Part1 MindSpore模块(7题):
1、MindSpore深度学习框架的候选运行时支持多种硬件平台,包括CPU、GPU、NPU等。以下关于MindSpore后端的描述中,正确的有哪些项?(多选题)
A.MindSpore后端运行时负责将计算图转换为对应硬件平台的执行指令,同时进行硬件相关的优化
B.MindSpore后端运行时可以根据用户的需求,动态地选择合适的硬件平台进行计算
C.MindSpore后端运行时可以实现跨硬件平台的数据传输和同步,保证计算的正确性和一致性
D.MindSpore后端运行时可以根据硬件平台的特性,自动地调整计算图的结构和参数,提高计算的效率和精度
正确答案:AC
2、MindSpore是一个全场景深度学习框架,提供了丰富的数据处理和数据增强的功能。MindSpore数据处理的核心是Dataset类,它可以从不同的数据源加载数据,并支持多种数据处理操作,如复制、分批、混洗、映射等。以下关于MindSpore数据处理的描述中,正确的是哪一项?(单选题)
A.Dataset类只能从文件系统中加载数据,不支持从内存中或网络中加载数据
B.Dataset类可以通过map函数对数据进行映射操作,用户可以自定义函数或使用transforms模块提供的算子
C.Dataset类可以通过batch函数对数据进行分批操作,但是不支持将不足一批的数据截掉
D.Dataset类可以通过shuffle函数对数据进行混洗操作,混洗程度由参数buffer_size设定,buffer_size越大,混洗时间越短,可节约计算资源消耗
正确答案:B
3、MindSpore是一个全场景深度学习框架,提供了丰富的模型层、损失函数、优化器等组件,帮助用户快速构建神经网络。MindSpore神经网络构建的核心是Cell类,它是所有网络的基类,也是网络的基本单元。以下关于MindSpore神经网络构建的描述中,正确的有哪些项?(多选题)
A.自定义网络时,需要继承Cell类,并重写__init__方法和construct方法
B.Cell类重写了__call__方法,在Cell类的实例被调用时,会执行construct方法
C.Cell类可以通过requires_grad方法指定网络是否需要微分求梯度,在不传入参数调用时,默认设置requires_grad为False
D.Cell类可以通过set_train方法指定模型是否为训练模式,在不传入参数调用时,默认设置mode属性为False
正确答案:AB
4、MindSpore提供了丰富的网络构建和优化的功能。MindSpore网络优化的核心是Optimizer类,它可以对网络的可训练参数进行梯度更新,并支持多种优化算法,如SGD、Adam、Momentum等。以下关于MindSpore网络优化的描述中,正确的是哪一项?(单选题)
A.Optimizer类只能对网络的权重参数进行优化,不支持对偏置参数进行优化
B.Optimizer类可以通过参数learning_rate设置学习率策略,支持固定的学习率或动态的学习率
C.Optimizer类无需参数分组即可通过参数parameters对不同的参数配置不同的学习率、权重衰减和梯度中心化策略
D.Optimizer类可以通过clip类算子对梯度进行裁剪操作,如果要将输入的Tensor值裁剪到最大值和最小值之间,可以用clip_by_global_norm
正确答案:B
5、MindSpore提供了多种模型迁移工具,如MindSpore Dev Toolkit、TroubleShooter等,支持将神经网络从其他主流深度学习框架快速迁移到MindSpore进行二次开发和调优。以下有关MindSpore网络迁移的流程描述中,正确的是哪一项?(单选题)
A.网络脚本开发;
B.网络脚本分析;
C.网络执行调试;
D.网络精度性能调优;
E.MindSpore环境配置
A.ECBAD B.EBACD C.EDCBA D.EABCD
正确答案:B
6、以下关于MindSpore的统一模型文件MindIR的描述中,正确的有哪些项?(多选题)
A.MindIR同时存储了网络结构和权重参数
B.同一MindIR文件支持多种硬形态的部署
C.支持云侧(训练)和端侧(推理)任务
D.MindIR模型与硬件平台解耦,实现一次训练多次部署
正确答案:ABCD
7、如图所示,在使用MindSpore构建的残差网络中,以下关于该段代码的描述中,正确的有哪些项?(多选题)
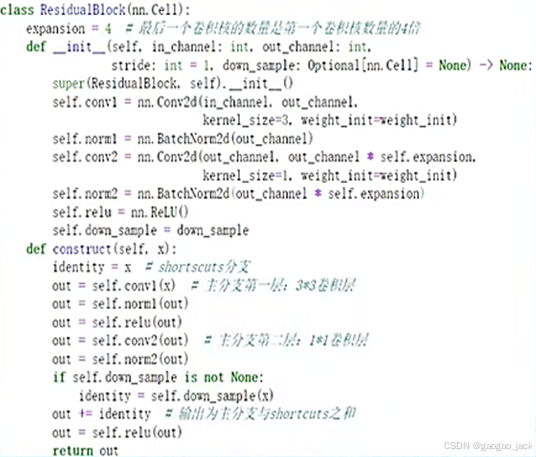
A.结构的主分支有两层卷积结构
B.主分支第二层卷积层通过大小1×1的卷积核进行升维
C.主分支与shortcuts输出的特征矩阵相加时,需要保证主分支与shortcuts输出的特征矩阵shape相同
D.该段代码可以正常运行的前提条件是要求in_channel = out_channel*2
正确答案:ABC
Part2 昇腾全栈AI平台模块(5题):
1、以下关于达芬奇架构(AI Core)中的硬件架构且对应的功能介绍中,不正确是哪一项?(单选题)
A.达芬奇架构(AI Core)包括计算单元、存储单元。计算单元:包含两种基础计算资源(矢量计算单元、向量计算单元)﹔存储系统: AI Core的片上存储单元和相应的数据通路构成了存储系统
B.达芬奇架构这一专门为AI算力提升所研发的架构,是昇腾AI计算引擎和AI处理器的核心所在
C.矩阵计算单元和累加器主要完成矩阵相关运算。一拍完成一个fp16的16×16与16×16矩阵乘(4096)
D.累加器:把当前矩阵乘的结果与前次计算的中间结果相加,可以用于完成卷积中加bias操作
正确答案:A
2、以下关于CANN的描述中,不正确的是哪一项?(单选题)
A.AscendCL接口是昇腾计算开放编程框架,是对底层昇腾计算服务接口的封装。它提供设备管理、上下文管理、流管理、内存管理等API库,只能供用户在MindSpore框架上开发人工智能应用。
B.昇腾计算服务层:主要提供昇腾算子库AOL,通过神经网络库、线性代数计算库(BLAS)等高性能算子加速计算;昇腾调优引擎AOE,通过算子调优OPAT、子图调优SGAT、梯度调优GDAT、模型压缩AMCT提升模型端到端运行速度。
C.昇腾计算编译层:昇腾计算编译层通过图编译器(Graph Compiler)将用户输入中间表达(Intermediate Representation,IR)的计算图编译成昇腾硬件可执行模型;同时借助张量加速引擎TBE (Tensor Boost Engine)的自动调度机制,高效编译算子。
D.昇腾计算执行层:负责模型和算子的执行,提供运行时库(Runtime)、图执行器(Graph Executor)、数字视觉预处理(Digital Vision Pre-Processing,DVPP)、人工智能预处理(Artificial Intelligence Pre-Processing,AIPP)、华为集合通信库(Huawei Collective Communication Library, HCCL)等功能单元。
正确答案:A
3、以下有关CANN层相关的内容描述中,正确的是哪些项?(多选题)
A.CANN是华为提出的异构的计算架构,包括AscendCL、GE、Runtime、DVPP、AI Core等部分
B. AscendCL (Ascend Computing Language,昇腾计算语言),是华为提供的一套用于在昇腾系列处理器上进行加速计算的API,能够管理和使用昇腾软硬件计算资源,并进行机器学习相关计算
C.当前AscendCL为您提供了C/C++和Python编程接口,负责模型加载、算子能力开放和Runtime开放
D.AscendCL提供分层开放能力的管控,通过不同的组件对不同的使能部件进行对接。包含GE能力开放、算子能力开放、Runtime能力开放、Driver能力开放等
正确答案:BCD
4、AscendCL是CANN层中很重要的一个环节,提供分层开放能力的管控,可以对不同的使能部件进行对接。以下哪些选项是正确的AscendCL的软件开发流程?(多选题)
A.准备环境->开发场景分析->编译运行应用->资源初始化->资源释放
B.资源初始化->数据传输到Device->数据预处理->模型推理->数据后处理
C.开发场景分析->创建代码目录->资源初始化->数据传输->数据预处理->模型推理
D.数据预处理->模型推理->资源释放->数据后处理->编译运行应用
正确答案:BC
5、以下关于AscendCL相关概念和开发流程描述中,正确的有哪些项?(多选题)
A.pyACL(Python Ascend Computing Language)是在AscendCL的基础上使用C++语言封装得到的Python API库,使用户可以通过Python进行昇腾AI处理器的运行管理、资源管理等。应用程序通过pyACL调用AscendCL层,进行模型加载等功能的实现
B.AscendCL提供Device管理、Context管理、Stream管理、内存管理、模型加载与执行、算子加载与执行、媒体数据处理等C/C++/Python (pyACL)API库供用户开发深度神经网络应用,用于实现目标识别、图像分类等功能
C.在运行应用时,AscendCL调用FE执行器提供的接口实现模型和算子的加载与执行、调用运行管理器的接口实现Device管理、Context管理、Stream管理、内存管理等
D.动态分辨率指的是在某些场景下,模型每次输入的Batch数或分辨率是不固定的,如检测出人脸后再执行人脸识别网络,由于人脸个数不固定导致人脸识别网络输入BatchSize不固定
正确答案:BD
Part3 昇腾AI应用实践模块(8题):
1、实现无人驾驶需要使用人工智能、传感器、控制器等多种技术来解决车辆自动驾驶或辅助驾驶中的环境感知、地图定位、规划决策、控制执行等四大问题。在无人驾驶中,以下哪一项是使用生成对抗网络算法的主要目的?(单选题)
A.规划驾驶路径,使智能车辆根据当前的路况采取合适的路径规划策略
B.识别道路和交通标志,辅助智能车辆感知环境,获取自身定位
C.增强驾驶场景模拟数据,用于感知车辆周围环境的机器视觉模型的训练和调优D.调优驾驶控制参数,提升智能车辆在固定场景中的驾乘体验
正确答案:C
2、小张在使用MindSpore构建网络的过程中(本地设备,基于Atlas 300I Duo的设备),为了方便调试,可以在程序中加入哪行代码?(单选题)
A.mindspore.set_context(mode=mindspore.PYNATIVE_MODE, device_target='NPU')
B.mindspore.set_context(mode="Graph", device_target='GPU’)
C.mindspore.set_context(mode=mindspore.PYNATIVE_MODE, device_target='Ascend')
D.mindspore.set_context(mode="PyNative", device_target='NPU’)
正确答案:C
3、卷积神经网络中1×1卷积的作用包含以下哪些项?(多选题)
A.控制输出特征图的通道数
B.融合不同特征图之间的信息
C.提供防止过拟合的能力
D.调节超参数
正确答案:AB
4、在自然语言处理任务中,以下有关处理输入输出长度不同问题的描述中,不正确的是哪一项?(单选题)
A. Seq2Seq方法,Seq2Seq可以用来处理输入输出序列不等长的问题,是一种特殊的RNN模型。
B. Attention注意力模型和self-Attention自注意力机制,核心逻辑就是从关注全部到关注重点,可以用于Seq2Seq方法中,用作机器翻译等任务。
C. BIRNN或者BILSTM等双向RNN结构,由前向RNN与后向RNN组合而成。考虑到词语在句子中前后顺序,更好学习双向的语义依赖,可以用在Seq2Seq网络中。
D.Seq2Seq属于encoder-decoder结构的一种,常见的encoder-decoder结构基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输出序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为解码,传递给decoder模块进行编码。
正确答案:D
5、以下关于MindSpore的统一模型文件MindIR的描述中,正确的有哪些项?(多选题)
A. MindIR同时存储了网络结构和权重参数。中间表示(IR)是程序编译过程中介于源语言和目标语言之间的程序表示,以方便编译器进行程序分析和优化,因此IR的设计需要考虑从源语言到目标语言的转换难度,同时考虑程序分析和优化的易用性和性能。
B.同一MindIR文件支持多种硬形态的部署。MindIR是一种基于图表示的函数式IR,其最核心的目的是服务于自动微分变换。
C.在图模式mindspore.set_context(mode=mindspore.GRAPH_MODE)下运行用MindSpore编写的模型时,若配置中设置了mindspore.set_context(save_graphs=True),运行时会输出一些图编译过程中生成的一些中间文件,我们称为IR文件。
D.在MindIR中,一个函数图(FuncGraph)表示一个普通函数的定义,函数图一般由ParameterNode、ValueNode和CNode组成有向无环图,可以清晰地表达出从参数到返回值的计算过程。
正确答案:ABCD
6、以下关于Transformer网络结构的描述中,不正确的是哪个选项?(单选题)
A.2017年,谷歌机器翻译团队发表的《Attention is All You Need》中,提出了Transformer,完全抛弃了RNN(Recurrent Neural Network,循环神经网络)和CNN (Convolutional Neural Networks,卷积神经网络)等网络结构,而仅仅采用Attention机制来进行机器翻译任务,并且取得了很好的效果,注意力机制也成为了大家近期的研究热点。
B.Encoder是由Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm组成的,不需要残差结构和卷积计算,Encoder包含N个相同的layer,layer指的就是多头自注意力机制单元。
C.将Encoder输出的编码信息矩阵C传递到Decoder中,Decoder依次会根据当前翻译过的1~i的单词翻译第i+1个单词。
D.对于Transformer来说,由于句子中的词语都是同时进入网络进行处理,顺序信息在输入网络时就已丢失。因此,Transformer是需要额外的处理来告知每个词语的相对位置的。其中的一个解决方案,就是论文中提到的位置编码(Positional Encoding),将能表示位置信息的编码添加到输入中,让网络知道每个词的位置和顺序。
正确答案:B
7、以下关于自注意机制描述中,正确的是哪些选项?(多选题)
A.QKV这三个向量是通过输入表示与三个权重矩阵相乘后创建的。这些新向量在维度上比词嵌入向量更低,他们的维度是64,而词嵌入和编码器的输入/输出向量的维度是512。但实际上不强求维度更小,这只是一种基于架构上的选择,它可以使多头注意力(multi-head attention)的大部分计算保持不变。
B.计算自注意力的第二步是计算得分。假设我们在为这个例子中的第一个词“机器”计算自注意力向量,我们需要拿输入句子中的每个单词对“机器”打分,这些分数决定了在编码单词“机器”的过程中有多重视句子的其它部分。这些分数是通过打分单词(所有输入句子的单词)的键向量与“机器”的查询向量相点积来计算的。所以如果我们是处理位置最靠前的词的自注意力的话,第一个分数是q1和k1的点积,第二个分数是q1和k2的点积。
C.自注意力机制第三步,归一化,将分数除以8(向量维度的平方根),然后通过Softmax计算每一个单词对于其他单词的attention系数。
D.在每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接,并且都跟随着一个“层-归一化”步骤。
正确答案:ABCD
8、华为AI全栈全场景解决方案中,以下关于ATC转换中AIPP的使能流程的描述,不正确的是哪一项?(单选题)
A.使能AIPP功能后,若实际提供给模型推理的测试图片不满足要求(包括图片格式,图片尺寸等),经过模型转换后,会输出满足模型要求的图片,并将该信息固化到转换后的离线模型中(模型转换后AIPP功能会以aipp算子形式插入离线模型中)。
B.实现AIPP的流程为获取网络模型->构造AIPP配置文件->ATC命令中加入参数->成功执行ATC命令。
C.静态AIPP配置模板主要由如下几部分组成:AIPP配置模式(静态AIPP或者动态AIPP),原始图片信息(包括图片格式,以及图片尺寸),改变图片尺寸(抠图,补边)、色域转换功能等。
D.ATC命令中加入conf参数,用于插入预处理算子。
atc --model=$HOME/module/resnet50_tensorflow*.pb --framework=3 --conf=$HOME/module/insert_op.txt --output=$HOME/module/out/tf_resnet50 --soc_version=<soc_version>。
正确答案:D