Github :https://github.com/json-path/JsonPath
JsonPath 在线解析:https://jsonpath.com/ https://www.jsonpath.cn/
1、像路径一样,操作嵌套字典
安装 dpath :pip install dpath
import dpath.util
data = {
"foo": {
"bar": {
"a": 10,
"b": 20,
"c": [],
"d": ['red', 'buggy', 'bumpers'],
}
}
}
print(dpath.util.get(data, "/foo/bar/d"))2、JsonPath 解析 json
JsonPath 是用来提取指定 JSON 文档的部分内容。 许多编程语言都提供的了对 json 的解析。
JsonPath 对于 JSON 来说,相当于 XPath 对于 XML。通过使用 JsonPath 可以方便的查找节点、获取想要的数据,JsonPath 就是 Json版的XPath。
jsonpath 库
jsonpath 安装:pip install jsonpath
jsonpath-rw:JSONPath 健壮且显著扩展的Python实现,带有一个明确的AST用于元编程。
jsonpath-rw 介绍:https://pypi.org/project/dt-jsonpath-rw/
安装:pip install dt-jsonpath-rw
JsonPath 语法要点
- $ 表示文档的根元素
- @ 表示文档的当前元素
- .node_name 或 ['node_name'] 匹配下级节点
- [index] 检索数组中的元素。JsonPath 的索引从 0 开始计数
- [start:end:step] 支持数组切片语法
- * 作为通配符,匹配所有成员
- .. 子递归通配符,匹配成员的所有子元素
- (<expr>) 使用表达式
- ?(<boolean expr>) 进行数据筛选
JsonPath中的 "根成员对象" 总是被引用为 $,不管它是对象还是数组。
JsonPath 使用方法:
- 方法 1:使用 点 表示法:$.store.book[0].title
- 方法 2:使用 括号 表示法:$['store']['book'][0]['title']
JsonPath 中字符串使用单引号表示,例如:$.store.book[?(@.category=='reference')]
使用 过滤
"过滤器" 是用于筛选数组的逻辑表达式。一个典型的过滤器应该是 [?(@.age > 18)],其中 @ 表示当前正在处理的项。可以使用逻辑运算符 && 和 || 创建更复杂的过滤器。字符串文字 必须用 单引号 或 双引号 括起来 ([?(@.color == 'blue')] or [?(@.color == "blue")])。
| 操作符 | 描述 |
|---|---|
| == | 左边得值 等于 右边的值 ( 注意:数字 1 不等于 字符串 '1' ) |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| =~ | 匹配正则表达式 [?(@.name =~ /foo.*?/i)] |
| in | 左边 in 右边 [?(@.size in ['S', 'M'])] |
| nin | 左边 not in 右边 |
| subsetof | 左边是右边的一个子字符串 [?(@.sizes subsetof ['S', 'M', 'L'])] |
| anyof | 左边和右边相交 [?(@.sizes anyof ['M', 'L'])] |
| noneof | 左边和右边不相交 [?(@.sizes noneof ['M', 'L'])] |
| size | (数组或字符串)长度 |
| empty | (数组或字符串)为空 |
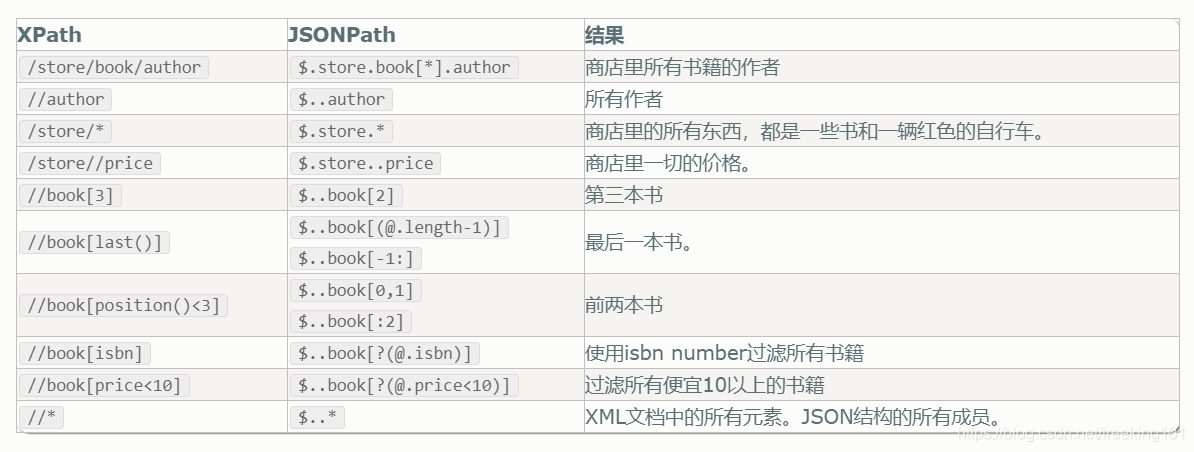
JsonPath 表达式示例:
| JsonPath ( 点击链接测试 ) | 结果 |
|---|---|
| $.store.book[*].author | 获取 Json 中 store下book下的所有author值 |
| $..author | 获取 Json 中 所有 author 的值。 |
| $.store.* | 获取 store 下所有东西( book 和 bicycle ) |
| $.store..price | 获取 store下以及所有子节点下的所有 price |
| $..book[2] | 获取 book数组的第3个值 |
| $..book[-2] | 获取 book数组的倒数第二个值 |
| $..book[0,1] | 获取 book数组的第一、第二的值 |
| $..book[:2] | 获取 book数组从索引 0 (包括) 到 索引 2 (不包括) 的所有值 |
| $..book[1:2] | 获取 book数组从索引 1 (包括) 到 索引 2 (不包括) 的所有值 |
| $..book[-2:] | 获取 book数组从索引 -2 (包括) 到 结尾 的所有值 |
| $..book[2:] | 获取 book数组从索引 2 (包括) 到 结尾 的所有值 |
| $..book[?(@.isbn)] | 获取 所有节点以及子节点中 book 数组包含 isbn 的所有值 |
| $.store.book[?(@.price < 10)] | 获取 store下 book 数组中 price < 10 的所有值 |
| $..book[?(@.price <= $['expensive'])] | 获取 所有节点以及子节点下 book 数组中 price <= expensive 的所有值 |
| $..book[?(@.author =~ /.*REES/i)] | 获取所有匹配正则的 book ( 不区分大小写 ) |
| $..* | 逐层列出 json 中 的所有值,层级由外到内 |
| $..book.length() | book 数组的长度 |
JsonPath 和 XPath 对比
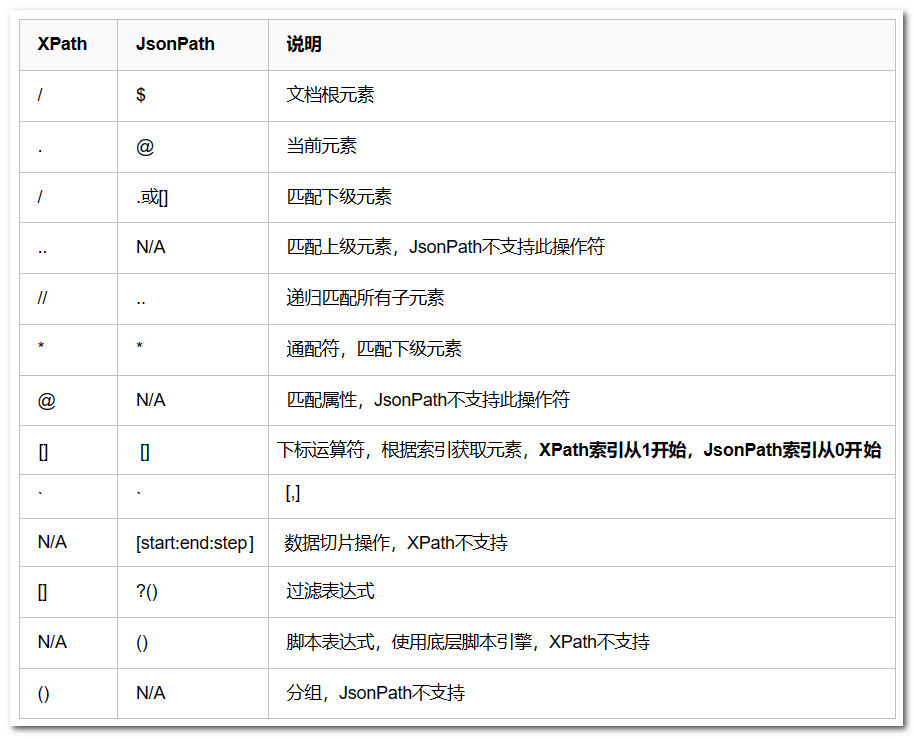
示例
代码来源于https://goessner.net/articles/JsonPath/,JSON文档如下:
{
"store": {
"book": [{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
}, {
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
}, {
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
}, {
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
示例:
import jsonpath
def learn_json_path():
book_store = {
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}
# print(type(book_store))
# 查询store下的所有元素
print(jsonpath.jsonpath(book_store, '$.store.*'))
# 获取json中store下book下的所有author值
print(jsonpath.jsonpath(book_store, '$.store.book[*].author'))
# 获取所有json中所有author的值
print(jsonpath.jsonpath(book_store, '$..author'))
# 获取json中store下所有price的值
print(jsonpath.jsonpath(book_store, '$.store..price'))
# 获取json中book数组的第3个值
print(jsonpath.jsonpath(book_store, '$.store.book[2]'))
# 获取所有书
print(jsonpath.jsonpath(book_store, '$..book[0:1]'))
# 获取json中book数组中包含isbn的所有值
print(jsonpath.jsonpath(book_store, '$..book[?(@.isbn)]'))
# 获取json中book数组中price<10的所有值
print(jsonpath.jsonpath(book_store, '$..book[?(@.price<10)]'))
if __name__ == '__main__':
learn_json_path()
示例:
import json
from jsonpath import jsonpath
data_dict = {
"family": {
"parent": "John",
"children": [
{"name": "Alice", "age": 10},
{"name": "Bob", "age": 8},
{"name": "Charlie", "age": 6},
{"name": "David", "age": 4}
]
}
}
result_list_1 = jsonpath(data_dict, '$..children[?(@.name=="Charlie")]')
print(result_list_1)
result_list_2 = jsonpath(data_dict, '$..[?(@.name=="Charlie")]')
print(result_list_2)
拉勾网城市 JSON 文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 获取所有城市。
import json
import jsonpath
import requests
url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json'
custom_headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Host": "www.lagou.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36"
}
response = requests.get(url, headers=custom_headers)
json_obj = json.loads(response.text)
print(json_obj)
# 从根节点开始,匹配name节点
city_list = jsonpath.jsonpath(json_obj, '$..name')
print(city_list)
print(type(city_list))
# A 下面的节点
jp = jsonpath.jsonpath(json_obj, '$..A.*')
print(jp)
# A 下面节点的name
jp = jsonpath.jsonpath(json_obj, '$..A.*.name')
print(jp)
# C 下面节点的name
jp = jsonpath.jsonpath(json_obj, '$..C..name')
print(jp)
# C 下面节点的第二个
jp = jsonpath.jsonpath(json_obj, '$..C[1]')
print(jp)
# C 下面节点的第二个的name
jp = jsonpath.jsonpath(json_obj, '$..C[1].name')
print(jp)
# C 下面节点的2到5的name
jp = jsonpath.jsonpath(json_obj, '$..C[1:5].name')
print(jp)
# C 下面节点最后一个的name
jp = jsonpath.jsonpath(json_obj, '$..C[(@.length-1)].name')
print(jp)
with open('city.json', 'w', encoding='utf-8') as f:
content = json.dumps(city_list, ensure_ascii=False, indent=4)
print(content)
f.write(content)注意事项:json.loads() 是把 Json 格式字符串解码转换成 Python 对象,如果在 json.loads 的时候出错,要注意被解码的 Json 字符的编码。
如果传入的字符串的编码不是 UTF-8 的话,需要制定字符编码的参数:encoding
jsonpath-ng 库
jsonpath-ng:https://pypi.org/project/jsonpath-ng/
jsonpath-ng 库可以对 JSON 数据进行复杂查询,包括选择父节点。比 jsonpath 库更强大。
安装:pip install --upgrade jsonpath-ng
语 法
$ 根节点。
`this` 当前节点。
`foo` foo 节点。
[ field ] 包含field字段。fieldname 字段名
"fieldname" 同上,如果包含特殊字符,使用引号包括。
'fieldname' 同上
* 任何字段
field , field 指定多个字段,等价于 field | field
[ idx ] 数组访问[*n*]
[start?:end?]
[*]jsonpath1.jsonpath2 在 jsonpath1节点下,查找所有与jsonpath2匹配的子节点
jsonpath[whatever] 等价于 jsonpath.whatever
jsonpath1..jsonpath2 在jsonpath1节点下,查找所有与jsonpath2匹配的子孙节点
jsonpath1 where jsonpath2 匹配 jsonpath1节点有个子节点jsonpath2 的所有节点
jsonpath1 | jsonpath2 匹配 jsonpath1 和 jsonpath2 并集的任何节点
import json
from jsonpath_ng import jsonpath
from jsonpath_ng import parse
from jsonpath_ng.ext import parse as ext_parse
# 假设我们有以下JSON数据
json_data = json.loads("""
{
"store": {
"book": [
{
"title": "Sword of Honour",
"category": "fiction"
},
{
"title": "Moby Dick",
"category": "fiction"
},
{
"title": "The Lord of the Rings",
"category": "fiction"
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
""")
# JsonPath 表达式,选择所有category为fiction的book的父节点
jsonpath_expr = ext_parse("$.store.book[?(@.category=='fiction')].title")
# 执行 JsonPath 查询
matches = jsonpath_expr.find(json_data)
# 打印出所有符合条件的节点的父节点的标题
for match in matches:
print(match.value)下面一些示例是一种更健壮的方法来创建不依赖于解析器的 JSONPath 表达式。
Root()
Slice(start=0, end=None, step=None)
Fields('foo', 'bar')
Index(42)
Child(Fields('foo'), Index(42))
Where(Slice(), Fields('subfield'))
Descendants(jsonpath, jsonpath)
要使用下面的扩展,必须从 jsonpath_ng.ext 导入。

字符串 的算术运算。操作是使用 python 运算符完成的,并允许 python 允许的类型,如果由于类型不兼容而可以执行操作,则返回 []。
{
'cow': 'foo',
'fish': 'bar'
}cow + fish 返回值为 cowfish
$.cow + $.fish 返回值为 foobar
$.cow + "_" + $.fish 返回值为 foo_bar
$.cow + "_" + fish 返回值为 foo_fish
列表 的 算术运算。如果两个列表的大小相同,则可以对它们使用算术。
{'objects': [
{'cow': 2, 'cat': 3},
{'cow': 4, 'cat': 6}
]}$.objects[\*].cow + $.objects[\*].cat 返回值为 [6, 9]
基本 示例
from jsonpath_ng import jsonpath, parse
from jsonpath_ng.jsonpath import Fields
from jsonpath_ng.jsonpath import Slice
json_dict = {'foo': [{'baz': 1}, {'baz': 2}]}
# 一个健壮的解析器,而不仅仅是一个正则表达式。
jsonpath_expr = parse('foo[*].baz')
temp = [match.value for match in jsonpath_expr.find(json_dict)]
print(temp)
temp = [str(match.full_path) for match in jsonpath_expr.find(json_dict)]
print(temp)
temp = jsonpath_expr.update(json_dict, 3)
print(temp)
matches = jsonpath_expr.find(json_dict)
matches[0].full_path.update(json_dict, 3)
jsonpath_expr.filter(lambda d: True, json_dict)
jsonpath_expr.filter(lambda d: d == 2, json_dict)
json_dict = {'foo': [{'id': 'bizzle'}, {'baz': 3}]}
jsonpath.auto_id_field = 'id'
temp = [match.value for match in parse('foo[*].id').find(json_dict)]
print(temp)
json_dict = {'a': {'x': {'b': 1, 'c': 'number one'}, 'y': {'b': 2, 'c': 'number two'}}}
temp = [match.value for match in parse('a.*.b.`parent`.c').find(json_dict)]
print(temp)
jsonpath_expr_direct = Fields('foo').child(Slice('*')).child(Fields('baz'))使用 extended parser
from jsonpath_ng.ext import parse
jsonpath_expr = parse('foo[*].baz')
3、json、usjon、rapidjson、orjson
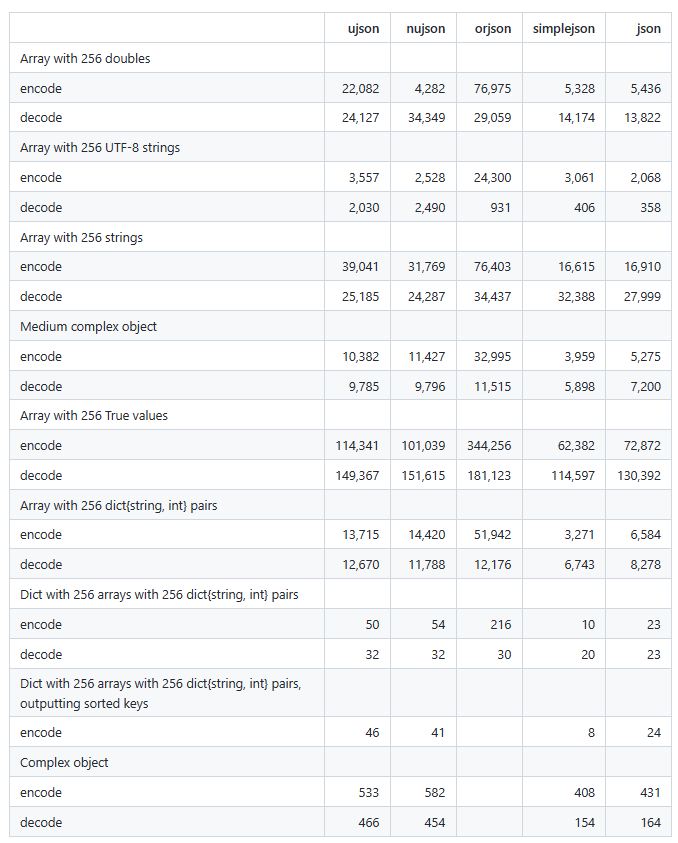
ujson:https://github.com/ultrajson/ultrajson
ujson github 上有各种 json 库对比。一般使用 json 足够,要是追求性能,推荐 ujson
4、使用 json
json 类型特征
- json 是一种通用的数据类型,一般情况下接口返回的数据类型都是json
- 长得像 Python 字典,形式也是 k-v
- 其实 json 是字符串
- 字符串不能用 key、value 来取值,所以要先转换为 Python 的字典才可以
json 帮助
官网文档:https://docs.python.org/zh-cn/3/library/json.html
json 提供了与标准库 marshal 和 pickle 相似的API接口。
对基本的 Python 对象层次结构进行编码:
import json
json.dumps(['foo', {'bar': ('baz', None, 1.0, 2)}])
print(json.dumps("\"foo\bar"))
print(json.dumps('\u1234'))
print(json.dumps('\\'))
print(json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True))
from io import StringIO
io = StringIO()
json.dump(['streaming API'], io)
io.getvalue()紧凑编码:就是把多余的空格全部删除。有的爬虫请求中就是使用的 紧凑编码
import json
json.dumps([1, 2, 3, {'4': 5, '6': 7}], separators=(',', ':'))美化输出:
import json
print(json.dumps({'4': 5, '6': 7}, sort_keys=True, indent=4))JSON解码:
import json
json.loads('["foo", {"bar":["baz", null, 1.0, 2]}]')
json.loads('"\\"foo\\bar"')
from io import StringIO
io = StringIO('["streaming API"]')
json.load(io)命令行使用 json.tool 来验证并美化输出:

5、Python 序列化
pickle 模块
- pickle 模块用于实现 序列化 和 反序列化。
- 序列化 dumps 可以将 list、dict 等数据结构转化为二进制
- 反序列化 loads 可以将字符串转化为 list、dict
数据结构(可以是列表、字典等)转成字符串:dumps()方法:将一个数据结构编码为二进制数据
import pickle
data_dict = {'name': 'king', 'age': '100'}
data_dict_list = [
{'name': 'king', 'age': '100'},
{'name': 'king', 'age': '100'}
]
data_string_1 = pickle.dumps(data_dict)
print(type(data_string_1))
print(data_string_1)
data_string_2 = pickle.dumps(data_dict)
print(type(data_string_2))
print(data_string_2)
temp = pickle.loads(data_string_2)
print(type(temp))
print(temp)
msgpack 模块
安装 msgpack :pip install msgpack
msgpack 类型特征
- msgpack 是一种有效的二进制序列化格式。它使您可以在多种语言(如JSON)之间交换数据。但是它更快,更小。
- 序列化 packb 可以将 list、dict 等数据结构转化为二进制 ( packb 别名为 dumps )
- 反序列化 loads 可以将字符串转化为 list、dict ( unpackb 别名为 loads )
import msgpack
data_dict = {'name': 'king', 'age': '100'}
data_dict_list = [
{'name': 'king', 'age': '100'},
{'name': 'king', 'age': '100'}
]
data_string_1 = msgpack.dumps(data_dict, use_bin_type=True)
print(type(data_string_1))
print(data_string_1)
temp_1 = msgpack.loads(data_string_1, use_list=False)
print(temp_1)
data_string_2 = msgpack.dumps(data_dict_list)
print(type(data_string_2))
print(data_string_2)
示例:
import datetime
import msgpack
useful_dict = {
"id": 1,
"created": datetime.datetime.now(),
}
def decode_datetime(obj):
if b'__datetime__' in obj:
obj = datetime.datetime.strptime(obj["as_str"], "%Y%m%dT%H:%M:%S.%f")
return obj
def encode_datetime(obj):
if isinstance(obj, datetime.datetime):
return {'__datetime__': True, 'as_str': obj.strftime("%Y%m%dT%H:%M:%S.%f")}
return obj
packed_dict = msgpack.packb(useful_dict, default=encode_datetime, use_bin_type=True)
this_dict_again = msgpack.unpackb(packed_dict, object_hook=decode_datetime, raw=False)
print(packed_dict)
print(this_dict_again)