【生成对抗网络GAN】最全的关于生成对抗网络Generative Adversarial Networks,GAN的介绍!!
【生成对抗网络GAN】最全的关于生成对抗网络Generative Adversarial Networks,GAN的介绍!!
文章目录
前言
生成对抗网络(Generative Adversarial Networks,GAN)自2014年由Ian Goodfellow提出以来,成为图像生成领域的核心技术之一。它通过对抗训练生成器和判别器两个网络,极大提升了生成图像的质量。
1.GAN的基础理论
1.1背景与概念
GAN由生成器(Generator)和判别器(Discriminator)两个对抗网络组成。
- 生成器:尝试生成逼真的假图像,输入通常是一个随机噪声向量。
- 判别器:判别输入图像是真实图像还是生成器生成的假图像。
GAN的目标是通过博弈的方式让生成器生成的图像逐步逼近真实图像,直到判别器无法区分两者为止。这个过程可以用一个零和博弈来表示,生成器试图“欺骗”判别器,而判别器试图准确区分真实图像与生成图像。
1.2训练过程
GAN的训练过程包含两个主要步骤:
- 训练判别器:让判别器尽可能区分真实图像与生成器生成的假图像。
- 训练生成器:通过更新生成器,使其生成的图像逐渐接近真实图像,从而迷惑判别器。
GAN的损失函数是基于博弈论中的最小最大损失函数,具体表达式如下:
其中,
D
(
x
)
D(x)
D(x)是判别器对真实图像的预测,
G
(
z
)
G(z)
G(z)是生成器从噪声
z
z
z生成的图像。
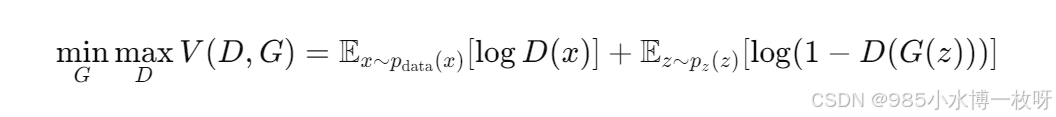
2.GAN的实际用途
GAN在图像生成任务中有着广泛的应用,以下是一些主要应用场景:
- 图像生成:生成高质量的照片、艺术作品等,常用于艺术创作、游戏开发等。
- 图像修复:修复破损或缺失部分的图像。
- 超分辨率重建:将低分辨率图像重建为高分辨率图像。
- 图像到图像翻译:如从素描生成彩色图像,从夏天风景图像生成冬天场景等。
- 视频生成:生成具有逼真运动的连续图像序列。
3.GAN的代码实现:使用GAN生成手写数字
以下是一个使用PyTorch实现简单GAN的代码示例,用于生成手写数字(如MNIST数据集)。
代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 定义生成器
class Generator(nn.Module):
def __init__(self, input_size=100, output_size=784):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_size, 256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.ReLU(True),
nn.Linear(512, 1024),
nn.ReLU(True),
nn.Linear(1024, output_size),
nn.Tanh() # 将输出限制在[-1, 1]之间,适合生成图像数据
)
def forward(self, x):
return self.model(x)
# 定义判别器
class Discriminator(nn.Module):
def __init__(self, input_size=784):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_size, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid() # 输出一个介于0到1之间的概率值
)
def forward(self, x):
return self.model(x)
# 数据准备
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
mnist = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
dataloader = DataLoader(mnist, batch_size=64, shuffle=True)
# 初始化模型
generator = Generator()
discriminator = Discriminator()
# 损失函数和优化器
criterion = nn.BCELoss() # 二分类交叉熵损失
optimizer_g = optim.Adam(generator.parameters(), lr=0.0002)
optimizer_d = optim.Adam(discriminator.parameters(), lr=0.0002)
# 训练过程
for epoch in range(50):
for i, (real_images, _) in enumerate(dataloader):
batch_size = real_images.size(0)
# 训练判别器
real_images = real_images.view(batch_size, -1) # 展平图像
real_labels = torch.ones(batch_size, 1) # 真实标签为1
fake_labels = torch.zeros(batch_size, 1) # 假标签为0
outputs = discriminator(real_images)
d_loss_real = criterion(outputs, real_labels) # 判别器对真实图像的损失
noise = torch.randn(batch_size, 100) # 随机噪声
fake_images = generator(noise) # 生成假图像
outputs = discriminator(fake_images.detach())
d_loss_fake = criterion(outputs, fake_labels) # 判别器对假图像的损失
d_loss = d_loss_real + d_loss_fake # 总损失
optimizer_d.zero_grad()
d_loss.backward() # 反向传播
optimizer_d.step() # 更新判别器
# 训练生成器
noise = torch.randn(batch_size, 100)
fake_images = generator(noise)
outputs = discriminator(fake_images)
g_loss = criterion(outputs, real_labels) # 生成器希望判别器输出1
optimizer_g.zero_grad()
g_loss.backward()
optimizer_g.step()
print(f'Epoch [{epoch+1}/50], d_loss: {d_loss.item():.4f}, g_loss: {g_loss.item():.4f}')
代码解释:
- 1.
class Generator(nn.Module):定义生成器网络,其输入是随机噪声,输出为生成的图像。 - 2.
class Discriminator(nn.Module):定义判别器网络,输入为图像,输出一个概率值,表示图像是真实图像的概率。 - 3.
criterion = nn.BCELoss():使用二分类交叉熵损失函数,适用于二分类问题。 - 4.
optimizer_g = optim.Adam(generator.parameters(), lr=0.0002):使用Adam优化器更新生成器的权重。 - 5.
optimizer_d = optim.Adam(discriminator.parameters(), lr=0.0002):Adam优化器更新判别器的权重。 - 6.
d_loss = d_loss_real + d_loss_fake:判别器的总损失包括真实图像的损失和生成图像的损失。 - 7.
g_loss = criterion(outputs, real_labels):生成器的损失,目标是让判别器认为生成图像为真实图像。 - 8.
noise = torch.randn(batch_size, 100):生成随机噪声作为生成器的输入,用于生成假图像。
4.GAN的相关论文推荐
(1)Generative Adversarial Networks,2014
论文地址:https://arxiv.org/pdf/1406.2661
主要内容:
- “GAN之父” Ian Goodfellow 发表的第一篇提出 GAN 的论文,这应该是任何开始研究学习 GAN 的都该阅读的一篇论文,它提出了 GAN 这个模型框架,讨论了非饱和的损失函数,然后对于最佳判别器(optimal discriminator)给出其导数,然后进行证明;最后是在 Mnist、TFD、CIFAR-10 数据集上进行了实验。
(2)Conditional GANs,2014
论文地址:https://arxiv.org/pdf/1411.1784
主要内容:
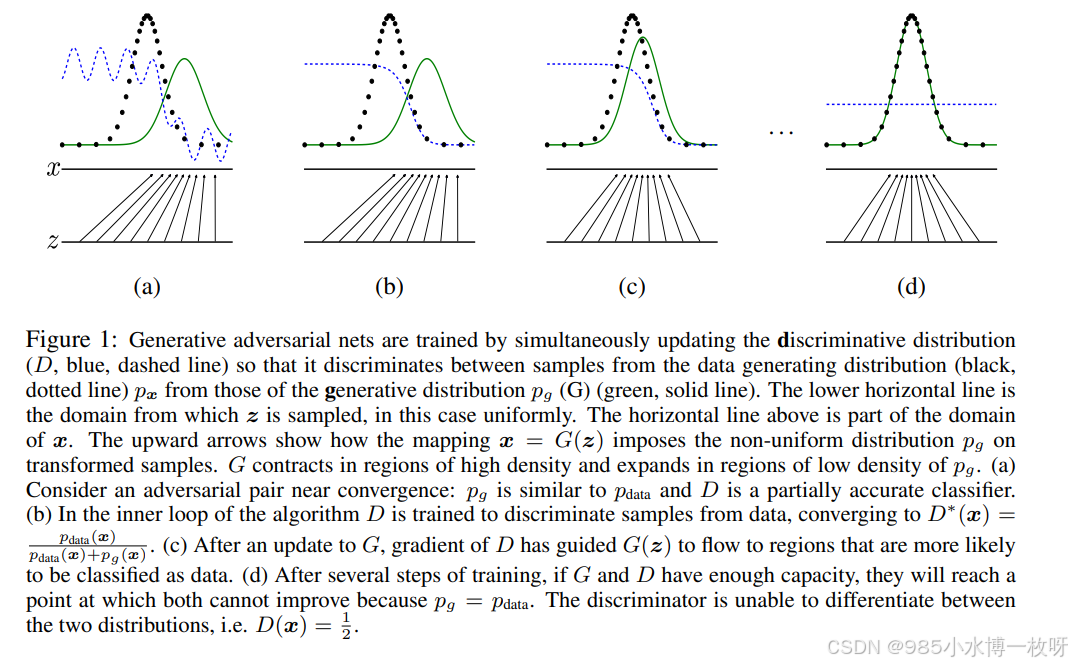
- 如果说上一篇 GAN 论文是开始出现 GAN 这个让人觉得眼前一亮的模型框架,这篇 cGAN 就是当前 GAN 模型技术变得这么热门的重要因素之一,事实上 GAN 开始是一个无监督模型,生成器需要的仅仅是随机噪声,但是效果并没有那么好,在 14 年提出,到 16 年之前,其实这方面的研究并不多,真正开始一大堆相关论文发表出来,第一个因素就是 cGAN,第二个因素是等会介绍的 DCGAN;
- cGAN 其实是将 GAN 又拉回到监督学习领域,如下图所示,它在生成器部分添加了类别标签这个输入,通过这个改进,缓和了 GAN 的一大问题–训练不稳定,而这种思想,引入先验知识的做法,在如今大多数非常有名的 GAN 中都采用这种做法,后面介绍的生成图片的 BigGAN,或者是图片转换的 Pix2Pix,都是这种思想,可以说 cGAN 的提出非常关键。
(3)DCGAN,2015
论文地址:https://arxiv.org/pdf/1511.06434
主要内容:
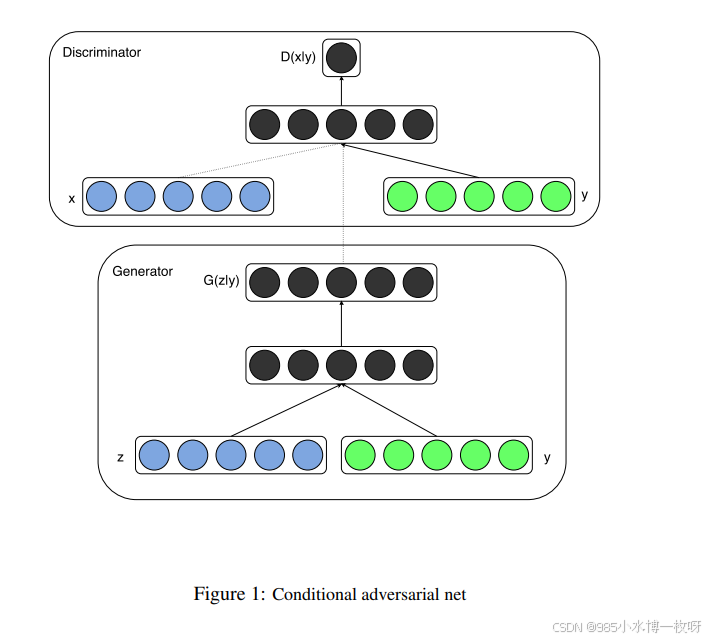
- 其实原作者推荐第一篇论文应该是阅读这篇 DCGAN 论文,2015年发表的。这是第一次采用 CNN 结构实现 GAN 模型,它介绍如何使用卷积层,并给出一些额外的结构上的指导建议来实现。另外,它还讨论如何可视化 GAN 的特征、隐空间的插值、利用判别器特征训练分类器以及评估结果。下图是 DCGAN 的生成器部分结构示意图
(4)Improved Techniques for Training GANs,2016
论文地址:https://arxiv.org/pdf/1606.03498
主要内容:
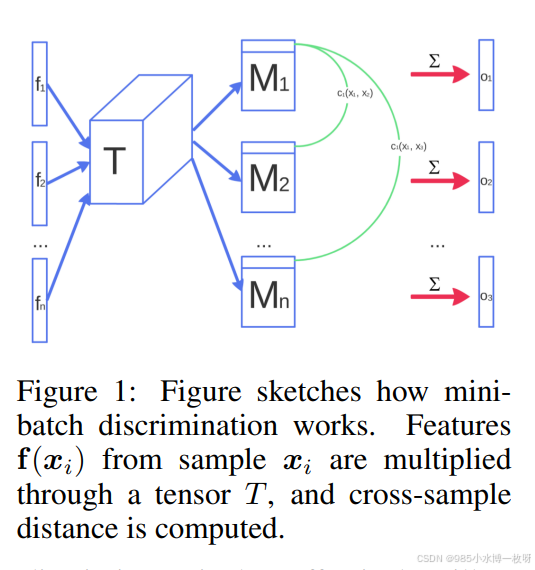
- 这篇论文的作者之一是 Ian Goodfellow,它介绍了很多如何构建一个 GAN 结构的建议,它可以帮助你理解 GAN 不稳定性的原因,给出很多稳定训练 DCGANs 的建议,比如特征匹配(feature matching)、最小批次判别(minibatch discrimination)、单边标签平滑(one-sided label smoothing)、虚拟批归一化(virtual batch normalization)等等,利用这些建议来实现 DCGAN 模型是一个很好学习了解 GANs 的做法。
(5)Pix2Pix,2016
论文地址:https://arxiv.org/pdf/1611.07004
主要内容:
- Pix2Pix 的目标是实现图像转换的应用,如下图所示。这个模型在训练时候需要采用成对的训练数据,并对 GAN 模型采用了不同的配置。其中它应用到了 PatchGAN 这个模型,PatchGAN 对图片的一块 70*70 大小的区域进行观察来判断该图片是真是假,而不需要观察整张图片。
- 此外,生成器部分使用 U-Net 结构,即结合了 ResNet 网络中的 skip connections 技术,编码器和解码器对应层之间有相互连接,它可以实现如下图所示的转换操作,比如语义图转街景,黑白图片上色,素描图变真实照片等。

(6)CycleGAN,2017
论文地址:https://arxiv.org/pdf/1703.10593
主要内容:
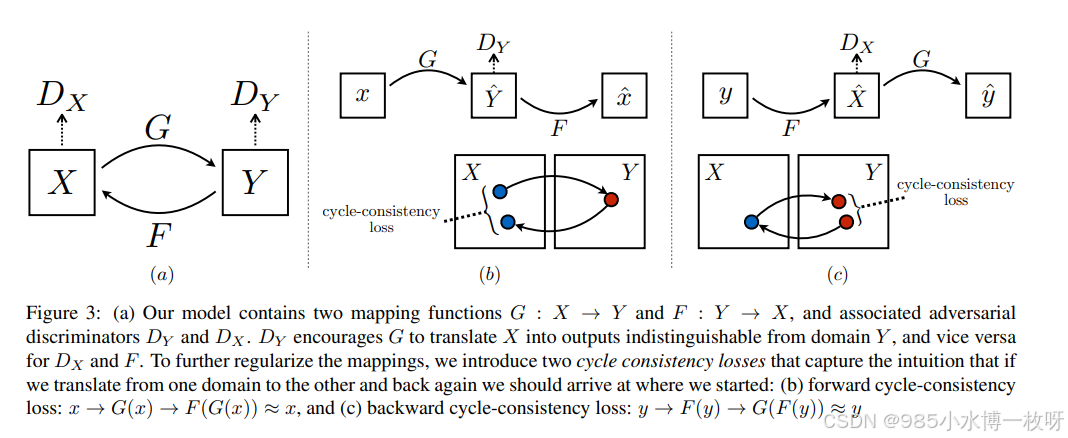
- 上一篇论文 Pix2Pix 的问题就是训练数据必须成对,即需要原图片和对应转换后的图片,而现实就是这种数据非常难寻找,甚至有的不存在这样一对一的转换数据,因此有了 CycleGAN,仅仅需要准备两个领域的数据集即可,比如说普通马的图片和斑马的图片,但不需要一一对应。这篇论文提出了一个非常好的方法–循环一致性(Cycle-Consistency)损失函数,如下图所示的结构:
- 这种结构在接下来图片转换应用的许多 GAN 论文中都有利用到,cycleGAN 可以实现如下图所示的一些应用,普通马和斑马的转换、风格迁移(照片变油画)、冬夏季节变换等等。

(7)Progressively Growing of GANs,2017
论文地址:https://arxiv.org/pdf/1710.10196
主要内容:
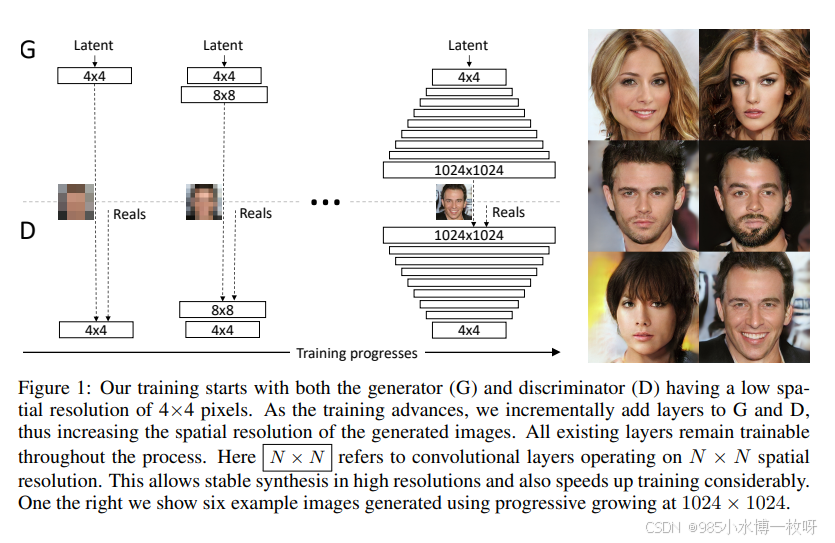
- 这篇论文必读的原因是因为它取得非常好的结果以及对于 GAN 问题的创造性方法。它利用一个多尺度结构,从 44 到 88 一直提升到 1024*1024 的分辨率,如下图所示的结构,这篇论文提出了一些如何解决由于目标图片尺寸导致的不稳定问题。
(8)StackGAN,2017
论文地址:https://arxiv.org/pdf/1612.03242
主要内容:
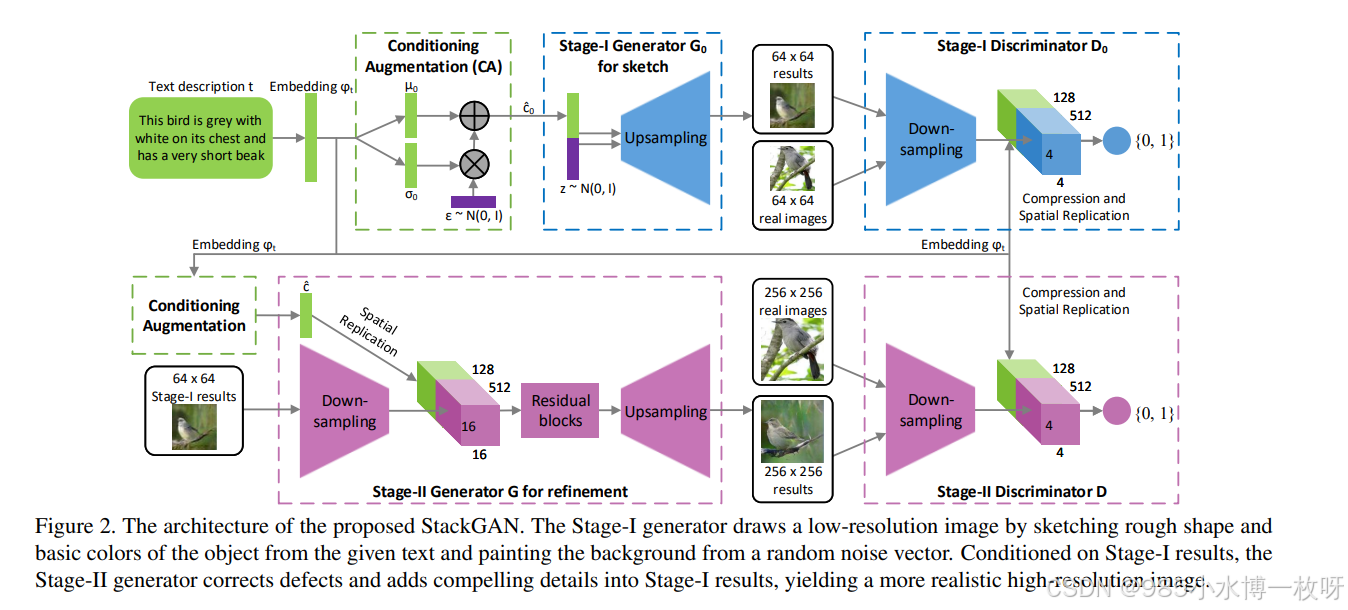
- StackGAN 和 cGAN 、 Progressively GANs 两篇论文比较相似,它同样采用了先验知识,以及多尺度方法。整个网络结构如下图所示,第一阶段根据给定文本描述和随机噪声,然后输出 6464 的图片,接着将其作为先验知识,再次生成 256256 大小的图片。相比前面 推荐的 7 篇论文,StackGAN 通过一个文本向量来引入文本信息,并提取一些视觉特征
(9)BigGAN,2018
论文地址:https://arxiv.org/pdf/1809.11096
主要内容:
- BigGAN 应该是当前 ImageNet 上图片生成最好的模型了,它的生成结果如下图所示,非常的逼真,但这篇论文比较难在本地电脑上进行复现,它同时结合了很多结构和技术,包括自注意机制(Self-Attention)、谱归一化(Spectral Normalization)等,这些在论文都有很好的介绍和说明。

(10)StyleGAN,2018
论文地址:https://arxiv.org/pdf/1812.04948
主要内容:
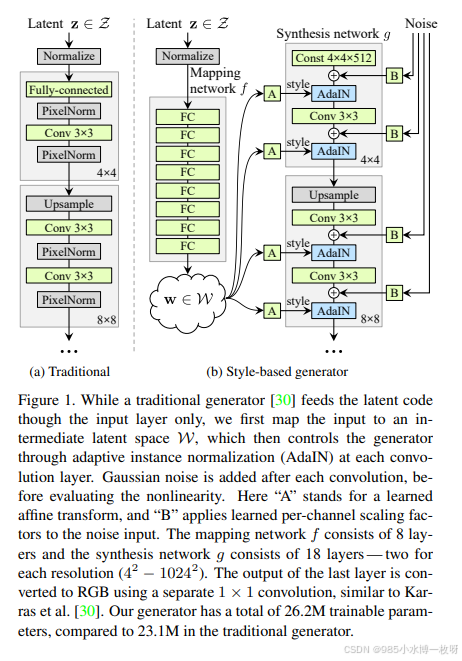
- StyleGAN 借鉴了如 Adaptive Instance Normalization (AdaIN)的自然风格转换技术,来控制隐空间变量 z 。其网络结构如下图所示,它在生产模型中结合了一个映射网络以及 AdaIN 条件分布的做法,并不容易复现,但这篇论文依然值得一读,包含了很多有趣的想法。
另外,再推荐一个收集了大量 GAN 论文的 Github 项目,并且根据应用方向划分论文:
https://github.com/zhangqianhui/AdversarialNetsPapers
以及 3 个复现多种 GANs 模型的 github 项目,分别是目前主流的三个框架,TensorFlow、PyTorch 和 Keras:
- TensorFlow 版本:https://github.com/TwistedW/tensorflow-GANs
- PyTorch 版本:https://github.com/eriklindernoren/PyTorch-GAN
- Keras 版本:https://github.com/eriklindernoren/Keras-GAN
论文推荐部分转自:https://zhuanlan.zhihu.com/p/72745900
总结
GAN通过生成器和判别器的对抗训练,极大地提升了生成图像的质量,并且通过诸如DCGAN、CycleGAN和StyleGAN等扩展变体不断优化生成效果。其广泛应用于图像生成、图像翻译、超分辨率重建等任务,推动了计算机视觉领域的快速发展。