《自然语言处理-基于预训练模型的方法》笔记
〇.写在前面
本笔记为哈工大“《自然语言处理-基于预训练模型的方法》——车万翔 郭江 崔一鸣 著 2021 年 7 月第一版” 的笔记,记录比较详细。不过,仍然强烈建议诸君购买原书进行学习! 因为本笔记只是笔记,很多地方只是总结性的!
在阅读本笔记前,可能需要您具备一定的深度学习基础和代码能力基础,对于比较欠缺的同学,我给出了一定的学习指示与推荐,包括代码学习的材料以及理论学习的材料。不过无论如何,本笔记都需要一定的神经网络知识基础。详细请看本笔记第四章。
本笔记除了记录了书中知识点之外,还对书中的少量错误进行了修正,同时还进行了少量的扩展。
对于代码学习部分,我给出了代码的链接,都在本人的代码笔记本当中,但是,在查找代码之前,请先查看代码笔记本项目的 README/Checklist,确保相应代码已经被记录。
当然,本人才疏学浅,如有错误在所难免,恳请指正交流,不胜感激,嘤鸣求友!
Github : ZenMoore Zhihu : ZenMoore Twitter : @ZenMoore1
in Markdown Homepage in HTML in PDF, 关于使用哪种格式,请看这里
Email : [email protected], [email protected]
一、绪论
(一) NLP 任务体系
I.任务层级
-
资源建设:语言学知识库 (词典、规则库);语料库。
词典:也称 Thesaurus, 可以提供音韵、句法、语义解释、词汇关系、上下位同反义等
-
基础任务:分词,词性标注,句法分析、句义分析等
-
应用任务:信息抽取、情感分析、问答系统、机器翻译、对话系统等
-
应用系统:教育、医疗、司法、金融、机器人等
II.任务类别
- 回归问题:输出为连续数值
- 分类问题
- 匹配问题:判断关系
- 解析问题:标注、词间关系
- 生成问题
III.研究层次
- 形式:符号
- 语义:符号+实
- 推理:符号+实+知 (常识知识、世界知识、领域知识)
- 语用:符号+实+知+环境
(二) 预训练的时代
预训练+精调范式,预训练说是无监督并不准确,因为下一词预测这一个预训练任务仍然有监督,应该说成是自监督学习。
二、NLP 基础
(一) 文本表示
I.独热向量
- one-hot vector
- 可以引进额外特征表示共同语义 (如 WordNet 同义词等),转为特征工程
II.分布式表示
- 分布式语义假设 : 利用上下文进行语义建模
如使用共现词频(共现矩阵): M = ( C ( w , c ) ) w ∈ V , c ∈ V \pmb{M}=(C(w,c))_{w\in\mathbb{V}, c\in{\mathbb{V}}} MMM=(C(w,c))w∈V,c∈V
C ( w , c ) C(w, c) C(w,c) 表示 词汇 w 与上下文词汇 c 共同出现的频次。
但存在直接使用存在 1.高频词问题 2.高阶关系 3.稀疏性问题
-
点互信息 PMI : P M I = l o g 2 P ( w , c ) P ( w ) P ( c ) PMI=log_2{\frac{P(w, c)}{P(w)P(c)}} PMI=log2P(w)P(c)P(w,c), 解决高频词问题
-
正点互信息 PPMI : P P M I = m a x ( P M I ( w , c ) , 0 ) PPMI=max(PMI(w, c), 0) PPMI=max(PMI(w,c),0), 解决低共现频负 PMI 的不稳定性 (大方差).
-
TF-IDF : 解决高频词问题
-
奇异值分解 SVD : M = U Σ V T ( U T U = V T V = I ) M=U\Sigma V^T (U^TU=V^TV=I) M=UΣVT(UTU=VTV=I), 使用截断奇异值分解近似 M M M (即取 d 个最大的奇异值),矩阵 U U U 的每一行即对应词的 d 维向量表示,该表示一般连续低维稠密。由于正交性,可以认为不同的维度的潜在语义相互独立。因此,这种方法也叫做 潜在语义分析 LSA. 相应地, Σ V T \Sigma V^T ΣVT 的每一列也可以作为上下文的向量表示。解决了高阶关系问题和稀疏性问题。
也可以设计 词汇-文档共现词汇,然后使用 SVD, 相应的技术为 潜在语义索引 LSI.
- 问题:
- 共现矩阵太大了,SVD 好慢
- 短单元问题 (面对段落/句子无能为力, 因为长单元共现的上下文非常少)
- 一旦训练完则固定下来,无法根据任务微调
III.词嵌入表示
- 通过任务预训练出来的词向量, 看成模型参数
- 之后介绍
IV.词袋表示
- BOW : 无顺序, 将文本中全部词的向量表示简单相加 (不论向量表示方法)
- 缺点
- 没有顺序信息
- 无法融入上下文信息
- 即便引入二元词表, 也存在严重的数据稀疏问题
- 解决: 深度学习技术, 之后介绍
(二) NLP 任务
I.语言模型
-
N-gram:N 元语言模型
- 马尔可夫假设 : P ( w t ∣ w 1 w 2 . . . w t − 1 ) = P ( w t ∣ w t − ( n − 1 ) : t − 1 ) P(w_t|w_1w_2...w_{t-1})=P(w_t|w_{t-(n-1):t-1}) P(wt∣w1w2...wt−1)=P(wt∣wt−(n−1):t−1)
- 满足该假设称为:N元语法或文法(gram)模型
- n=1 的 unigram 独立于历史(之前的序列),因此语序无关
- n=2 的 bigram 也被称为一阶马尔可夫链 P ( w 1 w 2 . . . w t ) = ∏ i = 1 l P ( w i ∣ w i − 1 ) P(w_1w_2...w_t)=\prod_{i=1}^lP(w_i|w_{i-1}) P(w1w2...wt)=∏i=1lP(wi∣wi−1)
- w 0 w_0 w0 可以是 <BOS>, w l + 1 w_{l+1} wl+1 <EOS>
-
平滑 : 解决未登录词 (OOV, Out-Of-Vocabulary, <UNK>)的零概率问题
- 折扣法:高频补低频
- 加1平滑:拉普拉斯平滑
对于 unigram: P ( w i ) = C ( w i ) + 1 ∑ w C ( w ) + 1 = C ( w i ) + 1 N + ∣ V ∣ P(w_i)=\frac{C(w_i)+1}{\sum_w{C(w)+1}}=\frac{C(w_i)+1}{N+|\mathbb{V}|} P(wi)=∑wC(w)+1C(wi)+1=N+∣V∣C(wi)+1,
对于 bigram: P ( w i ∣ w i − 1 ) = C ( w i w i − 1 ) + 1 ∑ w ( C ( w i − 1 w ) + 1 ) = C ( w i w i − 1 ) + 1 C ( w i − 1 ) + ∣ V ∣ P(w_i|w_{i-1})=\frac{C(w_iw_{i-1})+1}{\sum_w(C(w_{i-1}w)+1)}=\frac{C(w_iw_{i-1})+1}{C(w_{i-1})+|\mathbb{V}|} P(wi∣wi−1)=∑w(C(wi−1w)+1)C(wiwi−1)+1=C(wi−1)+∣V∣C(wiwi−1)+1
也可以使用 + δ \delta δ 平滑,尤其当训练数据较小时,加一太大了
关于 δ \delta δ 选择,可以使用验证集对不同值的困惑度比较选择最优参数
-
模型评价
- 外部任务评价:不怎么用
- 内部评价方法:基于困惑度 (Perplexity, PPL),越小越好
P ( D t r a i n ) → p a r a m s P(\mathbb{D^{train}})\to params P(Dtrain)→params
P ( D t e s t ) = P ( w 1 w 2 . . . w N ) = ∏ i = 1 N P ( w i ∣ w 1 : i − 1 ) P(\mathbb{D^{test}})=P(w_1w_2...w_N)=\prod_{i=1}^NP(w_i|w_{1:i-1}) P(Dtest)=P(w1w2...wN)=∏i=1NP(wi∣w1:i−1)
P P L = P ( D t e s t ) − 1 / N PPL=P(\mathbb{D^{test}})^{-1/N} PPL=P(Dtest)−1/N : 测试集到每个词的概率的几何平均值的倒数
这里针对一个句子而言:我们的目标是使测试集中的所有句子 PPL 最小。
不是绝对的好,只是正相关的好,关键还是得看具体任务神经网络语言模型之后介绍
II. 基础任务
- 往往不能直接面向用户,而是作为一个环节或者下游任务的额外语言学特征
-
中文分词
-
正向最大匹配算法 (FMM) :倾向于找最长词
相应地,有 逆向最大匹配算法
-
问题:切分歧义问题,未登录词问题
-
其他深度学习方法之后介绍
-
-
子词切分:Lemmatization (词形还原) & Stemming (词干提取)
-
解决数据稀疏问题和大词表问题
-
传统方法需要大量规则,因此:基于统计的无监督方法(使用尽量长且频次高的子词)
-
**字节对编码 (BPE) **生成子词词表,然后使用贪心算法;可以使用缓存算法加快速度
用 <\w> 表示单词的结束
缓存算法:把高频出现的事先保存成文件,每次只解决非高频的那些词
-
WordPiece: ~BPE, 不过 BPE 选频次最高对,WordPiece 选提升语言模型概率最大对
-
Unigram Language Model (ULM) : ~WordPiece, 不同的是,它基于减量法
SentencePiece 开源工具用于子词切分,使用 Unicode 扩展到了多种语言 -
-
词性标注:Part-of-Speech (POS)
也称为词类- 名词、动词、代词等
-
句法分析:Syntactic Parsing
- 树状结构的主谓宾定状补等
- 两种句法结构表示:不同点在于依托的文法规则不同
- 短语结构句法表示:上下文无关文法,层次性的
- 依存结构句法表示 (DSP):依托依存文法

-
语义分析
-
与前述语义不同,这里指的是离散符号和结构化的
-
词义消歧 WSD : 可以使用 WordNet 等语义词典
-
语义角色标注 SRL : 谓词论元结构
识别谓词后找到论元(语义角色)(施事 Agent 受事 Patient)
附加语义角色: 状语、副词等
-
语义依存分析 SDP : 通用图
- 语义依存图:词作为节点,词词关系作为语义关系边
- 概念语义图:首先将句子转化为虚拟的概念节点,然后建立语义关系边
-
专门任务:如自然语言转 SQL
-
III. 应用任务
-
信息抽取 IE : 非结构化文本提取结构化信息
-
命名实体识别 NER : 人名、机构名、地名、专有名称等名称。然后往往需要将命名实体链接到知识库或者知识图谱中的具体实体,被称作实体链接。
-
关系抽取:实体之间语义关系,如夫妻、子女、工作单位等
-
事件抽取:事件往往使用文本中提及的具体触发词 (Trigger) 定义,解析时间、地点、人物等关键因素。
~SRL : 谓词~Trigger, 论元~事件元素
-
时间表达式识别:时间表达式归一化。
绝对时间:日期等
相对时间:两天前
-
-
情感分析
- 情感分类
- 情感信息抽取:抽取情感元素,如评价词语、评价对象、评价搭配等
-
问答系统
- 检索式:查找相关文档抽取答案
- 知识库:问题 → \to →结构化查询语句 → \to →结构化知识存储 → \to →推理 → \to →答案
- 常见问题集:对历史积累的问题集合检索
- 阅读理解式:抽取给定文档中片段或生成
实际常常是综合的 -
机器翻译
- 任意时间
- 任意地点
- 任意语言
-
对话系统:多轮交互
-
任务型:自动业务助理等
自然语言理解 → \to →对话管理 → \to →自然语言生成
NLU : 领域(什么东西)、意图(要干什么)、槽值(?=?)等
DM : 对话状态跟踪 DST 和对话策略优化 DPO,对话状态往往表示为槽值列表
NLG : 有了 DPO 后比较简单,只需要套用问题模板即可
-
开放域:聊天系统或者聊天机器人
-
(三) 基本问题
以上任务都可以归结为三种问题
I. 文本分类问题
- 甚至文本匹配问题:文本对的关系分类,包括复述关系 Paraphrasing (语义是否相同)、蕴含关系 Entailment (蕴含或者矛盾)。一个方法就是:将文本对直接拼接,然后进行关系分类
II. 结构预测问题
-
序列标注
- 如 CRF 模型:不仅考虑每个词的标签概率 (发射概率),还考虑标签之间的关系 (转移概率)
- RNN + CRF
-
序列分割
-
分词、NER 等
-
也可以看成序列标注
NER : B-xxx 表示开始,I-xxx 表示中间,O-xxx 表示非实体
分词同理
-
-
图结构生成
-
基于图的算法:最小生成树,最小子图等
-
基于转移的算法:图 → \to →状态转移序列,状态 → \to →策略 → \to →动作等。
如用于 DSP 的 标准弧转移算法:
转移状态由一个栈 S m . . . S 1 S 0 S_m...S_1S_0 Sm...S1S0和队列 Q 0 Q 1 . . . Q n Q_0Q_1...Q_n Q0Q1...Qn组成, 栈存依存结构子树序列,队列存未处理的词
初始转移状态:栈为空
转移动作:
-
移进 Shift (SH) : first of Q to top of stack, engender an one-node sub-tree
-
左弧归约 Reduce Left (RL) : two sub-trees at top-stack, left arc=‘S1 ← \leftarrow ←S0’, S1 out
-
右弧归约 Reduce Right (RR): two sub-trees at top-stack, left arc=‘S1 → \rightarrow →S0’ S0 out
-
完成 FIN
弧上的句法关系可以在生成弧的时候(即 RR 或 RL)采用额外的句法关系分类器加以预测
该算法也可以用于短语结构的句法分析方法
-
-

III. 序列到序列问题
- 编码器-解码器
- 结构预测也能使用,但是由于结构预测有较强的对应关系,序列到序列很难保证这种对应关系,因此不常使用这种模型解决
(四) 评价指标
I. 标准答案明确的情况
- 准确率 Accuracy :正确的比所有的
- 精确率 Precision:正确的比所有识别出的
- 召回率 Recall:正确的
- F 值 F-score,特例 F1 值
- 对于 Syntactic Dependency Tree:
- UAS (unlabeled attachment score): 即准确率,父节点被正确识别的概率
- LAS:父节点被正确识别且与父节点的关系也正确的概率
- 对于 Semantic Dependency Graph :多个父节点不能用上述
- F-score : 图中的弧为单位,计算识别的精确率和召回率
- 可分为考虑和不考虑语义关系两种情况
- 对于 短语结构句法分析:也不能用准确率
- F-score : 句法结构中包含短语的 F 值进行评价
- 包含短语:包括短语类型以及短语所覆盖的范围
II. 标准答案不明确的情况
-
困惑度 PPL:见前述
-
BLEU : 统计机器译文与多个参考译文中 N-gram 匹配的数目占机器疑问中所有 N-gram 总数的比率,即 N-gram 的精确率; N 大小适中(>=2, <=4); 但仅这样忽略了召回率,倾向于短序列,于是引入了长度惩罚因子 (0~1),使其单词数目尽可能接近参考译文中的数目; 最终,BLEU ∈ [ 0 , 1 ] \in [0, 1] ∈[0,1], 越高越好
-
ROUGE : ~BLEU,但统计的是 N-gram 召回率, 即对于标准译文中的短语,统计一下它们有多少个出现在机器翻译的译文当中、
-
METOR : 用 WordNet 等知识源扩充了一下同义词集,同时考虑了单词的词形, 在评价句子流畅性的时候,用了 chunk 的概念(候选译文和参考译文能够对齐的、空间排列上连续的单词形成一个 chunk,这个对齐算法是一个有点复杂的启发式 beam serach),chunk 的数目越少意味着每个 chunk 的平均长度越长,也就是说候选译文和参考译文的语序越一致。最后还有召回率和准确率两者都要考虑,用 F 值作为最后的评价指标。
-
CIDEr : 多用于图像字幕生成,CIDEr 是 BLEU 和向量空间模型的结合。它把每个句子看成文档,然后计算 TF-IDF 向量(只不过 term 是 n-gram 而不是单词)的余弦夹角,据此得到候选句子和参考句子的相似度,同样是不同长度的 n-gram 相似度取平均得到最终结果。优点是不同的 n-gram 随着 TF-IDF 的不同而有不同的权重,因为整个语料里更常见的 n-gram 包含了更小的信息量。图像字幕生成评价的要点是看模型有没有抓取到关键信息
多个参考译文…没有怎么办,不好怎么办,主观怎么办,译文和原文有对应关系,那对于对话,没有语义相同关系怎么办,因此:只能人来了…
-
人为评价:多用于对话。多人评价其流畅度、相关度、准确性等等,给出主观分数进行统计
(五) 总结

三、基础工具集与常用数据集
(一) 工具集
所有这些,请移步开源代码笔记本 NoahKit@ZenMoore
- NLTK
- CoreNLP
- spaCy
- LTP
- PyTorch
(二) 数据集
-
WordNet : 包含同义词、释义、例句等
-
SentiWordNet : Senti=Sentiment
-
Wikipedia
下节介绍使用方法
-
Common Crawl
PB 级别,7 年爬虫我的妈,使用 Facebook 的 CC-Net 工具进行处理
-
Hugging Face Datasets
下节介绍使用方法
(三) Wikipedia 数据集使用方法
I. 原始数据获取
进入 Wikipedia 官网下载数据集压缩包,不需要解压
II. 语料处理方法
-
纯文本语料抽取
pip install wikiextractor python -m wikiextractor.WikiExtractor python -m wikiextractor.WikiExtractor -hthen we will get the following file system :
./text |- AA |- wiki_00 |- wiki_01 ... |- wiki_99 |_ AB ... |- A0and each text corpus ‘wiki_xx’ is like :
<doc id='xx' url="https://xxx" title="math"> xxxxx </doc> -
中文简繁体切换
我们使用 OpenCC : 甚至可以转换日本新体字等中文字体
pip install opencc python convert_t2s.py input_file > output_file -
数据清洗
包括:删除空的成对符号,删除除了 <doc> 外残留 html 标签,删除不可见控制字符等
python wikidata_cleaning.py input_file > output_file
(四) Hugging Face Datasets 使用方法
I. 数据集获取
pip install datasets
II. 调用 datasets
from datasets import list_datasets, load_dataset
import pprint
# dataset loading
datasets_list = list_datasets()
print(len(datasets_list)) # num_datasets
dataset = load_dataset('sst', split='train') # load SST (Stanford Sentiment Treebank)
print(len(dataset)) # num_samples
pprint(dataset[0]) # {'label':xxx, 'sentence':xxx, 'tokens':xxx, 'tree':xxx}
III. 调用 metrics
from datasets import list_metrics, load_metric
# metrics
metrics_list = list_metrics()
print(len(metrics_list)) # num_metrics
accuracy_metric = load_metric('accuracy')
results = accuracy_metric.compute(references= [0, 1, 0], predictions= [1, 1, 0])
print(results) # {'accuracy': 0.6666666}
四、NLP 的神经网络基础
(一) 理论学习
这个东西不要用这本书学习,系统的学习推荐以下教材:
以下是本书关于神经网络基础的目录:
多层感知机模型:感知器,线性/逻辑/Softmax回归,多层感知器
卷积神经网络
循环神经网络:普通,长短时记忆网络,基于 RNN 的序列到序列模型
注意力模型:注意力机制、自注意力模型、Transformer、基于 Transformer 的序列到序列模型,Transformer 模型的优缺点
神经网络训练:损失函数、梯度下降
(二) 代码学习
TensorFlow,PyTorch 等的学习请移步官网 Tutorial,如果感兴趣,可关注 NoahKit@ZenMoore
值得注意的是,PyTorch 新增了 Transformer 的支持:
import torch.nn as nn
data = torch.rand(2, 3, 4)
encoder_layer = nn.TransformerEncoderLayer(d_model= 4, nhead= 2)
transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers= 6)
memory = transformer_encoder(data)
decoder_layer = nn.TransformerDecoderLayer(d_model= 4, nhead= 2)
transfomer_decoder = nn.TransformerDecoder(decoder_layer, num_layers= 6)
out_part = torch.rand(2, 3, 4) # decoding history
out = transformer_decoder(out_part, memory)
(三) 项目实战
书中有两个实战:情感分类 和 词性标注,分别使用了 MLP、卷积神经网络、循环神经网络、Transformer 等,当然,还涉及了词表映射、词向量、数据处理等,非常的好,建议直接看看书中代码,有时间实现一下。如果没有这本书,那下面给出目录,照着网上的博客学习一下:
情感分类实战:词表映射 -> 词向量层 -> 融入词向量层的多层感知器 -> 数据处理 -> 多层感知器模型的训练与测试 -> 基于卷积神经网络的情感分类 -> 基于循环神经网络的情感分类 -> 基于 Transformer 的情感分类
词性标注实战:基于前馈神经网络的词性标注 -> 基于循环神经网络的词性标注 -> 基于 Transformer 的词性标注
五、静态词向量预训练模型
(一) 简单的词向量预训练
I. 预训练任务
-
基本任务就是根据上下文预测下一时刻词: P ( w t ∣ w 1 w 2 . . . w t − 1 ) P(w_t|w_1w_2...w_{t-1}) P(wt∣w1w2...wt−1)
-
这种监督信号来自于数据自身,因此称为自监督学习。
II. 前馈神经网络预训练词向量
-
输入层 → \to →词向量层 → \to →隐含层 → \to →输出层
-
训练后,词向量矩阵 E ∈ R d × ∣ V ∣ \pmb{E}\in\mathbb{R}^{d\times|\mathbb{V}|} EEE∈Rd×∣V∣ 即为预训练得到的静态词向量
III. 循环神经网络预训练词向量
-
输入层 → \to →词向量层 → \to →隐含层 → \to →输出层
-
然后把词向量层参数和词表(一一对应)保存下来就是静态词向量
(二) Word2Vec 词向量
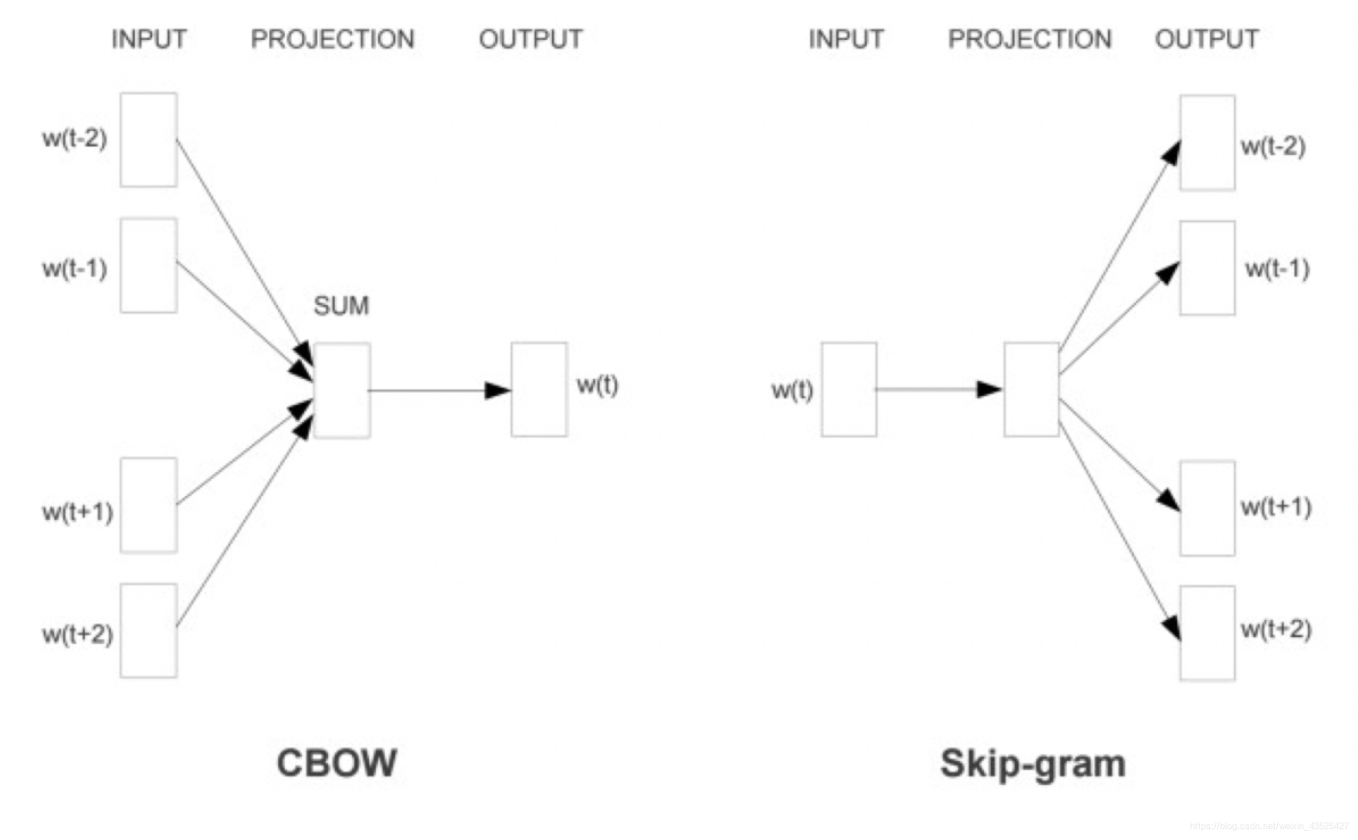
I. CBOW 模型
- 即 Continuous Bags-of-Words
- 基本思想:同时考虑历史与未来,选择一个上下文窗口 C t = { w t − k , . . . , w t − 1 , w t + 1 , . . . , w t + k } \mathcal{C_t}=\{w_{t-k},...,w_{t-1},w_{t+1},..., w_{t+k}\} Ct={ wt−k,...,wt−1,wt+1,...,wt+k} ,如图示为大小为 5 的窗口
- 输入层:词汇的独热向量 e w i = [ 0 ; . . . ; 1 ; . . . 0 ] ∈ [ [ 0 , 1 ] ] ∣ V ∣ e_{w_i}=[0;...;1;...0]\in [[0, 1]]^{\mathbb{|V|}} ewi=[0;...;1;...0]∈[[0,1]]∣V∣
- 词向量层:参数为 E ∈ R d × ∣ V ∣ \pmb{E}\in\mathbb{R}^{d\times|\mathbb{V}|} EEE∈Rd×∣V∣
- 隐含层:仅做平均操作 v C t = 1 ∣ C t ∣ ∑ w ∈ C t v w v_{\mathcal{C_t}=\frac{1}{\mathcal{|C_t|}}\sum_{w\in\mathcal{C_t}}v_w} vCt=∣Ct∣1∑w∈Ctvw
- 输出层:参数为 E ′ ∈ R ∣ V ∣ × d \pmb{E'}\in \mathbb{R}^{\mathbb{|V|}\times d} E′E′E′∈R∣V∣×d, P ( w t ∣ C t ) = e x p ( v C t ⋅ v w t ′ ) ∑ w ′ ∈ V exp ( v C t ⋅ v w ′ ′ ) P(w_t|\mathcal{C_t})=\frac{exp(v_{\mathcal{C_t}}·v'_{w_t})}{\sum_{w'\in \mathbb{V}}\exp(v_{\mathcal{C_t}}·v'_{w'})} P(wt∣Ct)=∑w′∈Vexp(vCt⋅vw′′)exp(vCt⋅vwt′), where v w i ′ v'_{w_i} vwi′是 E ′ \pmb{E'} E′E′E′中与 w i w_i wi 对应的行向量
- 词向量矩阵: E , E ′ \pmb{E, E'} E,E′E,E′E,E′ 都可以作为词向量矩阵,分别表示了词在作为条件上下文或目标词时的不同性质。实际常用 E \pmb{E} EEE, 也可以两者组合起来。
- 特点:不考虑上下文中单词的位置或者顺序,因此输入是一个词袋而非序列。
II. Skip-gram 模型
-
基本思想:在 CBOW 基础上简化为 “使用 C t \mathcal{C_t} Ct 中的每个词作为独立的上下文对目标词进行预测”, 即 P ( w t ∣ w t + j ) P(w_t|w_{t+j}) P(wt∣wt+j)
原文献是 P ( w t + j ∣ w t ) P(w_{t+j}|w_t) P(wt+j∣wt), 两者等价,本书采取原文献的办法
-
隐含层向量: v w t = E w t T v_{w_t}=\pmb{E_{w_t}^T} vwt=EwtTEwtTEwtT
-
输出层:参数为 E ′ ∈ R ∣ V ∣ × d \pmb{E'}\in \mathbb{R}^{\mathbb{|V|}\times d} E′E′E′∈R∣V∣×d, P ( c ∣ w t ) = e x p ( v w t ⋅ v c ′ ) ∑ w ′ ∈ V e x p ( v w t ⋅ v w ′ ′ ) P(c|w_t)=\frac{exp(v_{w_t}·v'_c)}{\sum_{w'\in\mathbb{V}}exp(v_{w_t}·v_{w'}')} P(c∣wt)=∑w′∈Vexp(vwt⋅vw′′)exp(vwt⋅vc′), where v w i ′ v'_{w_i} vwi′是 E ′ \pmb{E'} E′E′E′中与 w i w_i wi 对应的行向量
-
词向量:与 CBOW 同。
III. 参数估计与预训练任务
- θ = { E , E ′ } \pmb{\theta}=\{\pmb{E}, \pmb{E'}\} θθθ={ E