一: 集合
ArrayList
构造函数
- 1、无参构造:创建一个容量为0的数组
- 2、参数为int n:创建一个大小为n的数组
- 3、参数为集合Collection:创建一个大小为Collection.size的数组
什么时候扩容?
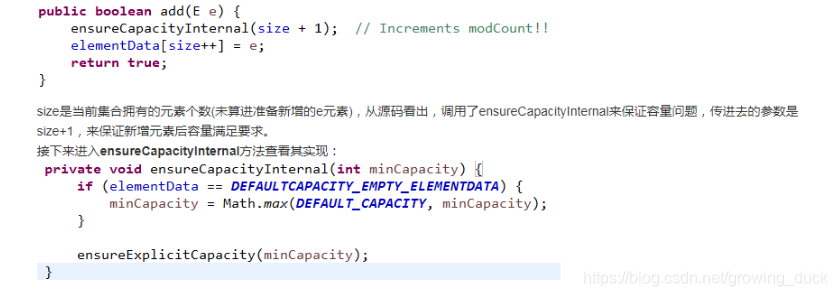
- 在add添加元素时候
先调用ensureCapacityInternal方法保证容量够用,然后赋值。那么怎样保证容量够用呢?
使用当前的元素个数 size + 1赋值给minCapacity来表示添加元素后的元素个数(如果size+1小于10则取10),使用minCapacity与当前容量oldCapacity比较,大于oldCapacity则开始扩容,按1.5倍扩容,扩容之后为newCapacity,如果还是比minCapacity小,则取minCapacity(第一次添加时,如果当前容量为0,size为0,minCapacity为10,这个时候1.5被扩容还是0,所以newCapacity就取的minCapacity,这也就是new ArrayList()初始容量为10的原因)
当然最终确定newCapacity还有最后一步判断(一般用不到):当newCapacity大于Integer.MAX_VALUE-8(整数的最大值-8)时,如果minCapacity也大于Integer.MAX_VALUE-8,则newCapacity = Integer.MAX_VALUE,否则newCapacity = Integer.MAX_VALUE-8。这样就能保证扩容后的容量不会小于存放的元素个数
Hashmap
结构
- hashmap是数组 + 链表的形式存储,先计算key的hash值,再和数组长度-1取与(&),来得到在数组中的index。
扩容
- 元素个数超过数组长度的0.75倍时,2倍扩容,数组为原来的两倍。 新建数组,,也把原来的值拷贝过去。
- 如果不扩容,,会造成大量的hash碰撞,影响性能。
ConcurrentHashMap
三:并发编程
java锁:
1:重入锁
- 所谓重入锁,同一个线程可以都次获取同一个对象的锁,其他线程则需要等待,意义在于避免死锁。
- synchronized 和 ReentrantLock 都是可重入锁,
- 比如同一个线程可以执行一个对象的多个synchronized 方法
- 比如ReentrantLock 可以多次lock.lock()
2:ReentrantLock
- lock(); 获取锁,锁被占用则等待。
- lockInterruptibly(); 响应线程中断,放弃获取锁,并释放已有资源,不会一直傻傻的等待。
- tryLock(); 尝试获取锁,返回boolean值,不等待
- tryLock(long time,TimeUnit unit); 指定时间内尝试获取锁
- unLock();
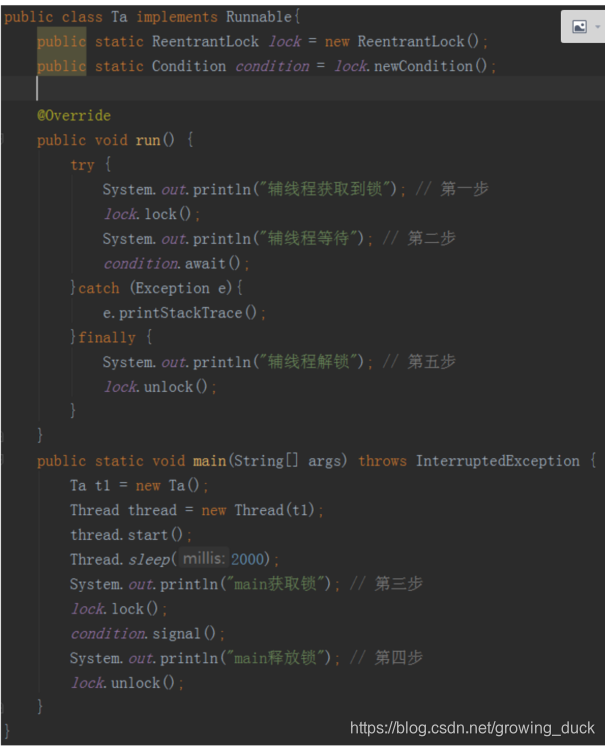
3:Condition
- Lock lock = new ReentrantLock();
- Condition condition = lock.newCondition();
- 该condition同lock绑定到一起,类似于synchronized 中锁住的对象,它有以下方法:
- await(); 让当前线程在condition上等待,并自动释放lock。 响应中断,放弃等待
- awaitUninterruptibly(); 等待,并释放lock,不响应中断,一直等下去
- signal(); 唤醒在await()的线程,需要手动去释放锁,
- signalAll();
ReentrantLock比synchronized更细粒度,但是需要手动释放(finally中一定要释放,避免普通释放代码没有执行到); 另外synchronized是非公平锁,而new ReentrantLock(true)可以让lock成为公平锁,也就是释放锁后,按等待线程的先来后到顺序获取。
4:读写锁
public static ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock();
public static Lock readLock = reentrantReadWriteLock.readLock();
public static Lock writeLock = reentrantReadWriteLock.writeLock();
读-读:不互斥 多个线程可以获得同一个读锁
写-写: 互斥 多个线程不能同时获取同一个写锁
读-写:互斥 一个线程不能在持有读锁的情况下,又获取写锁
写-读:不互斥 一个线程先持有写锁,可以再持有读锁
多线程:
1、Thread和Runnable区别:
- 使用Thread只能单根继承;
- Runnable需要传入Thread中使用,thread的run方法也是调用runnable的run方法,所以将同一个runnable对象传入不同的thread,可以实现资源共享;
- Callable:可以拿到返回值
2、线程状态:
- 新建,准备,运行,等待,阻塞,结束
3、常用api:
- sleep是线程的方法,主动挂起,不会让出cpu;
- wait是Object方法,obj.wait(),则当前线程会假如obj对象的等待队列中,直到被唤醒。 所以多个线程在操作obj对象时,必须获取obj的锁,wait和notify要处于同步块中。
- yeild(): 当然线程让出cpu资源给其他线程执行(不一定谦让成功);
- interupt: 线程中断。 其实就是给一个中断的标识:把线程的一个变量设置为true。 在线程执行过程中的合适位置调用Thread.interrupt()或者Thread.interrupted()判断该标识,为true就结束代码。 Thread.interrupted()调用后会清除标志位。
线程池:
Executors.
- newFixedThreadPool();
- newSingleThreadExecutor();
- newCachedThreadPool(); 线程数可变
- newScheduledThreadPool(); 定时任务
- newSingleScheduledThreadPool(); 定时任务-线程数只有一个
其中,newScheduledThreadPool有三个方法:
schedule(Runnable command,long delay,TimeUnit unit); 每经过delay的时间后执行一次任务
scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit); 经过initialDelay的时间后执行第一次任务,之后以上一次开始执行任务的时间为起点,经过period的时间,执行下一次任务。如果上一次任务的执行时间,大于period,则下一次任务会等上一次任务完成后立马执 行,而不会出现任务叠加的情况。
scheduleWithFixedDelay(Runnable command,long initialDelay,long period,TimeUnit unit); 同上面的去区别是,第一次任务结束后的period时间后,执行下一次任务
注意:如果任务出现了异常,后面的所有任务都不会执行。
线程池内部实现:
public ThreadPoolExecutor(
int corePoolSize, --指定线程池中线程的数量
int maximumPoolSize, --指定最大线程数量
long keepAliveTime, --超过了corePoolSize数量的空闲线程存活时间
TimeUnit unit,
BlockingQueue<Runnable> wordQueue, --任务队列,存放被提交但未被执行的任务
ThreadFactory threadFactory, --线程工厂,用于创建线程
RejectedExecutionHandler handler --拒绝策略,任务太多如何拒绝
)
BlockingQueue有几种:
1、直接提交的队列-SynchronousQueue
该队列不会保存任务,直接提交执行,所以需要设置很大的maximumPoolSize,否则很容易拒绝
2、有界的任务队列-ArrayBlockingQueue
小于corePoolSize时会创建新线程,超过后会放到queue中,超过queue的数量后,继续创建新线程,直到达到maximumPoolSize后执行拒绝策略
3、无界的任务队列-LinkedBlockingQueue
达到corePoolSize后会放入queue中,因为无界,所以可以一直放,直到资源耗尽
4、优先任务队列-PriorityBlockingQueue
优先级高的任务会先执行
常用线程池中使用的Queue:
newFixedThreadPool: LinkedBlockingQueue
newCachedThreadPool: SynchronousQueue
JDK内置拒绝策略:
1、AbortPolicy: 直接拒绝抛异常,停止工作
2、CallerRunsPolicy: 不想丢弃任务,如果线程池未关闭,直接调用任务的run方法,但是很可能造成性能急剧下降
3、DiscardOledestPolicy: 丢弃队列中即将最早提交的任务,接收新的
4、DiscardPolicy:直接拒绝但不抛异常