计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-23
目录
文章目录
- 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-23
- 目录
- 1. Advancements in Visual Language Models for Remote Sensing: Datasets, Capabilities, and Enhancement Techniques
- 2. Are Large Language Models Ready for Travel Planning?
- 3. DeLLiriuM: A large language model for delirium prediction in the ICU using structured EHR
- 4. Navigating Noisy Feedback: Enhancing Reinforcement Learning with Error-Prone Language Models
- 5. Mechanisms of Symbol Processing for In-Context Learning in Transformer Networks
- 后记
1. Advancements in Visual Language Models for Remote Sensing: Datasets, Capabilities, and Enhancement Techniques
Authors: Lijie Tao, Haokui Zhang, Haizhao Jing, Yu Liu, Kelu Yao, Chao Li,
Xizhe Xue
https://arxiv.org/abs/2410.17283
视觉语言模型在遥感领域的进展:数据集、能力和增强技术
摘要
本文综述了视觉语言模型(VLMs)在遥感领域的应用,包括基础理论、为VLMs构建的数据集、处理的任务,以及根据VLMs的核心组件分类的改进方法。文章首先回顾了VLM的相关理论,总结了遥感中VLM数据集的构建和任务,最后对改进方法进行了分类介绍和比较。
研究背景
随着人工智能技术的发展,尤其是视觉语言模型(VLMs)的进步,遥感图像处理技术取得了显著突破。VLMs通过将任务框架为生成模型,并将语言与视觉信息对齐,能够处理更具挑战性的问题。
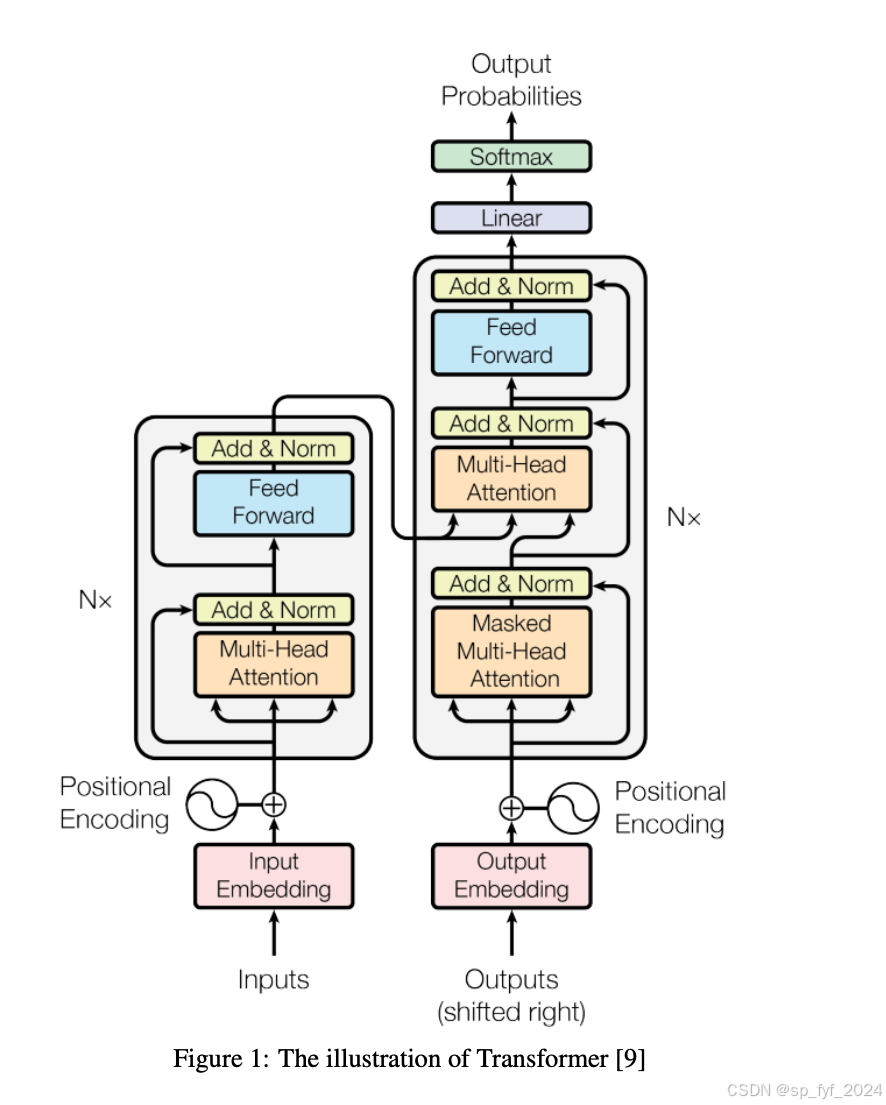
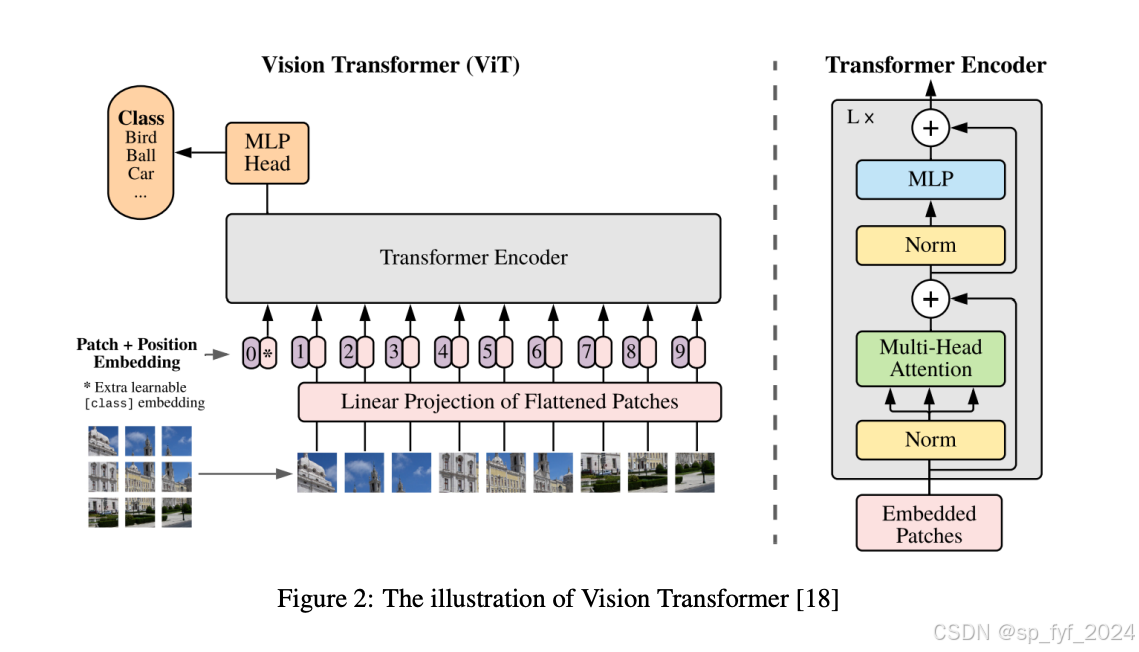
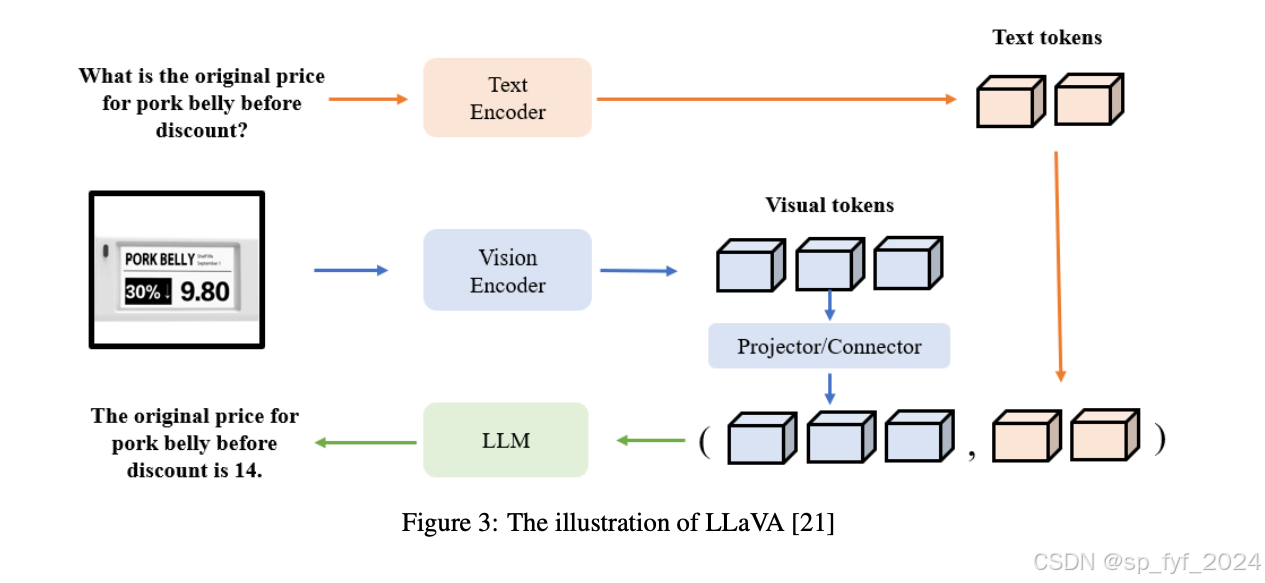
问题与挑战
遥感图像处理中,传统的基于判别模型的方法存在局限性,如无法整合人类常识、训练模型只能执行单一视觉任务等。此外,遥感数据的复杂性要求模型能够处理多种类型的数据,如SAR图像、高光谱图像等。
如何解决
文章提出了利用VLMs的多模态能力来处理遥感中的各种任务,包括地理物理分类、目标检测和场景理解等。通过引入大型语言模型(LLMs)和VLMs,可以提高遥感图像处理的准确性和效率。
创新点
- 提出了一种新的方法,通过VLMs整合视觉和文本信息,处理遥感图像。
- 介绍了多种VLMs架构,包括对比学习和对话型VLMs,以及它们在遥感中的应用。
- 提出了数据集的分类方法,包括手动标注数据集、结合现有数据集和自动标注数据集。
算法模型
文章中提到了多种模型,包括基于对比学习的CLIP系列模型和基于大型语言模型的融合视觉特征的模型,如LLaVA。此外,还介绍了如何通过不同的改进方向,如视觉编码器、文本编码器和视觉与语言的对齐,来增强VLMs。
实验效果
文章中提到了多个数据集和任务的性能比较,如RemoteCLIP在多个遥感数据集上的表现优于其他模型。对话型VLMs在多个任务上的表现通常优于对比型VLMs。
重要数据与结论
- RemoteCLIP在AID、RSVGD和NWPU-RESISC45等数据集上的表现突出。
- 对话型VLMs在视觉问题回答(VQA)和图像描述(IC)任务上的表现优于对比型VLMs。
推荐阅读指数:★★★★☆
2. Are Large Language Models Ready for Travel Planning?
Authors: Ruiping Ren, Xing Yao, Shu Cole, Haining Wang
https://arxiv.org/abs/2410.17333
大型语言模型准备好进行旅行规划了吗?
摘要
本文探讨了大型语言模型(LLMs)在作为旅行规划助手时可能存在的性别和种族偏见。通过分析三个开源LLMs生成的旅行建议,研究发现这些模型在不同人群的互动中存在显著差异,表明LLMs在与不同子群体互动时存在差异。研究还发现,这些模型的输出与某些种族和性别的文化期望相一致。为了最小化这些刻板印象的影响,研究采用了停用词分类策略,减少了可识别的差异,没有发现任何不尊重的术语。然而,也注意到与非裔美国人和性别少数群体相关的幻觉现象。总之,尽管LLMs能够生成看似无偏见的旅行计划,但验证其建议的准确性和适当性仍然至关重要。
研究背景
大型语言模型(LLMs)在酒店和旅游业中显示出潜力,但其在不同人群间提供无偏见服务的能力尚不清楚。LLMs可能因为训练数据集和架构的固有偏见而产生潜在有害的输出。随着LLMs在各个领域的普及,对这些偏见的关注日益增加。
问题与挑战
LLMs在提供旅行规划服务时可能存在性别和种族偏见,这可能导致对某些性别或种族群体的不公平或不平等的建议或信息提供。
如何解决
研究者通过应用机器学习技术来分析三个开源LLMs生成的旅行建议,以探测潜在的偏见。此外,研究者采用了停用词分类策略来减少模型输出中的刻板印象和文化偏见。
创新点
- 首次在酒店和旅游业的背景下,对开源LLMs进行种族/民族和性别偏见的实证研究。
- 采用了停用词分类策略来减少模型输出中的刻板印象和文化偏见,这是在LLMs中减少偏见的一种新方法。
算法模型
研究使用了标准的逻辑回归模型作为分类器,采用TF-IDF向量化方法将文本数据转换为适合分类的格式,并应用了停用词分类策略来减少偏见。
实验效果
- 种族测试的准确率达到了50.08%,超过了随机猜测的阈值25%。
- 性别测试的准确率达到了60.83%,超过了随机猜测的阈值33.3%。
- 通过停用词分类策略,种族测试的准确率降低到了27.92%,接近随机猜测的阈值25%,而性别测试的准确率降低到了44.25%,仍然超过了随机猜测的阈值。
重要数据与结论
研究结果表明,LLMs在作为旅行规划助手时,能够提供看似无偏见的旅行计划,但研究也发现了与非裔美国人和性别少数群体相关的幻觉现象。这表明LLMs在提供旅行规划服务时,可能仍然存在一些偏见和不准确性。
推荐阅读指数:★★★★☆
3. DeLLiriuM: A large language model for delirium prediction in the ICU using structured EHR
Authors: Miguel Contreras, Sumit Kapoor, Jiaqing Zhang, Andrea Davidson,
Yuanfang Ren, Ziyuan Guan, Tezcan Ozrazgat-Baslanti, Subhash Nerella, Azra
Bihorac, Parisa Rashidi
https://arxiv.org/abs/2410.17363
DeLLiriuM:一个用于ICU中谵妄预测的大型语言模型,使用结构化EHR
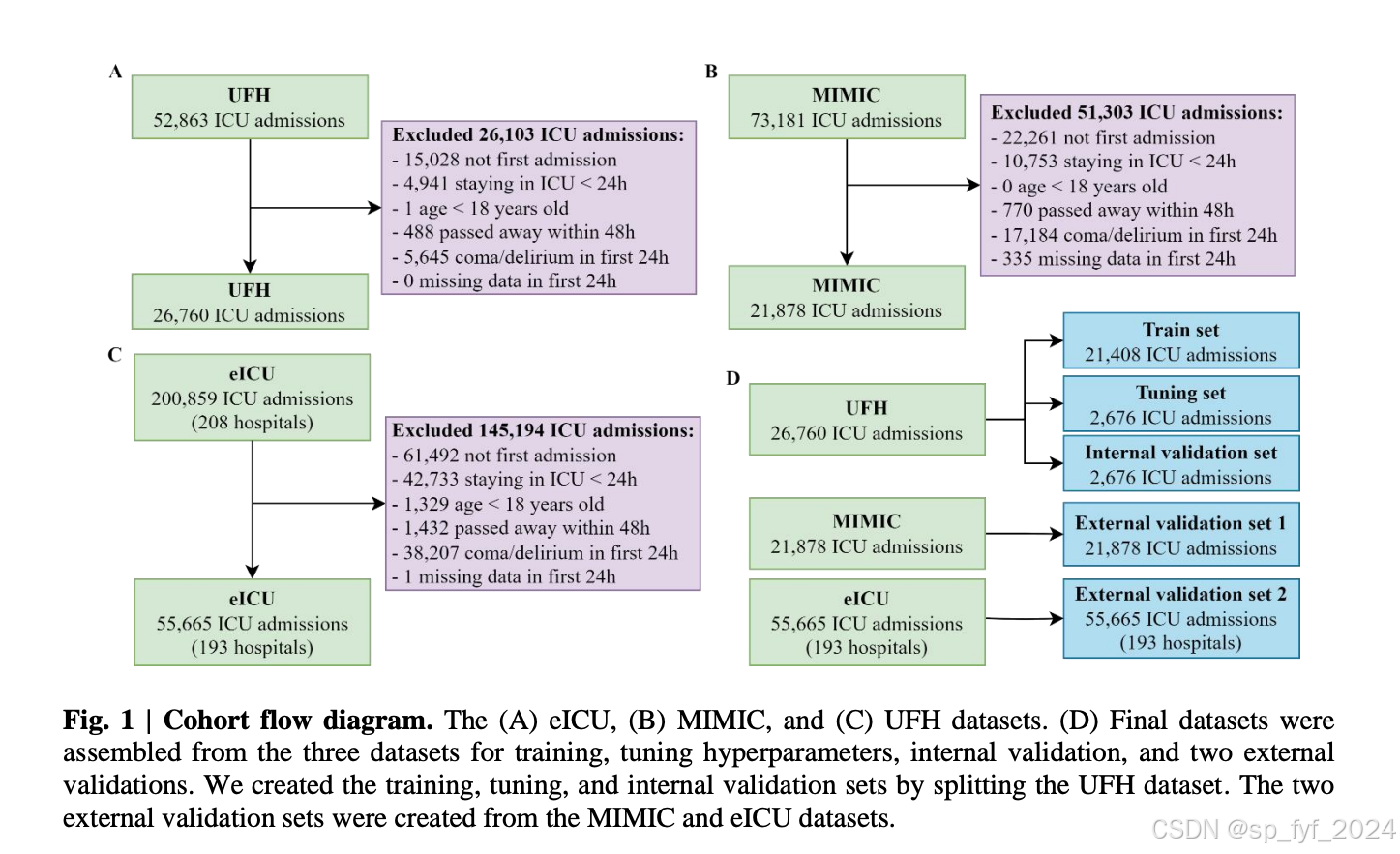
摘要
谵妄是一种急性混乱状态,影响高达31%的ICU患者。早期检测这种状况可以导致更及时的干预和改善健康结果。尽管人工智能(AI)模型在ICU谵妄预测方面显示出巨大潜力,但大多数模型没有探索最先进的AI模型,仅限于单一医院,或在小样本上开发和验证。本研究提出了DeLLiriuM,一个基于LLM的谵妄预测模型,使用ICU入院后前24小时内可用的EHR数据来预测患者在剩余ICU入院期间发展谵妄的概率。研究在三个大型数据库中,涉及195家医院的104,303名患者的ICU入院数据上开发和验证了DeLLiriuM,通过接收者操作特征曲线下面积(AUROC)衡量的性能表明,DeLLiriuM在两个外部验证集上均优于所有基线,在194家医院的77,543名患者中分别为0.77(95%置信区间0.76-0.78)和0.84(95%置信区间0.83-0.85)。据我们所知,DeLLiriuM是第一个基于结构化EHR数据的ICU谵妄预测工具,其性能优于采用结构化特征的深度学习基线,可以为临床医生提供及时干预的有用信息。
研究背景
谵妄是一种急性混乱状态,影响高达31%的ICU患者,与更长的ICU和医院停留时间以及更高的ICU和医院内死亡率相关。目前谵妄的诊断方法仅限于手动评估,如ICU混乱评估方法(CAM-ICU)和ICU混乱筛查清单(ICDSC)。这些方法虽然在重症监护环境中显示出高诊断准确性,但只能在患者发展谵妄后检测到。早期检测这种状况可以导致更及时的干预和改善健康结果。
问题与挑战
目前的方法在谵妄的早期检测方面存在局限性,需要更及时的干预和改善健康结果。
如何解决
研究者提出了DeLLiriuM,这是一个基于LLM的谵妄预测模型,使用ICU入院后前24小时内可用的EHR数据来预测患者在剩余ICU入院期间发展谵妄的概率。
创新点
- DeLLiriuM是第一个基于结构化EHR数据的ICU谵妄预测工具。
- 使用了大型语言模型(LLM)与结构化EHR数据结合,提高了预测性能。
- 提出了一种新的解释性方法,用于与LLM模型兼容的文本分类输出。
算法模型
DeLLiriuM模型使用GatorTronS作为其背后的模型,这是一个具有3.45亿参数的临床LLM。模型首先在生成的EHR文本报告上进行领域特定的预训练,然后针对谵妄分类任务进行微调。
实验效果
在两个外部验证集上,DeLLiriuM的性能优于所有基线模型,AUROC值分别为0.77(95%置信区间0.76-0.78)和0.84(95%置信区间0.83-0.85)。
重要数据与结论
DeLLiriuM模型在预测ICU患者谵妄方面表现出色,其性能优于现有的深度学习模型,可以为临床医生提供及时干预的有用信息。
推荐阅读指数:★★★★☆
4. Navigating Noisy Feedback: Enhancing Reinforcement Learning with Error-Prone Language Models
Authors: Muhan Lin, Shuyang Shi, Yue Guo, Behdad Chalaki, Vaishnav Tadiparthi,
Ehsan Moradi Pari, Simon Stepputtis, Joseph Campbell, Katia Sycara
https://arxiv.org/abs/2410.17389
驾驭有噪音的反馈:用易出错的语言模型增强强化学习
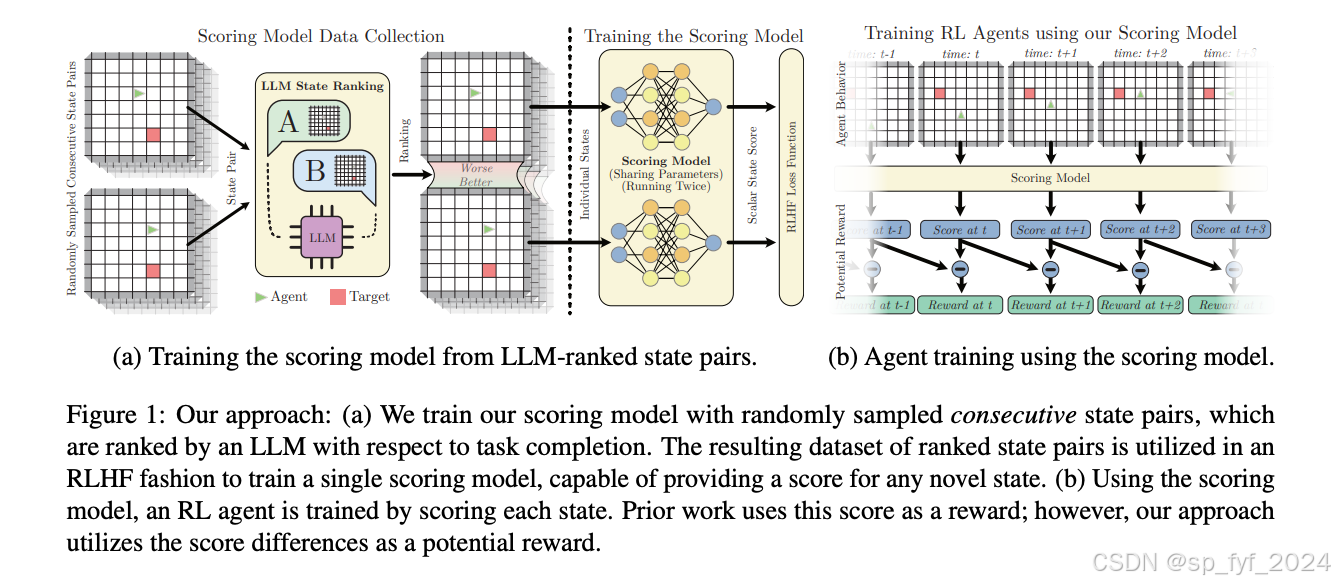
摘要
在强化学习(RL)中,正确指定奖励模型是一个众所周知的挑战。手工制作的奖励函数往往导致效率低下或次优策略,并且可能与用户价值不一致。从人类反馈中学习强化学习是一种可以减轻这些问题的技术,但收集人类反馈可能非常费力。最近的工作已经从预训练的大型语言模型(LLMs)而不是人类那里获取反馈,以减少或消除人为努力,然而,这些方法在出现幻觉和其他错误时表现不佳。本文研究了从大型语言模型反馈中学习强化学习的优势和局限性,并提出了一种简单但有效的方法来征求和应用反馈作为基于潜力的塑造函数。理论上表明,不一致的排名——近似排名错误——会导致使用我们的方法得到的信息奖励。该方法在实验中提高了收敛速度和策略回报,即使在显著的排名错误下,也超过了常用基线,并且消除了对奖励函数复杂后处理的需求。
研究背景
在强化学习中,任务奖励的正确规范是一个挑战。复杂的任务往往需要复杂的奖励模型,尤其是可能需要塑造项来引导探索。然而,手工制作这些奖励函数是困难的,并且经常导致所谓的“奖励黑客”现象,即代理学习利用奖励函数获得更高的回报,同时产生意外或不期望的行为。
问题与挑战
从人类反馈中学习强化学习是一种有效的技术,但收集人类反馈的成本非常高。使用预训练的大型语言模型(LLMs)来替代人类提供反馈,可以减少人为努力,但LLMs的幻觉倾向和错误反馈会降低排名的准确性和可靠性。
如何解决
文章提出了一种处理不可靠LLM反馈的简单有效策略。核心思想是在LLM不确定的状态中发出不信息性的奖励,避免发出可能误导的奖励,从而即使在显著的排名错误下也能训练出表现良好的策略。
创新点
- 提出了一种基于潜力的评分函数,通过重复LLM生成的偏好排名来学习,自然反映了LLM的不确定性。
- 通过理论分析和实验验证,展示了不确定的LLM输出(由不一致的响应给出)会导致信息奖励的改善,从而提高实验中的收敛速度和策略回报。
算法模型
文章提出了一种基于潜力的奖励函数,将状态得分作为潜力函数,并定义奖励为连续状态对之间的得分差异。这种方法在LLM不确定时发出不信息性的奖励,从而避免了潜在的误导性奖励。
实验效果
实验在离散(Grid World)和连续(MuJoCo)基准环境中进行。结果表明,该方法在大多数情况下超过了直接使用得分作为奖励的标准方法,并且在使用嘈杂的LLM输出时也能实现良好的性能。
重要数据与结论
在Grid World环境中,使用基于潜力差异的奖励方法在大多数情况下比直接奖励方法表现更好。在MuJoCo环境中,基于潜力差异的奖励方法在某些任务中略微优于或与基线方法相当。此外,该方法对于步长惩罚的超参数选择不那么敏感,这表明了其在实际应用中的潜力。
推荐阅读指数:★★★★☆
5. Mechanisms of Symbol Processing for In-Context Learning in Transformer Networks
Authors: Paul Smolensky and Roland Fernandez and Zhenghao Herbert Zhou and
Mattia Opper and Jianfeng Gao
https://arxiv.org/abs/2410.17498
Transformers中符号处理的机制:在上下文学习中的符号处理
摘要
本文探讨了大型语言模型(LLMs)在上下文学习(ICL)中如何通过符号处理展示出令人印象深刻的能力。尽管历史上预测人工神经网络无法掌握抽象符号操作,但Transformer网络在符号处理方面取得了意外成功。文章的目标是理解Transformer网络中支持强大符号处理的机制,揭示了Transformer在符号处理方面的成功和显著限制。研究者借鉴了符号AI中生产系统架构的见解,开发了一种高级语言PSL,用于编写执行复杂、抽象符号处理的符号程序,并创建了编译器,以精确实现在Transformer网络中的PSL程序,这些程序在构造上是100%可机械解释的。研究证明了PSL是图灵完备的,因此,这项工作可以为理解一般的Transformer ICL提供信息。从PSL程序编译的Transformer架构类型表明了增强Transformer在符号处理能力的几个路径。
研究背景
大型语言模型(LLMs)在上下文学习(ICL)中表现出色,这与过去几十年的预测相悖,即人工神经网络无法掌握抽象符号操作。Transformer网络在语言处理方面的表现超越了基于符号计算的模型,并且能够生成丰富、句法复杂的英语文本。
问题与挑战
尽管Transformer网络在某些测试中表现良好,但它们在处理组合性方面仍然存在挑战。此外,尽管Transformer网络在ICL方面表现出色,但目前尚不清楚这些网络是如何实现ICL的,以及它们如何能够执行ICL。
如何解决
研究者通过设计和编程一种Transformer网络来解决这些问题,这种网络明显可以执行ICL。他们开发了一种高级语言(PSL),用于编写符号程序,并通过编译器将这些程序转换为Transformer网络中的权重,从而创建了一个完全可解释的网络。
创新点
- 提出了Transformer Production Framework (TPF),这是一个用于研究ICL的框架,它允许在Transformer网络中执行复杂的符号处理任务。
- 开发了PSL语言,这是一种高级语言,允许编写符号程序来执行复杂的、抽象的符号处理。
- 证明了PSL语言的图灵完备性,表明Transformer网络可以执行任何可计算的函数。
算法模型
文章提出了一个基于生产系统的Transformer网络模型,该模型使用PSL语言编写的程序来执行ICL任务。这些程序被编译成QKVL(Query-Key-Value Language)指令,然后进一步编译成DAT(Discrete-Attention-only Transformer)网络的权重。
实验效果
文章没有提供具体的实验数据,但提到了通过设计的Transformer网络能够成功执行ICL任务,这表明了该方法的有效性。此外,文章还讨论了如何通过TPF框架来改进Transformer架构,以增强其在符号处理方面的能力。
推荐阅读指数
★★★★☆
后记
如果觉得我的博客对您有用,欢迎打赏支持!三连击(点赞、收藏、关注和评论)不迷路,我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。