目录
总结:爬虫编程工作量中,分析工作占其中非常重要的分量,直接决定后面编程结果的成败。爬虫编程主要有两个阶段工作,主要工作思路就是:
爬虫的定义:爬虫实质是 程序模拟浏览器发送 携带URL等参数 的请求->接收服务器响应->提取有用的数据->存放于数据库或文件中的程序。
注意:
- 爬取行为必须是为了合法的目的,如科学研究、数据分析、市场调研等,而不能用于非法目的,如商业欺诈、侵犯他人隐私等。
- 尊重Robots协议:在爬取前,检查阅读 网站的 Robots.txt文件,确保不违反网站规定。Robots协议是网站所有者用来指导爬虫行为的一种标准,遵循这一协议是爬虫开发的基本要求。
一、爬虫开发的基本原理
爬虫程序工作流程 最宏观 的概览图:
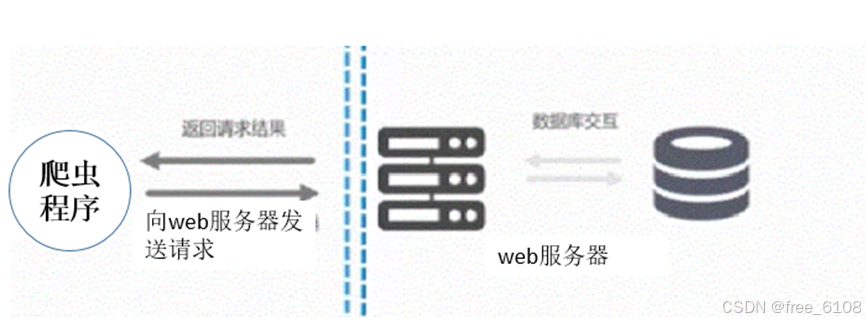
对于开发者来说:双虚线右侧部分是透明的可以忽略的,主要的工作在于爬虫程序与服务器的成功交流。这需要了解 浏览器基本的工作流程。
(一)先了解两个基本知识URL和html文档。
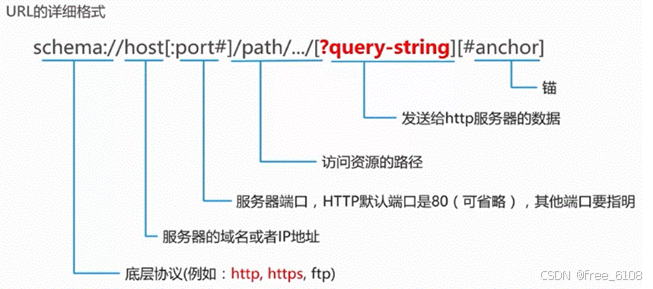
URL(Uniform Resource Locator)是统一资源定位符,用于标识互联网上某一资源的唯一地址。它不仅是网页的地址,也是互联网的基石之一,允许用户通过简单的地址访问Web服务器上的页面,从而简化信息的获取和分享过程。
URL的组成部分
html网页一般由三部分组成,分别是HTML(超文本标记语言)、CSS(层叠样式表)和JScript(动态脚本语言)。Html文件和浏览器执行后显示结果的 例子:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>内联脚本示例</title>
<style>
body {background-color: #f4f4f4;
font-family: Arial, sans-serif;}
h1 { color: #333; }
p { color: #666; }
</style>
</head>
<body>
<div class="container">
<h1>欢迎来到我的网站</h1>
<p id="demo"></p>
</div>
<script>
document.getElementById("demo").innerHTML = "Hello, World!";
</script>
</body>
</html>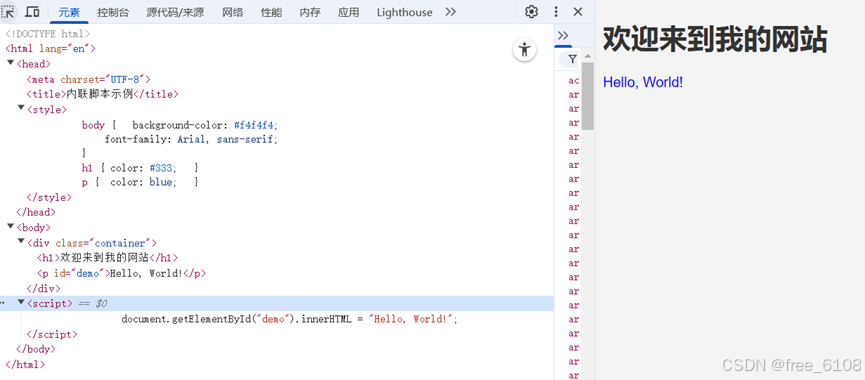
(二) 浏览器基本的工作流程
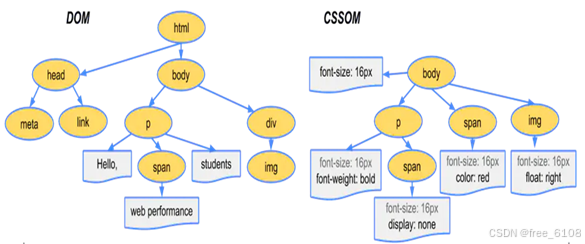
浏览器请求服务器的主要流程 如下图:
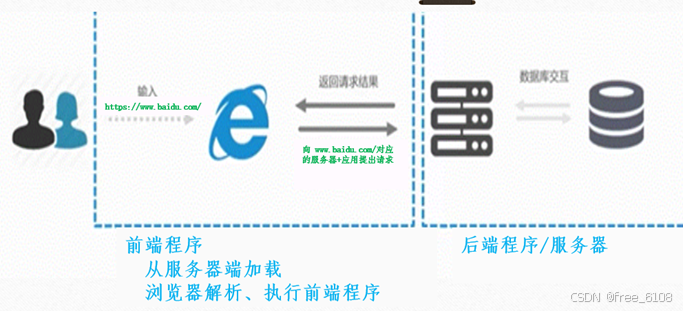
浏览器工作流程的主要内容:
- 用户在浏览器地址栏输入URL:https://www.baidu.com。/提交。
- 浏览器发送请求(主要为get和post请求)。如:浏览器向www.baidu.com/发送首次请求。
- 接收返回Response,解析html+执行脚本程序,发送深层次的请求(请求树)。
首次Response为Html文档为主体(html+CSS+JScript)的前端程序,浏览器解析html+执行脚本程序,自动发送深层次的请求(请求树,如下图)获取本次根请求所需的所有response。
- 生成或完善本次请求的最终CSSOM+DOM树,浏览器结合两者渲染显示最终的结果,一次用户请求完成。用户继续点击提交新的请求,浏览器重复2-4步的工作。

CSSOM(CSS Object Model)存储页面标签内容的丰富显示格式、动画功能等,DOM(Document Object Model)存储页面显示内容标签对象的组织和基础格式,前端用DOM和CSSDOM来实现复杂的交互效果和动态内容更新。简图如下。
(三)爬虫工作的主要流程——类似浏览器,但是又有主要区别:
- 发送请求(带URL,成功请求需要的其他参数)
- 接收返回Response,获取Response携带的不同格式的结果,如json、html文本或文件等其他结果。不执行脚本程序,不自动发起本次根请求所需的深层请求,后果造成结果不完整。
- 根据不同格式的结果挑选所需数据。
- 存储挑选后的结果数据,常用主要有CSV、数据库。可根据新的URL发送新的请求。
不同格式的结果处理方法:
- html文本:解析成DOM树,方便快速检索标签对象里包含的所需结果数据,根据需要可提取数据采集所需的新URL
- 非html文本:根据内容再次挑选数据或直接存储
- json:存储成key—value的对象变量,直接根据键值挑选数据
- 文件的原始二进制字节流,直接存储成相应格式的文件即可。
二、爬虫流程性工作中 涉及的 开发分析工作内容
爬虫通过URL请求获取web服务器响应的数据信息,从技术角度理解就是模拟浏览器发送请求Request,接收服务器响应内容Response,解析响应结果后通过定位提取所用的数据,为了永久性存储数据,把数据存放于数据库或文件中。
爬虫编程一般都是基于现成的API库或框架,根据上面介绍的爬虫工作流程,爬虫向服务器提出请求、接收请求、解析、挑选数据、存储都有API函数,因此重要的是提供给函数正确的参数、合理运用函数和 组织程序模块形成科学的架构。基础编程主要涉及正确的参数如何获取,即网站前端程序工作流程和结果的分析,主要利用浏览器开发者工具完成。
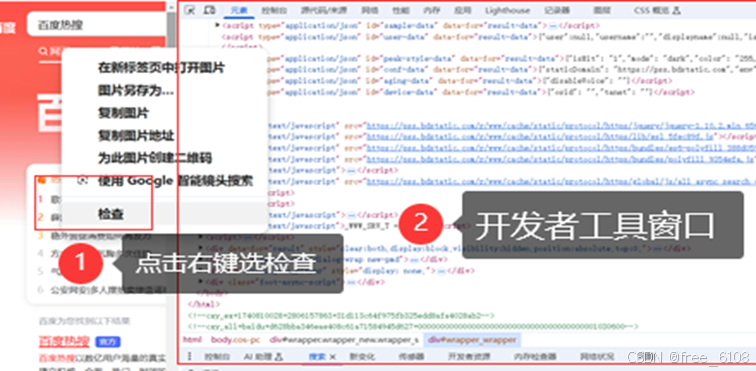
开发爬虫主要涉及的分析工作:
1)确定请求类型 和 请求参数
编写爬虫需要区分清楚向服务器发出的请求,这里主要涉及的HTTP请求类型主要是get和post类型, get和post它们在用途、数据传输方式、安全性、缓存等方面存在显著区别:
- GET:主要用于获取信息,即进行查询操作。POST:用于提交数据,它通常用于提交表单数据、上传文件等场景。
- GET:将参数拼接在URL之后进行传递,参数之间用&符号连接,参数名和参数值之间用=符号连接。由于URL长度的限制(通常由浏览器和Web服务器决定,一般是2KB左右),GET请求传输的数据量有限。POST:将参数放在请求体中传递,爬虫编程需要利用浏览器分析工具分析,因此没有长度限制,适合传输大量数据。POST请求的数据格式可以是application/x-www-form-urlencoded(表单数据编码类型)、multipart/form-data(用于文件上传)、application/json(JSON格式数据)等。
- GET:由于参数直接暴露在URL中,不适合传输敏感信息,如密码等。URL可能会被保存在历史记录中,或通过浏览器地址栏被其他人看到。POST:参数存放在请求体中,不会在URL中显示,因此相对更加安全。但需要注意的是,HTTP是明文传输的,POST请求的数据在传输过程中也可能被截获。为了增强安全性,应使用HTTPS协议进行加密传输。
- GET:请求的结果通常可以被浏览器缓存。如果下次请求的数据相同,浏览器可能会直接返回缓存中的内容,以提高响应速度。可以直接进行回退和刷新操作,而不会对用户或程序产生影响。其参数会保存在历史记录中,且GET请求的URL可以被收藏为书签。POST:请求的结果通常不会被缓存。如果直接回滚和刷新POST请求页面,可能会将数据再次提交。其参数不会。保留在历史记录中,且POST请求的URL不能被收藏为书签。
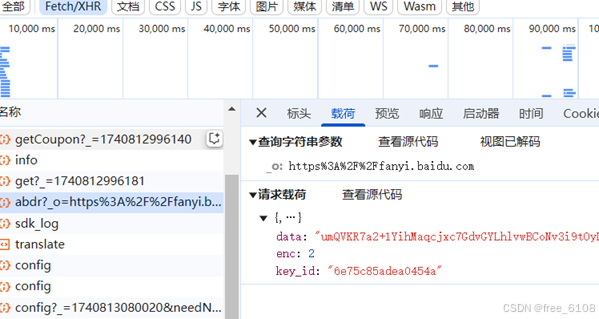
请iu参数主要涉及URL、查询字符串参数、请求载荷、表单数据的寻找。其中根据结果数据寻找所在的URL是最重要,剩下的根据URL即可容易找到。查询字符串参数、请求载荷、表单数据如下:
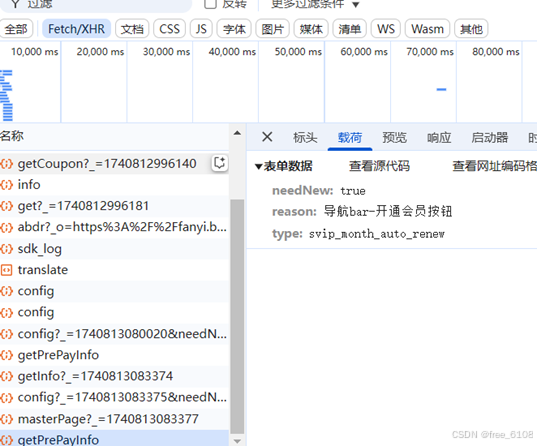
2)确定请求返回结果的类型
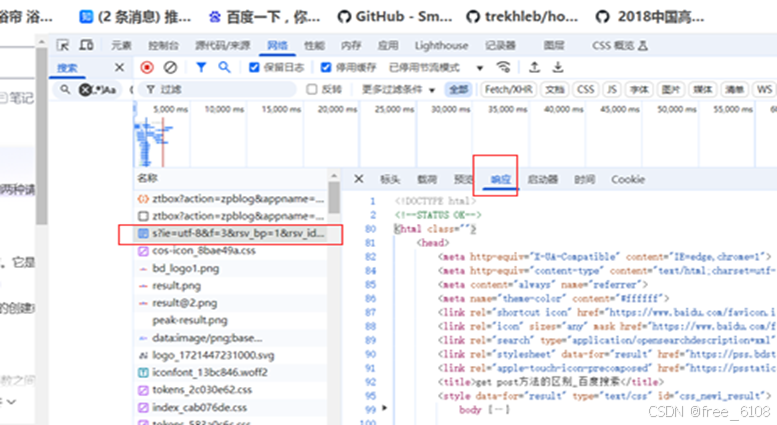
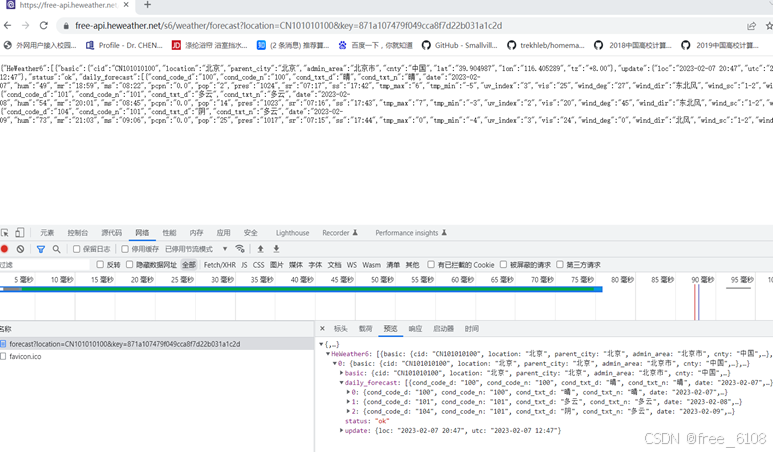
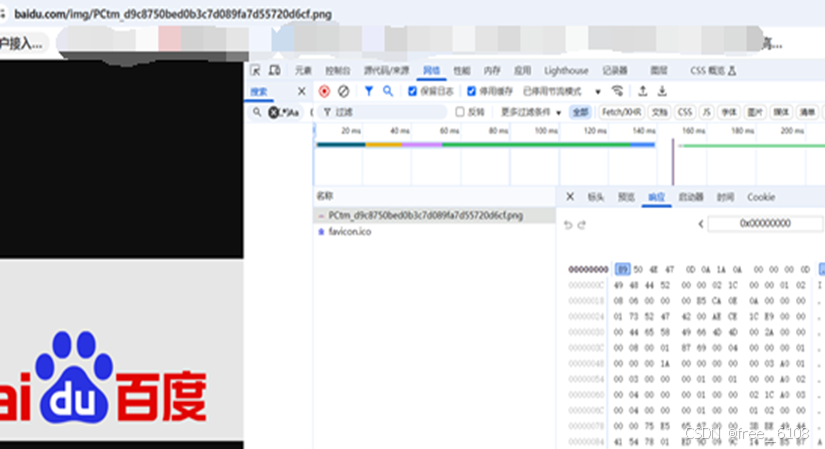
请求返回结果的类型 :html文本、非html文本、json、文件的原始二进制字节流,需要利用工具 根据具体的URL选择 才可以确定。例子分别如下:
3)确定要爬取数据的定位信息
了解返回结果的组织结构,依据返回结果的结构范例 找出想要爬取数据定位信息,这里主要针对html和json里的数据定位来阐述。
请求返回结果的类型 主要决定以后挑选数据利用什么具体 技术和API。
- 如html文本类型的结果,结果数据会包含在标签里,挑选数据首先找到所在标签对象。表示标签对象在的DOM树的位置路径主要有xpath或selector方法,selector表示的路径对应的数据,可以做BeautifulSoup的select方法的参数实现结果数据的获取。
- 如json类型的结果,较简单找出数据所在的KEY值即可。可以利用不同语言里 对应数据类型的 变量存储即可实现数据的快速提取,如java的map、python的字典dic。
总结:爬虫编程工作量中,分析工作占其中非常重要的分量,直接决定后面编程结果的成败。爬虫编程主要有两个阶段工作,主要工作思路就是:
分析准备阶段:工具浏览器
主要结果:URL、查询字符串参数、请求载荷、表单数据
编程阶段:加载库,按照工作流程 调用相应的API 实现对应的功能,主要编码的顺序:
1、发送请求、接收返回结果
2、根据结果类型挑选数据
3、存储结果数据