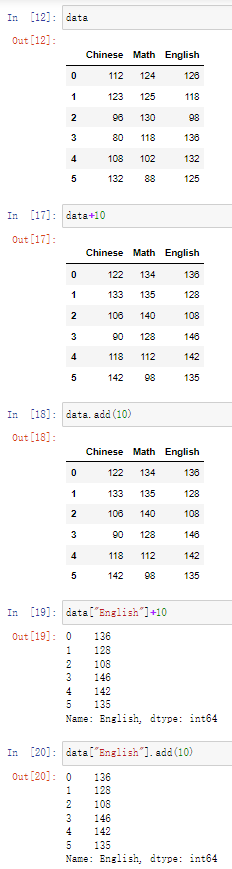
2.4 DataFrame的运算
2.4.1 算术运算
DataFrame+num
DataFrame-num
DataFrame.add(num)
DataFrame.sub(num)
· 代码示例:
data+10
data.add(10)
data["English"]+10
data["English"].add(10)
结果:
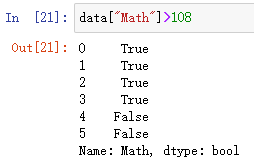
2.4.2 逻辑运算
- 逻辑运算符
<、>、|、&
- 代码示例:
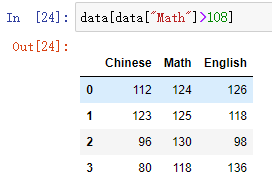
#判断"Math"列的值是否大于108的布尔值
data["Math"]>108
#索引"Math"列的值大于108的数据
data[data["Math"]>108]
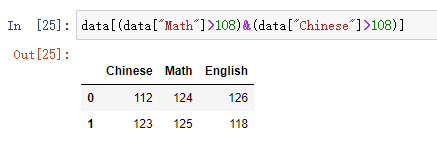
#索引"Math"列和"Chinese"列的值都大于108的数据
结果:
2. 逻辑运算函数
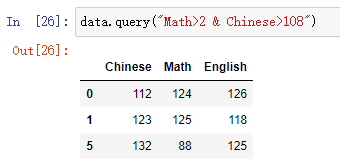
- query():通过查询字符串查询符合的值
DataFrame.query(str)
#str:要查询的字符串
- 代码示例:
data.query("Math>2 & Chinese>108")
结果:
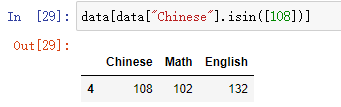
- isin():通过具体的值查询符合的值
DataFrame.isin(values)
#values为具体要查询的值
- 代码示例:
data[data["Chinese"].isin([108])]
结果:
2.4.3 统计运算
1. 统计描述函数
min()、max()、mean()、median()、var()、std()→describe()
DataFrame.describe()
- 代码示例:
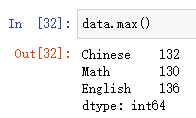
#取最大值
data.max()
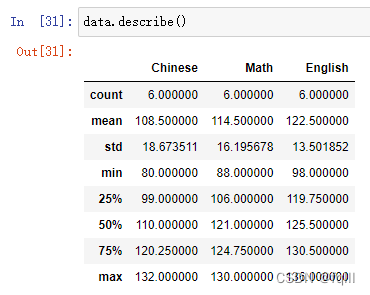
#缺统计指标
data.describe()
结果:
2. 累计统计函数
| 累计统计函数 | 作用 |
|---|---|
| cumsum | 求和 |
| cunnax | 求最大值 |
| commin | 求最小值 |
| cumprod | 求积 |
- 代码示例:
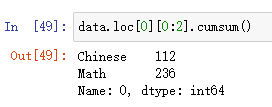
#将0号同学的“Chinese”和"Math"成绩的和,结果在"Math"列上
data.loc[0][0:2].cumsum()
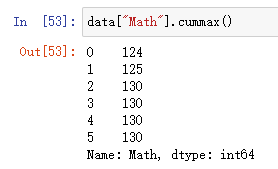
#求"Math"中最大的值
data["Math"].cummax() #遍历到当前最大时会保留并覆盖后续比它小的数据
结果:
2.4.4 自定义运算
DataFrame.apply(funnc,axis)
#func:自定义的函数
#axis
# axis=0:列运算(默认)
# axis=1:行运算
· 代码示例:
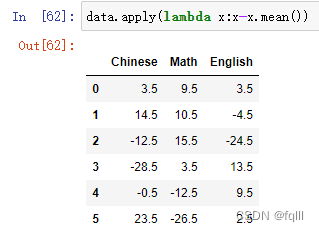
#计算各列中每个数与所在列平均数的差距
data.apply(lambda x:x-x.mean())
结果:
2.5 Pandas画图
pd.DataFrame.plot(x,y,kind)
#x
#y:
#kind:图的类型
# 'line':折线图
# 'bar':柱状图
# 'hist':直方图
# 'pie':饼图
# 'scatter':散点图
- 代码示例:
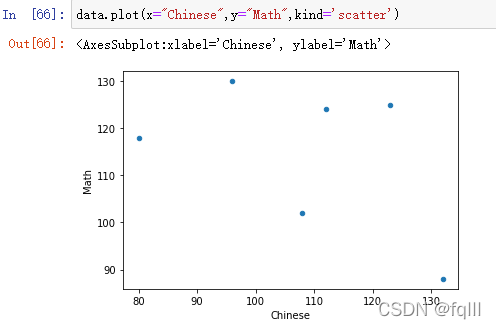
data.plot(x="Chinese",y="Math",kind='scatter')
结果:
2.6 csv文件的读取与存储
2.6.1读取csv文件read_csv()
DataFrame.read_csv(path,usecols,names...)
#usecols为读取字段列
#names为字段
- 代码示例:
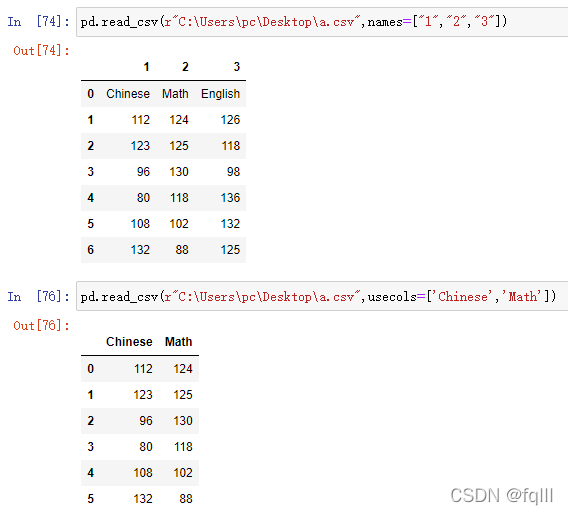
pd.read_csv(r"C:\Users\pc\Desktop\a.csv",names=["1","2","3"])
pd.read_csv(r"C:\Users\pc\Desktop\a.csv",usecols=['Chinese','Math'])
结果:
2.6.2写入csv文件to_csv()
DataFrame.to_csv(path,usecols,index,mode,header...)
#
#index=True(默认)/False,是否需要行索引
#mode为模式
#header=True(默认)/False,是否需要头行
- 代码示例:
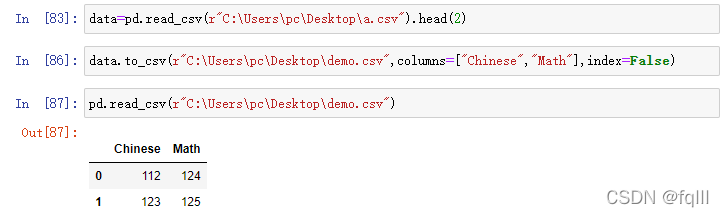
data=pd.read_csv(r"C:\Users\pc\Desktop\a.csv").head(2)
data.to_csv(r"C:\Users\pc\Desktop\demo.csv",columns=["Chinese","Math"],index=False)
pd.read_csv(r"C:\Users\pc\Desktop\demo.csv")
结果:
三、高级处理
3.1 缺失值处理
3.1.1 处理缺失值的思路
- 删除含有缺失值的样本
- 替换缺失值
3.1.2 如何处理缺失值
- 代码示例:
#读取文件b.csv
data=pd.read_csv(r"C:\Users\pc\Desktop\b.csv")
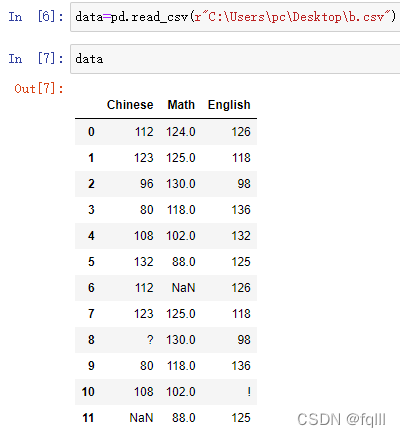
1. 判断数据中是否存在缺失值
pd.isnull(DataFrame)
#缺失值标记为true,否则标记为false
pd.notnull(DataFrame)
#缺失值标记为false,否则标记为true
- 代码示例:
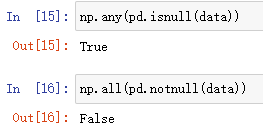
#返回True,说明数据中存在缺失值
np.any(pd.isnull(data))
#返回False,说明数据中存在缺失值
np.all(pd.notnull(data))
#观察存在缺失值的部分
pd.isnull(data).any()
pd.notnull(data).all()

2.处理nan缺失值
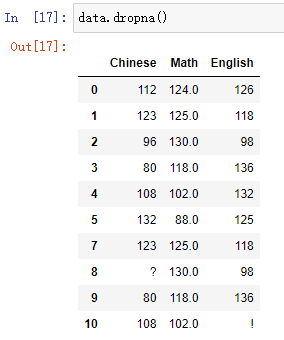
- 删除缺失值的样本
DataFrame.dropna(inplace)
#inplace:
# True:修改原数据
# False(默认):不修改原数据,返回一个新的对象
- 代码示例:
data.dropna()
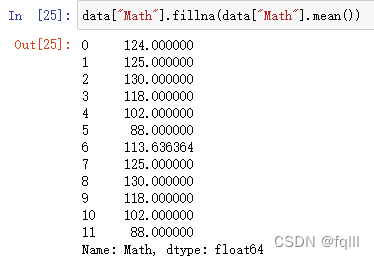
2) 替换
DataFrame.fillna(value,inplace)
#value:替换的目标值
#inplace:
# True:修改原数据
# False(默认):不修改原数据,返回一个新的对象
- 代码示例:
data["Math"].fillna(data["Math"].mean())
3.处理非nan缺失值
DataFrame.repalce(to_replace,value)
#to_replace为替换前的值
#value为替换后的值
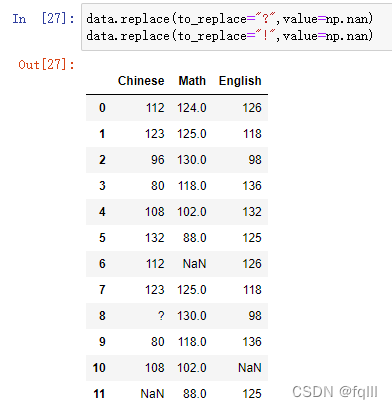
- 代码示例:
data.replace(to_replace="?",value=np.nan)
data.replace(to_replace="!",value=np.nan)
3.2 数据离散化
3.2.1 什么是数据离散化
连续属性的离散化就是将连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。
- 例如:
一组成绩:100,95,84,93,65,82,77,92
可以分为三个区间段:[60,74],[75,89],[90,100]
| A [90,100] | B [75,89] | C [60,74] | |
|---|---|---|---|
| 100 | 1 | 0 | 0 |
| 95 | 1 | 0 | 0 |
| 84 | 0 | 1 | 0 |
| 93 | 1 | 0 | 0 |
| 65 | 0 | 0 | 1 |
| 82 | 0 | 1 | 0 |
| 77 | 0 | 1 | 0 |
| 92 | 1 | 0 | 0 |
| (1表示是,0表示否) |
3.2.2 为什么要进行数据离散化
数据离散化技术可以用来减少给定连续属性值的个数。
3.2.3 如何实现数据离散化
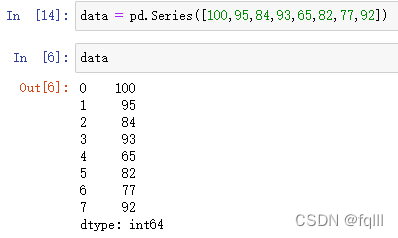
#准备数据
data = pd.Series([100,95,84,93,65,82,77,92])
1.分组
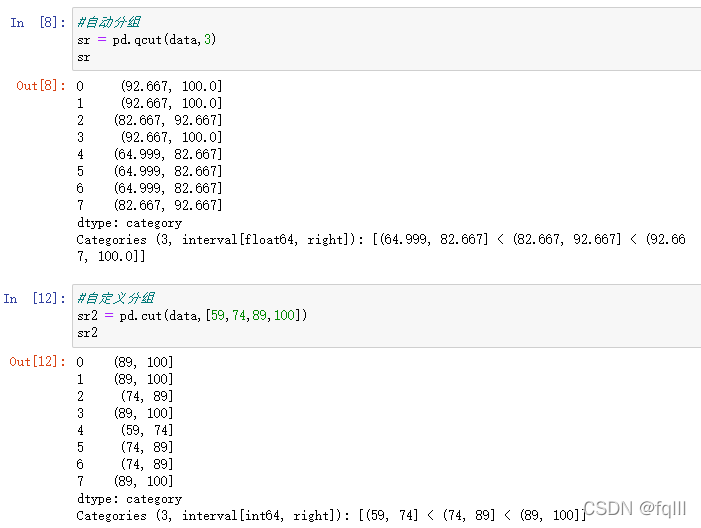
1)自动分组
pd.qcut(data,bins)
- 代码示例:
2)自定义分组
pd.cut(data,bins)
- 代码示例:
#自动分组
sr = pd.qcut(data,3)
#自定义分组
sr2 = pd.cut(data,[59,74,89,100])
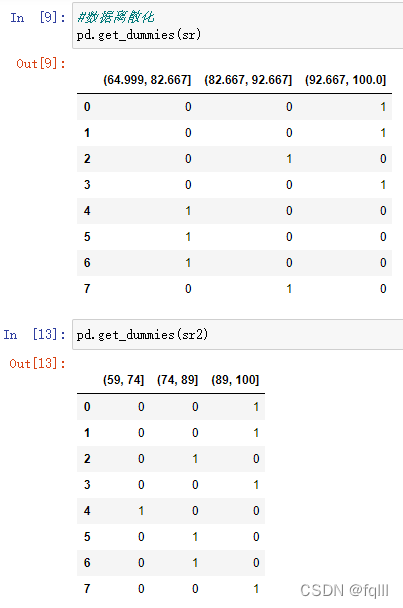
2.进行数据离散化
pd.get_dummies(data,prefix)
#prefix为前缀
- 代码示例:
#数据离散化
pd.get_dummies(sr)
pd.get_dummies(sr2)
3.3 合并
3.3.1 按方向合并
pd.concat([data1,data2],axis)
#axis:
# axis=0为列索引
# axis=1为行索引
- 代码示例:
data2 = pd.Series([77,66,90,62,81,83,96,73])
sr3 = pd.cut(data2,[59,74,89,100])
#合并
pd.concat([(pd.get_dummies(sr2)),(pd.get_dummies(sr3))],axis=0)

3.3.2 按索引合并
pd.merge(left,right,how,on,...)
#left为左表
#right为右表
#how为如何合并(默认内连接)
#on为按什么索引拼接
- 代码示例:
left=pd.DataFrame({'A':[1,2,3],
'B':[4,5,6],
'C':[7,8,9]})
right=pd.DataFrame({'C':[7,9,11],
'D':[13,15,17],
'E':[19,21,23]})
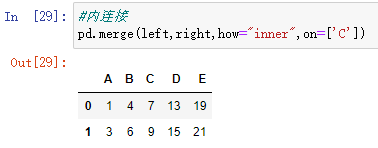
#内连接:保留指定字段两个表共有的键
pd.merge(left,right,how="inner",on=['C'])
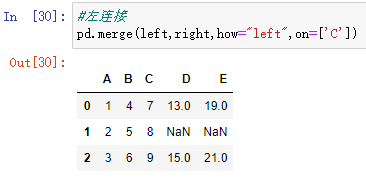
#左连接:保留指定字段左表有的键
pd.merge(left,right,how="left",on=['C'])
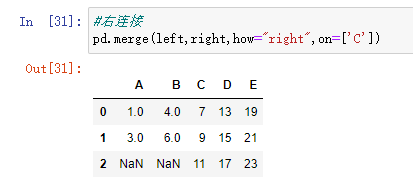
#右连接:保留指定字段右表有的键
pd.merge(left,right,how="right",on=['C'])
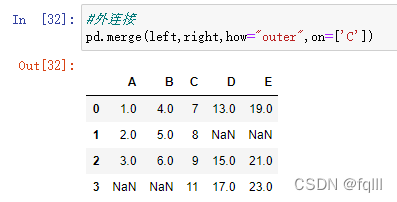
#外连接:保留指定字段两个表都有的键
pd.merge(left,right,how="outer",on=['C'])
3.4 交叉表和透视表
3.4.1 交叉表
pd.crosstab(value,value)
3.4.2 透视表
DataFrame.pivot_table([],index)
3.5 分组与聚合
DataFrame.groupby(by,as_index).count()[str]
#by:分组的列数据