K-means 聚类是一种常用的基于距离的聚类算法,旨在将数据集划分为 
1. K-means 的核心思想
K-means 的目标是将数据集划分为
核心思想
- 簇(Cluster):K-means 通过最小化簇内距离的平方和,使得数据点在簇内聚集。一个簇是数据点的集合,这些点在某种意义上“彼此相似”。比如,可以将商场顾客分为“学生群体”“上班族”“退休老人”这三个簇。
- 簇中心(Centroid):簇中心是簇中所有点的平均值,表示簇的中心位置。
- 簇分配和更新:K-means 通过反复迭代,调整簇的分配,使得簇内数据点与质心的距离尽可能小,逐步收敛。
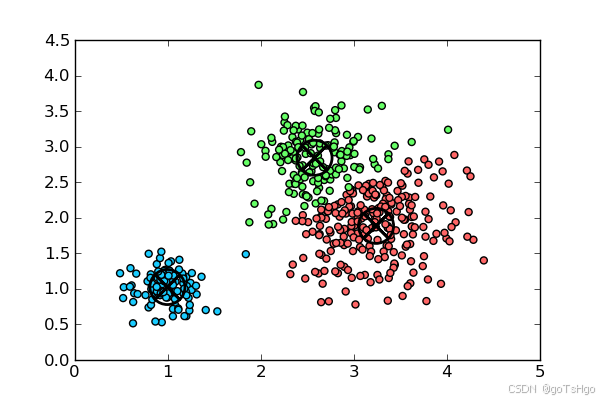
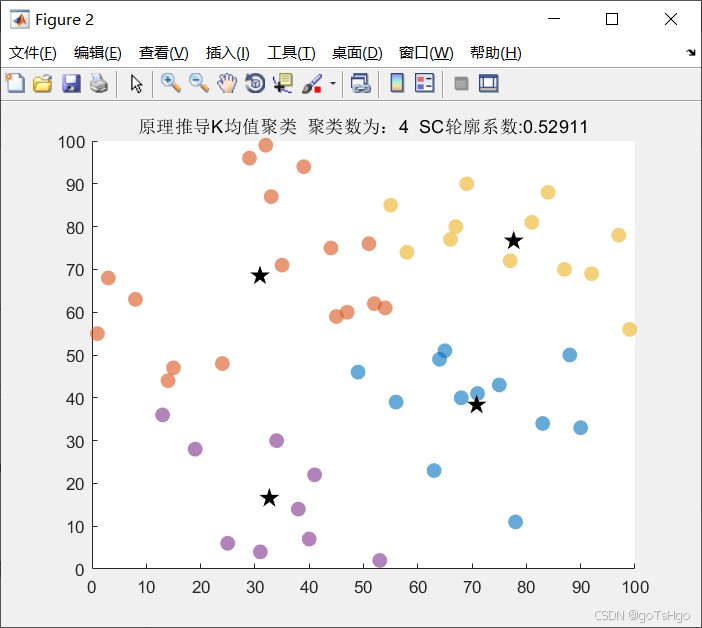
如下图:
以簇中心为中心,划分范围
2. K-means 聚类的工作流程
2.1 核心思想
K-means 使用“最近距离”来分组:
- 随机选择 K 个质心(初始中心点)。
- 每个数据点分配到距离最近的质心所属的簇。
- 重新计算每个簇的质心。
- 重复步骤 2 和 3,直到质心不再变化(或达到指定的迭代次数)。
2.2 算法步骤(结合例子)
K-means 聚类的流程分为两个主要步骤:分配(Assignment)和更新(Update)。以下是详细步骤:
-
选择 K 值:
设定簇的数量 -
初始化簇中心:
随机选择 -
分配步骤(Assignment Step):
对于数据集中的每个点,将它分配到最近的簇中心对应的簇。这里的“距离”通常使用欧氏距离(Euclidean distance)。 -
更新步骤(Update Step):
根据当前的簇分配,重新计算每个簇的中心,即计算簇内所有点的均值作为新的簇中心。 -
重复 3 和 4 步:
不断重复分配和更新步骤,直到簇中心不再发生变化(收敛)或达到指定的最大迭代次数。
例子:
假设我们有以下二维数据点,表示顾客的“消费金额”和“访问次数”:
| 数据点编号 | 消费金额(x) | 访问次数(y) |
|---|---|---|
| 点1 | 1 | 2 |
| 点2 | 2 | 1 |
| 点3 | 4 | 5 |
| 点4 | 5 | 4 |
| 点5 | 8 | 8 |
目标是将这些点分为 K=2 个簇。
第一步:初始化质心
- 随机选择两个点作为初始质心(假设选择点1 和点5)。
- 初始质心为:
- C1=(1,2)
- C2=(8,8)
第二步:分配簇
计算每个点到两个质心的欧几里得距离:
| 数据点编号 | 到 C1 的距离 | 到 C2 的距离 | 最近质心 | 分配簇 |
|---|---|---|---|---|
| 点1 | 0 | 8.49 | C1 | 簇1 |
| 点2 | 1.41 | 8.06 | C1 | 簇1 |
| 点3 | 4.24 | 5.0 | C1 | 簇1 |
| 点4 | 5.0 | 4.24 | C2 | 簇2 |
| 点5 | 8.49 | 0 | C2 | 簇2 |
分配结果:
- 簇1:点1、点2、点3
- 簇2:点4、点5
第三步:重新计算质心
对于每个簇,计算新质心的位置:
- 簇1 的质心:(平均x,平均y)=(1+2+4/3,2+1+5/3)=(2.33,2.67)
- 簇2 的质心:(平均x,平均y)=(5+8/2,4+8/2)=(6.5,6.0)
更新质心为:
- C1=(2.33,2.67)
- C2=(6.5,6.0)
第四步:重复分配与更新
再次计算每个点到新质心的距离,重复“分配簇”和“重新计算质心”步骤,直到质心不再变化。
最终结果:
- 簇1:点1、点2、点3
- 簇2:点4、点5
质心稳定在:
- C1=(2.33,2.67)
- C2=(6.5,6.0)
3. K-means 的数学公式
K-means 的目标是最小化簇内平方误差和(Within-Cluster Sum of Squares,WCSS),即每个点到其所属簇中心的距离的平方和,公式如下:
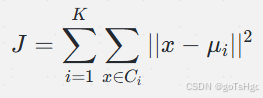
其中:
是第
个簇的点集。
是属于
是第
表示数据点
欧氏距离
K-means 通常采用欧氏距离来衡量点到簇中心的距离,其公式为:
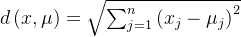
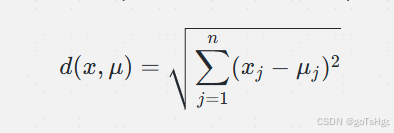
其中 n 是数据的维度。
4. K-means 的伪代码
KMeans(X, K):
1. 随机选择 K 个点作为初始簇中心
2. 重复以下步骤,直到簇中心不再发生变化:
a. 分配每个点到最近的簇中心
b. 重新计算每个簇的中心,作为簇内所有点的均值
3. 返回最终的簇分配和簇中心
分配步骤(Assignment Step)
对于每个数据点,找到距离最近的簇中心 μj:
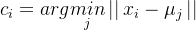

更新步骤(Update Step)
更新每个簇的中心 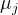

5. K-means 的时间复杂度分析
- 每次分配步骤:需要计算每个点到
。
- 更新步骤:重新计算每个簇的中心,需要遍历所有点,复杂度也是
- 总复杂度:若迭代次数为
,则总体复杂度为
。
6. K-means 的优缺点
优点
- 简单高效:适合大规模数据,处理大数据集时非常高效,具有良好的伸缩性。
- 收敛速度快:在适合的初始中心选择下,K-means 通常可以较快收敛。
缺点
- 对初始点敏感:初始簇中心的选择对最终结果影响较大。
- 非凸形状簇(球形簇):K-means 假设每个簇是凸形且大小相近,不适合发现非凸形状的簇或大小差异很大的簇,如“月牙型”数据。
- 对噪声敏感:离群点会影响簇的中心计算。
- 局部最优:K-means不能保证全局最优,只能达到局部最优
- 数据种类限制:算法要求样本存在均值,限制了数据的种类
7. K 值的选择
确定最佳的簇数
-
肘部法(Elbow Method):
绘制不同 K 值下的 WCSS 图,寻找“肘部”点作为最佳 -
轮廓系数(Silhouette Coefficient):
衡量聚类结果的紧密度和分离度。通常,轮廓系数越高,聚类效果越好。 -
Calinski-Harabasz 指数:
衡量簇内的方差与簇间方差之比,值越大越好。
下图可以发现当k=4或者5时是最佳的情况SSE图像下降幅度最大放缓的情况在4-5之间。
具体方法见我另一篇文章:使用肘部法则(Elbow Method)来确定最佳K值_elbow method for optimal k
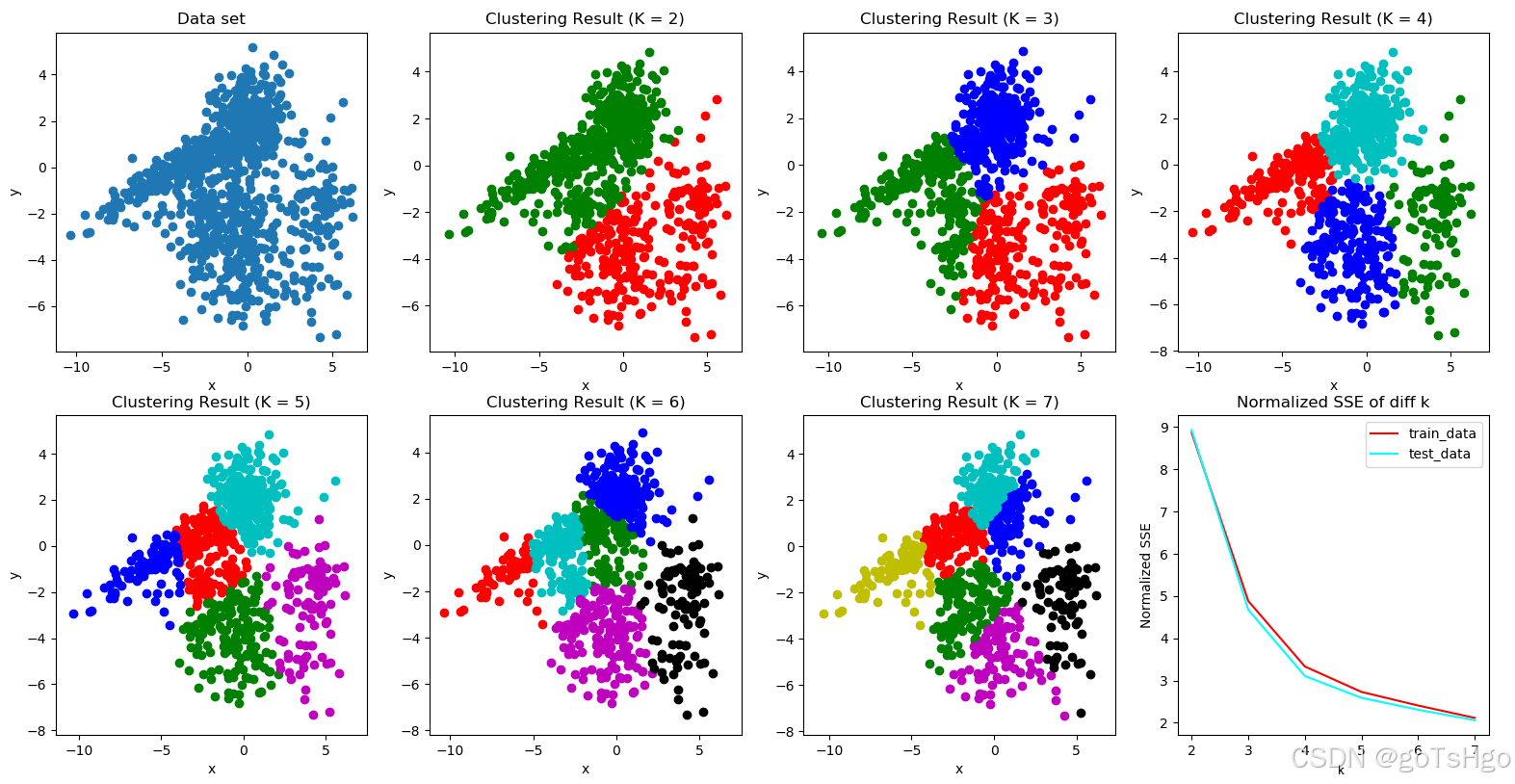
8. Python 实现 K-means
我们可以使用 scikit-learn 中的 KMeans,以及手动实现以便更深入理解。
8.1 使用 scikit-learn 实现 K-means
from sklearn.cluster import KMeans
import numpy as np
# 生成示例数据
X = np.array([[1, 2], [2, 2], [3, 3], [8, 7], [8, 8], [25, 80]])
# 初始化并训练 KMeans 模型
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
# 获取簇标签和簇中心
labels = kmeans.labels_
centroids = kmeans.cluster_centers_
print("Cluster labels:", labels)
print("Centroids:", centroids)
输出:
Cluster labels: [0 0 0 1 1 1]
Centroids: [[ 2. 2.33333333]
[13.66666667 31.66666667]]
8.2 手动实现 K-means 算法
以下是 K-means 的核心逻辑手动实现:
import numpy as np
def initialize_centroids(X, k):
indices = np.random.choice(len(X), k, replace=False)
return X[indices]
def closest_centroid(X, centroids):
distances = np.linalg.norm(X[:, np.newaxis] - centroids, axis=2)
return np.argmin(distances, axis=1)
def update_centroids(X, labels, k):
return np.array([X[labels == i].mean(axis=0) for i in range(k)])
def kmeans(X, k, max_iters=100, tol=1e-4):
centroids = initialize_centroids(X, k)
for i in range(max_iters):
labels = closest_centroid(X, centroids)
new_centroids = update_centroids(X, labels, k)
if np.all(np.abs(new_centroids - centroids) < tol):
break
centroids = new_centroids
return labels, centroids
# 示例数据
X = np.array([[1, 2], [2, 2], [3, 3], [8, 7], [8, 8], [25, 80]])
# 运行 K-means
labels, centroids = kmeans(X, k=2)
print("最终簇:", labels)
print("质心位置:", centroids)
9. 收敛性与初始中心的选择
K-means 的收敛性受到初始簇中心选择的影响。K-means++ 是一种改进的初始化方法,可以帮助选择更合理的初始中心,优先选择“距离最远”的点作为初始质心,减少陷入局部最优的风险。
K-means++ 初始中心选择步骤
- 随机选择一个点作为第一个中心。
- 对于每个点,计算其与已选择中心的最小距离。
对于每一个未被选中的数据点,计算其到已选中心的距离。具体来说,假设已经选择了 k 个聚类中心,接下来要选择第 k+1 个中心:
- 计算距离:计算每个数据点到最近一个已选聚类中心的距离 D(x),即对于数据点 x,计算其到已选择的所有质心的最短距离 D(x),其中 C 是已选的聚类中心集合。
- 加权选择下一个中心:根据每个数据点的距离 D(x) 的平方来选择下一个聚类中心,选择的概率与 D(x)的值的大小 成正比。也就是说,距离当前已选聚类中心远的点,被选为新中心的概率更大。
- 重复步骤 2,直到选择 K 个聚类中心
为什么 K-means++ 更好?
-
避免了随机初始化的问题:传统的 K-means 算法是随机选择聚类中心,可能导致聚类中心选择得非常接近,这样会导致算法陷入局部最优解,或者聚类效果不好。K-means++ 通过加权选择,确保了初始聚类中心的分布更加均匀,从而减少了这种风险。
-
提高了收敛速度:由于初始聚类中心已经比较合理,K-means++ 通常能更快收敛。K-means 算法的收敛速度和初始中心的选择密切相关,选择较好的初始中心可以减少迭代次数。
-
更稳定的聚类结果:K-means++ 选择中心的方式使得最终聚类结果更加稳定,尤其在处理具有复杂结构或分布的数据时,相比传统的随机初始化方法,K-means++ 更能得到质量较高的聚类结果。
10. 总结
K-means 是一种简单、快速的聚类算法,广泛应用于数据聚类任务。通过反复优化簇中心位置,K-means 不断收敛并找到数据的聚类结构。然而,它对初始条件敏感,对簇形状有限制,适合于球形且均匀分布的簇。在实际应用中,可通过结合 K-means++、肘部法和轮廓系数等手段改进其效果。