图像数据预处理
1. 图片格式
常见的图片格式有bmp、jpg(jpeg)、png、gif等。
1.1 图像基本数据结构
在计算机中,图像是由一个个像素点构成,像素点就是颜色点。而颜色最简单的方式就是用RGB或RGBA表示,即:
RGBA中A通道表示这个图像可以有透明效果。
R,G,B每个分量一般由一个字节(8位)来表示,因此RGB表示的图像中每个像素大小是38=24位图;而RGBA表示的图像中每个像素大小是48=32位图。


1.1.1 图像y方向正立或倒立
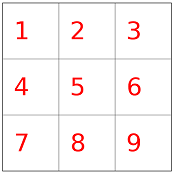
图像是二维数据,但数据在内存中只能一维存储,因此需要将图像转变为一维数据便于在内存中存储。二维转一维有不同的对应方式。比较常见的有两种方式:按像素行排列,从上往下或者从下往上。
如上图,图像有9个像素点,当按照从上往下排列成一维数据是:123456789;按照从下往上排列则是789456123.
只所以会有这种区别是因为,前一种是以计算机图形学的屏幕坐标系为参考(右上为原点,y轴向下 ),而另后一种是以标准的数学坐标系为参考(右下为原点,y轴向上)。这两个坐标系只是y值不一样,互相转换的公式为:
y
2
=
h
e
i
g
h
t
−
1
−
y
1
y_2 = height -1 - y_1
y2=height−1−y1
其中:
y
1
y_1
y1表示计算机图形学的屏幕坐标系的
y
y
y坐标;
y
2
y_2
y2表示标准的数学坐标系的
y
y
y坐标。
1.1.2 RGB排列顺序
不同图形库中每个像素点中RGBA的排序顺序可能不一样。上面说过像素一般会有RGB,或RGBA四个分量,那么在内存中RGB的排列就有6种情况,如下:
- RGB
- RBG
- GRB
- GBR
- BGR
- BRG
RGBA的排列有24种情况。一般情况下,只会有RGB,BGR, RGBA, RGBA, BGRA这几种排列据。绝大多数图形库或环境是BGR/BGRA排列,cocoa中的NSImage或UIImage是RGBA排列。
1.1.3 像素32位对齐
如果是RGB24位图,会存在一个32位对齐的问题。
在x86体系下,cpu一次处理32整数倍的数据会更快,图像处理中经常会按行为单位来处理像素。24位图,宽度不是4的倍数时,其行字节数将不是32整数倍。这时可以采取在行尾添加冗余数据的方式,使其行字节数为32的倍数。
比如,如果图像宽为5像素,不做32位对齐的话,其行位数为24*5=120,120不是32的倍数。是32整数倍并且刚好比120大的数是128,也就只需要在其行尾添加1字节(8位)的冗余数据即可。(一个以空间换时间的例子)
有个公式可以轻松计算出32位对齐后每行应该占的字节数:
b
y
t
e
N
u
m
=
(
(
w
i
d
t
h
∗
24
+
31
)
&
∼
31
)
>
>
3
byteNum = ((width * 24 + 31) \& \sim31)>>3
byteNum=((width∗24+31)&∼31)>>3
该结果是字节数,对于位数来说,还需要×8.
1.1.4 图片格式的必要性
将图像原始格式直接存储到文件中将会非常大,比如一个50005000 24位图,所占文件大小为50005000*3字节=71.5MB, 其大小非常可观。
如果用zip或rar之类的通用算法来压缩像素数据,得到的压缩比例通常不会太高,因为这些压缩算法没有针对图像数据结构进行特殊处理。
于是就有了jpeg,png等格式,同样是图像压缩算法jpeg和png也有不同的适用场景。
所以可以总结如下: jpeg,png文件之于图像,就相当于zip,rar格式之于普通文件(用zip,rar格式对普通文件进行压缩)。
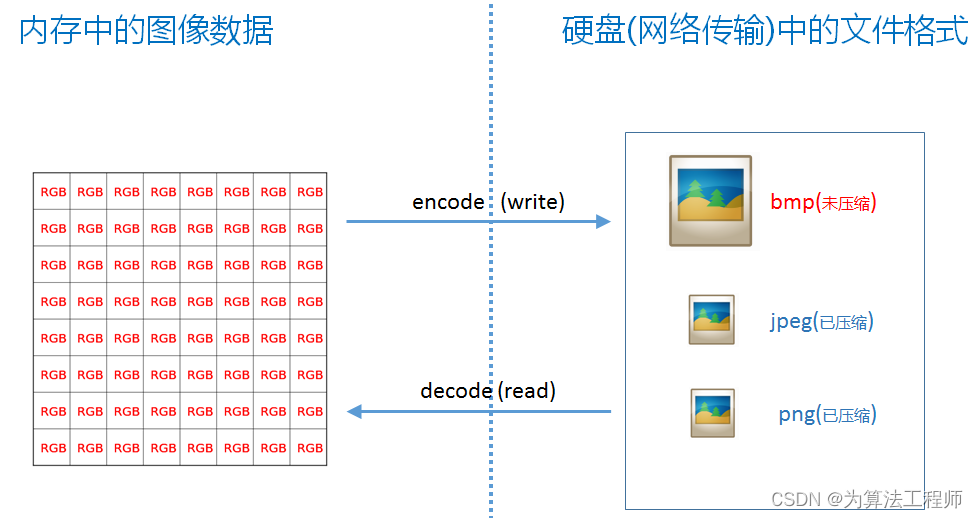
1.2 BMP格式
BMP是英文Bitmap(位图)的简写,由4个部分组成:文件头信息块、图像描述信息块、调色板和图像数据块。BMP图像文件也称位图文件。以24位图的bmp格式为例:
-
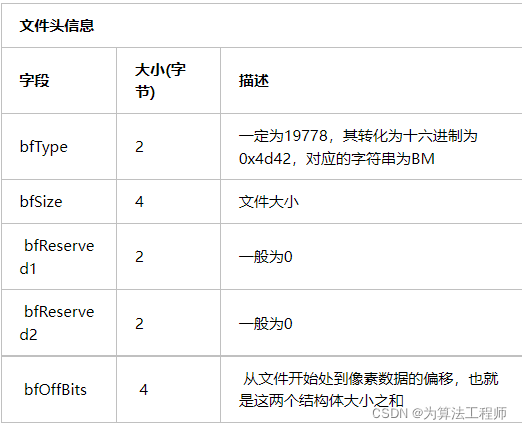
文件头信息块:图像是一个文件,文件头的功能就是对这个图像文件的描述,包括:图像类型,图像文件的大小,图像数据的存放地址,以及2个不常使用的字段。
-
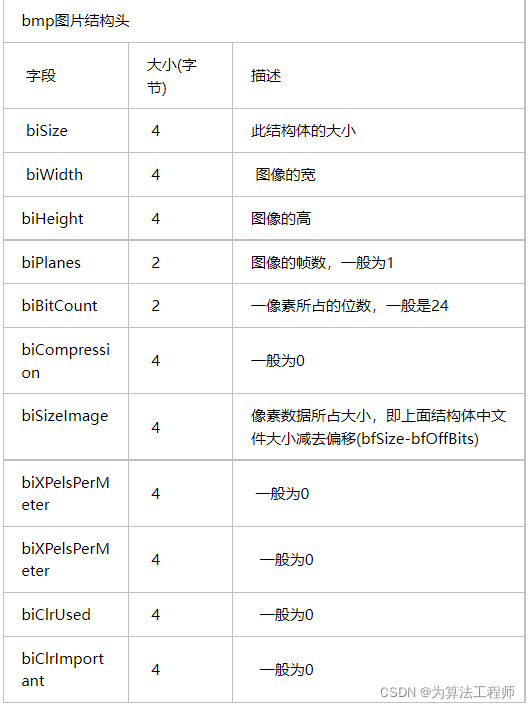
图像描述信息块:这个部分的结构体主要是来第一图像相关的信息的,包括这个信息头的大小,图像的深度,压缩与否,颜色板,表示图像数据有几层,还有图像的大小信息,图像每行,每列的像素个数,最后是颜色使用度和重要颜色度。
-
调色板(又称彩色表):图像数据块都是从这表里索引来的,其实就像一个颜料板一样。彩色表/调色板(color table)是单色、16色和256色图像文件所特有的,相对应的调色板大小是2、16和256,调色板以4字节为单位,每4个字节存放一个颜色值,图像 的数据是指向调色板的索引。可以将调色板想象成一个数组,每个数组元素的大小为4字节,假设有一256色的BMP图像的调色板数据为:
调 色 板 [ 0 ] = 黑 、 调 色 板 [ 1 ] = 白 、 调 色 板 [ 2 ] = 红 、 调 色 板 [ 3 ] = 蓝 … 调 色 板 [ 255 ] = 黄 调色板[0]=黑、调色板[1]=白、调色板[2]=红、调色板[3]=蓝…调色板[255]=黄 调色板[0]=黑、调色板[1]=白、调色板[2]=红、调色板[3]=蓝…调色板[255]=黄
图像数据块01 00 02 FF表示调用调色板[1]、调色板[0]、调色板[2]和调色板[255]中的数据来显示图像颜色。 -
图像数据块(位图数据):如果图像是单色、16色和256色,则紧跟着调色板的是位图数据,位图数据是指向调色板的索引序号。
如果位图是16位、24位和32位色,则图像文件中不保留调色板,即不存在调色板,图像的颜色直接在位图数据中给出。
6位图像使用2字节保存颜色值,常见有两种格式:5位红5位绿5位蓝和5位红6位绿5位蓝,即555格式和565格式。555格式只使用了15 位,最后一位保留,设为0。
24位图像使用3字节保存颜色值,每一个字节代表一种颜色,按红、绿、蓝排列。
32位图像使用4字节保存颜色值,每一个字节代表一种颜色,除了原来的红、绿、蓝,还有Alpha通道,即透明色。
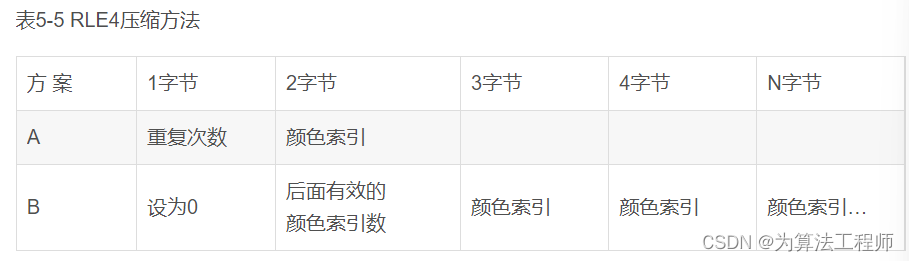
如果图像带有调色板,则位图数据可以根据需要选择压缩与不压缩,如果选择压缩,则根据BMP图像是16色或256色,采用RLE4或RLE8压缩算 法压缩。
RLE4是压缩16色图像数据的,RLE4采用表5-5所示方式压缩数据。
1.3 jpg(jpeg)格式
jpg全名是JPEG。JPEG 是与平台无关的格式,支持最高级别的压缩(这种压缩是有损耗的), 将像素信息用JPEG保存成文件再读取出来,其中某些像素值会有少许变化。在保存时有个质量参数可在[0,100]之间选择,参数越大图片就越保真,但图片的体积也就越大。一般情况下选择70或80就足够了。JPEG没有透明信息。jpeg比较适合用来存储相机拍出来的照片,这类图像用JPEG压缩后的体积比较小。其使用的具体算法核心是离散余弦变换、Huffman编码、算术编码等技术。
jpeg格式支持不完全读取整张图片,即可以选择读取原图、1/2、1/4、1/8大小的图片
1.4 png格式
png是一种无损压缩格式, 压缩大概是用行程编码算法。png可以有透明效果。png比较适合适量图,几何图。
-
头文件:对于一个PNG文件来说,其文件头总是由位固定的字节来描述的:
其中第一个字节0x89超出了ASCII字符的范围,这是为了避免某些软件将PNG文件当做文本文件来处理。文件中剩余的部分由3个以上的PNG的数据块(Chunk)按照特定的顺序组成,因此,一个标准的PNG文件结构应该如下:
-
数据块:PNG定义了两种类型的数据块,一种是称为关键数据块(critical chunk),这是标准的数据块,另一种叫做辅助数据块(ancillary chunks),这是可选的数据块。
关键数据块定义了4个标准数据块,每个PNG文件都必须包含它们,PNG读写软件也都必须要支持这些数据块。虽然PNG文件规范没有要求PNG编译码器对可选数据块进行编码和译码,但规范提倡支持可选数据块。
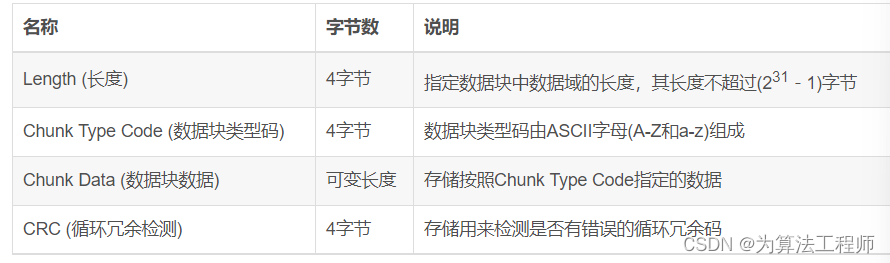
PNG文件中,每个数据块由4个部分组成,如下:


1.5 gif格式
gif可以保存多帧图像,即:
GIF文件中的图像数据均为压缩过的。GIF文件结构较复杂,一般包括7个数据单元:文件头、通用调色板、图像数据区,以及4个补充区。其中,表头和图像数据区是不可缺少的单元。
一个 GIF 文件中可以存放多幅图像(这个特点对实现网页上的动画非常有利),所以文件头中包含适用于所有图像的全局数据和仅属于其后那幅图像的局部数据。当文件中只有一幅图像时,全局数据和局部数据一致。存放多幅图像时,每幅图像集中成一个图像数据块,每块的第一个字节是标识符,指示数据块的类型(可以是图像块、扩展块或文件结束符)。
2. 数据集格式介绍
2.1 VOC数据集
VOC数据集是一种目标检测数据,VOC 2007 和 2012 数据集总共分 4 个大类,vehicle、household、animal、person,总共 20 个小类(加背景 21 类),预测的时候是只输出下图中黑色粗体的类别
目前目标检测常用的是 VOC2007 和 VOC2012 数据集,因为二者是互斥的,论文中的常用组合有以下几种:

- 07+12: 使用 VOC2007 和 VOC2012 的 train+val(16551) 上训练,然后使用 VOC2007 的 test(4952) 测试
- 07++12: 使用 VOC2007 的 train+val+test(9963) 和 VOC2012的 train+val(11540) 训练,然后使用 VOC2012 的 test 测试,这种方法需提交到 PASCAL VOC Evaluation Server 上评估结果,因为 VOC2012 test 没有公布
- 07+12+COCO: 先在 MS COCO 的 trainval 上 预训练,再使用 VOC2007 和 VOC2012 的 train+val 微调训练,然后使用 VOC2007 的 test 测试
- 07++12+COCO: 先在 MS COCO 的 trainval 上预训练,再使用 VOC2007 的 train+val+test 和 VOC2012 的 train+val微调训练,然后使用 VOC2012 的 test 测试 ,这种方法需提交到 PASCAL VOC Evaluation Server 上评估结果,因为VOC2012 test 没有公布
VOC2007 和 VOC2012 目标检测任务中的训练、验证和测试数据统计:

2.2 VOC数据集格式
VOC数据集中的每一个图像都对应着一个同名的xml文件,xml文件中标记物体框的坐标和类别等信息。
xml文件中包含以下字段:
- filename,表示图像名称。
<filename>road650.png</filename>
- size,表示图像尺寸。包括:图像宽度、图像高度、图像深度
<size>
<width>300</width>
<height>400</height>
<depth>3</depth>
</size>
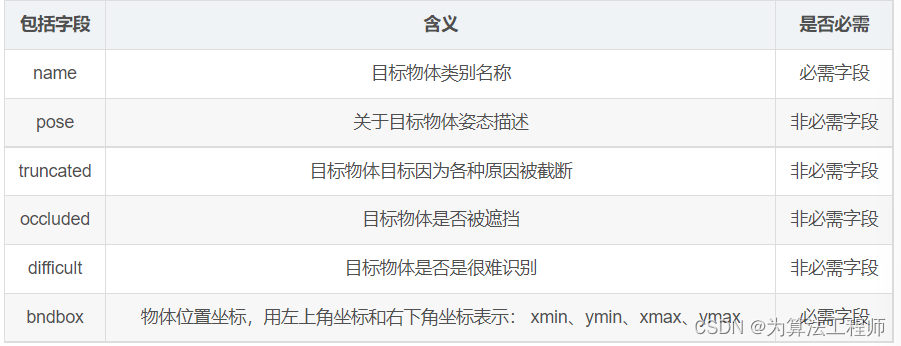
- object字段,表示每个物体。包括:
name: 目标物体类别名称;
pose: 关于目标物体姿态描述(非必须字段);
truncated: 目标物体目标因为各种原因被截断(非必须字段);
occluded: 目标物体是否被遮挡(非必须字段);
difficult: 目标物体是否是很难识别(非必须字段);
bndbox: 物体位置坐标,用左上角坐标和右下角坐标表示: xmin、ymin、xmax、ymax
如下所示:
<annotation>
<folder>VOC2007</folder>
<filename>000001.jpg</filename> # 文件名
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>341012865</flickrid>
</source>
<owner>
<flickrid>Fried Camels</flickrid>
<name>Jinky the Fruit Bat</name>
</owner>
<size> # 图像尺寸, 用于对 bbox 左上和右下坐标点做归一化操作
<width>353</width>
<height>500</height>
<depth>3</depth>
</size>
<segmented>0</segmented> # 是否用于分割
<object>
<name>dog</name> # 物体类别
<pose>Left</pose> # 拍摄角度:front, rear, left, right, unspecified
<truncated>1</truncated> # 目标是否被截断(比如在图片之外),或者被遮挡(超过15%)
<difficult>0</difficult> # 检测难易程度,这个主要是根据目标的大小,光照变化,图片质量来判断
<bndbox> # 检测框坐标
<xmin>48</xmin>
<ymin>240</ymin>
<xmax>195</xmax>
<ymax>371</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Left</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>8</xmin>
<ymin>12</ymin>
<xmax>352</xmax>
<ymax>498</ymax>
</bndbox>
</object>
</annotation>
2.3 提交格式
2.3.1 Classification Task(分类任务)
每一类都有一个 txt 文件,里面每一行都是测试集中的一张图片,前面一列是图片名称,后面一列是预测的分数。
# comp1_cls_test_car.txt, 内容如下
000004 0.702732
000006 0.870849
000008 0.532489
000018 0.477167
000019 0.112426
2.3.2 Detection Task(检测任务)
每一类都有一个 txt 文件,里面每一行都是测试集中的一张图片,每行的格式为:<image identifier> <confidence> <left> <top> <right> <bottom>,confidence 用来计算 mAP:
# comp3_det_test_car.txt,内容如下
# comp3:只允许用所给训练数据,comp4:允许使用外部数据
000004 0.702732 89 112 516 466
000006 0.870849 373 168 488 229
000006 0.852346 407 157 500 213
000006 0.914587 2 161 55 221
000008 0.532489 175 184 232 201
3 COCO数据集
MS COCO的全称是Microsoft Common Objects in Context。COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。
COCO中的图片包含了自然图片以及生活中常见的目标图片,背景比较复杂,目标数量比较多,目标尺寸更小,因此COCO数据集上的任务更难,对于检测任务来说,现在衡量一个模型好坏的标准更加倾向于使用COCO数据集上的检测结果。
3.1 COCO数据集分类
Image Classification:分类需要二进制的标签来确定目标是否在图像中。早期数据集主要是位于空白背景下的单一目标,如MNIST手写数据库,COIL household objects。在机器学习领域的著名数据集有CIFAR-10 and CIFAR-100,在32*32影像上分别提供10和100类。最近最著名的分类数据集即ImageNet,22,000类,每类500-1000影像。
Object Detection:经典的情况下通过bounding box确定目标位置,期初主要用于人脸检测与行人检测,数据集如Caltech Pedestrian Dataset包含350,000个bounding box标签。PASCAL VOC数据包括20个目标超过11,000图像,超过27,000目标bounding box。最近还有ImageNet数据下获取的detection数据集,200类,400,000张图像,350,000个bounding box。由于一些目标之间有着强烈的关系而非独立存在,在特定场景下检测某种目标是是否有意义的,因此精确的位置信息比bounding box更加重要。
Semantic scene labeling:这类问题需要pixel级别的标签,其中个别目标很难定义,如街道和草地。数据集主要包括室内场景和室外场景的,一些数据集包括深度信息。其中,SUN dataset包括908个场景类,3,819个常规目标类(person, chair, car)和语义场景类(wall, sky, floor),每类的数目具有较大的差别(这点COCO数据进行改进,保证每一类数据足够)。
COCO数据集格式
COCO有5种类型的标注,分别是:物体检测、关键点检测、实例分割、全景分割、图片标注,都是对应一个json文件。json是一个大字典,都包含如下的关键字:
{
"info" : info,
"images" : [image],
"annotations" : [annotation],
"licenses" : [license],
}
- info:
info{
"year" : int,
"version" : str,
"description" : str,
"contributor" : str,
"url" : str,
"date_created" : datetime,
}
- images对应的是一个list,对应了多张图片。list的每一个元素是一个字典,对应一张图片。格式如下:
images{
"id" : int,
"width" : int,
"height" : int,
"file_name" : str,
"license" : int,
"flickr_url" : str,
"coco_url" : str,
"date_captured" : datetime,
}
- license的内容如下:
license{
"id" : int,
"name" : str,
"url" : str,
}
虽然每个json文件都有"info", “images” , “annotations”, "licenses"关键字,但不同的任务对应的json文件中annotation的形式不同,分别如下:
目标检测任务:
每个对象实例注释都包含一系列字段,包括对象的类别id和分段掩码。分割格式取决于实例是表示单个对象(使用多边形的情况下iscrowd=0)还是表示对象的集合(使用RLE的情况下iscrowd=1)。注意,单个对象(iscrowd=0)可能需要多个多边形,例如遮挡时。Crowd注释(iscrowd=1)用于标记大量对象(例如一群人)。此外,还为每个对象提供了一个包围框(框坐标从图像左上角开始测量,并以0为索引)。最后,注释结构的categories字段存储类别id到类别和超类别名称的映射。请参见检测任务。
annotation{
"id" : int,
"image_id" : int,
"category_id" : int,
"segmentation" : RLE or [polygon],
"area" : float,
"bbox" : [x,y,width,height],
"iscrowd" : 0 or 1,
}
categories[{
"id" : int,
"name" : str,
"supercategory" : str,
}]
关键点检测任务:
一个关键点注释包含对象注释的所有数据(包括id、bbox等)和两个附加字段。首先,keypoints是一个长度为3k的数组,其中k是为该类别定义的关键点的总数。每个关键点都有一个0索引的位置x,y和一个可见性标志v,定义为v=0:未标记(在这种情况下x=y=0), v=1:标记但不可见,v=2:标记且可见。一个关键点被认为是可见的,如果它落在对象段内。num_keypoints表示一个给定对象(许多对象,例如人群和小对象,将有num_keypoints=0)标记的关键点的数量(v>0)。最后,对于每个类别,categories结构有两个额外的字段:keypoints,这是一个长度为k的关键点名称数组,以及skeleton,它通过一个关键点边缘对列表定义连接性,并用于可视化。目前,关键点仅被标记为person类别(对于大多数中型/大型非人群的person实例)。参见关键任务。
annotation{
"keypoints" : [x1,y1,v1,...],
"num_keypoints" : int,
"[cloned]" : ...,
}
categories[{
"keypoints" : [str],
"skeleton" : [edge],
"[cloned]" : ...,
}]
"[cloned]": denotes fields copied from object detection annotations defined above.
参考资料
常见图片格式详解
BMP的格式说明
PNG文件格式详解
VOC 数据集简介
COCO数据集annotations解析以及可视化
COCO数据集的简介、下载、使用方法之详细攻略
目标检测数据集MSCOCO详解