并发的基本概念
并发与并行
并发(concurrent)是指计算机可以处理多个任务,且并非像串行执行,这些任务并不需要等待计算机完成其中一个后再开始下一个,而是可以在多个任务间切换执行,或者同时执行多个任务。
并行(parallelism)是指则是指多核计算机可以使用自己的多个CPU同时独立地执行多个任务。从定义上可以看出,并行的要求更为严格。必须是多核计算机利用其多核同时处理多个任务。而并发并不要求一定是调用多核同时工作,仅仅调用单核通过时分复用的方式在多个任务中切换执行也属于并发的一种。
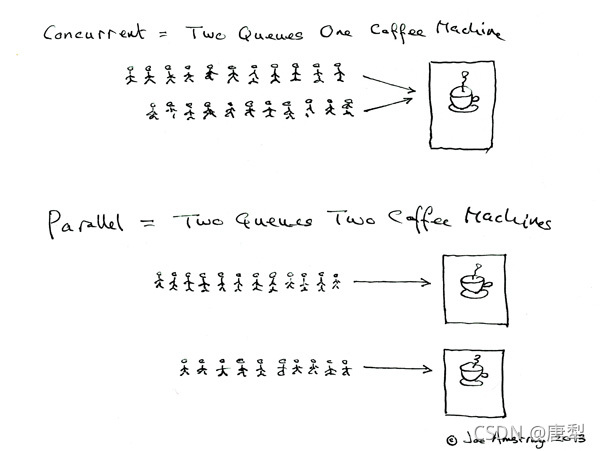
Joe Armstrong博士的画描述了这样一个场景,并发就是两队人去一个咖啡机打咖啡,咖啡机只有一台,只是不断切换打咖啡的人来实现服务多个人。并行就是两队人去两个咖啡机打咖啡,咖啡机有两台,但是队内依旧是通过排队换人的方式实现的一个咖啡机服务多个人。
并发的本质,是多路复用,将有限资源强制分给多个用户,而并行则是同时发生的多个并发事件。
同步与异步
同步机制,指的是一系列任务必须逐一完成。所有未被完成的任务,必须等待当前任务完成后,才能开始执行;对于当前执行的任务而言,必须要从头到尾一次执行完。比如我们去体检,测视力的时候,医生需要一个人从上到下把他能看清的符号都指出来,然后再叫下一个人进来。这就是一种同步机制——前一个人没有完成这一项检查之前,后面所有人都不能进来检查视力。
异步机制,则是在当前任务没有完全完成的情况下,可以在中途暂停,去执行一个其他的任务。当这个任务的暂停结束后,再切换回来继续刚刚的进度执行下去。这种机制主要是针对等待时间比较长,会产生资源浪费的情况。比如体检的时候抽血,结果可能需要10分钟的时间才能出来。那这等待的10分钟就可以去做其他的项目,比如查一下视力,测一下身高。当抽血结果出来之后,再回去取抽血的结果。
异步机制虽然看上去比同步机制更为合理,但是因为让出CPU会造成额外开销,因此异步并不总是比同步机制更合适。
Python的并发方式
多进程,多线程,以及GIL
像其他很多语言一样,python中的多进程可以实现并行运算。每一个进程可以调用一个CPU独立完成自己的任务。在这些进程中,每个进程都可以拥有多个线程。
然而python中的多线程是无法同时使用多个CPU的,因为在python中有一个GIL(Global Interpreter Lock)存在。在一个进程中,每个线程都需要获取GIL才能进入CPU执行,而GIL在一个进程中只存在一个,因此同一个进程里,最多只有一个线程可以在CPU中执行。只有当时间片用尽时,或者当前执行的线程等待时,才会释放GIL,由其他线程进行竞争。
因此在python中,处理I/O密集型任务可以使用多线程,但是在CPU密集型任务中,由于多线程只能调用一个CPU,无法完成加速,因此往往使用多进程。
协程
由于每个进程都有自己的独立内存空间,因此上下文进程切换的开销比较大。同一个进程内的线程是共享内存的,因此上下文切换比进程要快。但是由于线程需要线程锁,并且当线程锁释放时,线程的工作需要由计算机进行调度,因此依然存在一定的切换开销。
协程(coroutine)则是在进程内更为轻量的一种微线程,多个协程之间切换并不依赖多线程的机制,而是在同一个线程里执行。协程本质上和线程一样,可以看作是一种可以灵活中断的函数。当执行一个普通的函数调用时,如果A调用B,则B运行结束返回之后才会继续执行A。而协程A运行时如果中断去执行协程B,则不需要等B执行完,而是当A的中断条件结束后随时可以由B切换回A。
协程在运行的时候和线程类似,占用空间更小。在切换时,协程比线程效率更高。当一个线程的时间片用尽之后,CPU会中断,由OS切换上下文,此时进程的内核空间需要保存当前线程的上下文。但是协程却不需要保存上下文,因为其调度算法是在用户态完成的。因此,由程序自身控制的协程没有线程切换的开销。同时,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源也不需要多线程的锁机制。
协程的实现方式
生成器的send与yield
在python的3.5版本前,协程是基于生成器(generator)实现的。在理解协程的工作方式之前,可以先搞清楚生成器的通信问题。这里写一个例子简单说一下生成器的工作方式。
首先构建一个生成器函数gen_demo。
recv = 20
def gen_demo():
global recv
yield 1
yield 2
recv = yield 3
while recv > 0:
yield 4
recv = yield 5
print('recv:', recv)
yield 'Finish.'
然后通过生成器的send函数调用。
g = gen_demo()
# 1
print(g.send(None))
# 2
print(g.send(6))
# 3
print(recv)
print(g.send(7))
print(recv)
# recv: 8
# 4
print(g.send(8))
print('recv:', recv)
# 5
print(g.send(9))
# recv: 10
# 4
print(g.send(10))
# 5
print(g.send(11))
# recv: -1
# Finish.
print(g.send(-1))
结果为:
1
2
20
3
20
4
recv: 8
5
recv: 10
4
5
recv: -1
Finish.
生成器的send方法用来完成生成器的一次运行,也就是从当前位置运行至下一个yield所在的位置。从代码开始的yield 1和yield 2可以看出,生成器中的yield关键字相当于是return,将一个值返回给生成器的调用者。从yield 3和yield 4中可以看出,当yield位于赋值语句右侧时,代码运行至yield处返回,然后在下一次使用send调用生成器时,将send中的值传递到上次yield返回处,赋给赋值语句左边的变量。
生成器的yield关键字可以随时暂停运行,之后再从上次结束的位置恢复运行,这就是一种上下文机制,其调度也是在用户态实现的。因此依靠yield关键字实现的生成器可以成为协程的一种实现方式。经典的例子是通过生成器的send和yield不断切换生成器的运行,实现生产者-消费者模型。
def consumer():
print('[消费]开始消费...') # 4. 执行生成器
response = None
while True:
print('[消费]中断,保存上下文')
n = yield response # 5. 中断,保存上下文;返回response,接收n
print('[消费]恢复上下文,继续运行') # 8. 消费者恢复上下文,继续运行
if not n:
return
print(f'[消费]消费者消费了{n}个产品') # 9. 打印接收到的n值
response = 'OK,本次消费完成'
def produce(c):
print('[生产]开始生产...')
c.send(None) # 3. 启动生成器
print('[生产]首次唤醒生成器成功,继续生产...') # 6. 继续生产
n = 0
while n < 5:
n += 1
print(f'[生产]生产者已经生产了{n}次,这是n的值')
r = c.send(n) # 7. 再次唤醒生成器
print(f'[生产]生产者此时收到消费者返回的消息为:{r},这是r的值') # 10. 消费者返回的response被赋值给r
c.close()
c = consumer() # 1. 定义生产者,未执行
produce(c) # 2. 运行produce
greenlet
作为一个第三方库,greenlet的switch方法在使用上比原生的yield关键字更加简单清晰。通过greenlet创造出的协程,可以通过switch方法进行切换,切换时只需要调用此时想运行的协程的swtich方法就可以。因此在代码的编写和阅读上简单很多,可以很明确的知道此时要切换到哪一个协程上继续工作。
from greenlet import greenlet
def task_1():
while True:
print('Task 1 start.')
t2.switch() # switch to t2
print('Task 1 end.')
time.sleep(1)
def task_2():
while True:
print('Task 2 start.')
t1.switch() # switch to t1
print('Task 2 end.')
time.sleep(0.5)
t1 = greenlet(task_1)
t2 = greenlet(task_2)
t1.switch()
gevent
Gevent是另一个第三方库,相比于greenlet,gevent可以更高效的切换协程。Gevent是基于greenlet实现的协程,但是gevent提供了如gevent.sleep()等函数的封装。当gevent中的协程遇到类似的阻塞时,它会让出CPU,切换至另一个协程运行。如果没有阻塞发生,协程之间不会完成这种切换。
import gevent
def task(num, task_name):
for i in range(1, num+1):
print('Start {} -- {}.'.format(task_name, i))
gevent.sleep(1)
print('\nFinish {} -- {}.\n'.format(task_name, i))
t1 = gevent.spawn(task, 3, 't1')
t2 = gevent.spawn(task, 3, 't2')
t3 = gevent.spawn(task, 3, 't3')
t1.join()
t2.join()
t3.join()
通过monkey实现阻塞切换。
from gevent import monkey
import gevent
def task_1(task_name):
for i in range(5):
print(task_name, i)
time.sleep(1)
def task_2(task_name):
for i in range(5):
print(task_name, i)
time.sleep(1)
monkey.patch_all()
gevent.joinall([gevent.spawn(task_1, 'task-1'), gevent.spawn(task_2, 'task-2')])
asyncio
相比于之前三种协程实现方式,asyncio功能更为强大,使用频率更高。
事件循环event_loop
协程coroutine
task与future
在asyncio中,每个协程都是以task的形式工作的,task中保存着协程所需要的上下文信息。刚创建出的task是pending状态的,只有调用asyncio.run()方法才会真正开始运行。
回调函数
async与await
从python 3.7开始,async与await成为关键字,用于定义协程和挂起阻塞。在此之前,协程的定义往往通过@asyncio.coroutine的装饰器将一个生成器标记为协程类型,现在只需要将定义函数的def关键字改为async def即可。通过async关键字创建的函数本身,就是一个协程,运行时将协程封装成一个asyncio的task即可。在asyncio中,每个协程都是以task的形式工作的,task中保存着协程所需要的上下文信息。刚创建出的task是pending状态的,只有调用asyncio.run()方法才会真正开始运行。
async def task(task_name):
for i in range(3):
print(f'Task {task_name} is running.')
coro = task(1)
asyncio.run(coro)
在python 3.7以前,asyncio的任务都是通过放入event_loop来实现的。首先需要创建一个task,
import asyncio
async def task(task_name):
for i in range(3):
print(f'Task {task_name} is running.')
coro = task(1)
loop = asyncio.get_event_loop()
result = loop.run_until_complete(coro)
print(result)
async def main():
print('Hello')
await asyncio.sleep(1)
print('World!')
asyncio.run(main())
async def work(name, num):
f = 1
for i in range(2, num + 1):
print(f'Task {name}: Function ({i})')
await asyncio.sleep(1)
f *= i
print(f'Task {name}: Function ({num} = {f})')
return f'Task {name}: Done.'
async def main():
result = await asyncio.gather(
work('A', 2),
work('B', 4),
work('C', 6),
)
async def work(name, num):
f = 1
for i in range(2, num + 1):
print(f'Task {name}: Function ({i})')
await asyncio.sleep(1)
f *= i
print(f'Task {name}: Function ({num} = {f})')
return f'Task {name}: Done.'
async def main():
try:
result = await shield(work('A', 2))
except CancelledError:
result = None
print(result)