1. 引言 (Introduction)
欢迎来到本篇技术博客! 在本文中, 我将引导你一步一步地在阿里云服务器上部署 Qwen 大模型,并将其集成到 Cline 插件中。
我们将从零开始,详细介绍每个步骤,确保即使是初学者也能轻松上手。

近年来,大型语言模型(LLMs)展现出了强大的自然语言处理能力,吸引了越来越多的关注。 Qwen 系列模型是阿里巴巴开源的一系列强大的大语言模型, 具有优秀的性能和广泛的应用场景。
Ollama 是一个易于使用的工具, 可以让你在本地轻松部署和运行大模型, 并提供 API 接口供外部调用。 而 Cline 插件则提供了一个便捷的 UI 界面, 可以连接到各种大模型,并进行交互式对话。
本篇博客的目标是:
- 在阿里云服务器上,部署一个强大的 Qwen 大模型。
- 使用 Ollama 提供 API 接口,方便本地和远程调用。
- 使用 Cline 插件连接到 Ollama API, 并进行测试。
我们将使用以下配置:
- 阿里云服务器 (CPU 机器)。
- Ollama (最新版本)。
- Qwen2.5:1.5b 模型 (当然你可以选择更大的模型)。
- Cline 插件 (一个客户端, 用于连接到 Ollama API)。
2. 准备工作 (Prerequisites)
在开始之前, 你需要确保你的环境满足以下条件:
- 阿里云服务器:
你需要一个运行 Linux (例如 Ubuntu, CentOS) 的阿里云服务器。
服务器需要有公网 IP 地址。
服务器需要有足够的 CPU 核心数、 内存 (至少 4GB 以上) 以及 磁盘空间 (至少 20 GB 以上)。
- Xshell 连接工具 (或其他 SSH 工具):
你需要使用 SSH 客户端连接工具, 例如 Xshell 或者其他类似的工具,连接到你的阿里云服务器。
你需要知道服务器的 IP 地址, 用户名和密码。
- 网络:
你需要确保你的阿里云服务器可以连接互联网, 以便下载 Ollama 和模型。
3. Ollama 安装 (Ollama Installation)
- 下载 Ollama:
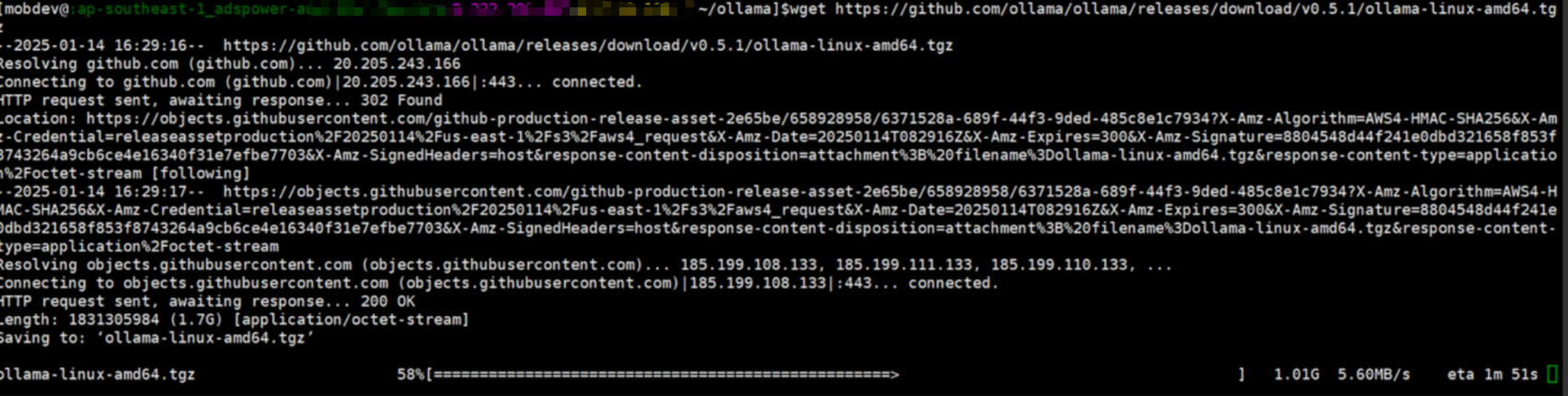
访问 Ollama 的官方 GitHub Release 页面 (https://github.com/ollama/ollama/releases), 找到最新版本的 Linux 安装包下载链接。 你应该看到类似 ollama-linux-amd64.tgz 的文件。
使用 wget 下载安装包, 并将 v0.x.x 替换为你实际的版本号:
wget https://github.com/ollama/ollama/releases/download/v0.x.x/ollama-linux-amd64.tgz
- 解压安装包:
使用 tar 命令解压安装包:
tar -zxvf ollama-linux-amd64.tgz

- 移动 Ollama 可执行文件到
**/usr/local/bin**:
sudo cp bin/ollama /usr/local/bin
sudo chmod +x /usr/local/bin/ollama
-
验证 Ollama 安装:
使用以下命令验证 Ollama 是否安装成功:
ollama --version
你将看到类似以下输出:
ollama version is 0.5.x
- 设置
OLLAMA_HOST环境变量:
为了让 Ollama API 监听所有网络接口, 你需要设置 OLLAMA\_HOST 环境变量。
- 在 __运行 __
\*\*ollama serve\*\*__ 的终端窗口中__ 设置, 你可以使用以下命令:
export OLLAMA_HOST="0.0.0.0:11434"
或者使用默认端口:
export OLLAMA_HOST="0.0.0.0"
你可以在该终端窗口中使用以下命令验证环境变量:
echo $OLLAMA_HOST
- 启动 Ollama 服务
使用 nohup ollama serve & 命令在后台启动 Ollama 服务。
使用 tail -f nohup.out 查看日志,确认服务在监听 0.0.0.0:11434 。
nohup ollama serve &
tail -f nohup.out
你将看到类似以下输出:
Listening on [::]:11434 (version 0.5.x)
4. 模型下载和运行 (Model Download and Run)
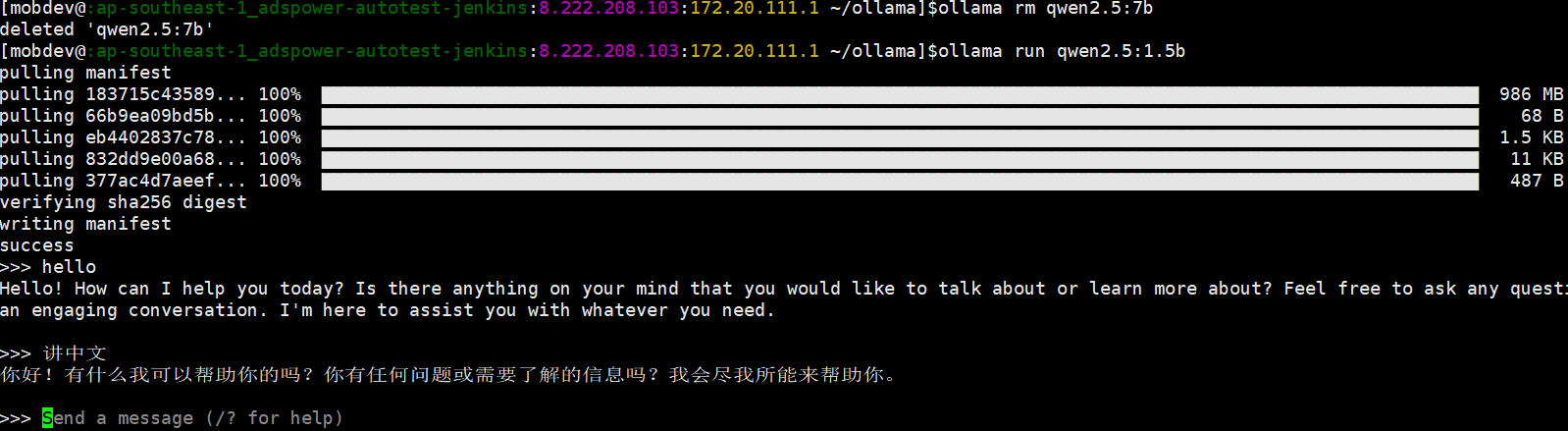
下载 qwen2.5:1.5b 模型:
使用以下命令下载并运行 qwen2.5:1.5b 模型:
ollama run qwen2.5:1.5bOllama 会自动下载模型文件, 你需要等待一段时间。
我们使用 qwen2.5:1.5b 模型是因为它适合我们当前的 CPU 服务器配置,
当然你可以选择更大的模型。
解释 Ollama 的模型加载:
ollama serve 命令仅启动 Ollama API 服务。
ollama run <model_name> 命令下载并运行指定模型。
我们使用 API 调用模型,因此不需要使用
ollama run <model_name> 命令来启动模型。
5. Cline 插件配置 (Cline Plugin Configuration)
- 安装 Cline 插件:
- 如果你没有安装 Cline 插件, 请参考 Cline 官方文档进行安装。
- 配置 Cline 的 API Provider:
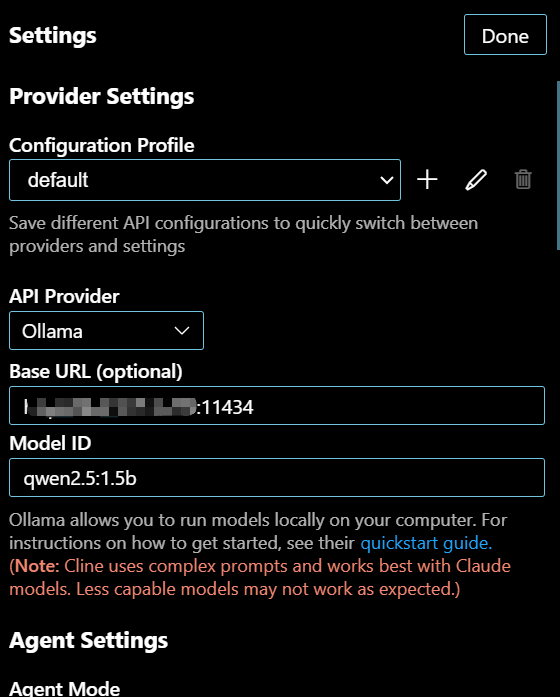
- 在 Cline 插件的设置中, 将 “API Provider” 设置为 “Ollama”:
- 设置 Base URL:
“Base URL” 设置为 http://<你的服务器公网IP>:11434, 将 <你的服务器公网IP> 替换为你的阿里云服务器的公网 IP 地址:
- 设置 Model ID:
将 “Model ID” 设置为你使用的 Ollama 模型 ID: qwen2.5:1.5b
- 设置 Custom Instructions (可选):
你可以设置自定义的指令, 这些指令会添加到发送给模型的系统提示中:
- 配置阿里云服务器防火墙
你需要在阿里云控制台中配置你的防火墙, 允许外部访问 11434 端口。
6. Cline 测试 (Cline Testing)
- 输入 Prompt 测试:
- 在 Cline 插件中输入 prompt,测试是否可以正常连接到 Ollama API, 并获取模型响应。
7. 总结 (Conclusion)
恭喜你, 你已经成功地在阿里云服务器上部署了 Qwen 大模型,并将其集成到 Cline 插件中!
通过本篇博客, 我们学习了:
- 如何下载、安装和配置 Ollama。
- 如何下载和运行 Qwen 模型。
- 如何配置 Cline 插件,连接到 Ollama API 。
通过 Ollama 和 Cline, 你可以方便地在本地运行大模型,并且可以通过 Cline 插件进行对话。
未来展望:
- 你可以尝试使用更大规模的模型,例如
qwen2.5:7b,qwen2.5:32b等, 但需要你的服务器内存足够。 - 你可以考虑使用 GPU 服务器加速推理过程。
- 你可以考虑使用 Docker 来管理和部署你的环境。
- 你可以使用 API 网关实现 API Key 验证和其他安全措施。
8. 附录 (Appendix) (可选)
- 常用命令:
下载 Ollama 安装包:
wget https://github.com/ollama/ollama/releases/download/v0.x.x/ollama-linux-amd64.tgz`
解压安装包:
tar -zxvf ollama-linux-amd64.tgz`
移动 Ollama 可执行文件:
sudo cp bin/ollama /usr/local/bin sudo chmod +x /usr/local/bin/ollama`
验证 Ollama 安装:
ollama --version`
设置 OLLAMA_HOST 环境变量:
export OLLAMA_HOST="0.0.0.0:11434"`
后台运行 Ollama 服务:
nohup ollama serve &`
查看 Ollama 日志:
tail -f nohup.out`
下载并运行模型
ollama run qwen2.5:1.5b`
- Ollama 官方网站: https://ollama.com/
- Ollama 官方文档: https://ollama.com/docs
- Cline 插件官方 GitHub: https://github.com/cline-py/cline
如果遇到任何问题,欢迎私信作者,一起交流学习
