四、门控循环单元GRU
建议看本篇时,一定要把前面的LSTM先看看:【NLP】第三章:长短期记忆网络LSTM-CSDN博客 ,再看本篇就没有难度了。
门控循环单元Gated Recurrent Unit,GRU,是在LSTM基础上改进的,所以它也是LSTM的一个变体。 GRU是在2014年Cho,etal.《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》(门控循环神经网络在序列建模上的实证评估)论文中提出的,是目前非常流行的一个变体,因为它比LSTM网络要简单,但在某些情况能产生同样出色的效果。就是效果不弱LSTM,所以非常受欢迎。
1、GRU原理及架构
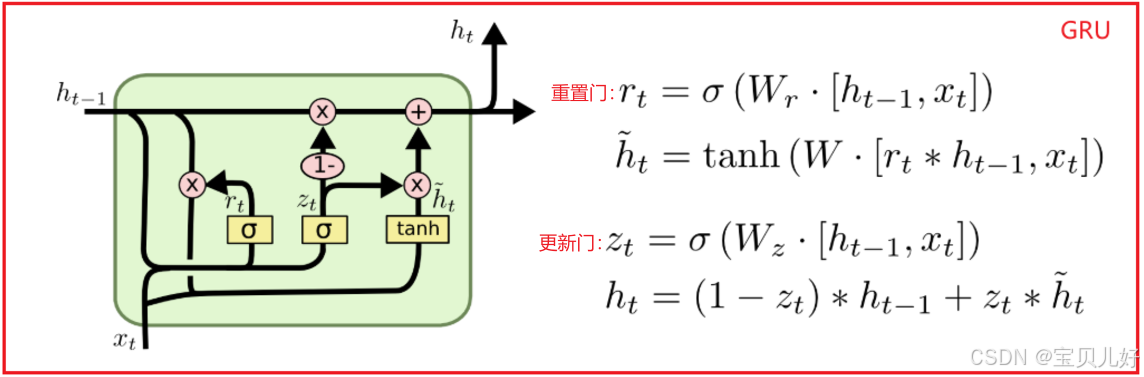
上图是GRU的计算过程。我在网上看很多解读GRU的文章,感觉非常凌乱,一个人一个说法。我这里就大致梳理一下确定的东西:
(1)上图就是GRU网络的一个重复模块。有的资料叫节点,有的叫单元,有的叫循环单元,,,等等各种叫法,所以我们也不用纠结。这里我叫重复模块也是我自己沿用LSTM中的叫法。所以GRU也是和RNN、LSTM一样,都是重复模块在时序维度上的串联结构。
(2)GRU模块的输入只有ht-1和xt。ht-1就可以理解为记忆信息。xt就是时序样本了。
(3)GRU模块的输出只有ht,也就是记忆信息了。
GRU的输入输出都比LSTM简单,LSTM还有一个Ct,所谓的长期记忆。而GRU没有分所谓的长期信息、短期信息,只有一条ht,叫隐藏信息。
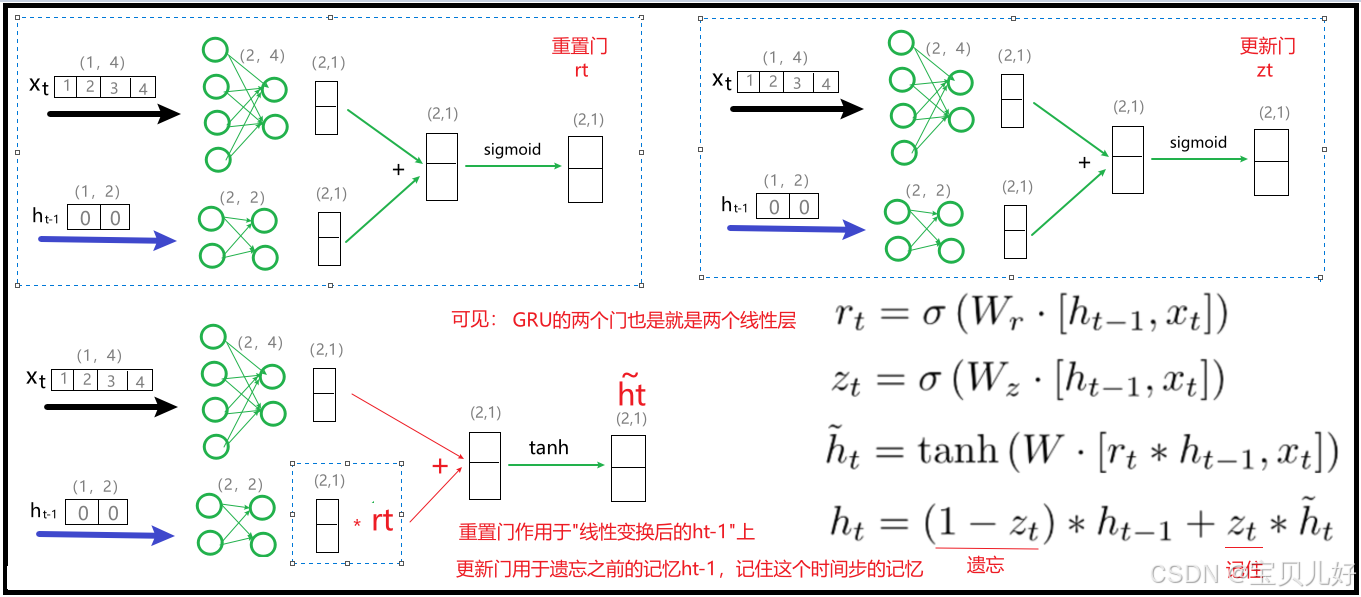
(4)GRU模块只有两个门结构。一个叫重置门(reset gate),一个叫更新门(update gate)。
我个人认为真是没必要纠结这两个门的名称,甚至不用纠结他们的功能有啥区别。因为你单单从名称上看,重置和更新这两个词有啥区别?!似乎没有吧。而看网上很多资料也是解读的五花八门。比如重置门,有人说"用于控制之前的记忆需要保留多少"。而别的人又说"重置门主要决定了到底有多少过去的信息需要遗忘"。哎,笑一会儿,本来记忆和遗忘就是一体两面,非此即彼的。所以一个人一种话术,一篇博客一种理解。所以我就说,我们就不要纠结名称,也不要纠结功能了。
从上图的公式看,其实这两个门,仅仅是两个门而已,它们两个的计算一模一样,输入一模一样,只是使用了两个不同的矩阵线性变换了一下,而且这两个矩阵都是随机生成的,只有在训练过程中,这两个门才会慢慢迭代成其功能的门。所以现在这两个门只是两个门而已,只是两个门系数矩阵而已。
(5)GRU的原理是:学一个重置门rt,让rt先过滤一遍输入的记忆信息ht-1,然后把过滤后的记忆信息和本时间步样本数据一起,用一个线性层+tanh学习一下,变成新的记忆信息ht漂。
然后再学习一个更新门zt,如果说zt是要记住的系数,那1-zt就是要遗忘的系数。
一是,用1-zt乘以更新前的ht-1,就表示该忘记的就彻底忘记了吧,就是又加强了一次忘记。
二是,用zt乘以ht漂,就表示该记住的就一定要记牢,就是又加强了一次记忆。
最后,把"该忘记的就干脆彻底的忘记、该牢记的就是加强记忆"的记忆信息ht输出即可。
如果说zt是要遗忘的系数,那1-zt就是要记住的系数。
1-zt乘以更新前的ht-1,就表示该记住的就一定要记牢,就是又加强了一次记忆。
zt乘以ht漂,就表示该忘记的就彻底忘记了吧,就是又加强了一次忘记。
最后也是把"该忘记的就干脆彻底的忘记、该牢记的就是加强记忆"的记忆信息ht输出即可。
2、pytorch中实现GRU的数据流
GRU的原理基本上就是这样的。我们下面看看pytorch中实现GRU的数据流,来印证我们上面说的原理。
在pytorch.nn下面也有GRU类torch.nn.GRU。我们看看pytorch是如何实现GRU的,也就是从代码角度看看它的数据流:
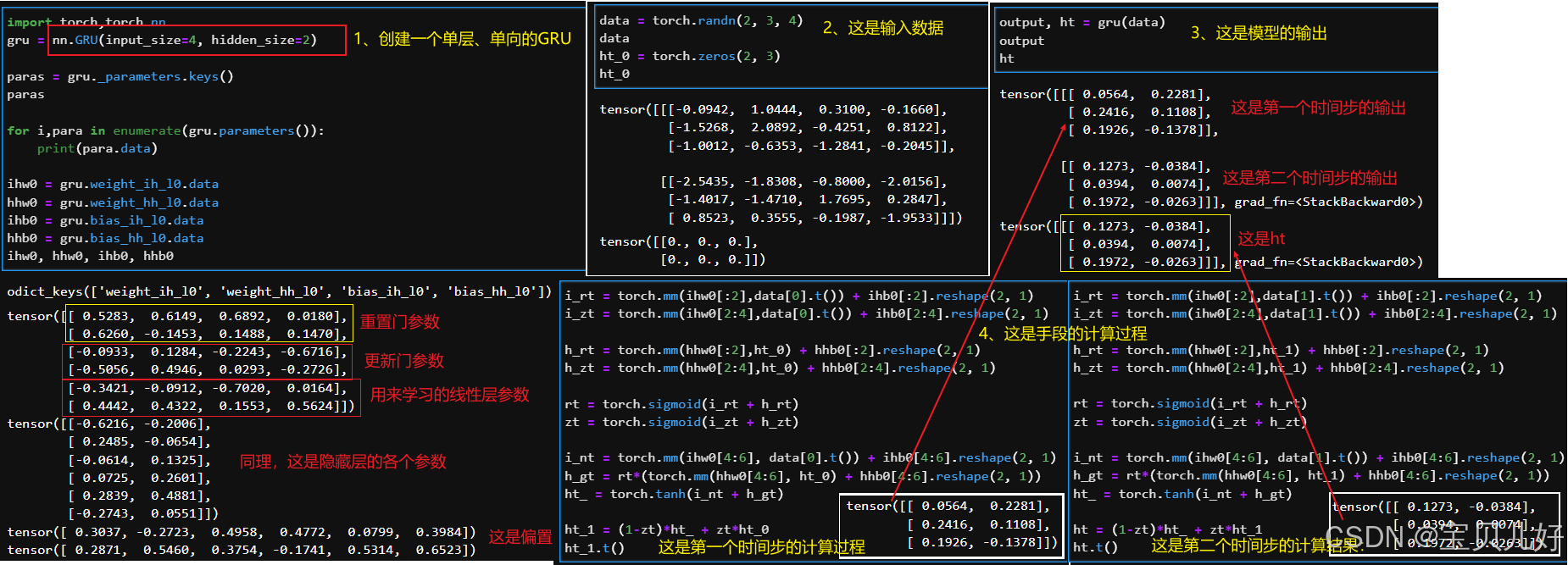
上图我手动计算出来的结果和pytorch计算出来的结果一模一样。说明我们理解的原理没错。但是这里想说的是,这里其实有两个坑,害我找了好半天:
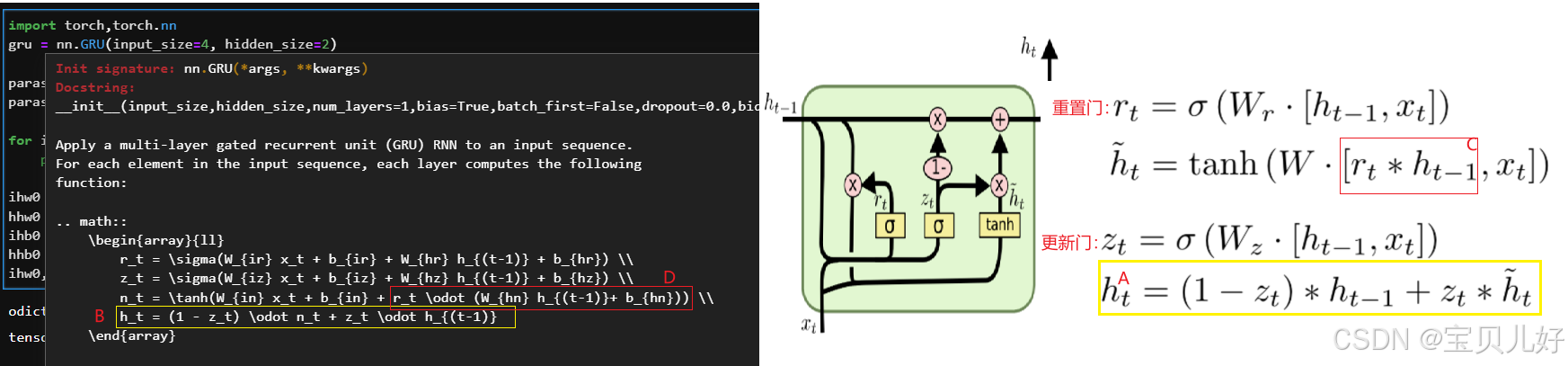
左边的公式是我们讲的公式,但是pytorch使用的公式是右边截图中的公式。两边还是有一些差异的,不知道是pytorch开发人员的失误还是理解错误,A处的公式到B处,它就给ht-1和ht漂换了个位置。这也就是为什么我一开始就强调不要去纠结是遗忘还是忘记,因为遗忘就等于1-记住,记住=1-遗忘,所以就别区分到底是忘记了还是记住了。
第二个坑就是上图的C处,我一开始先计算的rt*ht-1,然后再进行线性变换,一看结果对不上,查看GRU的说明文档才发现,pytorch人家是先线性变换后再乘rt的。
这算是踩的两个坑吧。从这两个坑也可以看出,其实没有特别肯定的做法,每个人都是按照自己的理解去做的。
最后说一嘴,网上很多资料还经常提到GRU是如何避免梯度消失的?如果说lstm是因为并联三条线路来避免梯度消失,那GRU就是利用遗忘=1-记忆,或者说记忆=1-遗忘,这个巧妙地设计来避免梯度消失的。
个人感觉没有其他要深究的了,知道它的数据流,会用,知道可能出现的问题症结在哪里就可以了,其他就没有什么要探索了。本篇是最简单最短的一篇文章了,回头看看是不是再放个小案例。
最后总结一个LSTM和GRU的终极版数据流:
(1)LSTM
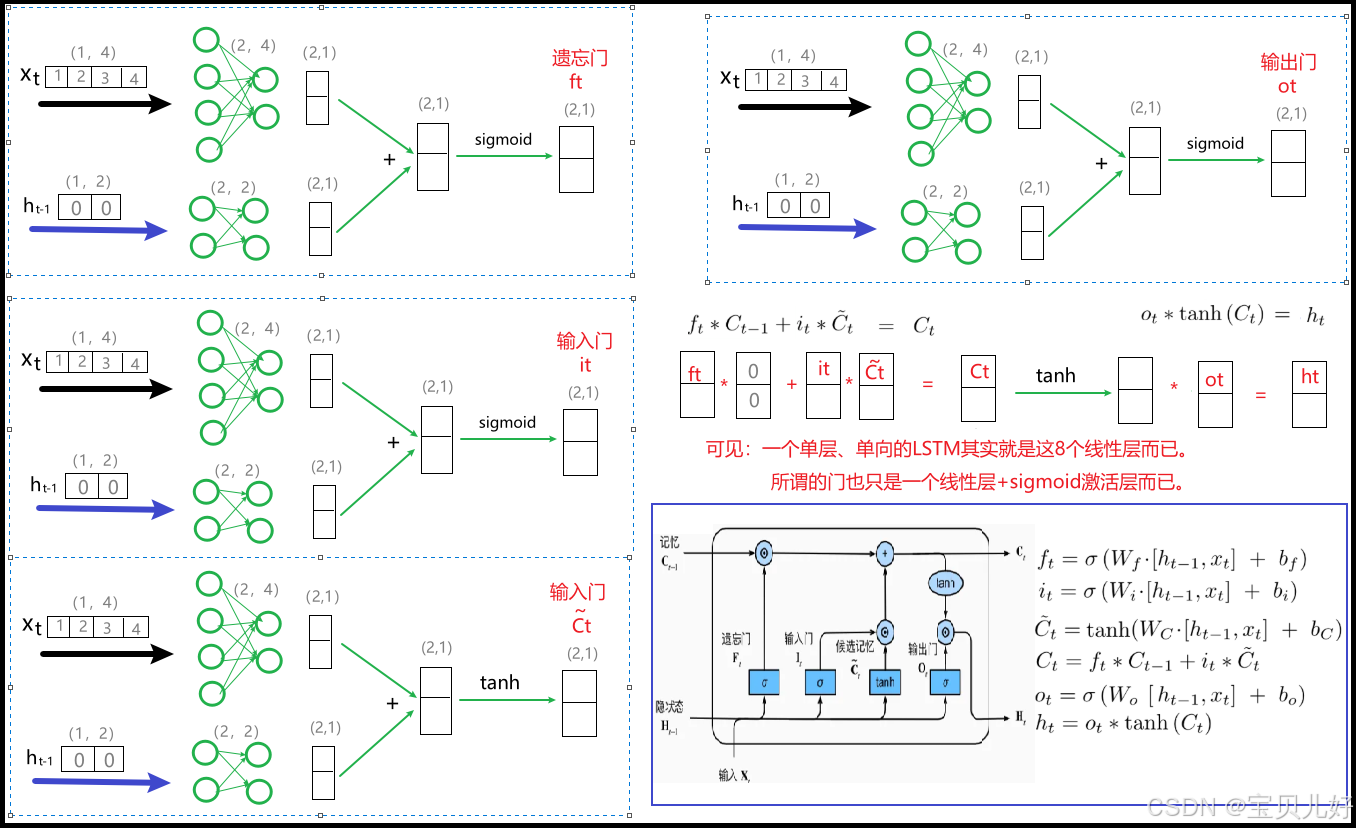
(2)GRU
至此可以说RNN一族的架构就算是讲解完毕了。