目录
0 问题描述
绝对值分布分析也可以理解为组距分组分析。对于某个指标而言,一个记录对应的指标值的绝对值,肯定落在所有指标值的绝对值的最小值和最大值构成的区间内,根据一定的算法,在把这个区间划分为等距离的几个小区间,统计落入这些区间的指标值的绝对值的情况,决策者就可以得到指标值的绝对值在各个区间的分布情况。
以销售表为例,销售表如下:
| country | sale_month | sales_number | sales_value |
| USA | 2008-01-01 | 1200 | 500000 |
| USA | 2008-02-01 | 1150 | 450000 |
| USA | 2008-03-01 | 1300 | 520000 |
| USA | 2008-04-01 | 1280 | 510000 |
| USA | 2008-05-01 | 1350 | 530000 |
| USA | 2008-06-01 | 1400 | 535000 |
| USA | 2008-07-01 | 1300 | 510000 |
| USA | 2008-08-01 | 1250 | 460000 |
| USA | 2008-09-01 | 1400 | 530000 |
| USA | 2008-10-01 | 1380 | 520000 |
| USA | 2008-11-01 | 1450 | 540000 |
| USA | 2008-12-01 | 1500 | 545000 |
| USA | 2009-01-01 | 1600 | 550000 |
| USA | 2009-02-01 | 1390 | 532000 |
| USA | 2009-03-01 | 1730 | 570000 |
| USA | 2009-04-01 | 1900 | 600000 |
| USA | 2009-05-01 | 1850 | 585000 |
| USA | 2009-06-01 | 3800 | 780000 |
| USA | 2009-07-01 | 1700 | 560000 |
| USA | 2009-08-01 | 1490 | 542000 |
| USA | 2009-09-01 | 1830 | 580000 |
| USA | 2009-10-01 | 2000 | 610000 |
| USA | 2009-11-01 | 1950 | 595000 |
| USA | 2009-12-01 | 1900 | 590000 |
1 数据准备
create table sales as
select 'USA' country, '2008-01-01' sale_month, '1200' sales_number, '500000' sales_value union all
select 'USA' country, '2008-02-01' sale_month, '1150' sales_number, '450000' sales_value union all
select 'USA' country, '2008-03-01' sale_month, '1300' sales_number, '520000' sales_value union all
select 'USA' country, '2008-04-01' sale_month, '1280' sales_number, '510000' sales_value union all
select 'USA' country, '2008-05-01' sale_month, '1350' sales_number, '530000' sales_value union all
select 'USA' country, '2008-06-01' sale_month, '1400' sales_number, '535000' sales_value union all
select 'USA' country, '2008-07-01' sale_month, '1300' sales_number, '510000' sales_value union all
select 'USA' country, '2008-08-01' sale_month, '1250' sales_number, '460000' sales_value union all
select 'USA' country, '2008-09-01' sale_month, '1400' sales_number, '530000' sales_value union all
select 'USA' country, '2008-10-01' sale_month, '1380' sales_number, '520000' sales_value union all
select 'USA' country, '2008-11-01' sale_month, '1450' sales_number, '540000' sales_value union all
select 'USA' country, '2008-12-01' sale_month, '1500' sales_number, '545000' sales_value union all
select 'USA' country, '2009-01-01' sale_month, '1600' sales_number, '550000' sales_value union all
select 'USA' country, '2009-02-01' sale_month, '1390' sales_number, '532000' sales_value union all
select 'USA' country, '2009-03-01' sale_month, '1730' sales_number, '570000' sales_value union all
select 'USA' country, '2009-04-01' sale_month, '1900' sales_number, '600000' sales_value union all
select 'USA' country, '2009-05-01' sale_month, '1850' sales_number, '585000' sales_value union all
select 'USA' country, '2009-06-01' sale_month, '3800' sales_number, '780000' sales_value union all
select 'USA' country, '2009-07-01' sale_month, '1700' sales_number, '560000' sales_value union all
select 'USA' country, '2009-08-01' sale_month, '1490' sales_number, '542000' sales_value union all
select 'USA' country, '2009-09-01' sale_month, '1830' sales_number, '580000' sales_value union all
select 'USA' country, '2009-10-01' sale_month, '2000' sales_number, '610000' sales_value union all
select 'USA' country, '2009-11-01' sale_month, '1950' sales_number, '595000' sales_value union all
select 'USA' country, '2009-12-01' sale_month, '1900' sales_number, '590000' sales_value
;2 问题分析
第一步:按照给定的分组方法,计算区间开始,区间结束的值。计算区间范围维度表DIM
select group_num
, min_num + group_step * pos begin_num --区间开始
, min_num + group_step * (pos + 1) end_num --区间结束
, pos
from (select pos
, group_num
, group_step
, min_num
from (select
--分组方法
CEIL(1 + LOG(10, count_num) / LOG(10, 2)) group_num,
--极差/组数 =组距
CEIL((max_num - min_num) / CEIL(1 + LOG(10, count_num) / LOG(10, 2))) group_step,
min_num
from (SELECT MAX(sales_number) max_num,
MIN(sales_number) min_num,
COUNT(*) COUNT_NUM
FROM sales) t) t
lateral view posexplode(split(space(cast(group_num as int) - 1), space(1))) tmp as pos, value) t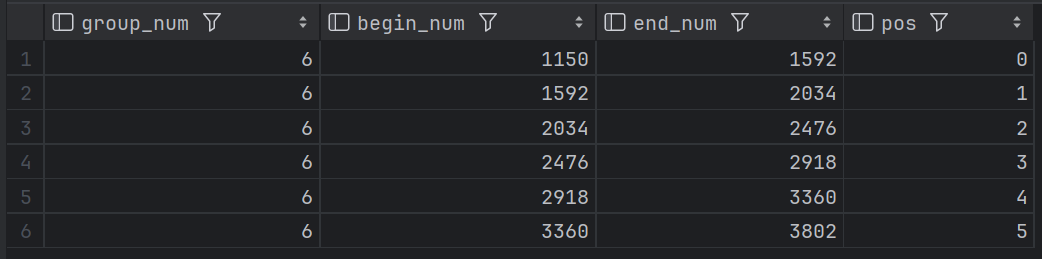
第二步:关联数据表SALES,计算落入区间范围的个数
with dim as (
select group_num
, min_num + group_step * pos begin_num --区间开始
, min_num + group_step * (pos + 1) end_num --区间结束
, pos
from (select pos
, group_num
, group_step
, min_num
from (select
--分组方法
CEIL(1 + LOG(10, count_num) / LOG(10, 2)) group_num,
--极差/组数 =组距
CEIL((max_num - min_num) / CEIL(1 + LOG(10, count_num) / LOG(10, 2))) group_step,
min_num
from (SELECT MAX(sales_number) max_num,
MIN(sales_number) min_num,
COUNT(*) COUNT_NUM
FROM sales) t) t
lateral view posexplode(split(space(cast(group_num as int) - 1), space(1))) tmp as pos, value) t
)
select concat_ws('-', cast(b.begin_num as string), cast(b.end_num as string)) group_name
, count(*) cnt
from dim b
left join sales a
WHERE a.sales_number >= b.begin_num
AND a.sales_number < b.end_num
GROUP BY concat_ws('-', cast(b.begin_num as string), cast(b.end_num as string))
3 小结
组距分组是将全部变量值依次划分为若干个区间,并将这一区间的变量值作为一组。组距分组是数值型数据分组的基本形式。离散变量的整数值如果变动幅度较大,而且总体单位数N又很大,则也要进行组距分组。 在组距分组中,各组之间的取值界限称为组限,一个组的最小值称为下限,最大值称为上限;上限与下限的差值称为组距;上限与下限值的平均数称为组中值,它是一组变量值的代表值。
具体步骤如下:
1. 确定组数。一组数据的组数一般与数据本身的特点及数据的多少有关。由于分组的目的之一是为了观察数据分布的特征,因此组数的多少应适中。如组数太少,数据的分布就会过于集中,组数太多,数据的分布就会过于分散,这都不便于观察数据分布的特征和规律。组数的确定应以能够显示数据的分布特征和规律为目的。
2.确定各组的组距。组距是一个组的上限与下限的差,可根据全部数据的最大值和最小值(即极差)及所分的组数来确定,即组距=(最大值-最小值)/组数。
3.根据分组整理成频数分布表。

如果您觉得本文还不错,对你有帮助,那么不妨可以关注一下我的数字化建设实践之路专栏,这里的内容会更精彩。
专栏 原价99,现在活动价59.9,按照阶梯式增长,还差5个人上升到69.9,最终恢复到原价。
专栏优势:
(1)一次收费持续更新。
(2)实战中总结的SQL技巧,帮助SQLBOY 在SQL语言上有质的飞越,无论你应对业务难题及面试都会游刃有余【全网唯一讲SQL实战技巧,方法独特】
SQL很简单,可你却写不好?每天一点点,收获不止一点点-CSDN博客
(3)实战中数仓建模技巧总结,让你认识不一样的数仓。【数据建模+业务建模,不一样的认知体系】(如果只懂数据建模而不懂业务建模,数仓体系认知是不全面的)
(4)数字化建设当中遇到难题解决思路及问题思考。
我的专栏具体链接如下: