【大语言模型】ACL2024论文-38 从信息瓶颈视角有效过滤检索增强生成中的噪声
目录
《An Information Bottleneck Perspective for Effective Noise Filtering on Retrieval-Augmented Generation》
从信息瓶颈视角有效过滤检索增强生成中的噪声
https://arxiv.org/abs/2406.01549

-
概览
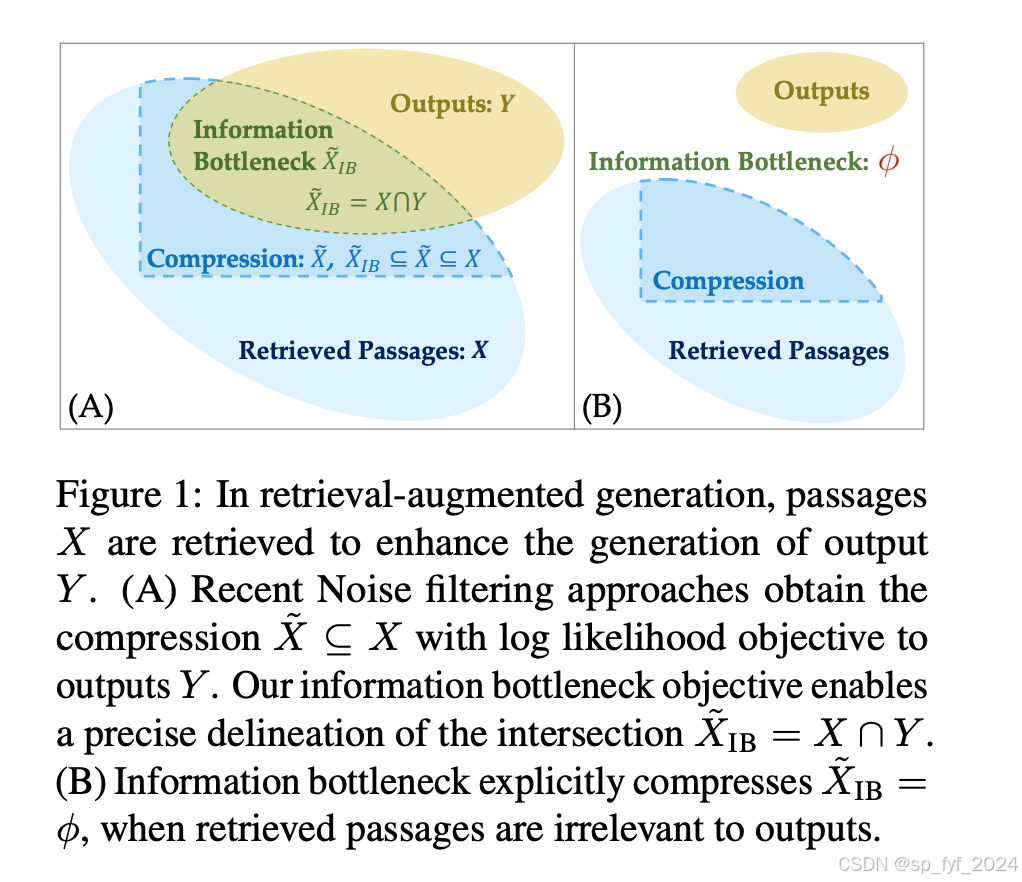
本文旨在解决检索增强生成(Retrieval-Augmented Generation, RAG)任务中面对现实世界噪声数据时的挑战。尽管RAG结合了大型语言模型(LLMs)和从广泛语料库中检索到的相关信息,但在处理噪声数据时仍面临困难。现有的解决方案是训练一个过滤模块来寻找相关内容,但这种方法在噪声压缩方面效果不佳。本文提出将信息瓶颈(Information Bottleneck, IB)理论引入RAG,通过同时最大化压缩内容与输出之间的互信息,同时最小化压缩内容与检索到的段落之间的互信息,从而有效过滤噪声。实验结果表明,该方法在多个问答数据集上取得了显著的改进,不仅提高了答案生成的正确性,还实现了2.5%的压缩率。
-
论文研究背景、技术背景和发展历史
大型语言模型(LLMs)在自然语言理解和生成方面取得了显著进展,能够以无与伦比的规模和复杂性处理和生成类人文本。然而,LLMs存在一些缺点,如幻觉(hallucination)和缺乏特定领域或高度专业查询的知识。检索增强生成(RAG)通过在推理阶段结合外部知识源的信息,提高了文本生成的相关性、连贯性和事实准确性。RAG在实际应用中也面临问题,一方面,检索器的效果可能不佳;另一方面,互联网数据通常质量低下,存在冗余和噪声。最近的解决方案通过采用过滤模块来减轻检索证据中的噪声,但这些方法存在几个问题:无法确保过滤结果能有效支持生成模型准确回答问题;难以指导过滤器在面对不支持问题解决的检索证据时保持沉默;缺乏对过滤结果压缩程度的适应性,阻碍了成本性能最优解的实现。 -
技术挑战
在检索增强生成的发展中,面临的主要技术挑战包括:
模型微调的资源消耗:为了使检索模型能够理解对话形式的文本,需要在视觉对话数据上进行微调,这一过程资源密集且难以扩展。
生成问题的相关性和冗余性:LLM提问者在没有查看图像候选者的情况下,可能会生成与目标图像无关的问题,或者生成冗余的问题,这些问题不会为后续的检索提供有价值的信息。
评估指标的局限性:现有的评估指标如Recall@K和Hits@K在评估交互式检索系统时存在不足,未能充分考虑用户满意度、效率和排名提升的重要性。 -
如何破局
针对上述技术挑战,本文提出了以下解决方案:
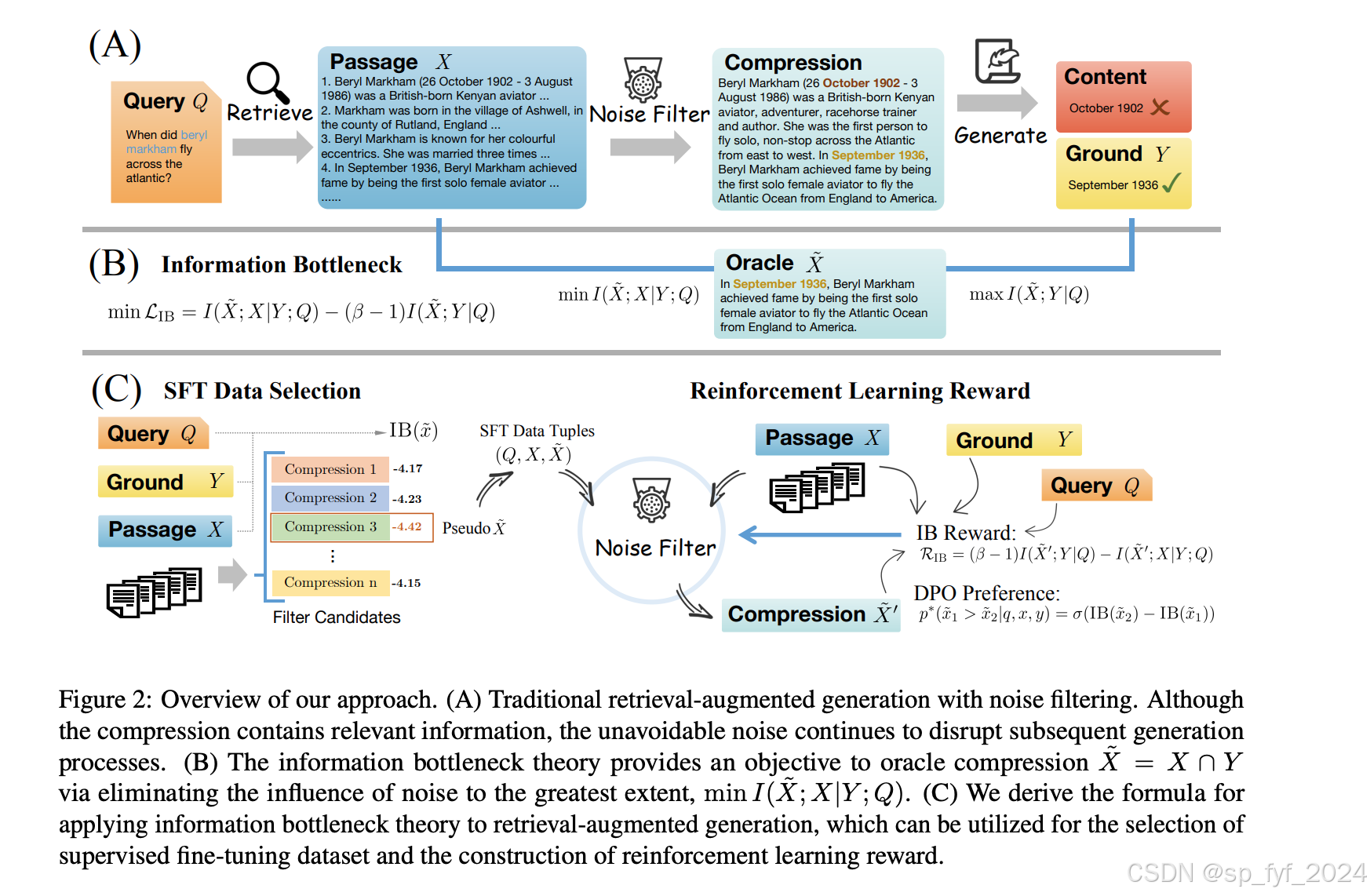
引入信息瓶颈理论:利用信息瓶颈理论优化噪声过滤器,通过同时最大化有用信息的同时最小化噪声,从而精确界定交集X ∩ Y。
信息瓶颈公式的推导:推导信息瓶颈公式,便于其在新的综合评估、监督微调数据选择和强化学习奖励构建中的应用。
实验验证:在开放域问答数据集上进行实验,证明了该方法的有效性,与强大的基线模型相比,取得了显著的改进。
-
技术应用
实验设置
实验在Natural Questions(NQ)、TRIVIAQA和HOTPOTQA三个问答基准数据集上进行,使用对抗性密集段落检索器(DPR)从所有维基百科段落中检索前5个段落。使用LLAMA2作为大型语言模型的骨干架构,对7B模型版本进行微调以进行噪声过滤。实验中使用了多种评估指标,包括Exact Match(EM)、F1分数和信息瓶颈(IB)分数,以全面评估生成内容的简洁性和正确性。
潜在应用
本文的方法在问答系统、文本生成和信息检索等领域具有潜在应用。通过有效过滤噪声,可以提高生成文本的质量和相关性,减少计算资源的消耗,提高系统的效率和性能。 -
主要相关工作与参考文献
本文与多个领域的研究相关,包括信息瓶颈理论、噪声过滤、检索增强生成等。主要相关工作包括:
信息瓶颈理论:Tishby等人提出的信息瓶颈理论,旨在通过最小化信息来实现数据压缩和信息保留的平衡。
噪声过滤:现有的噪声过滤方法,如FLARE、Self-RAG、REPLUG等,通过训练模型主动检索和过滤内容,但这些方法缺乏对压缩结果的统一评估。
检索增强生成:Lewis等人提出的检索增强生成方法,通过结合检索方法和生成模型,提高了文本生成的相关性和准确性。 -
后续优化方向
尽管本文的方法在噪声过滤任务中取得了显著效果,但仍有一些优化方向:
性能依赖:该方法的性能依赖于生成器的质量,需要进一步优化生成器以提高整体性能。
True-Flip-Rate(TFR)和False-Flip-Rate(FFR)的平衡:通过引入额外的预测标志来评估当前过滤结果的必要性,成功降低了TFR,但可能以降低FFR为代价。可以通过更多的训练迭代来缓解这一问题,但这也导致了训练成本的增加。
多模态融合:探索如何更有效地融合文本、图像和其他模态的信息,以进一步提升检索性能。
本文通过引入信息瓶颈理论,为检索增强生成中的噪声过滤问题提供了一种新的解决方案,不仅提高了生成内容的质量和相关性,还减少了计算资源的消耗,具有重要的理论和实践意义。
后记
如果您对我的博客内容感兴趣,欢迎三连击 ( 点赞、收藏和关注 )和留下您的评论,我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。