在Flink中,作业(Job)的提交流程是一个复杂的过程,涉及多个组件和模块,包括作业的编译、优化、序列化、任务分发、任务调度、资源分配等。Flink通过分布式架构来管理作业的生命周期,确保作业在不同节点上以高效和容错的方式运行。我们可以从底层原理和源码层面详细解析Flink作业的提交流程。
1. Flink的架构组件
Flink作业提交流程的底层实现涉及以下几个核心组件:
- Client:用户通过Client提交作业,通常是通过Flink的API(如
DataStream或TableAPI)构建作业。 - JobManager:负责协调和管理Flink集群的运行时组件。其主要职责是作业的调度、资源分配、故障恢复等。
- TaskManager:负责在各个工作节点上执行作业的具体任务(Task),并与JobManager通信,报告状态和进度。
- Dispatcher:负责接受Client的作业请求,并将作业传递给JobManager处理。
- ResourceManager:负责资源的分配和调度,确保集群有足够的资源来运行提交的作业。
2. 作业提交流程的概览
Flink作业的提交流程可以分为以下几个主要步骤:

- 用户代码编写与作业构建:用户通过Flink API构建Flink作业逻辑,生成相应的
StreamGraph(流作业)或Table作业。 - 生成JobGraph:Client将用户定义的逻辑转换为Flink内部的
JobGraph,这是Flink理解并能够执行的作业表示。 - 向Dispatcher提交JobGraph:Client将JobGraph提交到集群的Dispatcher,Dispatcher接受作业请求。
- JobManager接管JobGraph:Dispatcher将JobGraph提交给JobManager,JobManager负责作业的调度和执行。
- JobGraph转换为ExecutionGraph:JobManager将JobGraph进一步优化并转换为
ExecutionGraph,这是Flink真正执行的物理作业计划。 - 任务的调度与执行:JobManager将ExecutionGraph分解为多个并行子任务,调度给TaskManager去执行。
- 作业执行与监控:TaskManager执行各个子任务,并通过心跳机制向JobManager报告任务状态。
3. 从源码角度详细解析提交流程
3.1 用户提交作业
作业提交流程从用户通过ExecutionEnvironment或StreamExecutionEnvironment提交作业开始。下面以DataStream API为例,提交流程一般是通过调用StreamExecutionEnvironment.execute()来触发。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements(1, 2, 3, 4, 5)
.map(i -> i * i)
.print();
env.execute("Flink Job");
调用execute()方法后,Flink会进行以下操作:
- 创建StreamGraph:在执行环境中,用户定义的操作被转化为
StreamGraph,这是Flink作业的逻辑表示,记录了所有的操作算子及其连接关系。StreamGraph streamGraph = this.getStreamGraph();
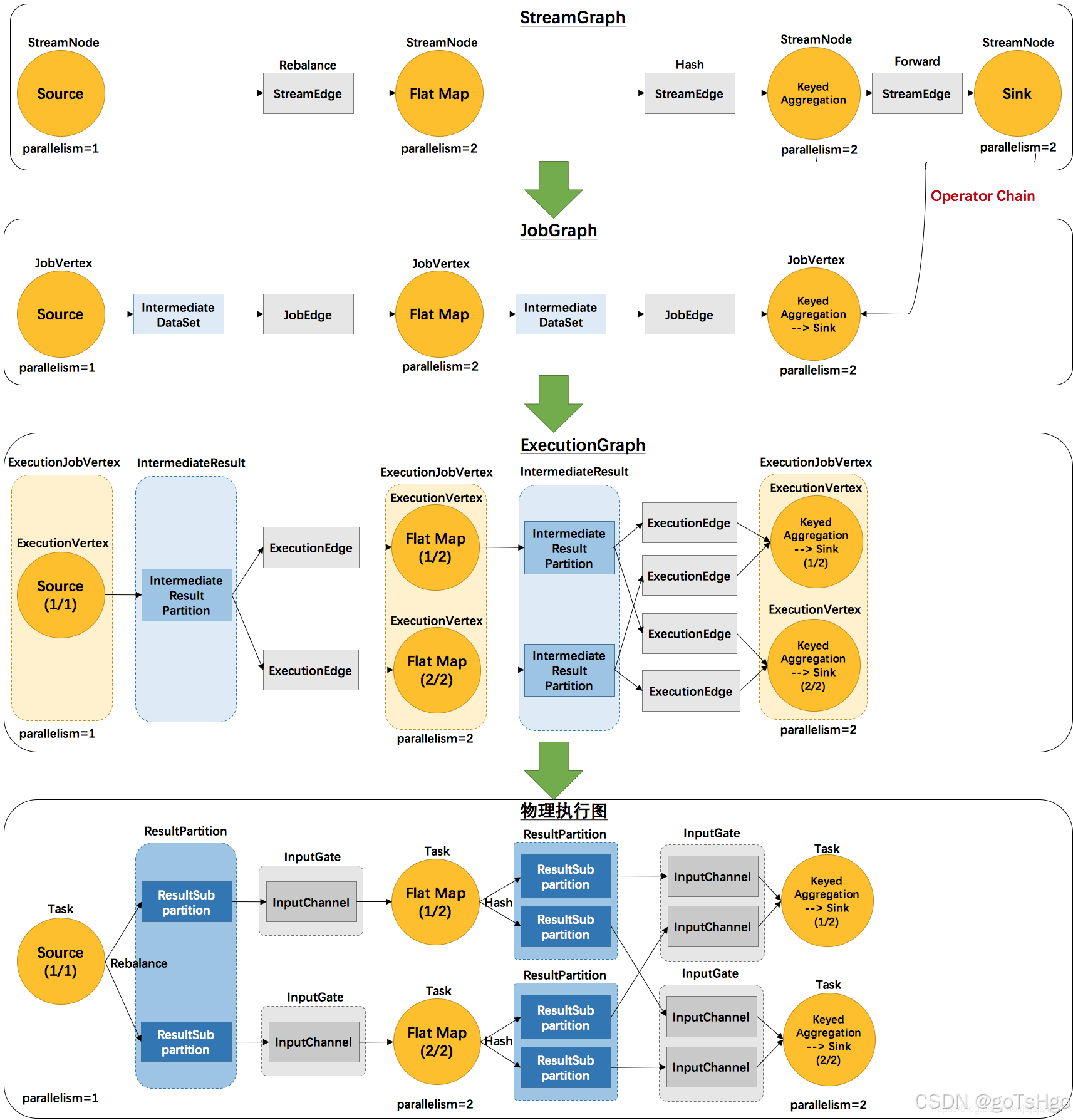
3.2 生成JobGraph
一旦StreamGraph构建完成,Flink将其转换为JobGraph。JobGraph是一个优化后的表示,它将包含计算任务的并行度、物理任务之间的依赖关系等,是Flink提交给集群进行分布式执行的作业表示。
JobGraph jobGraph = streamGraph.getJobGraph();- JobVertex:
JobGraph中的每个操作算子(如map、filter等)会被转化为JobVertex,代表一个逻辑上的计算节点。 - JobEdge:操作算子之间的连接关系会被转化为
JobEdge,定义了不同JobVertex之间的数据流动。
3.3 提交JobGraph到Dispatcher
客户端通过RPC将JobGraph提交给Flink集群中的Dispatcher,由它来接管作业的调度和执行。
dispatcherGateway.submitJob(jobGraph, "Flink Job", timeout); Dispatcher接受到作业后,会创建一个JobManager实例来负责具体的作业执行流程。在集群模式下(如YARN、Kubernetes等),Dispatcher可能会启动一个新的JobManager(即JobMaster)实例来执行作业。
3.4 JobManager接管JobGraph
在JobManager中,接收到JobGraph后,作业的核心执行流程将由JobMaster处理。JobMaster首先会将JobGraph进一步优化和转换为ExecutionGraph,这是Flink中实际执行任务的图结构,包含所有物理任务及其依赖关系。
ExecutionGraph executionGraph = new ExecutionGraph(jobGraph, ...);- ExecutionVertex:
ExecutionGraph中的每个顶点代表一个具体的并行任务(即ExecutionVertex),它们会被调度给不同的TaskManager实例执行。 - ExecutionEdge:
ExecutionVertex之间的依赖关系被表示为ExecutionEdge,用于描述不同任务之间的通信模式(如shuffle)。
3.5 任务的调度与资源分配
JobMaster接管ExecutionGraph后,会向ResourceManager申请资源以执行任务。ResourceManager负责调度并分配资源到TaskManager,每个TaskManager会接收一部分任务并执行。
resourceManagerGateway.requestSlot(...);- Slot分配:每个
TaskManager拥有多个Slot,表示可用的计算资源。ResourceManager根据任务并行度为ExecutionVertex分配Slot。 - 任务调度:一旦Slot分配完成,
JobMaster会将任务调度到相应的TaskManager,通过RPC调用将任务部署到这些TaskManager。
3.6 任务执行与监控
TaskManager负责执行分配到的任务,它会启动相应的线程来处理每个ExecutionVertex中的任务。任务执行过程中,TaskManager会定期通过心跳机制向JobMaster报告任务的状态和进度。
taskExecutorGateway.submitTask(...);- 故障恢复:如果任务失败,
JobMaster会根据Flink的容错机制(如检查点机制)尝试重新调度任务,确保作业的高可用性。
4. 重要的源码模块
- JobGraph:
org.apache.flink.runtime.jobgraph.JobGraph,表示用户作业的逻辑执行计划。 - ExecutionGraph:
org.apache.flink.runtime.executiongraph.ExecutionGraph,表示作业的物理执行计划,任务调度基于此结构。 - JobMaster:
org.apache.flink.runtime.jobmaster.JobMaster,负责管理作业的整个生命周期,包括任务调度、资源分配、故障恢复等。 - ResourceManager:
org.apache.flink.runtime.resourcemanager.ResourceManager,负责资源的管理和分配,确保作业运行时所需的计算资源。 - TaskManager:
org.apache.flink.runtime.taskmanager.TaskManager,在每个节点上运行,负责执行具体的任务并与JobManager协调。
5. Flink作业提交流程总结
- 用户通过Client提交Flink作业,作业被转换为JobGraph。
- JobGraph通过Dispatcher提交给JobManager,JobManager将其转换为ExecutionGraph。
- JobManager与ResourceManager交互,申请并分配资源,调度任务到TaskManager执行。
- TaskManager执行任务,并定期向JobManager报告任务状态。
- 整个流程基于高效的分布式架构和容错机制,保证作业的稳定和可靠执行。
这就是Flink作业从提交到执行的详细提交流程,从底层原理和源码层面揭示了Flink的作业管理机制。