上一篇中已经了解了机器学习中一个简单的决策树模型,接下来将通过理论知识的学习,了解如何利用Pandas操作数据。
Pandas操作数据
机器学习项目的首要操作是建模人员要熟悉数据。在这节中,将教大家用Python的Pandas库来操作数据。Pandas是数据科学家用于浏览和操作数据的一个最基础的工具。大多数使用Pandas的人都习惯将pandas简称为‘pd’。
通过这条命令就可以完成该操作:
import pandas as pd
而Pandas库中最重要的是Dataframe。一个DataFrame变量可以存储一个类似与表一样的数据类型。DataFrame就好比是Excel表中的Sheet页、支持SQL的数据库中的表一样,是一个能存储表数据的框架。
Pandas封装了绝大多数你想要对表数据进行的操作。举个例子,来看一下澳大利亚墨尔本的房价数据。在后面的练习中,你可以将同样的操作流程运用到新的数据集,其中有Lowa州的房价数据。
墨尔本的房价数据所在文件目录为:…/input/melbourne-housing-snapshot/melb_data.csv.这个文件目录在实践时,可以根据你自己的情况进行修改,只要与下面的代码中相匹配即可。
# 文件存储路径
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
# pandas读取csv文件
melbourne_data = pd.read_csv(melbourne_file_path)
# 对于数值型变量输出描述性统计结果
melbourne_data.describe()
描述性统计结果如下所示:
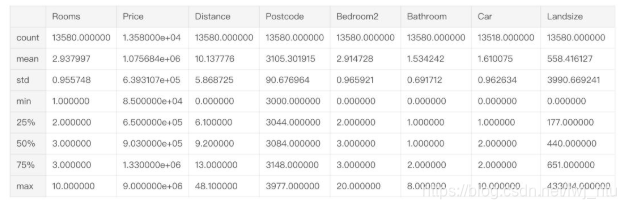
解释描述性统计结果
描述性统计结果给出了原始数据的8个特征值,第一个特征值count,揭示了对于每个列而言,有多少非空的数据行。
缺失值产生的原因有很多,比如在调研一居室时,永远不可能收集到第二个房间的面积数据。关于缺失值,后面会有详细的专业操作。
第二个统计特征mean,即算术平均值。在mean下面是std,即标准差,揭示了数值的离散程度。
为了解释min,25%,50%,75%以及max,先对一组数按照从小到大进行排序。对于这样一个有序数列,第一个值即为最小值。沿着从小到大的顺序,走过此数列长度的25%,你会遇到一个数,这个数值比前25%的值都大,比数列后75%的数值都小。这个数就是该数列的四分之一分位数。50%,即二分位数,75%即四分之三分位数,都是如此定义的。走到数列的末尾,就遇到了该数列的最大值max。
下一节内容,将通过一个练习,手把手完成实操演练.
👏👏👏再看看我们以前的文章😃😃😃
🌺 Excel中数据分析工具库-相关系数篇
🌺 干货,手把手教会你做相关性分析
🌺 5年数据分析路,小结。
🌺 用户细分及画像分析
🌺 K-近邻算法及实践
欢迎关注,微信公众号“数据分析师之家”
扫描二维码 关注我们
💁提供职业规划、简历指导、面试辅导服务哦
QQ交流群:254674155
数据分析之家联合JEE RAY品牌为粉丝派发福利
添加粉丝福利派发官,领取粉丝福利哦

